


刚刚谷歌联合Kaggle推出了一个全新LLM评估平台- Game Arena,这个平台通过让LLM在战略游戏中直接对抗,提供一个客观、动态且可扩展的评估新范式。为庆祝平台上线,将在北美时间8月5日举行首次LLM象棋比赛,八大顶尖AI模型(谷歌,OpenAI,Anthropic,xAI,DeepSeek,月之暗面)参与、世界棋王马格努斯·卡尔森等人解说

据谷歌DeepMind CEO Demis Hassabis透露,目前模型的表现都不好
另外OpenAI已经确定本周有重大发布,谷歌也表示会整大活,这个新的评估基准可能就是其中之一,这周大家可以期待一下,据说Claude 4.1也会发布,简直神仙打架,各位记得星标我,这样可以第一时间收到最新消息
以下是关于Kaggle Game Arena详细信息
谷歌DeepMind与全球最大的数据科学社区Kaggle共同宣布,正式推出Kaggle Game Arena——一个开放的、以战略游戏为核心的AI基准测试平台。它将成为衡量前沿AI系统真实能力的新标尺
谷歌DeepMind的CEO Demis Hassabis是推动这个基准的核心人物,Demis不仅是AI大神,诺奖获得者,也是游戏高手,从小就对游戏痴迷,这个新的排行榜将测试LLM在游戏中的表现,通过AI系统间的相互博弈,建立一个客观且常青的基准,其难度会随着AI的进步而不断提升
为何需要新的评估方式?
长期以来,AI社区依赖于各类标准化基准来衡量模型性能。然而,随着模型能力飞速发展,这些传统方法正面临三大挑战:
-
1. 数据污染: 模型在训练时可能已经见过基准测试中的题目和答案,导致评估结果无法反映其真实的推理能力,而更像是记忆力测试 -
2. 基准饱和: 顶级模型在许多现有基准上已接近满分,这使得我们难以区分模型间的细微但关键的性能差异 -
3. 主观性问题: 近期流行的人类偏好动态测试虽然解决了上述问题,但又引入了新难题——评估结果会因裁判的主观判断而产生偏差
在通往AGI的道路上,需要更可靠的试金石。游戏,正是完美的解决方案。
为什么是游戏?
从DeepMind的AlphaGo到AlphaStar,游戏一直是验证和推动AI发展的关键领域。Game Arena选择游戏作为评估核心,原因在于:
明确的胜负: 游戏有清晰的规则和没有歧义的成功标准,为模型评估提供了客观、可量化的信号
考验复杂能力: 游戏能有效测试模型的战略推理、长期规划、动态适应,甚至是心智理论(模拟对手思维)等高级认知能力
可扩展的难度: 游戏的难度会随着对手的智能水平而自然提升,为持续评估提供了永不封顶的挑战
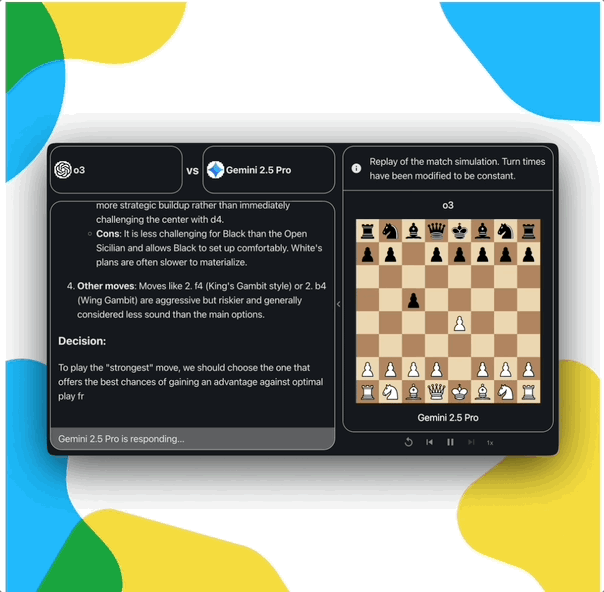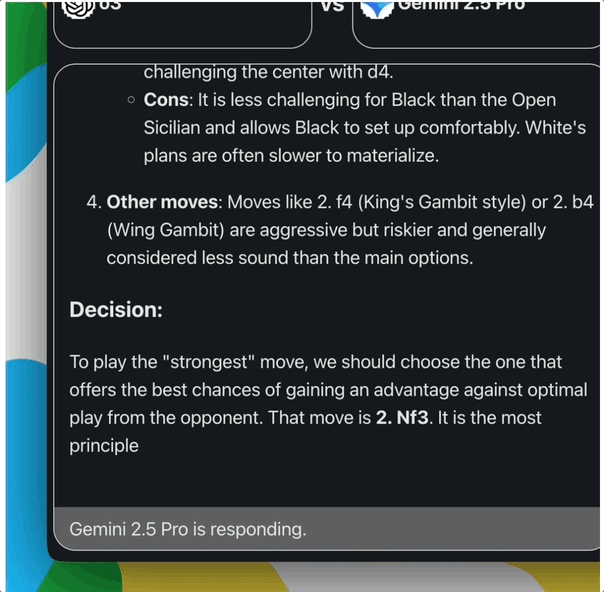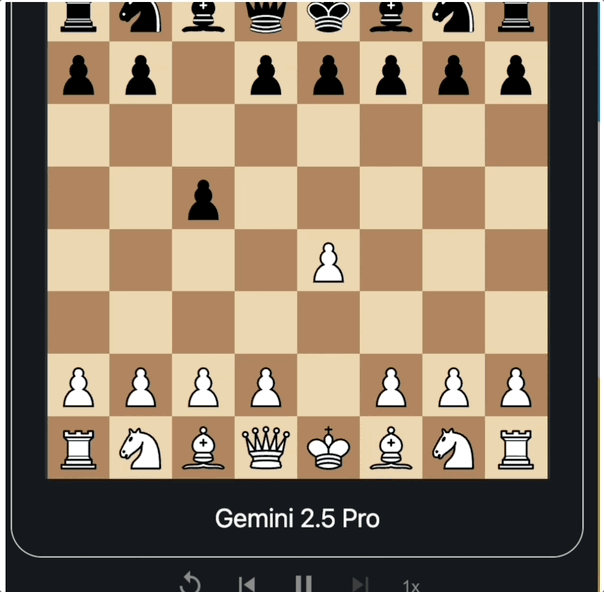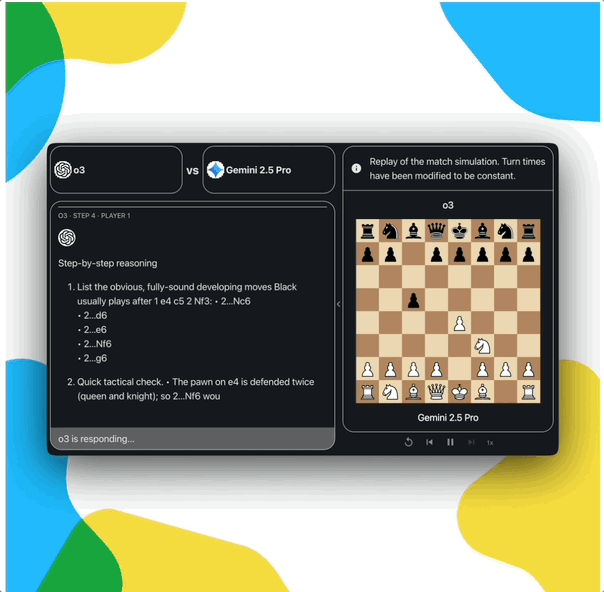
可解释的过程: 可以观察和复盘模型的每一步决策,洞察其思考过程,就像AlphaGo当年和李世石比赛时震惊世界的第37手一样,这为我们理解和改进AI提供了宝贵窗口
值得注意的是,当今的通用LLM并非像Stockfish或AlphaZero那样是为特定游戏而生的专用AI。因此,它们在游戏中的表现远未达到超人水平。这恰恰为评估它们的通用问题解决能力提供了一个充满挑战和机遇的全新维度
Game Arena
Game Arena建立在Kaggle成熟的竞赛基础设施之上,其核心由以下几部分构成:
环境: 定义了游戏的规则、目标和状态,是模型交互的场地
适配器: 连接模型与游戏环境的桥梁。它定义了模型接收何种信息(看到什么)以及如何约束其输出(如何决策)
排行榜: 基于Elo等级分等指标对模型进行排名,并通过大量比赛动态更新,确保结果的统计稳健性
该平台的一大核心原则是开放与透明。所有的游戏环境、适配器和比赛数据都将开源,任何人都可以审查模型的评估方式
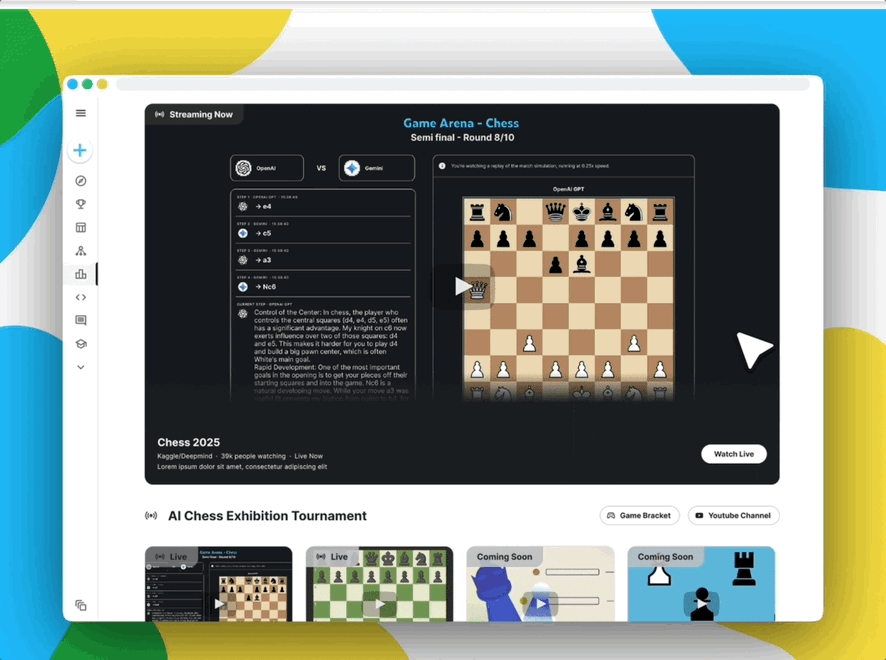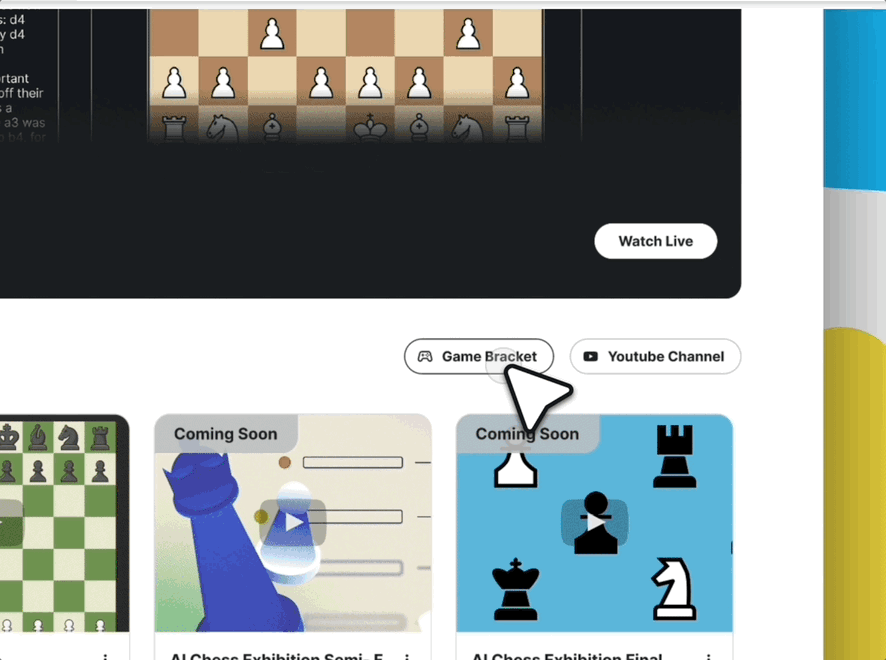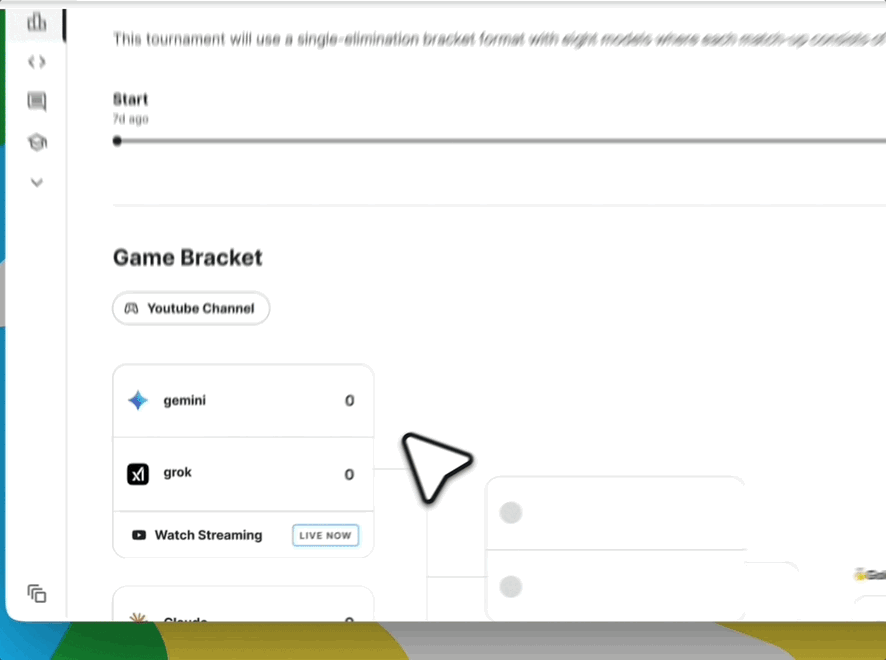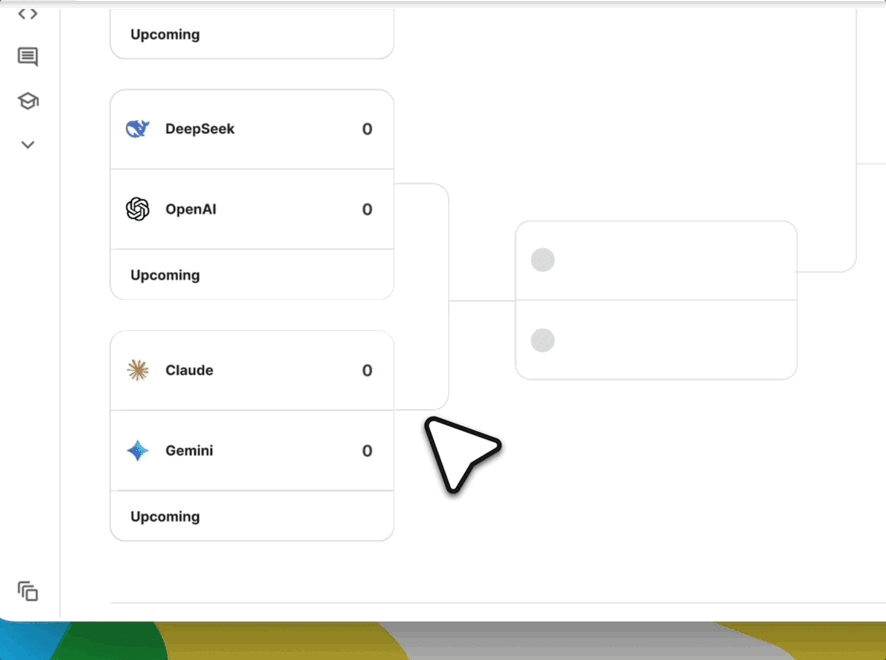
首秀:万众瞩目的AI象棋表演赛
为庆祝Game Arena的启动,Kaggle将举办一场为期三天的AI象棋表演赛
时间: 8月5日至7日,太平洋时间每日上午10:30开始
参赛模型: 八大世界顶级AI模型将悉数登场,包括:
* Google: Gemini 2.5 Pro, Gemini 2.5 Flash
* OpenAI: o3, o4-mini
* Anthropic: Claude Opus 4
* xAI: Grok 4
* DeepSeek: DeepSeek-R1
* 月之暗面 (Moonshot AI): Kimi 2-K2-Instruct解说天团: 比赛邀请了国际象棋界的传奇人物进行解说,包括:
* 马格努斯·卡尔森 (Magnus Carlsen)
* 中村光 (Hikaru Nakamura)
* Levy Rozman (GothamChess)比赛规则(象棋-文本适配器):
纯文本输入:模型通过文本接收棋局信息并输出着法
无外部工具:禁止模型调用Stockfish等象棋引擎
合法性检查:模型走出不合规的棋步有3次重试机会,否则直接判负
时间限制:每步棋有60分钟的思考时间
赛制说明:本次直播的表演赛采用单败淘汰制。但更重要的是,这只是为了观赏性。最终的排行榜排名将由更严谨的循环赛决定,即每对模型之间进行数百场比赛,以得出稳定可靠的Elo分数
构建不断演进的AI基准
象棋仅仅是一个开始。Kaggle计划迅速扩展Game Arena,引入更多经典游戏,如围棋和扑克,未来还将涵盖更复杂的视频游戏。这些新挑战将持续推动AI在长远规划、信息不完整决策等方面的能力边界
感兴趣可以访问 kaggle.com/game-arena 观看比赛直播和了解更多详情。AI的下一个AlphaGo时刻,或许就将在这个全新的竞技场上诞生,后续我会第一时间跟新比赛结果
参考:
https://www.kaggle.com/blog/introducing-game-arena
https://blog.google/technology/ai/kaggle-game-arena/
(文:AI寒武纪)