

又是国产 AI “风起云涌”的一周!
📢本周AI快讯 | 1分钟速览🚀
1️⃣ 🏆 DeepSeek 斩获 ACL 最佳论文 :梁文锋团队的原生稀疏注意力技术将长文本处理速度提升 11 倍,可支持百万 tokens 级别上下文。
2️⃣ 🔥 智谱开源 GLM-4.5 :3550 亿参数 MoE 架构,12 项评测全球第三、国产第一,API 价格仅为 Claude 十分之一。
3️⃣ 💻 阿里发布编程小模型 Qwen3-Coder-Flash :30.5B 参数仅激活 3.3B,智能体编程能力超越所有开源模型,支持 262K 超长上下文。
4️⃣ 🧠 阿里推理模型 Qwen3-30B-A3B-Thinking :AIME25 数学竞赛得分 85.0,量化版本仅需 32GB 内存,本地部署成为现实。
5️⃣ ⚡ Kimi K2 高速版发布 :输出速度飙升至每秒 40 Tokens,实现 4 倍加速,限时五折优惠至 9 月 1 日。
6️⃣ 🐝 Manus 推出“广泛研究” :199 美元/月解锁智能体集群协作,可同时调度数十个 AI Agent 并行处理复杂任务。
7️⃣ 🤖 360 纳米 AI 升级 L4 级“蜂群” :全球首个多智能体蜂群系统,5 万个推理智能体协同作战,视频生成效率提升 6 倍。
8️⃣ 🎯 昆仑万维开源 Skywork MindLink :自适应推理范式智能切换,人类最后考试评测第一,数学奥赛包揽 4 项冠军。
9️⃣ 📚 OpenAI 推出 Study 学习模式 :采用苏格拉底式教学法,联合 40 余所高校打造,实现真正的“授人以渔”。
🔟 🎭 神秘模型 Horizon Alpha 登顶 :EQ-Bench 得分 1570.9,256K 上下文,疑似 OpenAI 的 GPT-5 测试版本。
1️⃣1️⃣ 🧩 谷歌 Gemini 2.5 Deep Think 上线 :开启“并行思考”时代,HLE 测试成绩 34.8% 超越 Grok 4 和 o3。
1️⃣2️⃣ 🖥️ Ollama 桌面版发布 :macOS 和 Windows 一键运行本地大模型,支持 DeepSeek-R1、Llama 3.3 等主流模型。
1️⃣3️⃣ 💑 马斯克推出虚拟男友 Valentine :Grok Heavy 订阅用户专享,300 美元/月,正式进军女性向 AI 陪伴市场。
1️⃣4️⃣ ⏱️ Anthropic 限制 Claude 使用 :8 月 28 日起实施每周限额,Pro 用户 40-80 小时,仅影响 5% 极限用户。
1️⃣5️⃣ 🎨 Black Forest Labs 开源 FLUX.1 Krea dev :120 亿参数专注照片级写实,有效解决传统文生图的“AI 感”问题。
01|DeepSeek 创始人梁文锋署名论文斩获 ACL 2025 最佳论文奖
8 月 1 日,在 ACL 2025 颁奖典礼上,由 DeepSeek 创始人梁文锋作为通讯作者,与北京大学等联合发表的论文《Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention》斩获大会最佳论文奖。本届 ACL 规模空前,总投稿量达到 8360 篇,相较去年的 4407 篇几乎翻倍,竞争异常激烈。值得注意的是,今年所有投稿论文的第一作者中,有超过一半(51.3%)来自中国,而去年这一比例还不到三成;相较之下,美国作者占比则降至 14.0%,充分显示出中国在 AI 自然语言处理研究领域的强势崛起。

获奖论文提出的原生稀疏注意力(Native Sparse Attention, NSA)机制在算法与硬件协同优化方面实现了革命性突破,直接将长文本处理速度提升了 11 倍。更为关键的是,在性能表现上,NSA 并未因稀疏化处理而降低准确性,反而在多个指标上超过了传统的全注意力模型。一作袁境阳在会上透露,这一创新机制可支持上下文长度扩展至百万 tokens 级别,未来将率先应用于 DeepSeek 的下一代前沿模型中。结合该论文发表于 DeepSeek-R1 发布之后、且实验部分采用了 DeepSeek-R1 蒸馏数据进行微调,业界纷纷猜测 NSA 很可能成为下一代 DeepSeek-V4 和 DeepSeek-R2 的核心技术。NSA 的成功不仅体现出 DeepSeek 在基础技术研发上的强劲实力,也标志着中国 AI 研究正在从“模型规模竞赛”迈向更加高效的“算力效率竞赛”新时代。
02|智谱发布并开源旗舰模型 GLM-4.5,国产开源再创新高
7 月 28 日,智谱正式推出新一代旗舰模型 GLM-4.5 系列,这是业内首个专为 AI Agent 智能体应用打造的原生融合推理、编码与智能体能力的开源基础模型,采用混合专家(MoE)架构。该系列包含两款版本:总参数 3550 亿、激活参数 320 亿的旗舰版 GLM-4.5,以及精简高效的 1060 亿参数版 GLM-4.5-Air。GLM-4.5 在 12 项权威评测基准中斩获全球第三、国产第一、开源第一的亮眼成绩,综合平均分达到 63.2,超越了 DeepSeek-R1、Kimi K2 等多款明星竞品。

技术创新方面,GLM-4.5 展现出出色的参数效率:参数规模仅为 DeepSeek-R1 的一半、Kimi-K2 的三分之一,但在多项标准基准测试中表现反而更胜一筹。智谱团队设计了严格的三阶段训练流程:首先在 15 万亿 tokens 的通用数据集上完成基础预训练,接着用 8 万亿 tokens 的代码、推理和智能体特定数据进行精准强化,最后再通过强化学习进一步增强能力。在商业策略上,API 价格极具竞争力,输入每百万 tokens 仅需 0.8 元、输出 2 元人民币,成本仅为 Claude 的十分之一,高速版实测生成速度更超过 100 tokens/秒。目前,GLM-4.5 已在 Hugging Face 和 ModelScope 平台同步开源,模型权重采用 MIT License 开放,满血版可在智谱清言及 z.ai 官网免费体验,真正实现了 AI 技术的普惠化落地。
03|阿里千问发布编程小模型 Qwen3-Coder-Flash
7 月 31 日,阿里通义千问团队正式发布全新编程小模型 Qwen3-Coder-Flash(全称 Qwen3-Coder-30B-A3B-Instruct)。该模型在保持高性能与高效率的基础上,重点强化了智能体编程、智能体浏览器使用及基础编码任务能力,进一步完善了阿里在开发者工具与 AI Agent 领域的布局。Qwen3-Coder-Flash 采用混合专家(MoE)架构,总参数量 30.5B,激活参数仅 3.3B,实现了“小马拉大车”的高效能设计。

Qwen3-Coder-Flash 的核心亮点在于其卓越的智能体能力。在智能体编程(Agentic Coding)、浏览器使用(Agentic Browser-Use)和工具调用(Tool Use)等前沿场景中,该模型超越了现有所有开源模型,仅略逊于顶配版 Qwen3-Coder-480B-A35B-Instruct 及闭源的 Claude Sonnet-4、GPT-4.1 等旗舰模型。模型原生支持 262,144 tokens 的超长上下文,并可通过 YaRN 技术扩展至 100 万 tokens,能够一次性理解整个代码库,有效解决上下文断层问题。同时,该模型针对 Qwen Code、CLINE、Roo Code 等平台进行了函数调用格式优化,大幅提升实际部署效率,为全球开发者提供了一款兼具性能、效率与易用性的高效编程助手。
04|阿里千问发布推理小模型 Qwen3-30B-A3B-Thinking-2507
7 月 30 日,阿里通义千问团队正式发布全新推理模型 Qwen3-30B-A3B-Thinking-2507,继同日上线的非推理版本 Qwen3-30B-A3B-Instruct-2507 后,再次完善了 30B 系列产品矩阵。作为今年 4 月开源的 Qwen3-30B-A3B 系列最新迭代,该模型在逻辑推理、数学、科学和编程等专业场景中实现了显著跃升,其中 AIME25 数学竞赛得分高达 85.0,已逼近大参数模型表现。
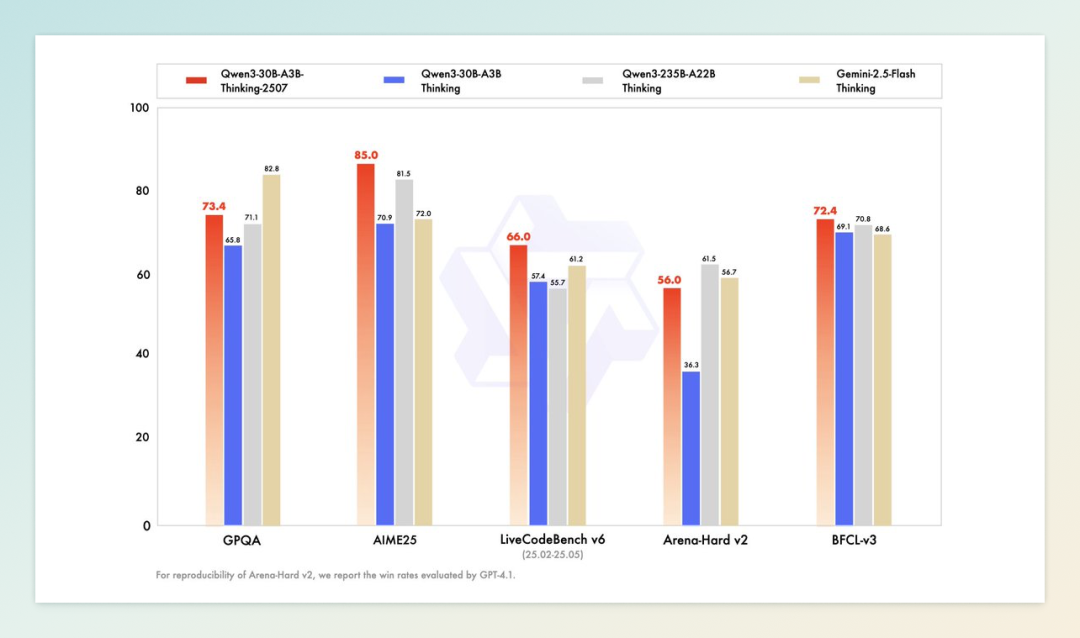
此次更新标志着阿里正式确立“推理”与“非推理”模型的独立发展路线,将原有混合架构拆解为两个针对性优化的版本,以便更精准地匹配不同应用需求。新模型原生支持 262,144 tokens 的超长上下文,并强化了长链条推理能力,官方建议在高复杂度任务中优先使用。在部署层面,Qwen3-30B-A3B-Thinking-2507 展现了“小而强”的特性:量化版本仅需 32GB 内存即可运行,在 M4 Max 芯片上推理速度可突破 100 tokens/s,让本地部署成为现实。结合活跃的开源生态,这款模型显著降低了高性能推理的门槛,使中小企业及个人开发者也能轻松享受顶尖推理技术带来的生产力红利。
05|月之暗面发布 Kimi K2 高速版,速度飙升至每秒 40 Tokens
8 月 1 日,月之暗面正式推出 Kimi K2 高速版 —— Kimi-K2-turbo-preview,将大模型速度提升至新的里程碑。该版本在保持原有参数规模不变的前提下,将输出速度从每秒 10 Tokens 提升至每秒 40 Tokens,实现 4 倍加速,为用户带来显著更流畅的交互体验。
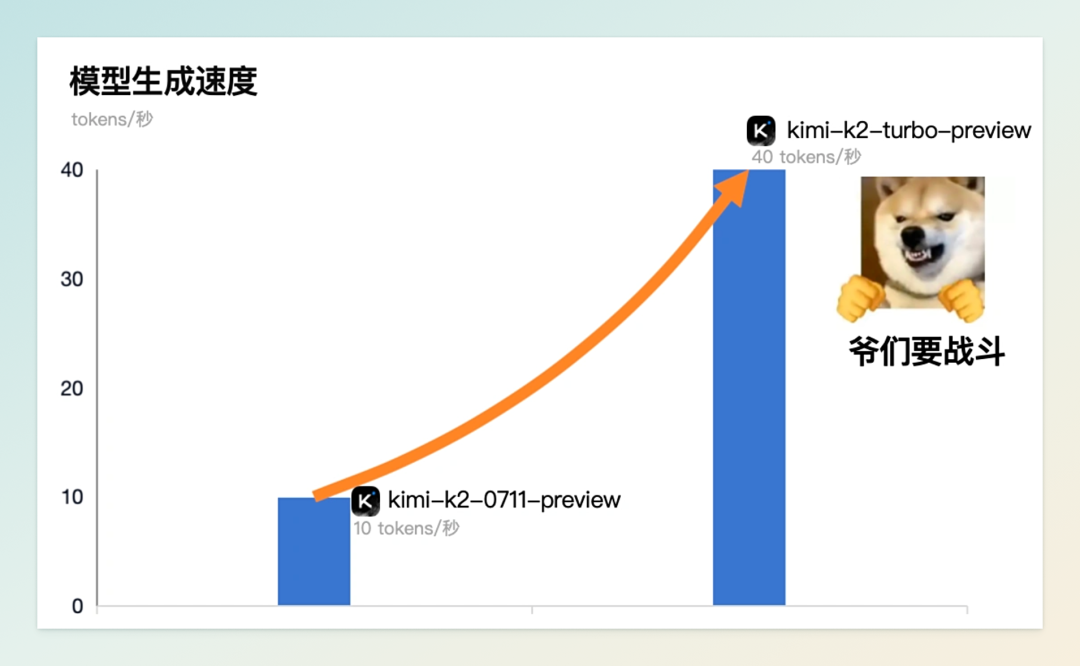
高速版延续了 Kimi K2 的核心优势。这款采用 MoE 架构的模型拥有 1T 总参数、32B 激活参数,在代码生成、智能体任务(Agent)及数学推理等领域表现优异,原生支持最长 128K 上下文。为推广此次升级,月之暗面同步推出限时五折优惠活动,至 9 月 1 日前有效:输入价格为每百万 tokens(缓存命中)2 元、(缓存未命中)8 元,输出价格 32 元。此次速度飞跃不仅显著提升了用户体验,也彰显了月之暗面在大模型推理优化上的技术实力,为高吞吐量与实时响应需求的企业级应用提供了更具竞争力的解决方案。
06|Manus 推出“广泛研究”功能,199 美元/月解锁智能体集群协作
8 月 1 日,AI 智能体平台 Manus 正式上线新功能“广泛研究”(Wide Research),这是该平台自 3 月发布以来最大规模的更新。该功能允许系统同时调用大批 AI 智能体并行处理复杂任务,实现大规模数据的同步分析,标志着 AI 研究工具正从“深度探索”迈向“广度协作”的新阶段。
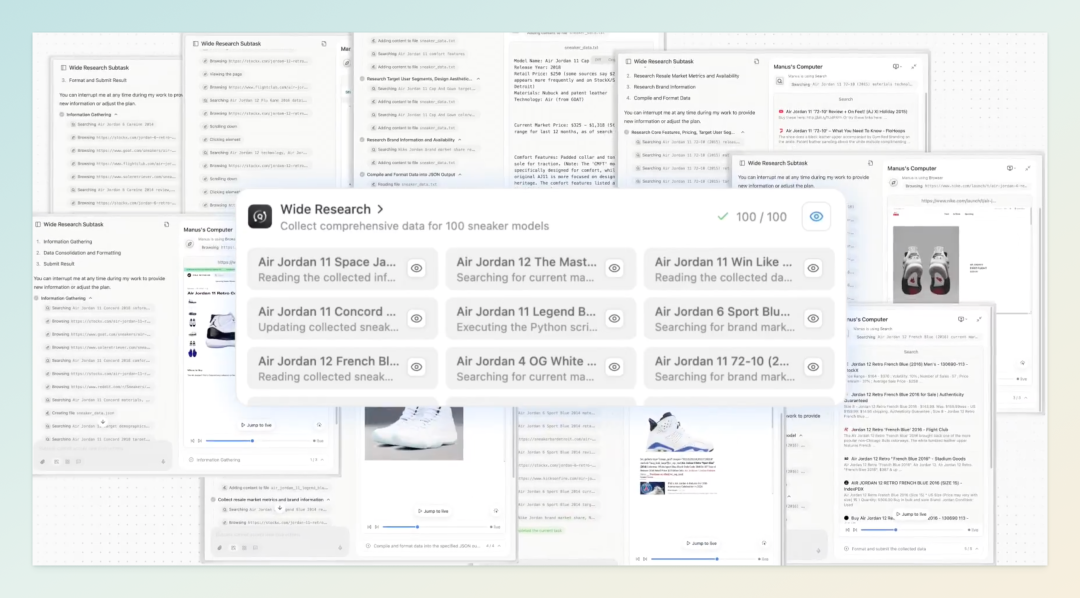
Wide Research 的核心创新在于“智能体集群协作”技术,与 OpenAI 的 Deep Research 等侧重单一智能体深度推理的模式截然不同。用户可以一次性调度数十个智能体并行工作,从容完成诸如“生成 50 个海报设计草稿”“排名全球前 100 的 MBA 项目”“分析 1000 支股票表现”等高负载任务 —— 这些在现有工具中往往难以高效完成。技术架构上,每个子智能体均为功能完整的 Manus 实例,运行在独立虚拟机上,既保证了灵活性,也为水平扩展提供了充分空间。
该功能将以 199 美元/月的高阶订阅服务提供,与 OpenAI ChatGPT Pro 定价接近,彰显了 Manus 在高端智能体市场的激进布局。对企业用户和专业研究者而言,Wide Research 的推出意味着大规模并行智能体协作正从概念走向可落地的生产力工具。
07|360 纳米 AI 升级为全球首个 L4 级“多智能体蜂群”
8 月 2 日,360 集团宣布旗下纳米 AI 完成品牌焕新,正式升级为“多智能体蜂群”,成为全球首个迈入 L4 级别的智能体系统,实现了从“单兵作战”到“群体协同”的物种级跃迁。这一突破颠覆了传统智能体工作模式,也解决了长期困扰行业的多智能体协作难题 —— 在现有框架下,多智能体在任务分配、参数传递和上下文管理等方面存在天然瓶颈,单个智能体成功率可达 90%,而 5 个智能体协作的成功率甚至可能跌至 50% 以下。
纳米 AI 的核心技术创新体现在两大方面:一是实现多智能体灵活组队与多层嵌套协作,让多个“AI 专家”各司其职、紧密配合,如同蜂群作战般高效完成复杂任务;二是支持灵活编队,既可单蜂群作战,也可组合为蜂群方阵,并能根据用户任务需求实时调整阵形。当前,纳米 AI 已拥有超过 5 万个 L3 级推理智能体,可连续执行超 1000 步、持续 2 小时不中断的复杂任务,累计消耗 token 超 2000 万。
在应用层面,纳米 AI 的“一句话生成大片”功能尤为亮眼:从脚本、分镜、画面到配音、配乐及剪辑成片,原本依赖 L1 至 L3 级智能体完成的工作至少需 2 小时,如今仅需 20 分钟,大幅提升了视频创作与生产效率。
08|昆仑万维开源推理大模型 Skywork MindLink
8 月 2 日,昆仑万维正式发布并开源全新推理大模型 Skywork MindLink,标志着大模型推理技术迈入新阶段。该模型采用创新的自适应推理范式,可根据任务难度智能切换推理与非推理回复,大幅降低推理成本,同时提升多轮对话的可读性与有效性。与传统推理模型普遍生成冗长思考链不同,MindLink 引入了革命性的 Plan-based Reasoning 技术,去除了“think”标签,不仅节省计算开销,还在实际应用中实现了推理效率与质量的双重提升。
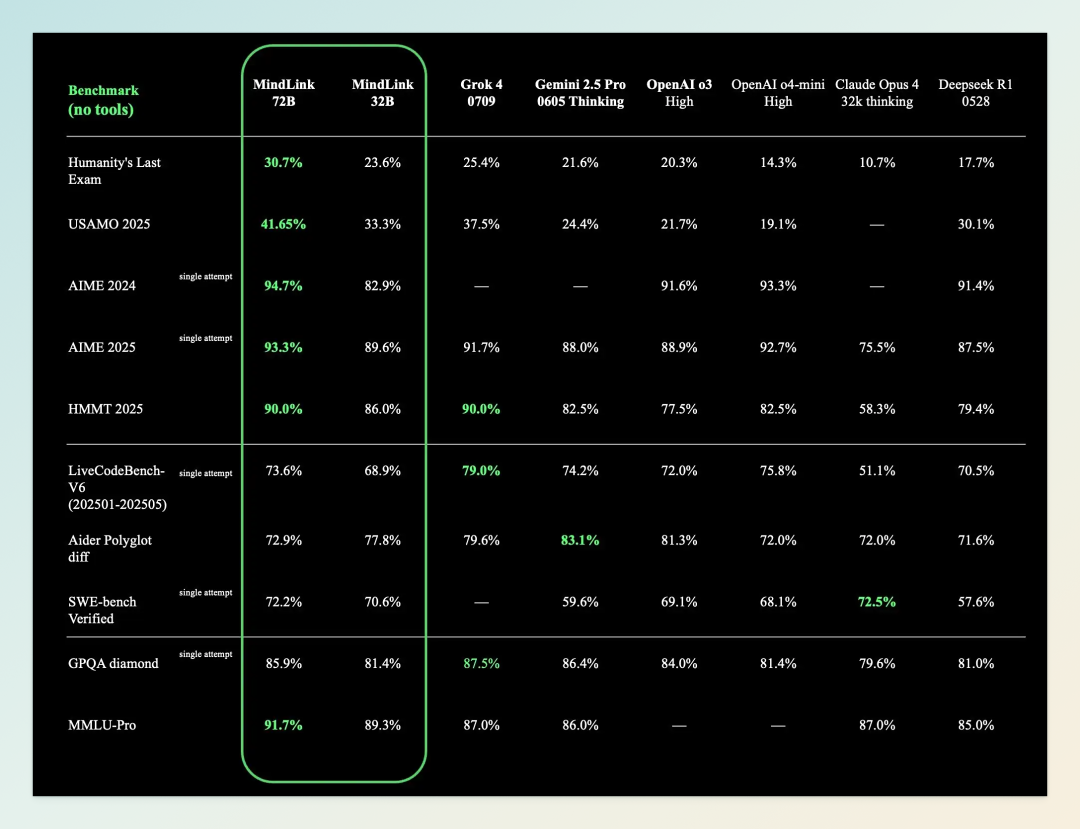
性能方面,Skywork MindLink 表现亮眼:在 Humanity’s Last Exam(人类最后的考试)评测中位列第一,在数学奥赛相关测试(USAMO 2025、AIME 2024、AIME 2025、HMMT 2025)中包揽 4 项第一,在通识类 GPQA-diamond 与 MMLU-pro 评测中也表现优异。值得一提的是,该模型基于 Qwen3-32B 与 Qwen2.5-72B 进行后训练,在节省大量训练成本的同时进一步释放原模型潜力,为行业探索出一条更具性价比的推理模型训练路径。
昆仑万维表示,目前公司已形成覆盖语言、多模态、SWE 代码、Agent、视频、3D、音乐与音频等多领域的完整大模型矩阵,Skywork MindLink 的加入进一步巩固了其在推理能力和技术创新上的领先地位。
09|OpenAI 推出 ChatGPT 学习模式,打造“授人以渔”的智能辅导
7 月 30 日,OpenAI 正式发布 ChatGPT 全新 Study 学习模式,现已面向所有 Free、Plus、Pro 与 Team 用户开放。与传统问答式交互不同,Study 模式采用苏格拉底式引导教学法,通过提问、提示与自我反思,引导学生循序渐进地理解知识,而非直接给出答案。OpenAI 教育副总裁 Leah Belsky 表示:“当 ChatGPT 被用作教学或辅导工具时,能显著提升学业成绩;若仅用作答案机器,反而可能阻碍学习。”
该功能的设计凝聚了教育界的智慧。OpenAI 联合全球 40 余所高校与教育机构的教师、科学家和教育专家,基于长期的学习科学研究成果打造了这一模式。Study 模式支持个性化辅导、分层解答与知识检查,可根据学生水平与学习目标提供量身定制的教学方案,并通过历史对话记忆持续优化学习体验。
目前该功能仍处于早期阶段,OpenAI 计划根据用户反馈迭代升级,未来将加入可视化教学、目标设定与进度追踪等功能。虽然学生可随时切换回常规模式获取直接答案,但在普林斯顿、沃顿等高校的试点中,多数学生反馈 Study 模式让学习过程更有趣、更高效,实现了真正的“授人以渔”。
10|神秘模型 Horizon Alpha 横空出世,疑似 GPT-5 测试版本
7 月 30 日,一个名为 Horizon Alpha 的神秘大模型突然现身 OpenRouter 平台,没有官方发布、无任何技术文档,开发者身份也完全匿名。在 EQ-Bench 评测中,该模型以 1570.9 的高分登顶榜首,在创意写作、情感推理等多个维度几乎满分。更令人瞩目的是,它支持 256K 上下文、多模态处理,推理速度高达 150 tokens/秒,并且当前阶段完全免费开放测试。
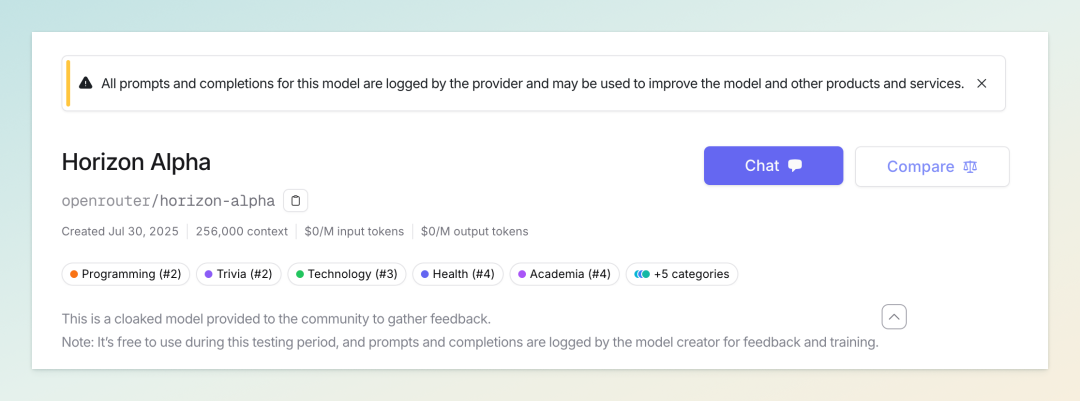
技术社区迅速对这位“隐形冠军”的真实身份展开讨论,最有力的猜测直指 OpenAI。当被询问来源时,模型直接回应:“I’m an OpenAI language model (GPT-4 class)… I was created by OpenAI。”此外,OpenAI 曾多次在 OpenRouter 进行秘密测试,GPT-4.1 也曾以“Quasar Alpha”代号低调上线。
尽管 Horizon Alpha 在创意生成和编程任务上表现出色,但在部分逻辑与数学“陷阱题”上意外失误,显示出能力分布不均衡。这种特性暗示它可能是一个针对特定任务优化的实验版本,而非完整的通用旗舰。业界普遍认为,Horizon Alpha 很可能是 OpenAI 即将发布的开源模型或 GPT-5 的早期测试版本,为即将到来的下一代产品发布埋下伏笔。
11|谷歌 Gemini 2.5 Deep Think 上线,开启“并行思考”时代
8 月 1 日,谷歌正式向 Gemini Ultra 订阅用户推出 Gemini 2.5 Deep Think 模型,标志着 AI 推理迈入“并行思考”新阶段。Deep Think 能够在生成答案时同时考虑多个想法,并动态修改或组合不同思路,最终得出更优解。这种多智能体式的并行推理虽然对算力要求更高,但性能提升极为显著 —— 在 Humanity’s Last Exam(HLE)测试中取得 34.8% 的成绩,超越 xAI 的 Grok 4(25.4%)和 OpenAI 的 o3(20.3%)。

谷歌采用了差异化发布策略:付费用户可体验经过优化的“青铜版”,每日使用次数有限;而在国际数学奥林匹克竞赛(IMO)中斩获金牌的完整版则仅向少数数学家和学术界开放。在 LiveCodeBench 编程测试中,该模型得分从 5 月的 80.4% 提升至 87.6%,在迭代开发与复杂系统设计方面表现尤为突出。
此外,Deep Think 原生整合了代码执行与 Google 搜索等工具,能生成更长、更具深度的响应,特别适合需要创造力、战略规划和逐步优化的复杂任务。谷歌计划在未来几周内,通过 Gemini API 向可信测试者提供包含和不包含工具的双版本,进一步探索企业级与开发者应用场景。
12|Ollama 桌面版正式上线,macOS 与 Windows 一键运行本地大模型
7 月 31 日,本地大模型运行工具 Ollama 正式推出 macOS 与 Windows 桌面应用,让用户无需依赖命令行即可便捷运行大语言模型。全新应用提供直观的聊天界面,支持一键下载并运行包括 DeepSeek-R1、Llama 3.3、Gemma 3 等主流开源模型,大幅降低了本地 AI 的使用门槛。

新版桌面应用功能亮点包括:
-
文档处理更便捷:支持拖放文本与 PDF 文件,用户可将上下文长度调至 128K tokens,以处理大型文档; -
多模态支持:基于全新多模态引擎,可向 Gemma 3等模型发送图像进行分析; -
代码友好:支持处理代码文件,辅助模型理解与生成相关文档; -
网络访问与存储灵活:可将本地模型暴露至局域网供其他设备访问,并支持自定义模型存储目录,方便迁移至外部硬盘等存储位置。
macOS 版本已实现原生化,启动速度更快,安装包体积显著缩小;而偏好命令行的用户仍可通过 GitHub 获取独立 CLI 版本。
13|马斯克宣布推出虚拟男友 Valentine,Grok Heavy 用户可抢先体验
8 月 1 日,马斯克在社交平台发帖表示,将很快向 Grok Heavy 订阅用户推出两项全新功能:AI 视频生成器 Imagine 和 AI 虚拟男友 Valentine 测试版。Grok Heavy 是 Grok 的最高级订阅服务,每月收费 300 美元(约合人民币 2161 元),相比 SuperGrok 订阅新增 Grok 4 新功能预览权限,并支持最大 256K tokens 的上下文长度。

Valentine 是继 “Ani”(哥特风动漫少女)和 “Bad Rudy”(粗鲁红熊猫)之后推出的第三款 AI 伴侣角色。其形象为忧郁黑发男性,灵感来源于《暮光之城》的 Edward Cullen 和情色小说《五十度灰》的 Christian Grey,名字取自科幻小说《异乡异客》主角。与此同时,Imagine 功能基于 Aurora 引擎,可通过文本提示生成带声音的视频内容,预计将在 10 月面向 SuperGrok 用户开放测试。
业内分析认为,高价虚拟男友服务的推出,意味着马斯克及 xAI 正正式进军女性向 AI 陪伴市场。这不仅彰显了 xAI 在情感 AI 领域的野心,也折射出 AI 伴侣正在成为科技巨头角逐的新兴赛道。
14|Anthropic 将对 Claude 实施每周使用限制,平衡资源与高负载
7 月 29 日,人工智能公司 Anthropic 宣布,将自 8 月 28 日起对 Claude Pro(月费 20 美元)和 Claude Max(月费 100-200 美元)订阅服务实施新的每周使用量限制。这一举措主要针对极少数“极限用户” —— 包括长期 24/7 不间断运行 Claude Code 的用户,以及违反使用政策进行账号共享或转售访问权限的用户。Anthropic 表示,此次调整预计仅影响不到 5% 的订阅者。
新的使用额度将根据订阅级别分级:
-
Pro 用户:每周可使用 Claude Sonnet 4约 40-80 小时; -
Max(100 美元/月)用户:每周可获得 140-280 小时的 Sonnet 4和 15-35 小时的Opus 4; -
Max(200 美元/月)用户:每周可享有 240-480 小时的 Sonnet 4和 24-40 小时的Opus 4。
随着 Claude Code 推出后需求激增,过去一个月内该服务已出现至少 7 次部分或重大故障,计算资源极度紧张。业内人士指出,在 AI 编程工具爆发式增长的背景下,如何在保障服务稳定性与防止资源滥用之间取得平衡,正成为各大厂商亟待解决的难题。对于超出限额的 Max 用户,Anthropic 还提供按标准 API 费率购买额外使用量的选项,以在维护服务稳定性的同时保持一定商业灵活性。
15|Black Forest Labs 开源 FLUX.1 Krea dev,专注照片级写实文生图
Black Forest Labs 联合 Krea AI 正式发布全新开源文生图模型 FLUX.1 Krea dev,专为照片级写实场景打造,旨在解决传统文生图常见的“AI 感”问题。作为一款 120 亿参数的整流流变换器模型,它通过独特的美学训练方法,实现了更加真实、自然且多样化的图像生成,有效避免过饱和或过度平滑的纹理失真,这是文生图领域的长期难题。
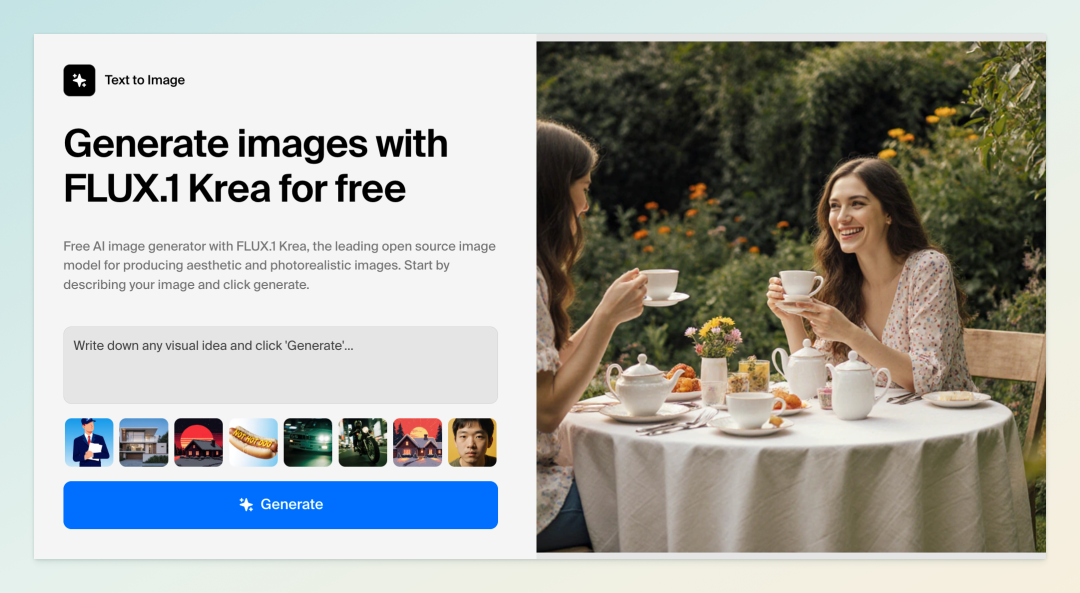
FLUX.1 Krea dev 的最大特色是“有主见”(opinionated)—— 它不追求全能,而是专注于特定视觉美学的极致优化。在人类偏好评估中,该模型不仅全面超越以往开源文生图模型,甚至可与闭源的 FLUX1.1 [pro] 等高级模型媲美。
在技术与生态上,FLUX.1 Krea dev 与 FLUX.1 [dev] 系列完全兼容,可作为下游应用定制的灵活基础模型。模型权重现已在 Hugging Face 开源,商业授权可通过 BFL 官方许可门户获取,同时 FAL、Replicate、Runware 等合作伙伴提供便捷的在线 API 接入,进一步推动了视觉 AI 生成技术的普惠与开放。
我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。
(文:AI信息Gap)