

这两天,通义千问团队接连更新开源进展,推出Qwen3系列的两项重要成果:Qwen3-Coder-480B-A35B-Instruct 与 Qwen3-235B-A22B-Instruct-2507 。前者以代码生成与代理能力为核心目标,后者则是旗舰版Qwen3模型——Qwen3-235B-A22B instruct模式(Non-thinking)的更新版本。
模型链接
Qwen3-Coder-480B-A35B-Instruct
https://www.modelscope.cn/models/Qwen/Qwen3-Coder-480B-A35B-Instruct
Qwen3-235B-A22B-Instruct-2507
https://modelscope.cn/models/Qwen/Qwen3-235B-A22B-Instruct-2507
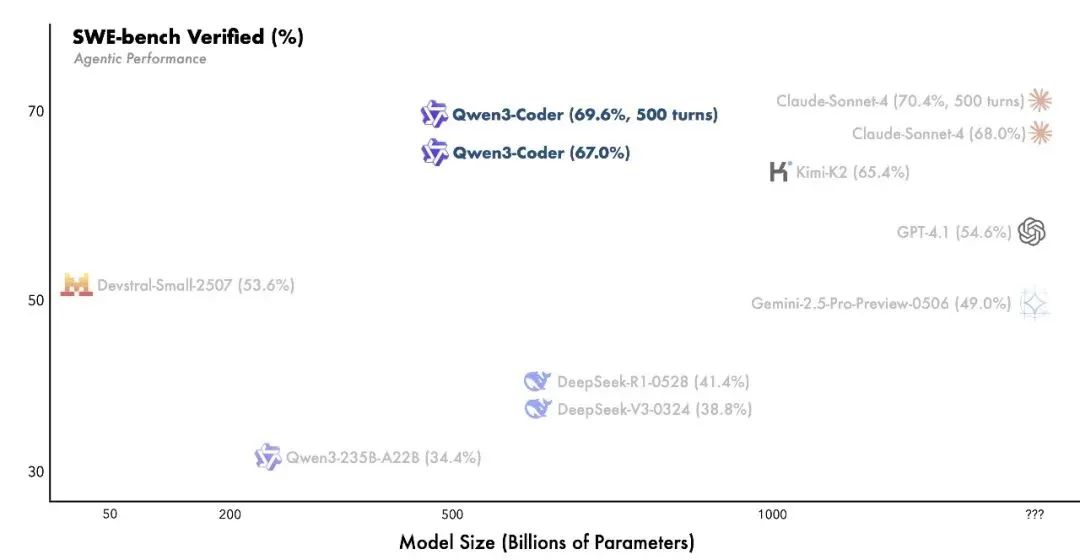
作为Qwen3系列中最具代理能力的代码模型,Qwen3-Coder通过多维度技术扩展实现了代码生成与工具调用的突破,其核心版本Qwen3-Coder-480B-A35B-Instruct 采用480B参数总量、35B激活参数的MoE架构,原生支持256K上下文长度(通过YaRN可扩展至1M),在Agentic Coding、Browser-Use和Tool-Use等任务中达到开源模型的SOTA水平,表现接近Claude Sonnet4。
Qwen3-Coder通过预训练与后训练的协同优化强化模型能力。预训练阶段,团队构建了包含7.5T数据(代码占比70%)的混合语料库,并利用Qwen2.5-Coder清洗低质数据生成高质量合成样本;同时,针对仓库级代码任务(如Pull Request处理)优化长上下文建模能力。后训练阶段则引入Code RL 与Long-Horizon RL 双技术路径:前者通过自动化扩展测试样例实现执行驱动的强化学习,在提升代码执行成功率的同时反哺其他任务;后者依托阿里云基础设施搭建20k并行验证环境,通过多轮交互解决SWE-Bench等长周期任务,最终在SWE-bench Verified中取得开源模型最优成绩。
此外,Qwen团队还开源了配套工具Qwen Code ,其基于Gemini Code二次开发,通过Prompt工程与工具调用协议适配,最大化Qwen3-Coder在代理式编程场景下的表现。该模型还可与Claude Code、Cline等工具集成,推动“Agentic Coding in the World”的落地实践。
以下是一些使用Qwen3-Coder生成的交互Demo:
太阳系轨迹模拟
打字练习
DUET游戏界面
Qwen3-235B-A22B-Instruct-2507:旗舰通用模型的长文本与多任务优化
作为Qwen3系列的旗舰通用模型,Qwen3-235B-A22B-Instruct-2507 延续了Qwen3-235B-A22B的非思考模式(Non-Thinking)架构设计,但针对关键指标进行了系统性优化。该模型保持94层深度、分组查询注意力(GQA, Q=64, KV=4)及MoE结构(128专家,激活8专家),总参数量235B(激活22B),非嵌入参数占比达234B。其原生支持262,144 tokens上下文长度,为复杂长文本任务提供底层支持。
💡 值得注意的是,该模型仅支持非思考模式,输出不包含标记,且无需手动指定enable_thinking=False,进一步简化了部署流程。
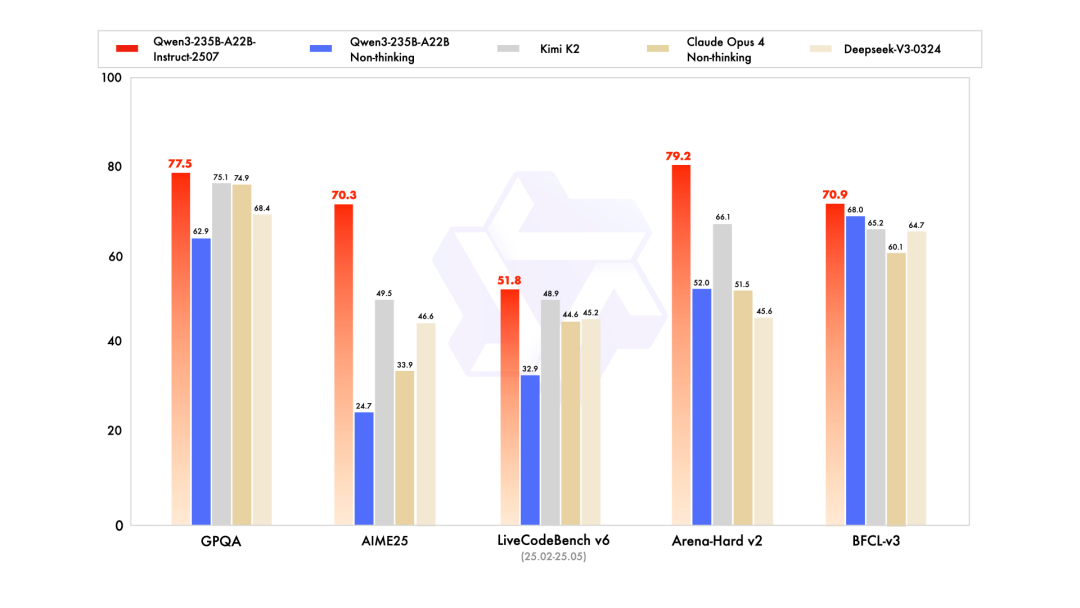
研究团队通过预训练与后训练双阶段范式进一步提升模型性能。在GPQA(知识)、AIME25(数学)、LiveCodeBench(编程)等评测中,该模型超越Kimi-K2、DeepSeek-V3等开源模型 及 Claude-Opus4-Non-thinking等闭源模型。具体优化方向包括:
-
多语言长尾知识覆盖 :通过数据增强提升低频语言与领域的泛化能力;
-
用户偏好对齐 :在主观任务中增强回复有用性与文本质量;
-
长文本建模 :将上下文理解能力扩展至256K tokens,优化复杂场景下的推理连贯性。
模型实战教程
模型推理
Qwen3-Coder-480B-A35B-Instruct-FP8
-
vLLM
VLLM_USE_MODELSCOPE=True vllm serve Qwen/Qwen3-Coder-480B-A35B-Instruct-FP8 \--enable-expert-parallel \--data-parallel-size 8 \--enable-auto-tool-choice \--tool-call-parser qwen3-coder
Qwen3-235B-A22B-Instruct-2507
-
SGLang
SGLANG_USE_MODELSCOPE=true python -m sglang.launch_server --model-path Qwen/Qwen3-235B-A22B-Instruct-2507 --tp 8 --context-length 262144
-
vLLM
VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3-235B-A22B-Instruct-2507 --tensor-parallel-size 8 --max-model-len 262144
模型微调
我们介绍使用ms-swift集成的megatron & LoRA对Qwen3-235B-A22B-Instruct-2507进行自我认知微调。你需要准备8卡80GiB的显卡资源。ms-swift是魔搭社区官方提供的大模型与多模态大模型训练部署框架。
ms-swift开源地址:https://github.com/modelscope/ms-swift
在开始微调之前,请确保您的环境已准备妥当。对megatron相关依赖的安装可以查看megatron-swift训练文档(可直接使用镜像):https://swift.readthedocs.io/zh-cn/latest/Instruction/Megatron-SWIFT%E8%AE%AD%E7%BB%83.html
git clone https://github.com/modelscope/ms-swift.gitcd ms-swiftpip install -e .
微调数据集准备格式如下(system字段可选),在训练脚本中指定`–dataset <dataset_path>`即可。
{"messages": [{"role": "user", "content": "浙江的省会在哪?"}, {"role": "assistant", "content": "浙江的省会在杭州。"}]}
1. HF格式的权重转为Megatron格式,并测试转换精度:
# 8 * 80GiB# 若要测试转换精度,请设置`--test_convert_precision true`,注意这需要1.3T内存资源CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \swift export \--model Qwen/Qwen3-235B-A22B-Instruct-2507 \--to_mcore true \--torch_dtype bfloat16 \--output_dir Qwen3-235B-A22B-Instruct-2507-mcore
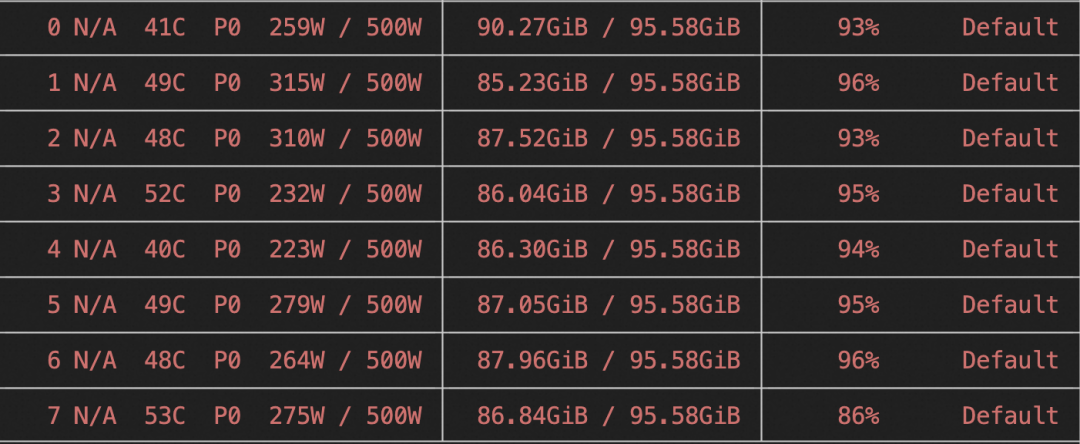
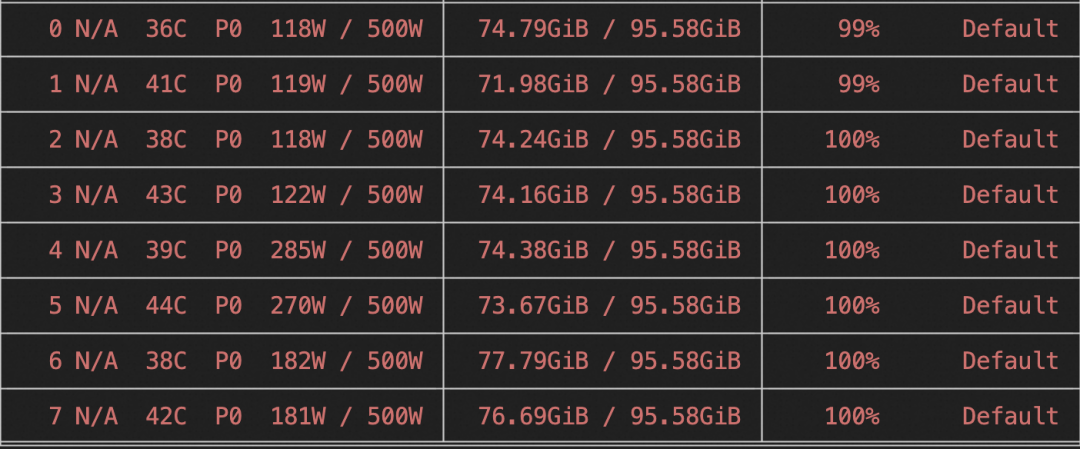
2. 对Qwen3-235B-A22B-Instruct-2507-mcore进行自我认知微调(全参数训练)。在8卡H20上所需显存资源为:8 * 90GiB,训练速度为3.5s/it。
# 显存占用:8 * 90GiB# 训练速度:3.5s/itPYTORCH_CUDA_ALLOC_CONF='expandable_segments:True' \NPROC_PER_NODE=8 \CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \megatron sft \--load Qwen3-235B-A22B-Instruct-2507-mcore \--dataset 'swift/Chinese-Qwen3-235B-2507-Distill-data-110k-SFT#2000' \'swift/self-cognition#1000' \--train_type lora \--lora_rank 8 \--lora_alpha 32 \--target_modules all-linear \--split_dataset_ratio 0.01 \--expert_model_parallel_size 8 \--moe_grouped_gemm true \--moe_shared_expert_overlap true \--moe_aux_loss_coeff 1e-3 \--micro_batch_size 2 \--global_batch_size 16 \--recompute_granularity full \--recompute_method uniform \--recompute_num_layers 1 \--max_epochs 1 \--finetune true \--cross_entropy_loss_fusion true \--lr 1e-4 \--lr_warmup_fraction 0.05 \--min_lr 1e-5 \--save megatron_output/Qwen3-235B-A22B-Instruct-2507 \--eval_interval 200 \--save_interval 200 \--max_length 2048 \--num_workers 8 \--dataset_num_proc 8 \--no_save_optim true \--no_save_rng true \--sequence_parallel true \--attention_backend flash \--model_author swift \--model_name swift-robot
训练显存占用:
训练日志:
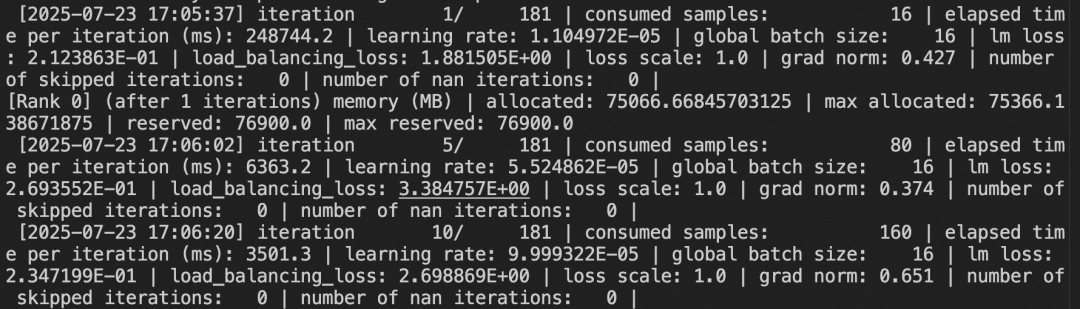
如果你需要在8卡 80GiB显存资源下跑起来,可以使用以下配置:
# 显存占用:8 * 78GiB# 训练速度:9.5s/itPYTORCH_CUDA_ALLOC_CONF='expandable_segments:True' \NPROC_PER_NODE=8 \CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \megatron sft \--load Qwen3-235B-A22B-Instruct-2507-mcore \--dataset 'swift/Chinese-Qwen3-235B-2507-Distill-data-110k-SFT#2000' \'swift/self-cognition#1000' \--optimizer_cpu_offload true \--use_precision_aware_optimizer true \--train_type lora \--lora_rank 8 \--lora_alpha 32 \--target_modules all-linear \--split_dataset_ratio 0.01 \--expert_model_parallel_size 2 \--pipeline_model_parallel_size 4 \--decoder_first_pipeline_num_layers 23 \--decoder_last_pipeline_num_layers 23 \--moe_grouped_gemm true \--moe_shared_expert_overlap true \--moe_aux_loss_coeff 1e-3 \--micro_batch_size 8 \--global_batch_size 16 \--recompute_granularity full \--recompute_method uniform \--recompute_num_layers 1 \--max_epochs 1 \--finetune true \--cross_entropy_loss_fusion true \--lr 1e-4 \--lr_warmup_fraction 0.05 \--min_lr 1e-5 \--save megatron_output/Qwen3-235B-A22B-Instruct-2507 \--eval_interval 200 \--save_interval 200 \--max_length 2048 \--num_workers 8 \--dataset_num_proc 8 \--no_save_optim true \--no_save_rng true \--sequence_parallel true \--attention_backend flash \--model_author swift \--model_name swift-robot
3. 将Megatron格式权重转为HF格式,并测试转换精度:
# 8 * 80GiBCUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \swift export \--mcore_adapters megatron_output/Qwen3-235B-A22B-Instruct-2507/vx-xxx \--to_hf true \--torch_dtype bfloat16 \--output_dir megatron_output/Qwen3-235B-A22B-Instruct-2507/vx-xxx-hf
4. 训练完成后,使用以下命令进行推理:
# 8*80GiBCUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \swift infer \--model output/vx-xxx/checkpoint-xxx \--infer_backend vllm \--stream true \--temperature 0 \--vllm_tensor_parallel_size 8 \--vllm_max_model_len 8192 \--max_new_tokens 2048

5. 推送模型到ModelScope:
swift export \--model output/vx-xxx/checkpoint-xxx \--push_to_hub true \--hub_model_id '<your-model-id>' \--hub_token '<your-sdk-token>'
(文:路过银河AI)