

最近大家应该都被OpenAI和谷歌的内部模型获得IMO2025金牌的消息刷屏了,但是正式参赛的公开的模型03high,Gemini 2.5 pro等表现很差,连铜牌都没拿到,不过现在又有了一个新情况
刚刚发布在arXiv上的研究论文《Gemini 2.5 Pro Capable of Winning Gold at IMO 2025*》证明Gemini 2.5 Pro本体通过适当提示就可以获得IMO 2025金牌
论文地址:
https://arxiv.org/pdf/2507.15855
该论文由加州大学洛杉矶分校的杨林(UCLA 电子与计算机工程系副教授)和黄溢辰撰写,详细阐述了他们如何利用谷歌最新的Gemini 2.5 Pro模型,成功解决了6道2025年国际数学奥林匹克(IMO)竞赛题目中的5道,达到了IMO金牌得主水平

核心方法
该研究的真正创新之处,在于设计了一套由两个核心角色解题者和验证者构成的自我验证流水线。这两个角色均由Gemini 2.5 Pro扮演,但通过截然不同且高度特化的提示词(Prompt)来引导,使其各司其职,形成了高效的协作与迭代机制
流水线流程如下图所示:
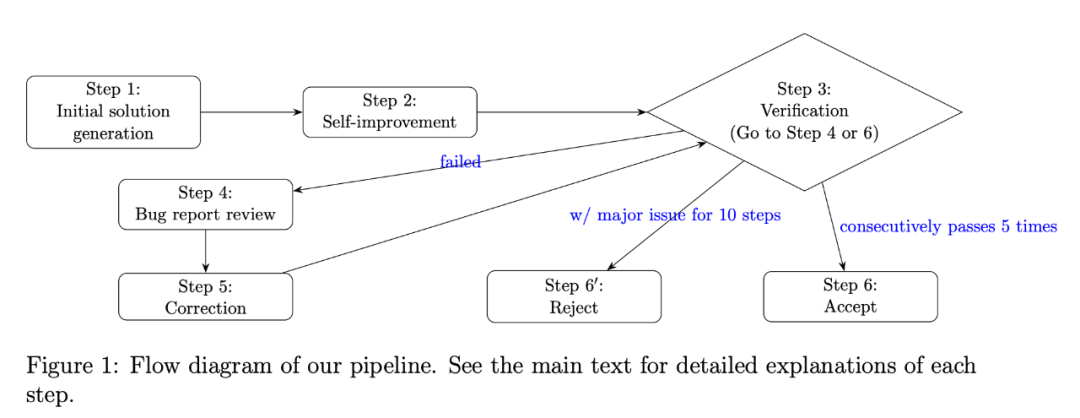
初始解题 : 模型首先尝试对问题进行解答。作者发现,由于IMO问题的复杂性,模型的首次尝试往往不完美,甚至存在错误
自我改进 : 模型被提示审视并改进自己的初步解答,相当于进行第一轮反思
严格验证 : 引入一个验证器角色(同样由Gemini 2.5 Pro扮演)。验证器会逐行审查解答,生成一份详细的错误报告,将问题分为关键错误(如逻辑谬误)和论证缺陷如步骤跳跃、缺乏足够论证)
修正与迭代:解题模型根据验证器提供的错误报告来修正自己的证明。修正后的版本会再次提交给验证器进行审核
接受或拒绝 :这个验证-修正的循环会持续进行。一个解答只有在连续5次通过验证器且未发现任何问题后,才会被最终接受。如果一个方案在10轮迭代后仍存在重大问题,则被拒绝
提示词设计
解题者提示词:强调严谨与诚实
解题者的目标是生成初步的数学证明。研究者为其设计的提示词,旨在根除大型语言模型常见的幻觉和走捷径的弊病。核心指令包括:
严谨性至上 : 提示词明确要求:你的首要目标是产出完整且严格论证的解法。解题的每一步都必须逻辑上无懈可击且解释清晰。一个从有缺陷或不完整的推理中得出的正确答案,将被视为失败。 这条指令将模型的重心从得出答案转移到了构建严谨的证明过程。
对完整性的诚实:这是对抗模型编造内容的关键。提示词指示:如果你找不到完整的解法,你绝不能猜测或创造一个看似正确但包含隐藏缺陷或论证空白的解法。相反,你应该只呈现你能够严格证明的重要部分成果。这使得模型在遇到困难时,会选择回退到可靠的、已证明的子结论,而不是强行完成整个证明
结构化输出 :要求模型必须按照摘要和详细解法的格式输出。摘要部分又必须包含对解题结果的定论(例如我成功解决了问题或我未能找到完整解法,但我严格证明了……),以及一个方法草图。这种格式强迫模型在输出最终答案前,进行一次自我评估和梳理
验证者提示词:精细化的错误诊断
当解题者完成一次尝试后,验证者登场。它的任务不是解题,而是像一位经验丰富的竞赛评委一样,对证明进行逐行审查。其提示词设计得更为精妙:
角色定位:你是一位IMO级别的专家数学家和一丝不苟的评分人。你的唯一任务是严格验证所提供的数学解法
非建设性审查:明确指示你必须扮演验证者,而非解题者。不要尝试修正你发现的错误或填补空白。这确保了验证过程的客观性
创新的错误分类系统:这是整个方法论的点睛之笔。验证者被要求将发现的问题分为两类,并按不同规则处理:
a.关键错误 : 指的是逻辑谬误或计算错误,这类错误会直接破坏证明链条。一旦发现,验证者会指出错误,并停止对该条推理后续步骤的检查,但会继续检查证明中其他独立的部分(例如,证明题设的另一种情况)
b.论证缺陷 :指的是结论可能正确,但论证过程过于简略、想当然或缺乏足够严谨性。处理这类问题时,验证者会指出论证的不足,然后假设这一步的结论是正确的,并继续检查后续的证明是否在逻辑上成立。这种方法极具价值,因为它能评估即使在某个局部存在瑕疵的情况下,整个证明的宏观结构是否依然稳固
我把论文里的提示词整理了一下,完整提示词如下:

生成-验证-修正”闭环
通过这套双提示词系统,研究建立了一个迭代循环:
解题者根据强调严谨和诚实的提示词生成证明
验证者根据精细化的诊断提示词,对证明进行审查,并输出一份结构化的错误报告
解题者接收这份报告,并针对性地修正自己的证明
修正后的版本再次进入验证环节,如此循环往复,直至证明连续多次通过验证,没有任何瑕疵
数据污染?
评估大型语言模型能力时,一个核心挑战是数据污染——即测试数据可能已存在于模型的训练集中,导致评估结果虚高
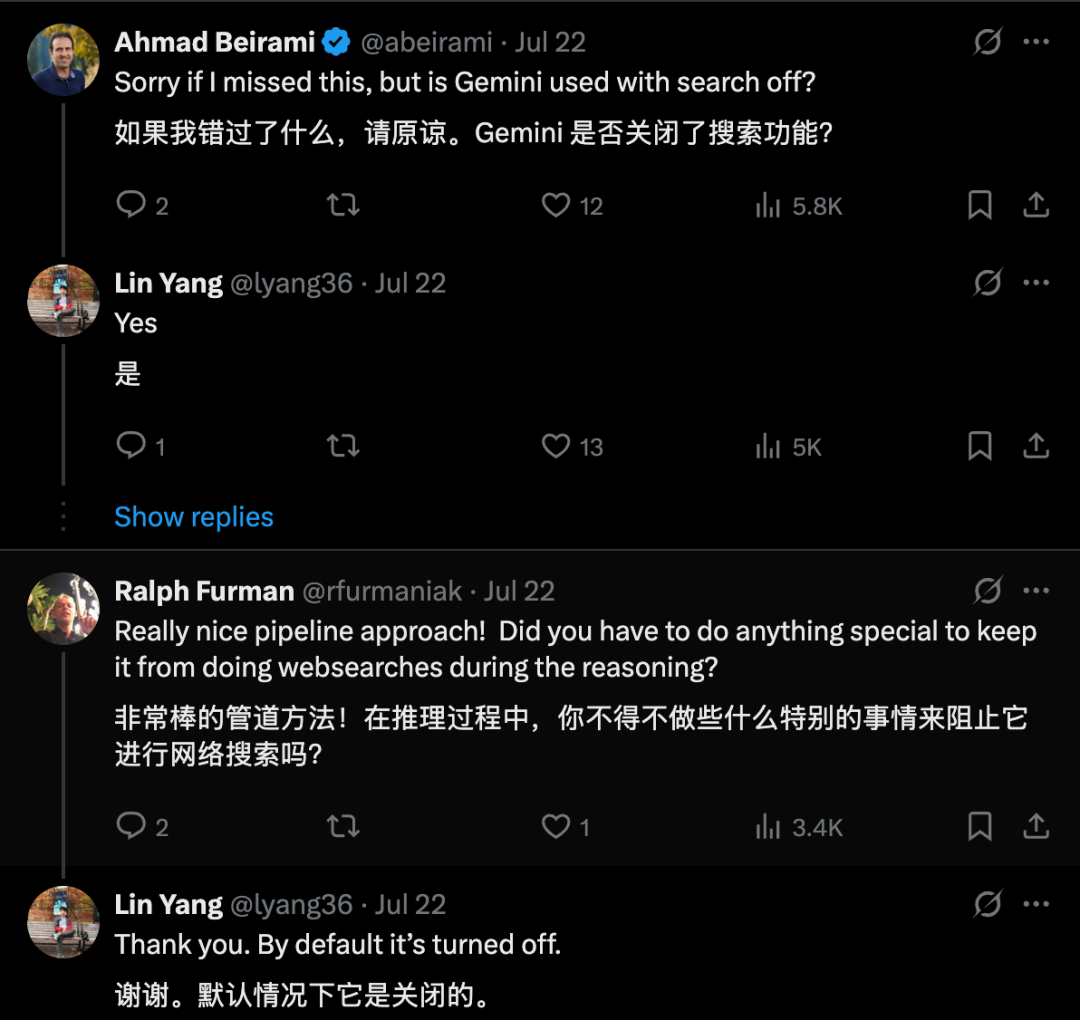
为了规避这一问题,研究团队专门使用了刚刚发布的2025年IMO竞赛题目进行测试。由于这些题目是在评估前几天才公布的,可以确保模型此前从未见过它们,从而提供了一个纯净的测试环境,真实地反映了Gemini 2.5 Pro的泛化和原创性解题能力
另外论文作者的回应,也没有开启网络搜索功能
结果是否可验证?
通过上述方法,作者宣称Gemini 2.5 Pro成功地为IMO 2025的前5道题提供了完整且严谨的证明。
问题1(组合数学)和问题2(几何): 研究人员在使用模型解题时,额外加入了一句提示,分别建议尝试归纳法和解析几何。他们认为,这两种方法是解决此类问题的通用策略,一个先进的多智能体系统本就会分配智能体去探索这些路径,因此这并不算提供捷径,而更像是节约计算资源。模型在处理几何问题时尤其得心应手,被认为是6道题中最简单的一道
问题3(数论): 团队通过20次采样和迭代改进,成功获得严谨解。这展示了其迭代方法相比于纯粹暴力采样的更高效率
问题4和问题5 也被成功解决
问题6: 模型未能解决,只给出了一个平凡的上界
综合来看,解决6道题中的5道,结果请看论文,文章中有详细过程
解题过程和结果正确性得到了手动验证
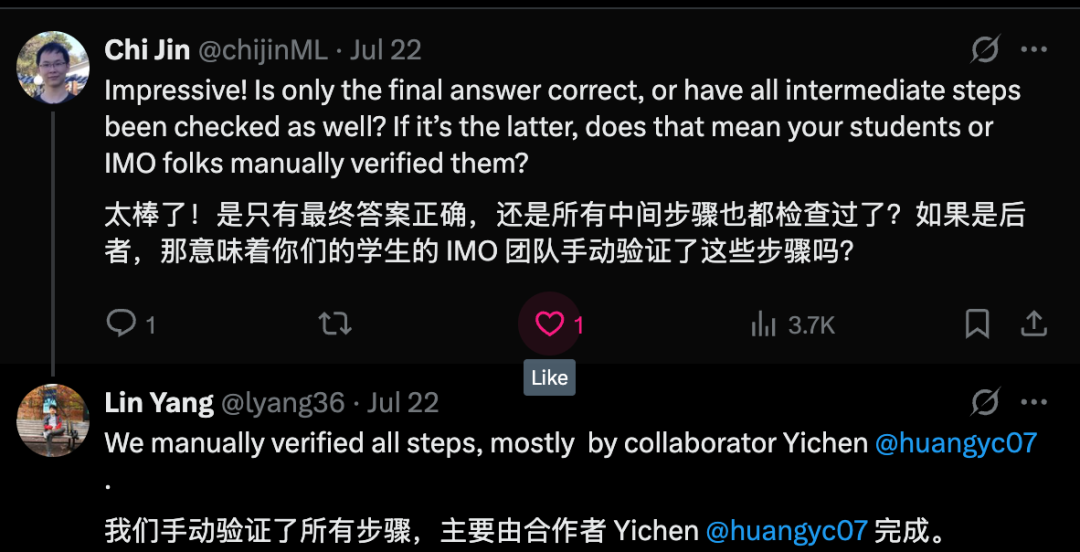
但是目前这个结果只是他们自我报道,还没有的到IMO组委会的认可
参考:
https://arxiv.org/pdf/2507.15855
(文:AI寒武纪)