


极市导读
本文提出仅用32个一维离散 token 的高度压缩 TiTok tokenizer,无需训练额外生成模型,仅通过测试时梯度优化即可直接完成图像生成、编辑、修复等任务,并发现压缩越极致生成质量越好,颠覆传统“先压缩后生成”范式。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

Highly Compressed Tokenizer Can Generate Without Training
代码:https://github.com/lukaslaobeyer/token-opt
论文:https://arxiv.org/abs/2506.08257
目录
-
引言
-
理解一维分词器
-
方法论
-
潜在空间分析
-
测试时优化
-
主要发现
-
应用
-
局限性与未来工作
-
重要性
引言
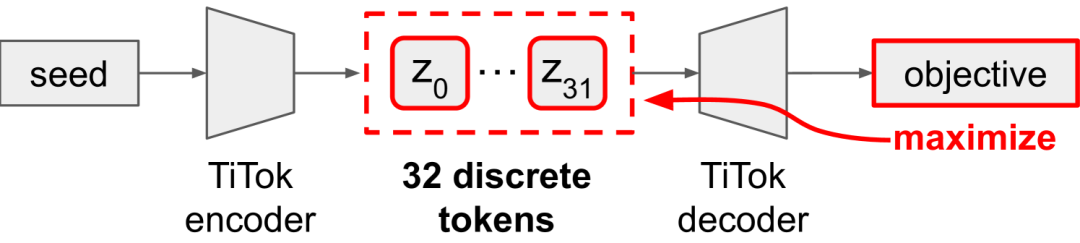
所提出的方法通过基于梯度的测试时优化,对32个离散标记进行优化,无需训练独立的生成模型即可完成各种图像生成任务。
传统的图像生成流程包含两个主要组成部分:一个将图像压缩为潜在表示的标记器(tokenizer),以及一个学习生成新标记序列的生成模型。这篇由麻省理工学院和Meta FAIR的Beyer等人撰写的论文挑战了这一范式,通过证明高度压缩的一维标记器无需单独训练的生成模型即可生成图像。
这项研究基于TiTok(一维标记器)架构,该架构将图像表示为仅32个离散标记的序列——与通常生成数百或数千个以空间网格排列的标记的传统二维标记器相比,这是一个极高的压缩比。作者提出,随着标记器实现更高的压缩比,其解码器必须变得越来越复杂,可能发展出固有的生成能力。
理解一维分词器
一维和二维标记器之间的区别是这项工作的核心。传统的二维标记器,如VQGAN中使用的,会生成空间排列的标记网格,从而保留局部图像结构。相比之下,TiTok等一维标记器学习将整个图像表示为没有固定空间排列的序列,允许每个标记捕获更多的全局信息。
TiTok架构使用Vision Transformer (ViT)编码器来处理图像块,并通过向量量化(VQ)步骤生成离散标记。然后解码器从这32个标记重建完整的图像。这种极致的压缩迫使解码器学习丰富的表示,能够从最少的信息中重建复杂的视觉内容。
方法论
作者采用系统方法,通过两种主要策略来研究TiTok标记器的生成能力:直接潜在空间操作和基于梯度的优化。
潜在空间分析
研究人员首先通过检查不同标记位置与高级图像属性的关系,分析了一维标记空间的语义结构。他们根据语义属性(例如,“动物 vs. 无生命物体”、“白天 vs. 夜晚场景”)对ImageNet验证数据集进行划分,并计算了每个标记位置的重要性指标,以识别哪些标记携带有关特定属性的信息。
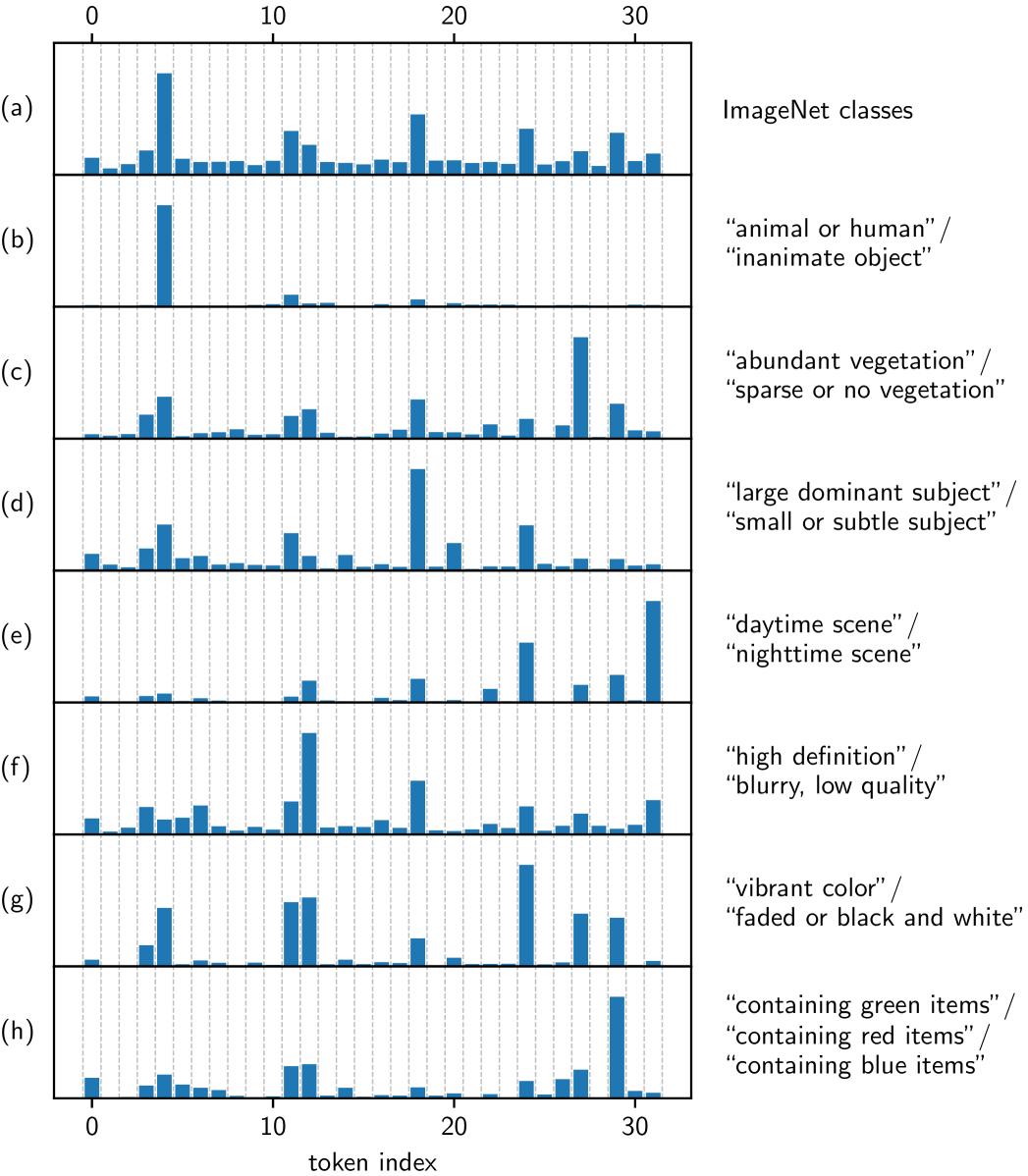
分析表明,特定的标记位置编码了不同的语义属性,例如主体类型、植被密度和图像质量。
这项分析揭示了标记位置之间显著的语义解耦,特定的标记始终编码着特定的全局属性,如场景光照、图像锐度和主体类型。
测试时优化
基于这些见解,作者开发了一个基于梯度的优化框架,该框架迭代地完善标记表示,以满足任意目标函数。优化在向量量化步骤之前对连续特征向量进行操作,使用直通估计器(straight-through estimator)将梯度反向传播通过离散标记。
一般的优化过程包括:
-
初始化 token(可以来自种子图像或随机初始化)
-
计算目标函数相对于 token 特征的梯度
-
使用 Adam 优化器更新 token
-
应用各种正则化技术(注入噪声、L2 正则化、指数移动平均)
主要发现
压缩提高生成质量
一个反直觉但至关重要的发现是,增加压缩显著提高了生成质量。TiTok-LL-32 模型(32 个 token,4096 个码本大小)始终优于具有更多 token 或更大码本的变体。这表明,极致压缩迫使分词器学习更强大和更具泛化能力的表示。
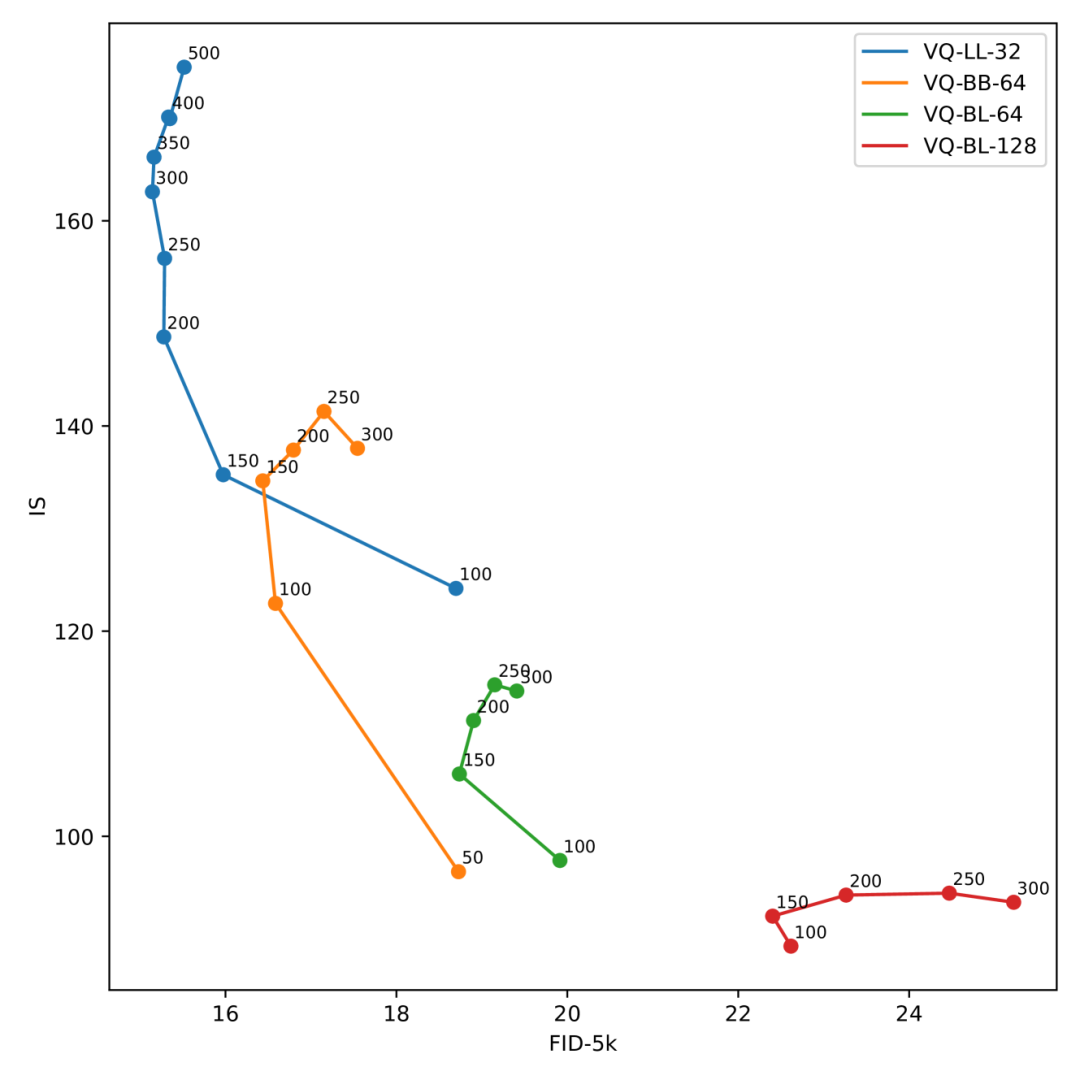
向量量化至关重要
作者发现,向量量化提供的离散潜在空间对于良好的生成性能至关重要。连续 VAE 变体表现明显更差,这表明离散瓶颈对生成过程起到了关键的正则化作用。
1D 与 2D 分词器
该方法在使用标准 2D 分词器(如 MaskGIT 的 VQGAN)时未能成功,这突出表明 1D 分词的独特特性——特别是高度压缩的全局信息编码——是该方法成功的根本。
应用
文本引导图像编辑
该框架通过优化 token 以最大化 CLIP 与文本提示的相似性,实现了灵活的文本引导图像编辑。从种子图像开始,优化可以转换主体,同时保留姿势和构图等结构元素。

复制粘贴编辑
语义解耦实现了潜在空间中直观的“复制粘贴”编辑,其中可以将来之参考图像的 token 直接复制到目标图像,以转移照明或图像质量等特定属性。

图像修复
该方法通过优化 token 以最小化未遮蔽区域的重建损失来处理图像修复,并进行周期性的“token 重置”以保持与已知图像部分的连贯性。

无条件生成
即使没有种子图像,该方法也可以通过从随机初始化的 token 开始并针对文本提示或其他目标进行优化,生成多样化、逼真的图像。
局限性与未来工作
尽管该方法作为一种无需训练的方法取得了有竞争力的结果,但它仍有局限性。极致压缩可能会限制对细粒度细节的控制,并且该方法需要仔细调整优化超参数。作者承认绝对生成质量并未超越最先进的专用生成模型,但强调了在无需训练的情况下实现生成这一概念的重要性。未来的工作可以探索扩展到更高的压缩比,研究替代优化策略,并将该方法扩展到自然图像以外的其他领域。
意义
这项工作代表了图像生成思维的范式转变,证明了表示学习和生成之间的传统分离可能是人为的。通过展示高度压缩的标记器具有固有的生成能力,该研究为高效、灵活的图像生成系统提出了新的方向。实际意义包括降低部署的计算要求,通过语义解耦提高可解释性,以及通过即插即用的目标函数增强灵活性。这项工作为基础模型开辟了新的研究方向,其中单一的、超压缩的表示作为理解和生成任务的通用主干。极度压缩不仅没有阻碍反而提高了生成质量的发现挑战了传统观念,并表明强制模型学习最大程度压缩的表示可能是开发更强大、更通用的视觉人工智能系统的关键。
(文:极市干货)