
CogDDN团队 投稿
量子位|公众号QbitAI
让机器人像人一样边看边理解,来自浙江大学和vivo人工智能实验室的研究团队带来了新进展。

正如视频所展示的,机器人在复杂的室内环境中不仅能自主探索,还具备理解指令背后的意图,灵活调整行为的强大能力。
而这一能力的核心就来自他们在ACM MM 2025上发表的新框架—CogDDN。这是首个模拟人类认知机制,将心理学著名的“双过程理论”应用于移动机器人的需求驱动导航任务(Demand-driven navigation,DDN)的系统。

论文的共同第一作者为浙江大学博士生黄跃豪和vivo人工智能实验室算法专家刘亮,通讯作者为浙江大学教授刘勇与研究员吕佳俊。
研究动机
随着科技的不断发展,移动机器人逐渐走进人们的日常生活,成为家庭、医院、仓库中的得力助手。为了让机器人更加高效地工作,它们不仅需要执行指令,还应具备理解人类需求的能力——例如,当人们感到饥饿时,机器人能够主动根据这一需求(我饿了)去寻找食物,而不是被动等待包含明确目标(例如拿一根香蕉)的指令。
然而,传统的需求驱动导航方法依赖大量数据训练,往往只能应对“见过的情况”。一旦面对陌生环境或模糊的指令,机器人便容易陷入困境。
为了解决这一问题,研究团队开始探索更具通用性的导航方法:让机器人像人一样具备“推理能力”,能够灵活应对未知情境,真正理解人类的意图。
人类在面对需求时,通常不会立即做出决定,而是通过不断试探和调整来逐步明确目标。这种灵活的决策过程启发了一些研究,通过引入丹尼尔 · 卡尼曼 (Daniel Kahneman)的“双过程理论”来模拟人类思维:系统1代表快速、直觉式的决策系统,系统2代表缓慢但深度推理的系统。
这两种思维模式的结合,有望帮助机器人在复杂环境中做出更合理的导航决策。
基于“双过程理论”的需求驱动导航框架
基于上述动机,团队提出了一个认知驱动的双过程闭环导航框架——CogDDN。该框架构建于视觉语言模型(VLM)之上,具备持续学习、适应和自我改进的能力。该框架将双过程决策模块分为启发式过程(系统1)与分析过程(系统2),以实现快慢系统一体化的设计,模拟了人类在不同情境下的决策方式。
其中,启发式过程依赖已有经验,进行快速、直觉式的高效决策;而分析过程则聚焦于错误反思,通过深度推理持续优化策略。

在闭环导航实验中,分析过程不断积累经验,构建可迁移的知识库,包含高质量的决策信息。这些知识不仅可适应不同场景,还可通过微调迁移至启发式过程,为后续决策提供支持与增强。
在AI2-THOR模拟器上,基于ProcTHOR数据集的闭环评估结果表明,CogDDN的表现相比当前单视角SOTA方法DDN提高了15%,且与加入深度输入的InstructNav效果相当。
CogDDN框架介绍
如下图所示,CodDDN由3部分组成:
- 用于检测物体的3D机器人感知模块;
- 用于确定目标物的需求匹配模块;
- 由分析过程和启发式过程组成的双过程决策模块。
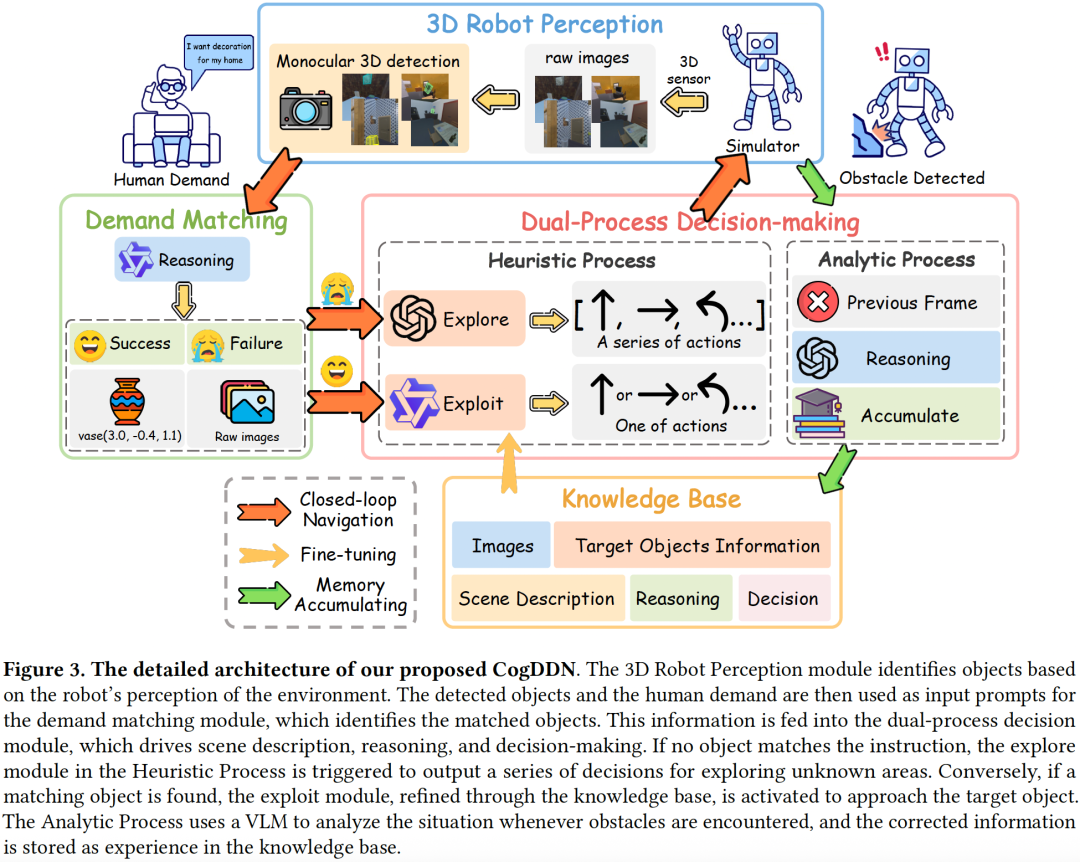
3D机器人感知模块
为了提高机器人在室内导航中的三维感知能力,团队采用了当前最先进的单目3D检测方法——UniMODE。该方法通过单一视角的图像,精准地估算物体的三维位置,避免了传统方法对多视角或深度传感器的依赖。
需求匹配模块
在需求驱动导航中,满足相同人类需求的物体通常具有共同的关键特性。例如,画作、盆栽和雕塑都适合用来装饰空间,因为它们可以提升视觉效果,营造所需的环境氛围。这种人类需求与物体特性之间的关系是基于普遍的知识。
大型语言模型(LLM)擅长根据指令和物体特性进行推理,但当无法精确匹配请求时,LLM可能会推荐一些不太合适的物体。例如,如果用户要求“需要一个东西来放我的花”,它可能会推荐一个杯子,尽管它并不是最理想的选择。这种倾向会大大降低模型在选择最合适物体时的准确性。
为了避免这个问题,团队采用了有监督微调(SFT)技术来训练LLM,使其更好地将物体与用户需求对齐,从而在无法精确匹配时避免推荐不合适物体。通过微调后的LLM,系统能够更精准地处理复杂指令和物体特性,即使在模糊场景中,也能提供更合理的建议。

双过程决策
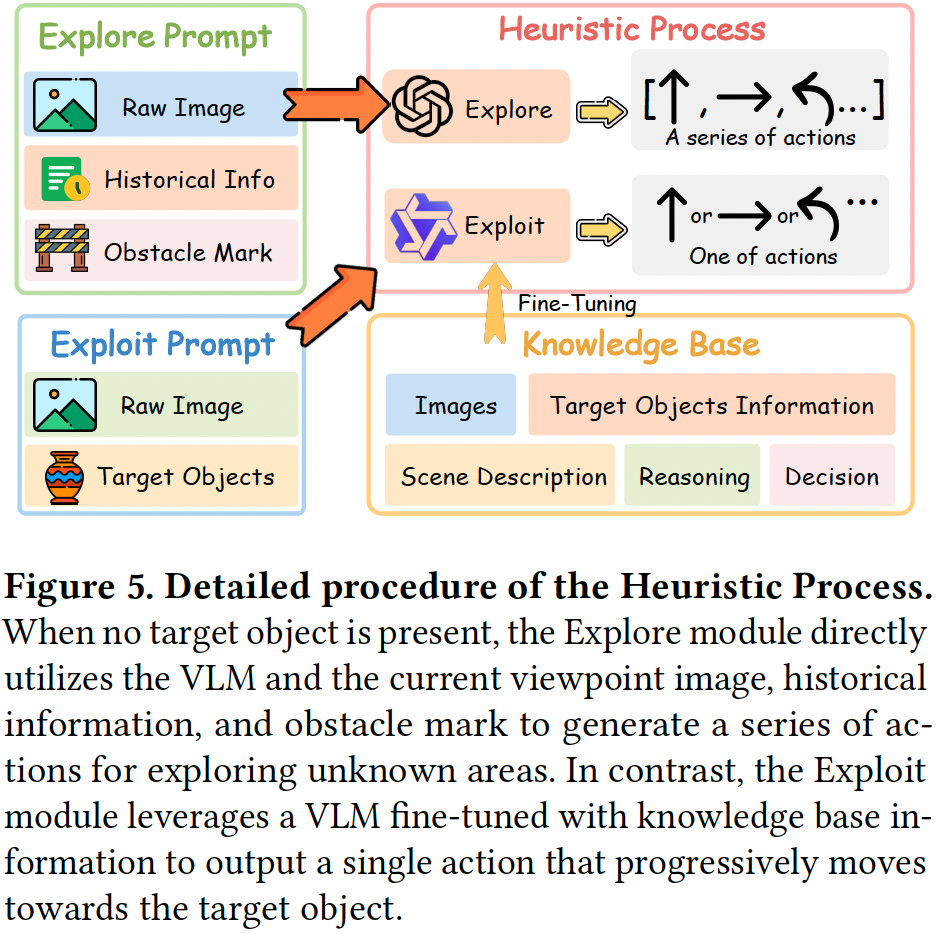
启发式过程
在室内导航中,传统系统往往受到处理速度慢和信息冗余的限制,导致在实际应用中表现不佳。为了解决这些问题,团队引入了启发式过程,它就像是CogDDN的“直觉”,通过模拟人类的导航方式,并通过不断练习和积累经验,能够快速适应各种情况,从而提高导航效率。
启发式过程包括两个模块:Explore和Exploit,两者都依赖思维链(CoT)来适应新环境并优化导航执行。
当无法找到合适目标时,Explore模块会启动。此时,系统通过生成探索性动作扫描环境,寻找可能被忽视的物体或路径。它根据当前视角生成场景描述并进行推理,指导探索过程。系统会结合之前的行动和旋转信息,优化探索路径,避免重复的探索。
一旦目标物体被找到,Exploit模块启动,专注于采取精准的行动实现导航目标。在这一阶段,系统利用探索阶段积累的经验和知识库,借助有监督微调(SFT),就像把知识内化为直觉,使其更好地应对各种情境。系统对环境进行细致推理,生成最适合的行动,快速而有效地达成目标。
这种双重决策机制使得CogDDN能够快速适应新环境,并高效完成复杂的导航任务,大幅提升了机器人在动态环境中的智能决策能力。
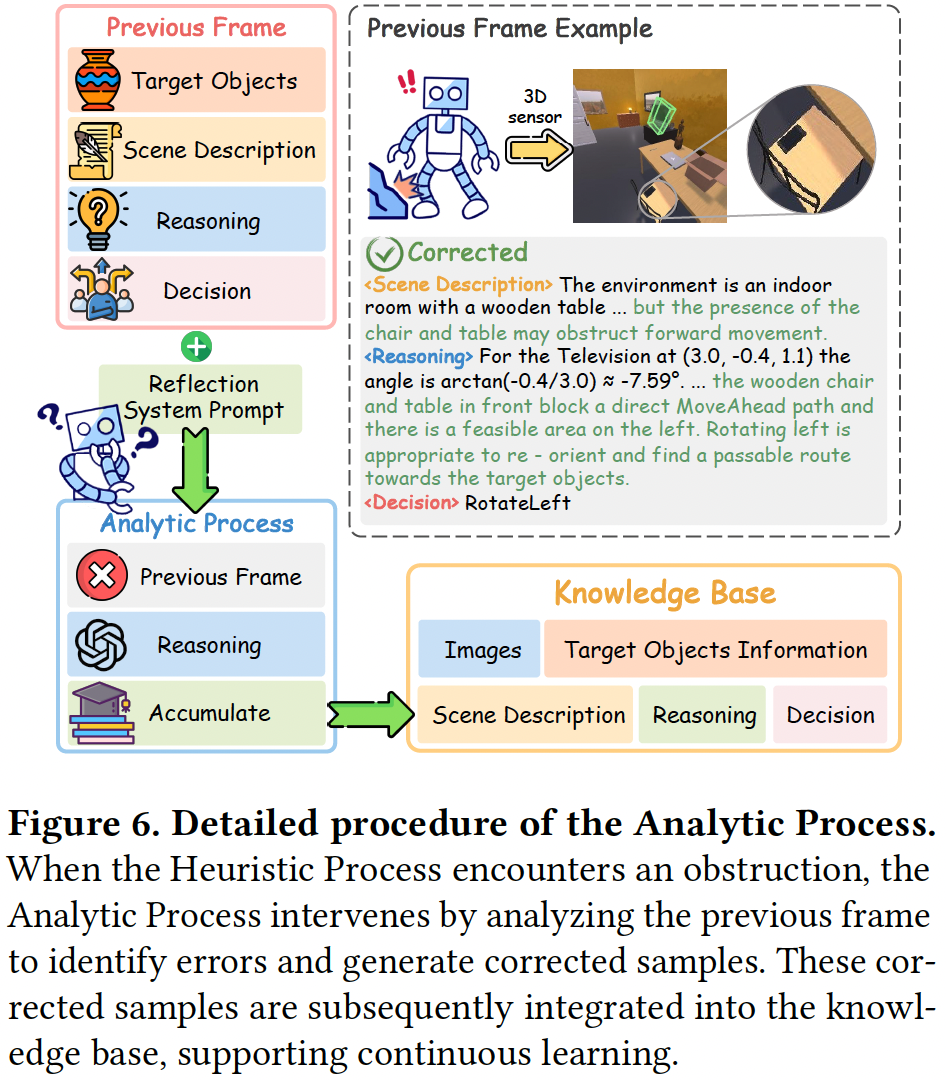
分析过程
分析过程是CogDDN的“大脑”,类似于人类的理性思维,帮助系统反思导航中的障碍,并不断优化决策以应对复杂的导航挑战。
通过在多个数据集上广泛预训练,视觉语言模型(VLM)积累了丰富的世界知识,具备强大的推理和洞察能力。这使得分析过程能够在室内导航中进行深入的分析和情境理解,从而得出准确的推论。
在闭环室内导航场景中,当需求匹配和启发式过程模块正常运作时,任何遇到的障碍都会触发反思机制。分析过程利用VLM中积累的知识,基于障碍发生前收集的信息进行分析,包括物体的位置、场景描述、推理和决策。
系统通过这一过程深入分析问题根源,识别错误并生成修正后的推理和决策。所得的经验会被整合到知识库中,使系统能够从失败中不断学习。
通过这种迭代学习,CogDDN不断提升决策能力,使系统在未来的导航任务中做出更精准、更明智的决策,从而持续优化导航策略。
实验结果
团队在开源仿真器AI2Thor使用Procthor数据集进行闭环实验,以评估CogDDN的性能。为了验证有效性,团队在400个场景中进行了闭环导航的综合评估。团队的评估指标包括导航成功率(NSR)、加权路径长度的导航成功率(SPL)和选择成功率(SSR)。
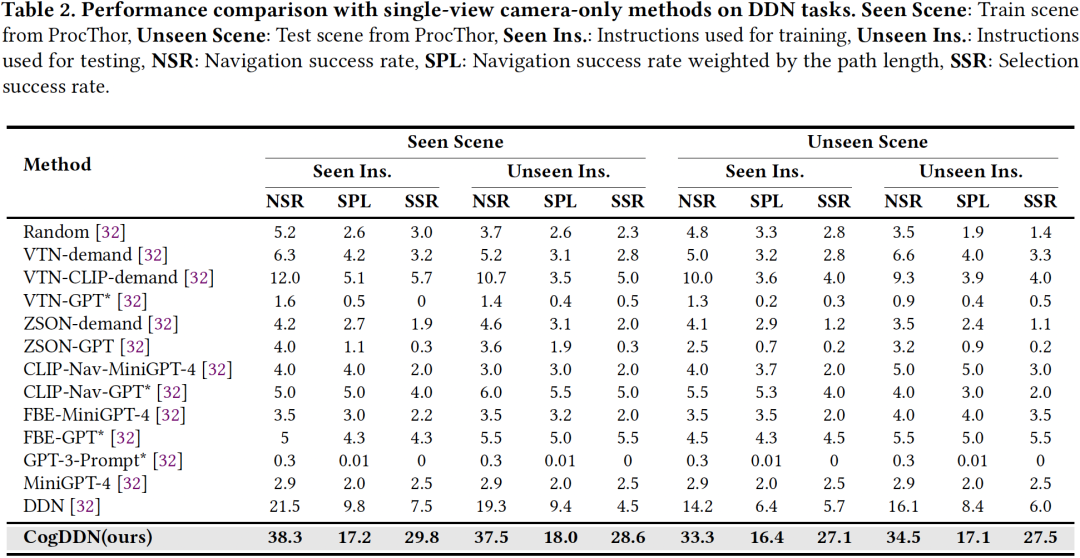
如表2所示,CogDDN优于所有其他仅依赖前向视角相机传感器输入的方法。
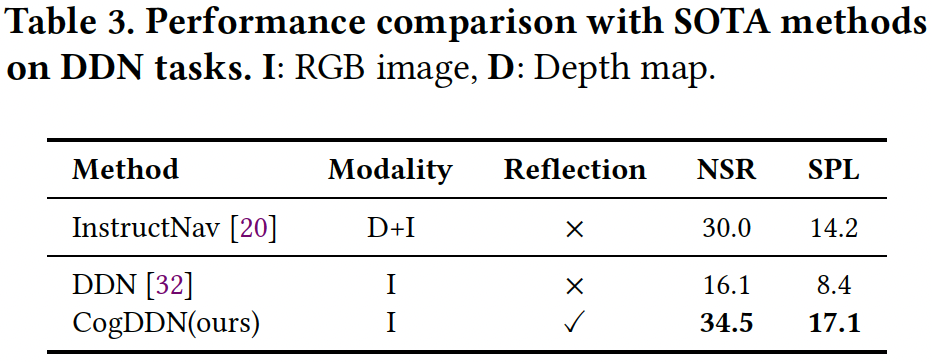
此外,CogDDN与SOTA方法InstructNav的比较也展示了令人瞩目的成果。尽管InstructNav利用深度图作为额外输入,CogDDN仍在未见场景和指令中表现出相当的性能,证明了其在多种复杂场景中的适应性与高效性。
团队还进行了消融实验,验证了CogDDN各模块的作用。
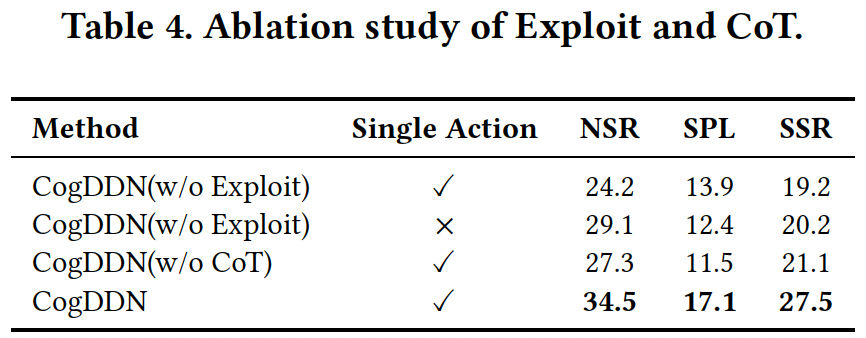
实验结果表明,移除Exploit模块后,系统性能显著下降,突显了微调的重要性。
同样,去除CoT后,系统在复杂决策中的推理能力大幅减弱,证明了CoT对决策过程的关键作用。
此外,反思机制的消融实验进一步验证了CogDDN的持续学习能力。在每轮500个epoch的训练中,系统通过反思积累经验并微调VLM,将其添加到知识库中。
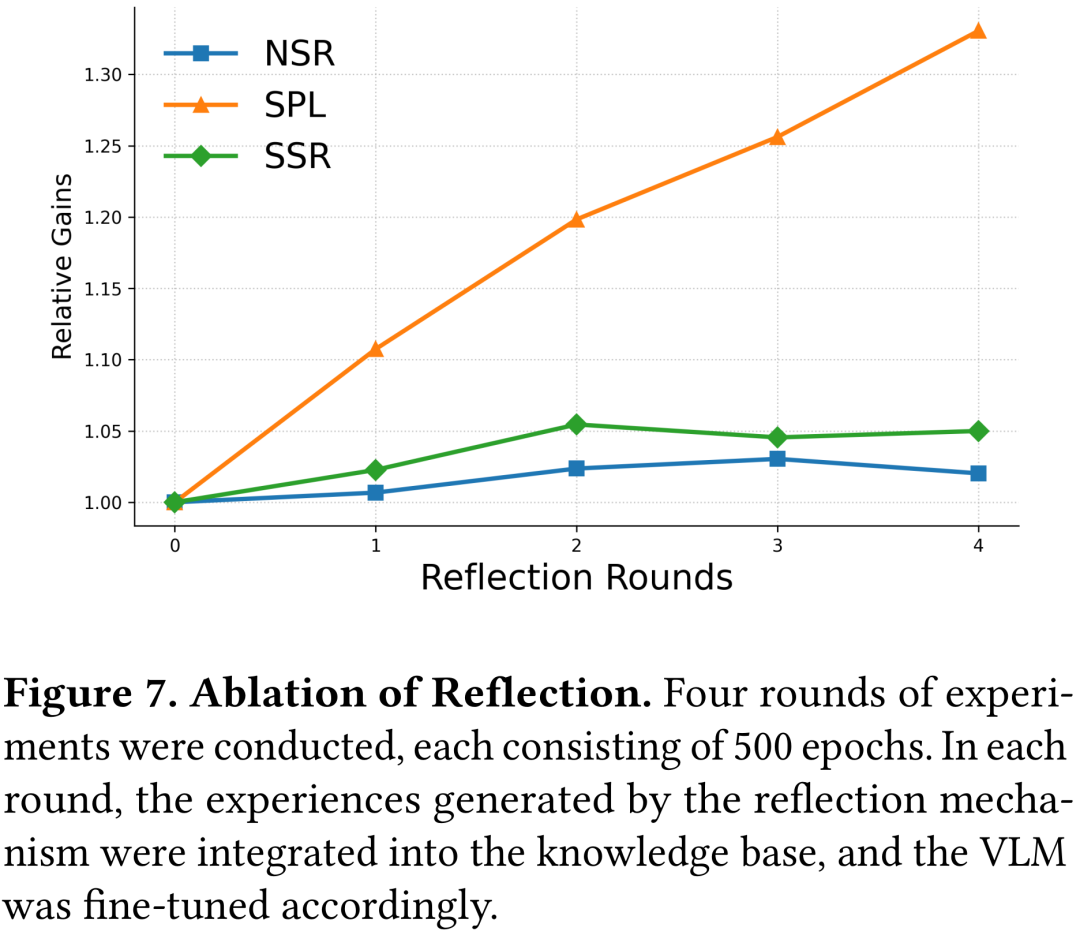
通过图7可以看到,SPL显著提升。该实验表明,反思机制有效提高了系统在遇到障碍后的表现,进一步证明了CogDDN在持续学习和适应新环境方面的强大能力。
总结
CogDDN是一款认知驱动的导航系统,具备持续学习、灵活适应与自我优化能力,仿佛赋予机器人一颗“思考的大脑”。
受人类注意力机制启发,CogDDN能精准聚焦任务相关的关键物体,简化环境信息,从而提升决策效率。系统采用双过程决策机制:
一方面通过快速、直觉式的启发式决策,实现高效响应;
另一方面依赖深度推理与分析,完成复杂情境下的判断。
两者协同运行,使机器人在复杂环境中也能灵活应对。此外,CogDDN能在闭环过程中持续积累经验,优化策略,并可无缝集成至现有机器人系统中。
其独特的双过程能力,使其在需求驱动导航任务中表现出色,为智能机器人技术的发展奠定了坚实基础。
(文:量子位)