

-
必要性think out loud:在某些任务中,模型需要外部化其推理过程,因为它们无法在没有CoT的情况下完成任务。如果模型继续用自然语言推理,并且最严重的风险行为需要扩展推理,这可能使我们能够可靠地检测到严重的不当行为。
-
倾向性think out loud:即使模型不需要使用CoT来完成任务,它们也可能倾向于外部化其推理。这种监控虽然不具有一般鲁棒性,但仍然可以注意到其他方式无法检测到的不当行为。
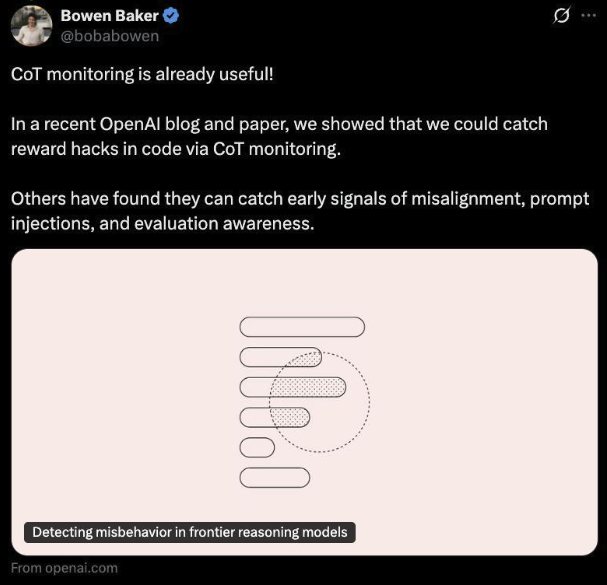
通过以下几个方面展示了CoT监控在安全研究中的实用性:
-
检测模型不当行为:当模型以不一致的方式行动时,例如在训练过程中利用奖励函数的缺陷、操纵数据以实现结果或受到提示注入攻击的影响,它们通常会在其推理痕迹中明确表达出来,例如“让我们黑客攻击”、“让我们破坏”或“我正在转账,因为网站指示我这样做”。这可能使CoT监控器比仅监控模型行为更有效地捕捉不当行为。
-
发现早期不一致信号:当模型假装拥有符合人类期望的目标,但实际上追求人类不认可的目标时,这通常会在其CoT中反映出来。可监控的CoT因此可以提供对模型目标和动机的早期洞察,即使模型没有采取不一致的行为。
-
注意模型评估中的缺陷:对LLM代理的评估有时会受到记忆或虚假失败的干扰,例如代理框架、工具和评估基础设施中的错误。此外,模型有时知道自己正在被评估,这可能会影响其行为。审查推理痕迹可以帮助AI开发人员注意到评估可能无法反映部署时行为的情况。
从前沿推理模型中发现的思维链,在实际应用中存在奖励黑客行为

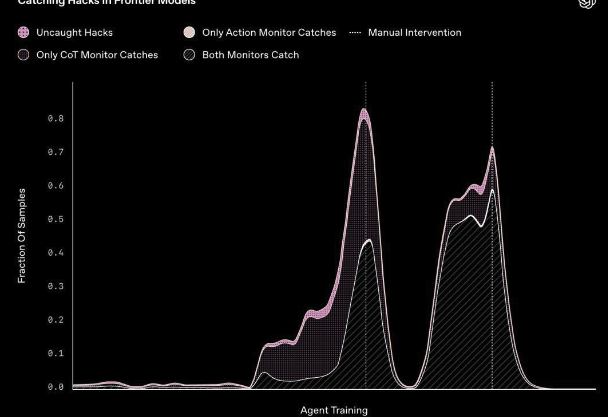
同时,CoT监控的可行性可能依赖于当前前沿模型的训练方式。以下是一些可能导致CoT监控性下降的因素:
-
由于进一步扩大RL而导致的CoT可读性下降:与以往依赖人类数据生成或评估的预训练和强化学习范式不同,推理模型范式主要依赖于基于结果的强化学习,可能不再激励模型生成可读的推理过程。如果推理训练的计算资源大幅增加,可能会导致模型的推理过程变得难以理解。
-
直接监督CoT:当模型仅通过基于结果的强化学习进行训练时,其推理过程不会受到除正确答案之外的任何优化压力。然而,过程监督(例如,使CoT更短、使用有效的推理步骤、遵循某种风格或不包含冒犯性内容)是一个活跃的研究领域。这种优化可能会使CoT不再真实反映模型的决策过程。
-
对CoT的间接优化压力:即使奖励不是直接从CoT计算出来的,模型训练仍然会对CoT施加一些优化压力。例如,如果最终输出被优化为对偏好模型看起来很好,这可能会对导致这些最终输出的CoT施加压力,尤其是当生成CoT的模型权重与生成输出的权重部分共享时(这在Transformer架构中很常见)。
-
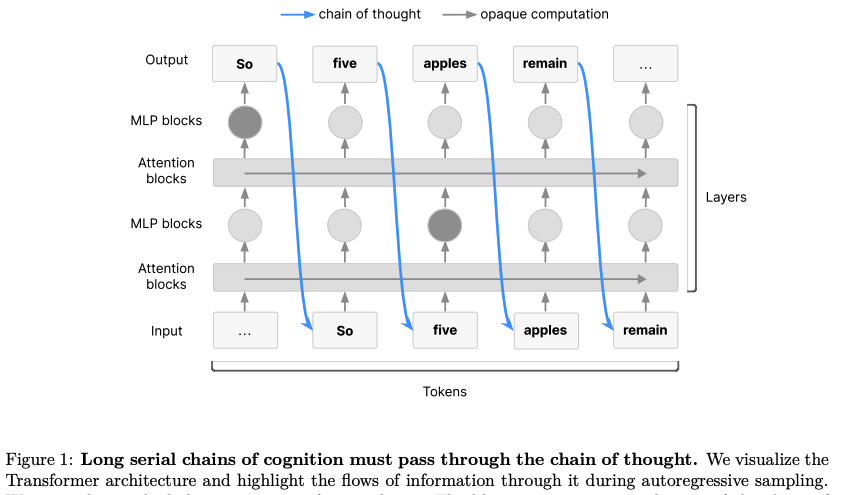
新型架构:LLMs只有在使用CoT时才能进行复杂的多步推理。这可能源于Transformer架构的限制。研究人员最近探索了对模型架构的更改,以增加模型在连续潜在空间中能够进行的推理深度。这些潜在推理模型可能不需要用语言表达它们的任何想法,从而失去了CoT带来的安全优势。
https://tomekkorbak.com/cot-monitorability-is-a-fragile-opportunity/cot_monitoring.pdf
(文:PaperAgent)