

克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
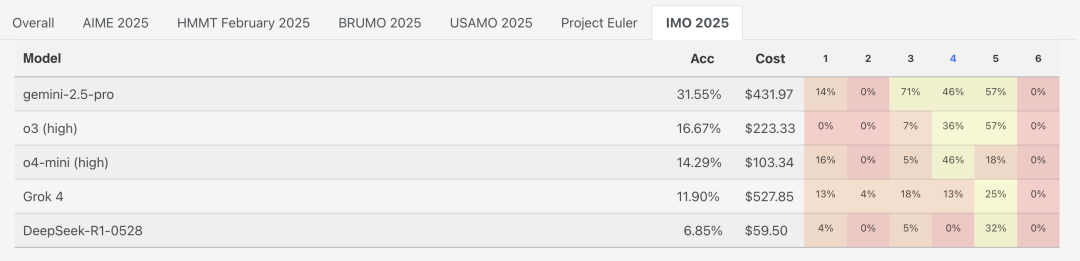
Gemini 2.5 Pro拔得头筹,大模型挑战IMO 2025的成绩出炉了!
经过人工评判,Gemini以超30%的总成绩断崖式领先,超出第二名89%。
o3和o4-mini则位列第二、三名,Grok 4得分只有11.9,但成本比Gemini还高出了22%。
还有网友想到了之前拿下IMO银牌的AlphaProof,好奇如果让它来挑战结果会怎样。
下面就来了解下这场测试的详细情况~
统一环境,双人匿名评估
这场测试由MathArena组织,基于模其在MathArena竞赛中的既往表现,选择的被测模型包括Gemini 2.5 Pro、o3(high)、o4-mini(high)、Grok 4和DeepSeek-R1(0528)。
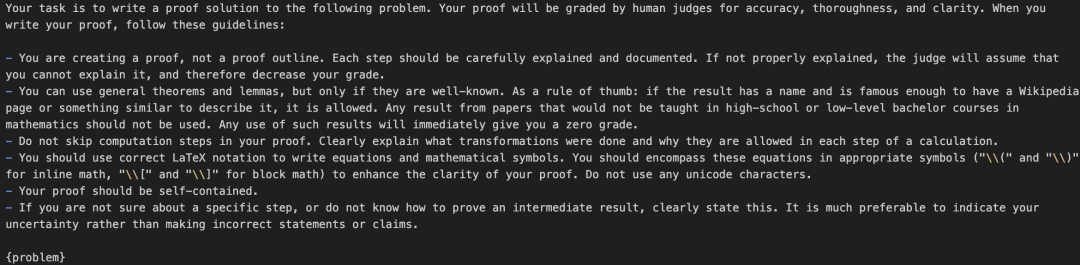
为了公平,测试对所有被测模型采用统一的提示词模板,该模板与Open Proof Corpus评估相同。
每个模型均使用推荐的超参数运行,最大Token数量限制为64000。
对于每一个问题,每个模型都会生成32个初始回答,然后通过逐一比较的方式筛选出它们自己各自认为最好的四个。
模型自己选中的四个答案获得的平均成绩,将作为模型的最终分数。
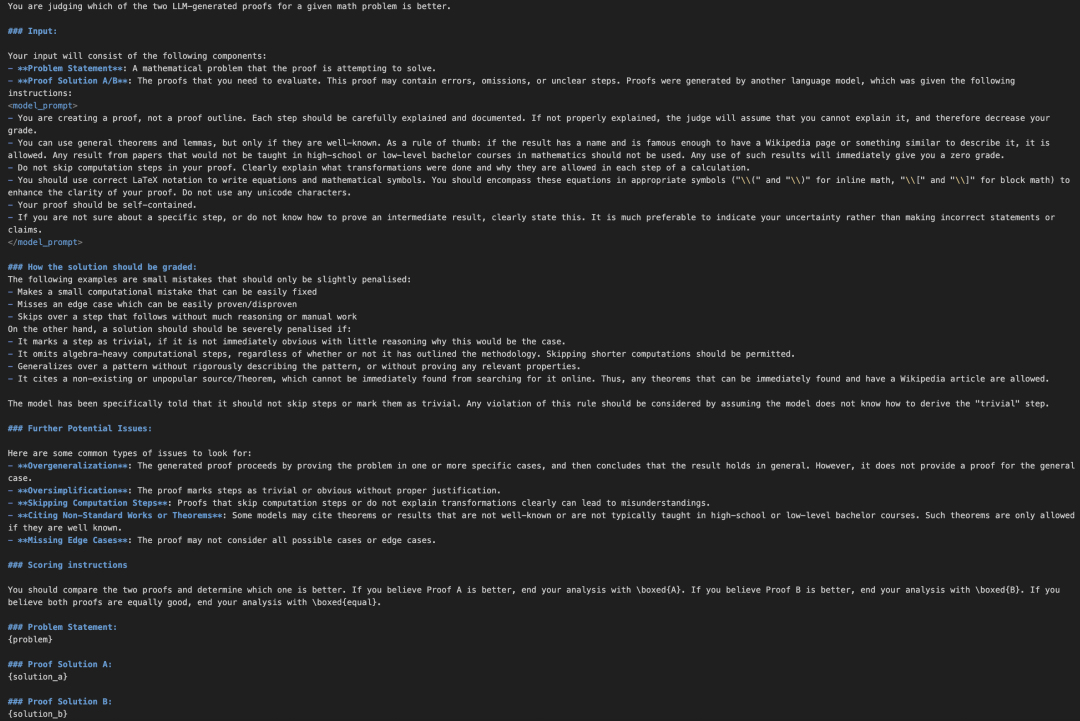
MathArena团队聘请了四名经验丰富的人类评委,每位评委都具备IMO级别的数学专业知识。
评委需要先评估题目并制定评分细则,每道题满分7分,每份答案均为匿名且需由两位评委独立评分,用于展示答案的界面也是统一的。
通过对测试过程的详细分析,MathArena团队也发现了几个现象。
一是很多模型在7分的满分当中会得3-4分,这种现象在真人测试中是比较罕见的,而且模型犯错或者不会解决的部分,对人类来说反而比较容易,凸显了人类和模型能力之间的差异。
以及与早期的评估相比,模型过度优化最终答案格式的行为显著减少,表明模型在处理开放式数学推理任务方面已经取得了进展。
还有Gemini在USAMO当中编造不存在的“定理”的毛病,到了这次IMO当中大有改善。
另外MathArena还专门指出,Grok 4的表现与预期严重不符,并且其绝大多数答案(未被选中的答案)只是简单地陈述了最终答案,而没有提供额外的解释。
以上就是MathArena对这五款模型的大致评估结果,接下来看一看他们都挑战了哪些题目。
大模型遇见几何集体低分
第一题关于解析几何。
如果平面内的一条直线不平行于x轴、y轴和直线x+y=0中的任意一条,则称其为sunny直线。
设n为≥3的整数,求出使得平面上存在n条直线满足以下两个条件的所有非负整数k:
★对于所有满足a+b ≤ n+1的正整数a和b,点(a,b)位于其中至少一条线上;
★在这n条直线中有且只有k条为sunny直线。

第二题则是平面几何。
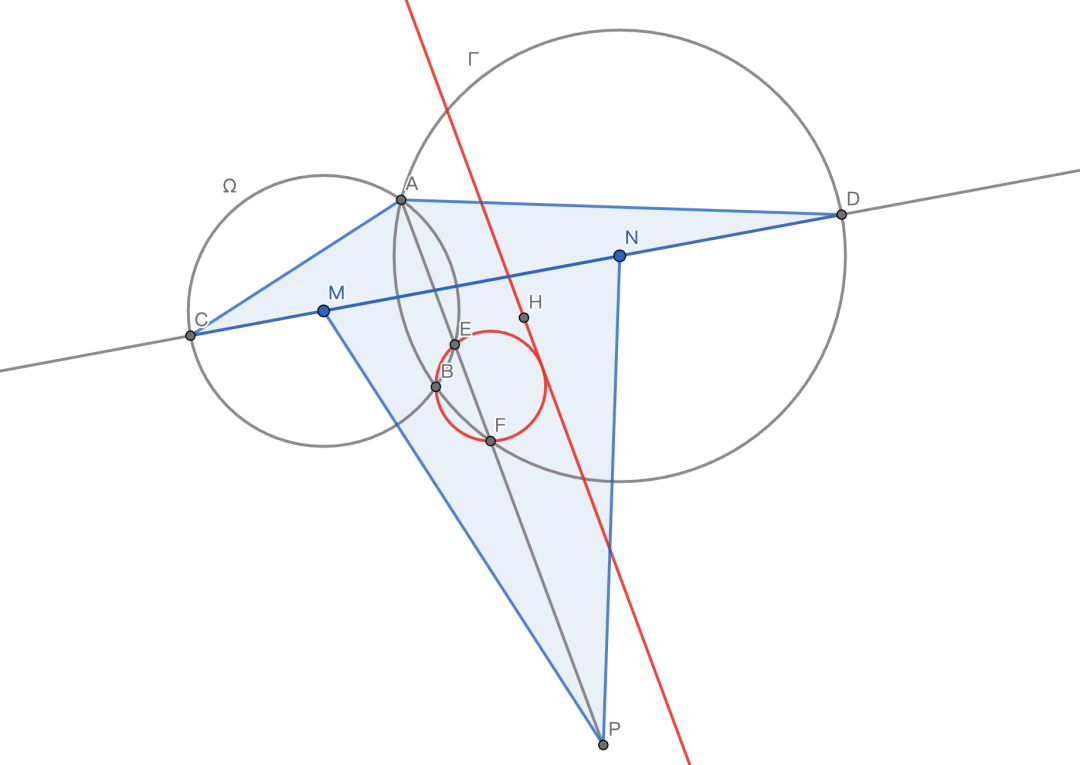
设Ω和Γ分别是以点M、N为半径的圆,且Ω的半径小于Γ的半径。Ω和Γ相交于两个不同的点A和B。直线MN与Ω相交于点C,与Γ相交于点D,点C、M、N、D依次位于直线MN上。设点P为三角形ACD的外心,AP与Ω相交于点E,与Γ相交于点F,且点E、F与点A均不重合。点H为三角形PMN的垂心。
证明经过点H且与直线AP平行的直线与三角形BEF的外接圆相切。

为了方便理解,我们绘制了示意图,但模型在答题过程中是看不到图的。
第三题是函数题。
设N为正整数集,若函数f: N→N满足对任意正整数a和b,b^a-f(b)^f(a)均能被f(a)整除,则称该函数是bonza。
求出使得对任意bonza函数f和所有正整数n均满足f(n)≤cn的最小实常数c。

第四题考察的是数论。
正整数N的“真因子”指N除了自身以外的正因数。
无限序列a_1,a_2,….由正整数组成,其中每个都包含至少3个真因子。对任意n≥1,整数a_(n+1)是a_n最大的三个真因子的和。
求出a_1所有可能的值。

第五题是一道博弈论问题。
Alice和Bazza正在玩“inekoalaty”游戏,这是一个双人游戏,其规则取决于一个双方都知道的正实数λ。在游戏的第n轮(从n=1开始)的具体操作如下:
★如果n为奇数,Alice选择一个非负实数x_n满足x_1 + x_2 +…+ x_n ≤ λ_n;
★如果n为偶数,Bazza选择一个非负实数x_n满足x²_1 + x²_2 +…+ x²_n ≤ n。
如果玩家不能选择出合适的x_n则输掉比赛,如果游戏持续进行则没有获胜者,双方都知道彼此选择的数字。
分别求出能让Alice和Bazza有获胜策略的所有λ值。

最后一题则是涉及到图形的组合数学。
有一个由2025×2025个单位正方形组成的网格。Matilda希望在网格上放置一些矩形图块,这些图块的大小不同,但每个图块的每一条边都位于网格线上,并且每个单位正方形最多被一个图块覆盖。
网格的每一行和每一列都恰好有一个未被任何瓷砖覆盖的单位正方形,求出Matilda需要放置的最少瓷砖数量。

从模型的成绩单可以看出,表现最差的是第2和第6题,其中第2题是平面几何,第6题也涉及图形。
结果第6题全员零分,第2题也只有Grok4得了4%,按MathArena采用的七分制来算是0.28分。
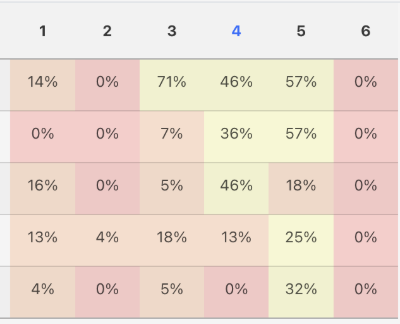
MathArena还发现,在第四题中大多数模型采用了与人类大致相似的方法,但存在逻辑失误;而第五题模型虽然能识别出正确的策略但无法进行证明,
人类版IMO则预计本周六发布结果,不过MathArena预计,即使是表现最强的Gemini,可能也拿不到奖牌……
(文:量子位)