

今天是2025年7月17日,星期四,北京,晴。
我们今天来看文档智能话题,来做技术总结。
包括文档解析技术实现范式以及多模态文档理解两个细分方向。
关注其中不同细节信息的对比,会很有收获。
一、文档解析技术实现及数据集总结
文档解析这块目前讲过很多了,《Document Parsing Unveiled: Techniques, Challenges, and Prospects for Structured Information Extraction》,https://arxiv.org/pdf/2410.21169,这个工作回顾了文档解析的现状,涵盖了从模块化pipeline系统到由多模态大模型驱动的端到端模型的关键方法,也介绍了一些布局检测、内容提取(包括文本、表格和数学表达式)和多模态数据集成等核心组件。
其中记录几个比较重要的点。
1、两种文档解析方法,包括piepeline式以及多模态端到端式
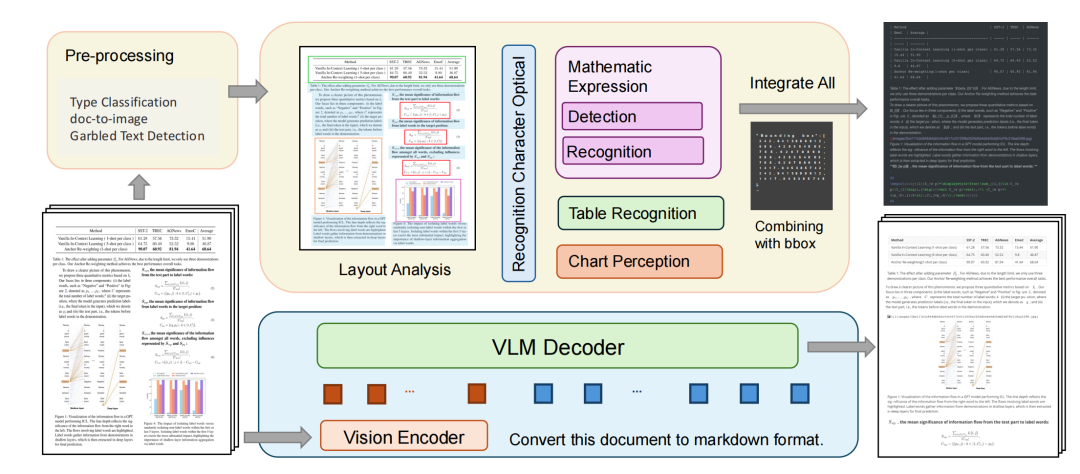
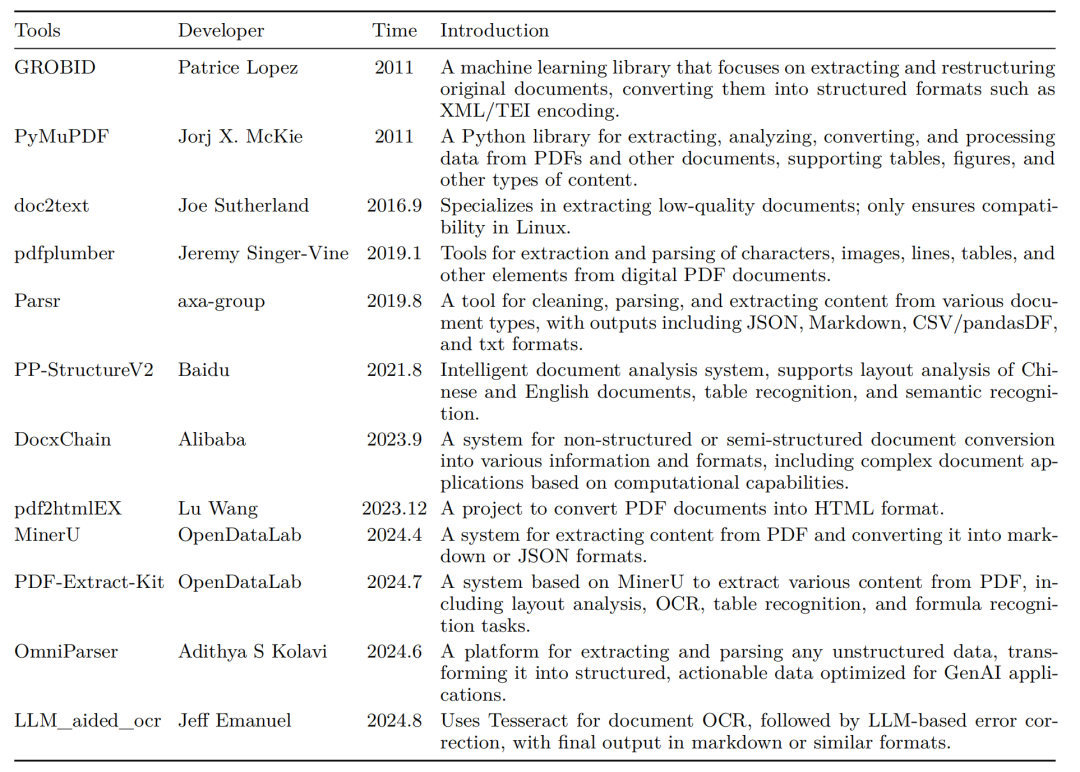
2、代表开源文档解析工具
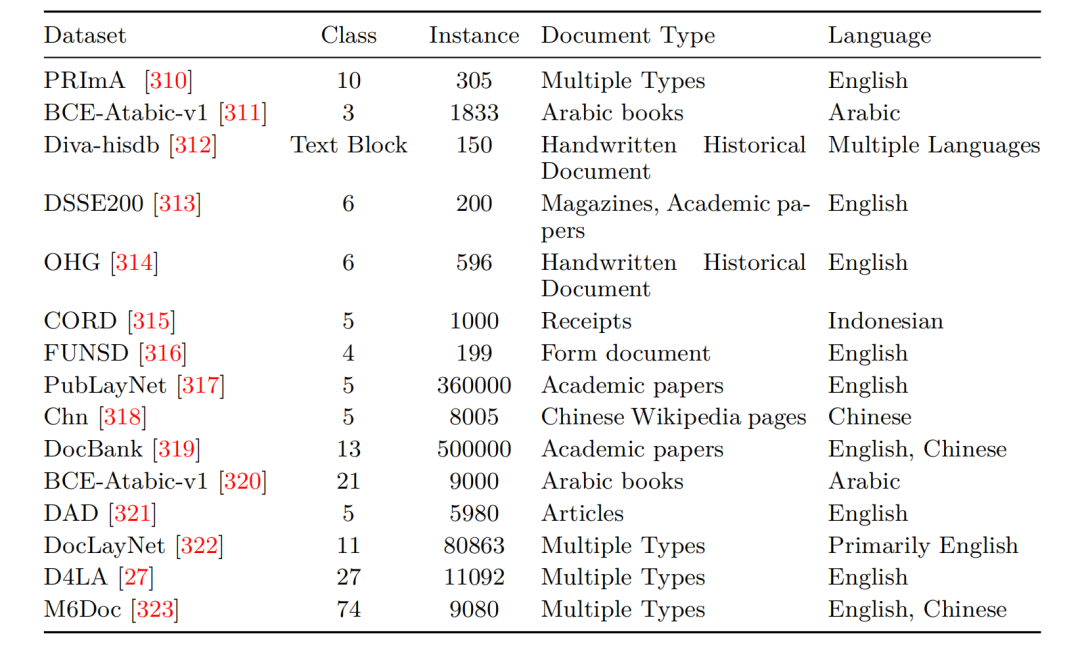
3、布局分析数据集
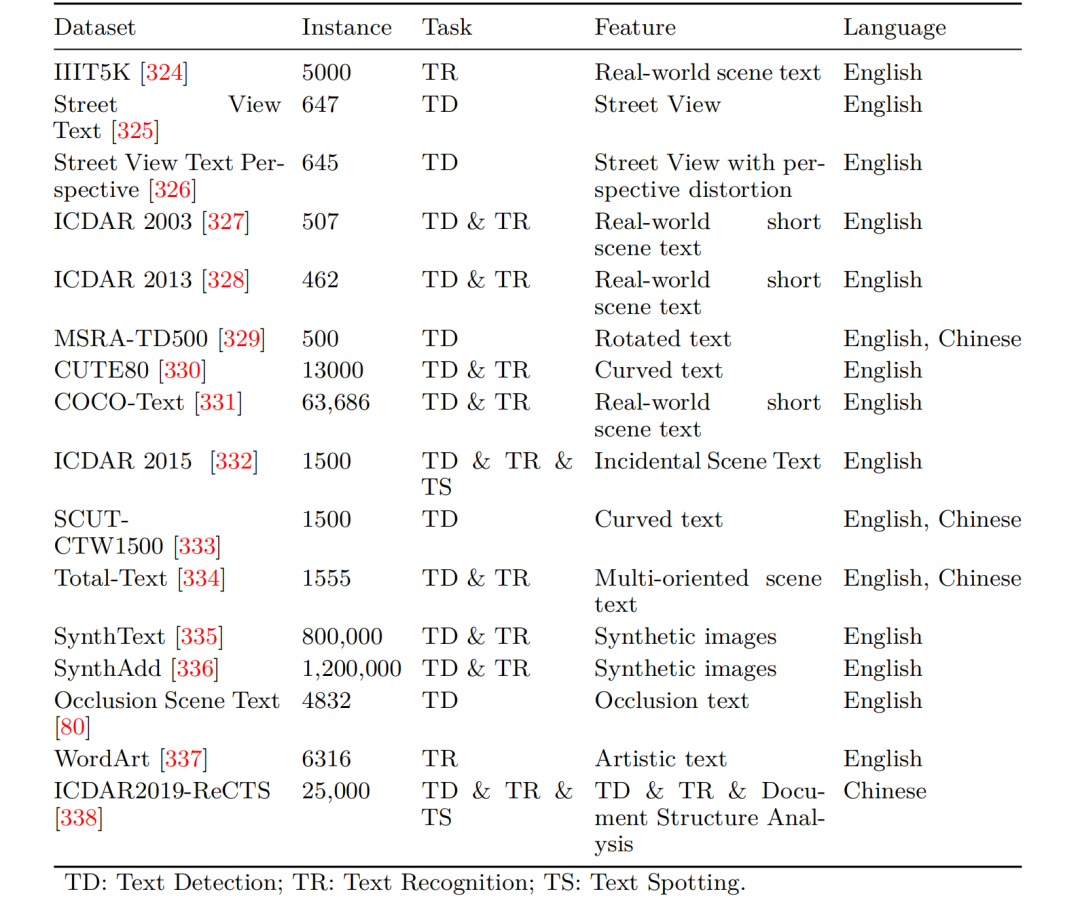
4、ocr数据集
5、医学影像分析和医学影像检索常用数据集
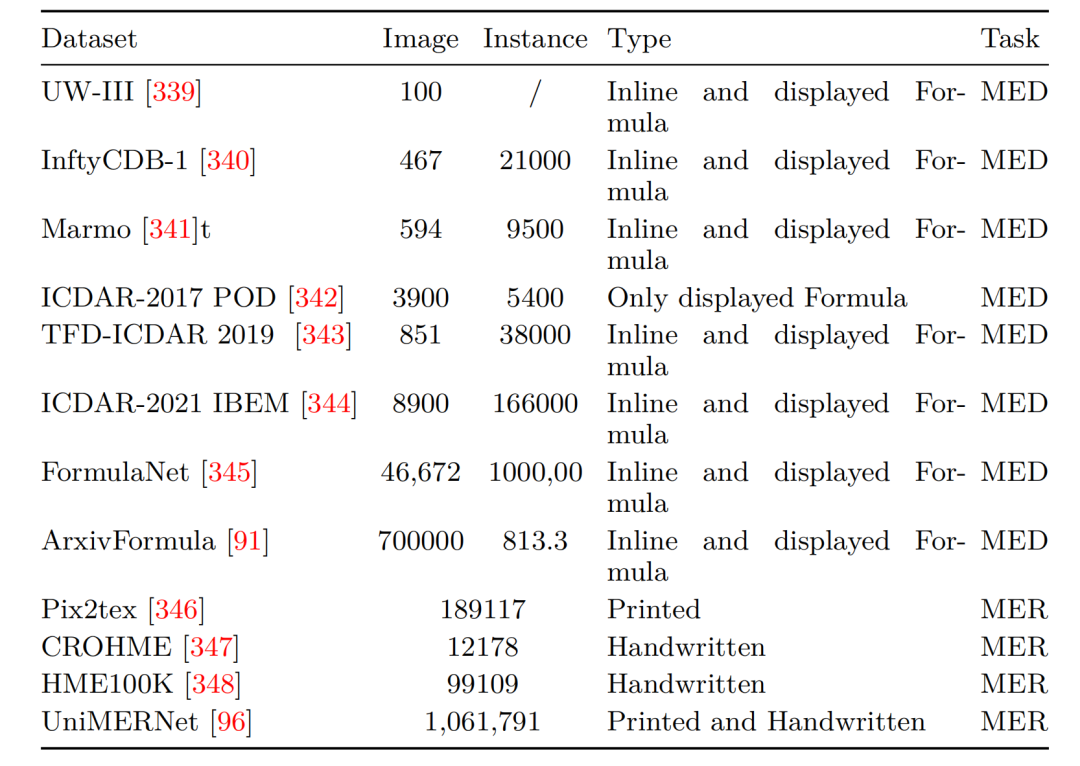
6、表格解析数据集
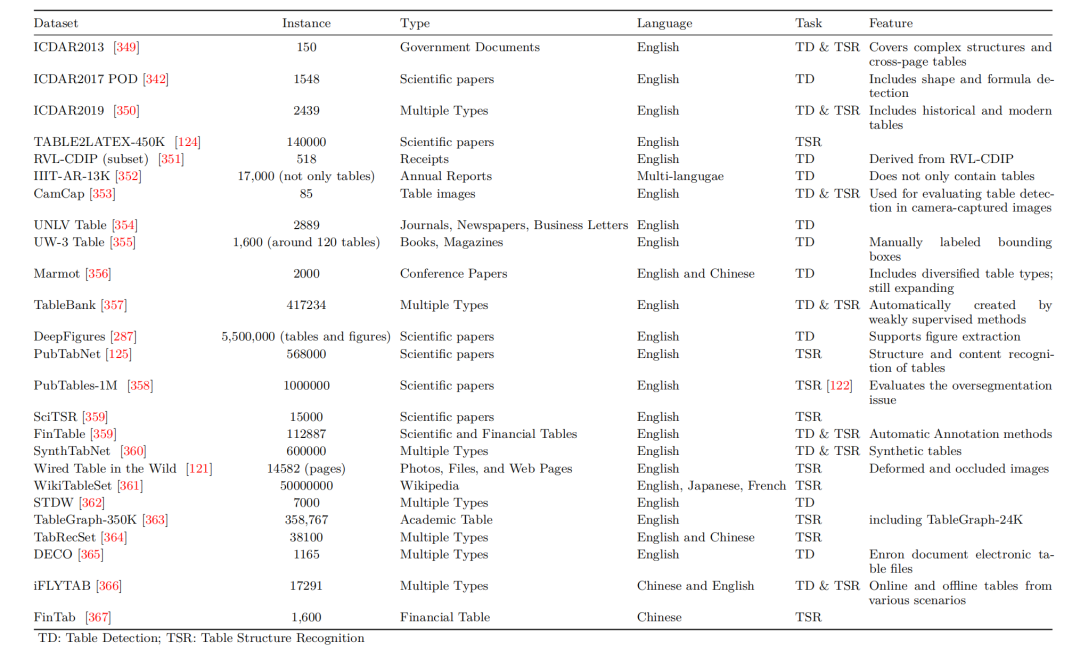
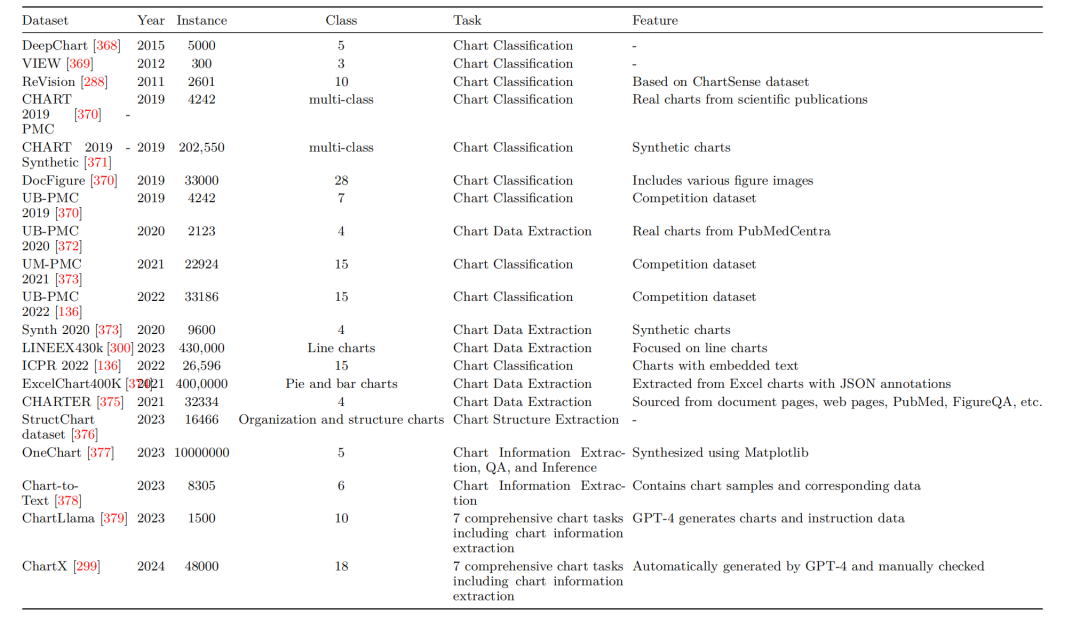
7、图表相关任务常用数据集
二、多模态文档理解技术总结
这个方向是视觉丰富的文档理解 (VRDU) ,代表性的工作《A Survey on MLLM-based Visually Rich Document Understanding:Methods, Challenges, and Emerging Trends》,https://arxiv.org/pdf/2507.09861,回顾了基于MLLM的VRDU的最新进展。
其中重点介绍了用于编码和融合文本、视觉和布局特征的方法;训练范式以及用于预训练、指令-调整和监督微调的数据集,其中设计到的一些工具、数据集这些,感兴趣的可以关注。
也记录下其中重要的点。
1、现有基于MLLM的VRDU框架对比
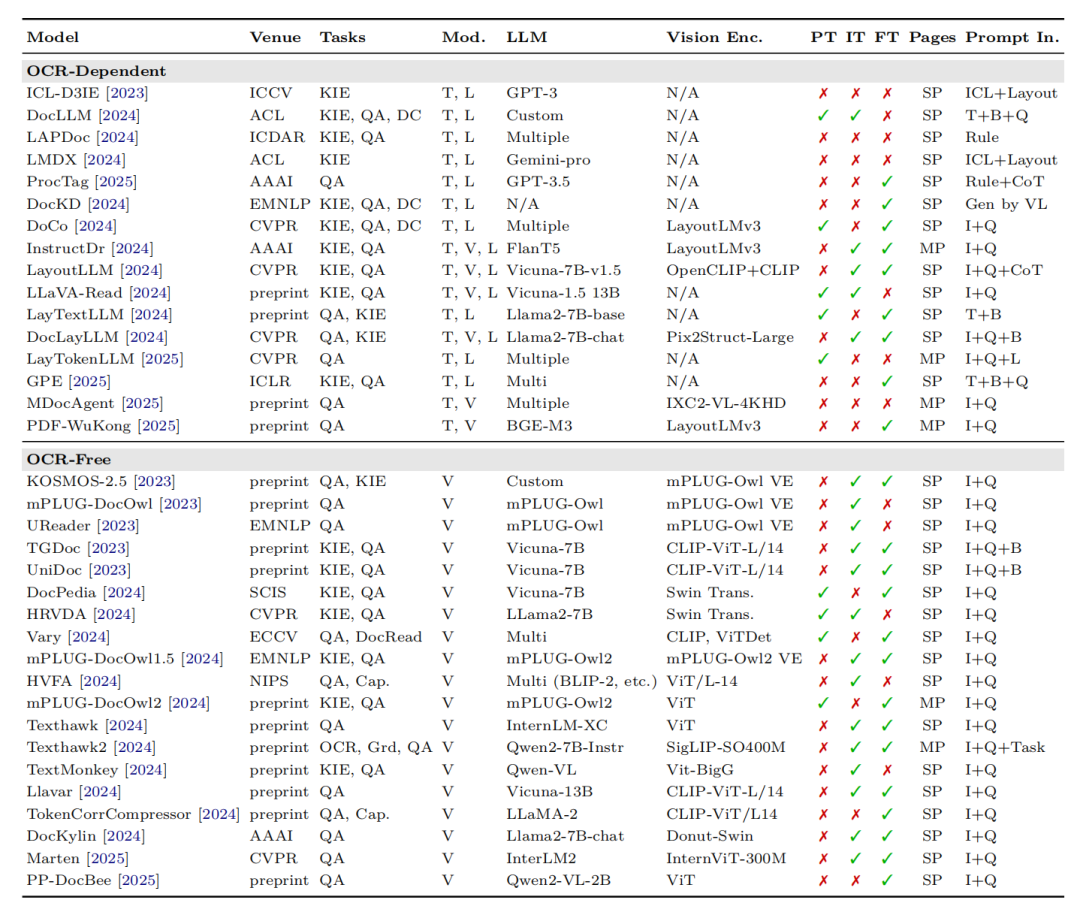
其中,KIE:关键信息提取;QA:问答系统;DC:文档分类;T:文本;L:布局;V:视觉;MP:多页;SP:单页;I:图像;Q:问题;B:边界框;CoT:思维链;Cap.:标题生成;Grd.:真实标注;Task:任务信息;VL:视觉-语言。
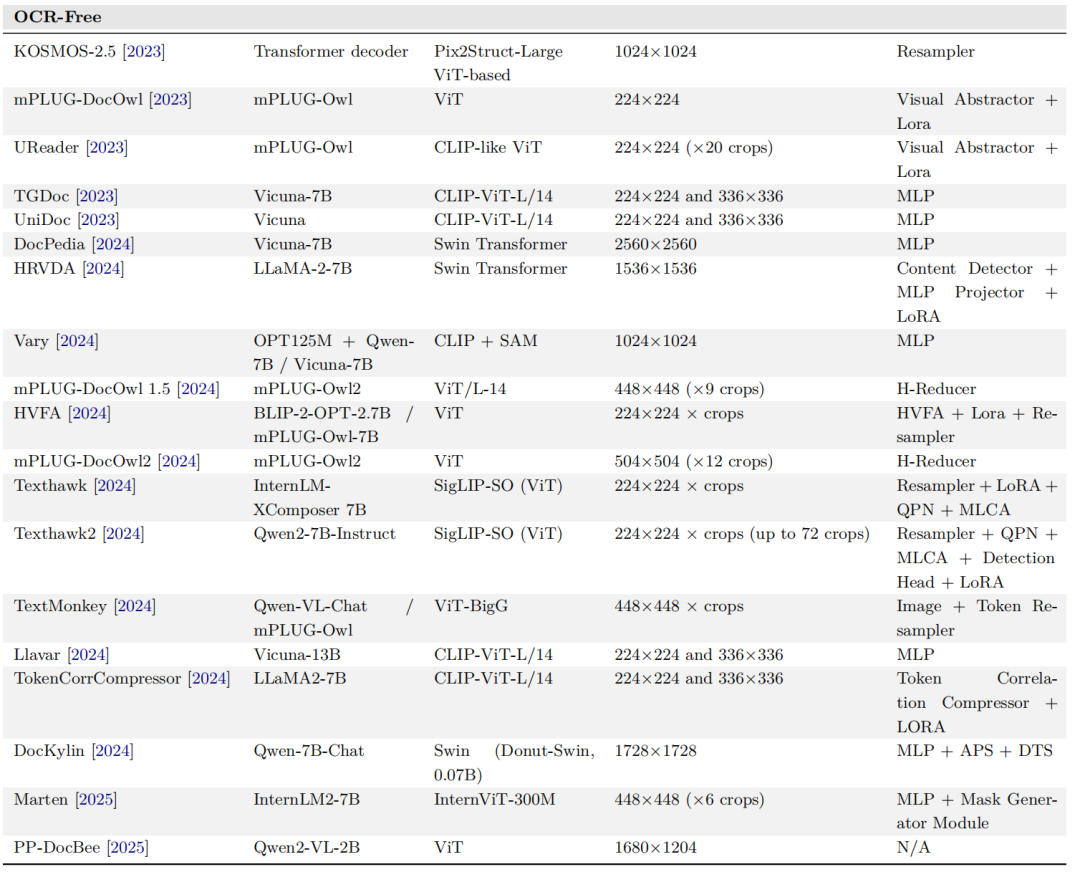
2、OCR-Dependent及OCR-Free框架
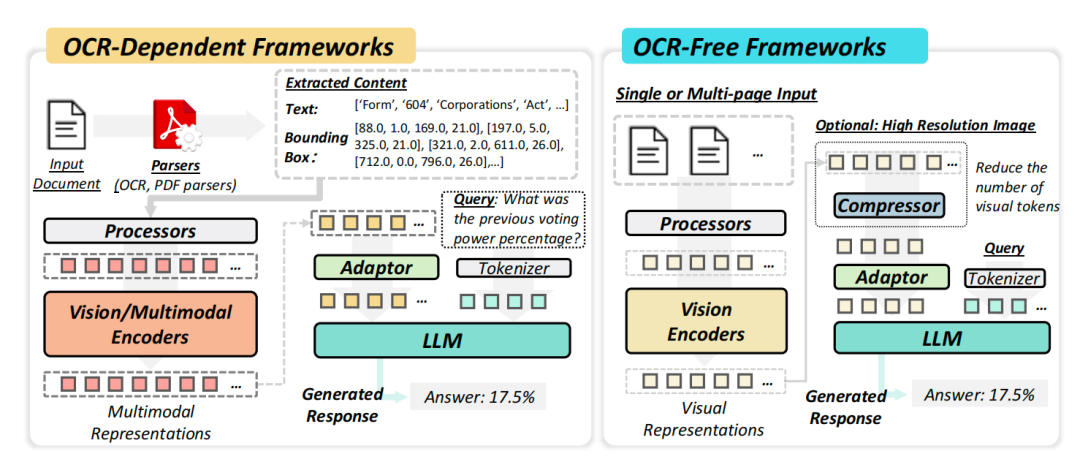
3、多模态特征表示与融合机制
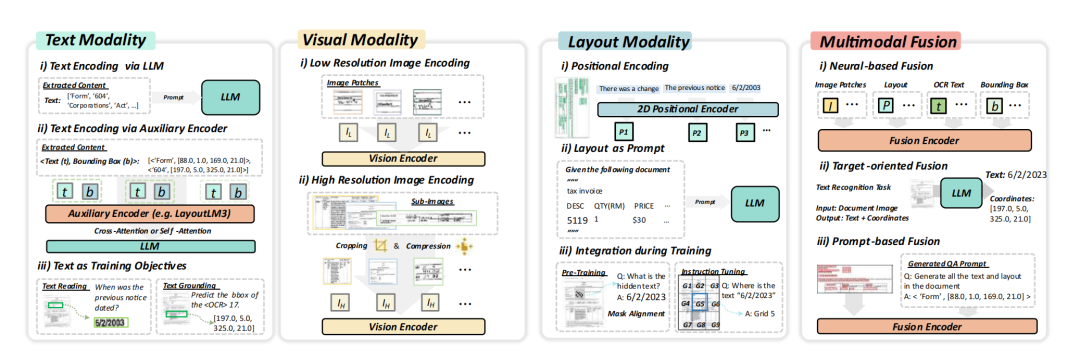
4、基于多模态模型的文档理解框架对比
可以看看训练阶段的参数是否冻结以及微调方式对比。
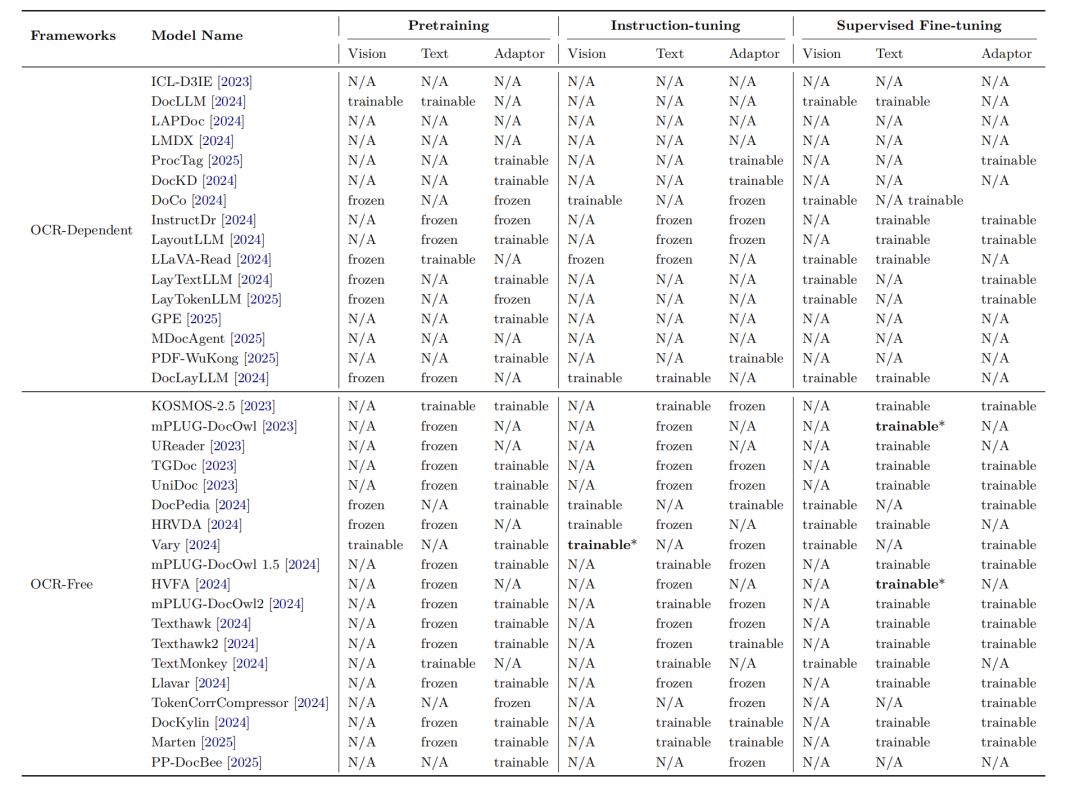
5、OCR-Dependen的模型对比
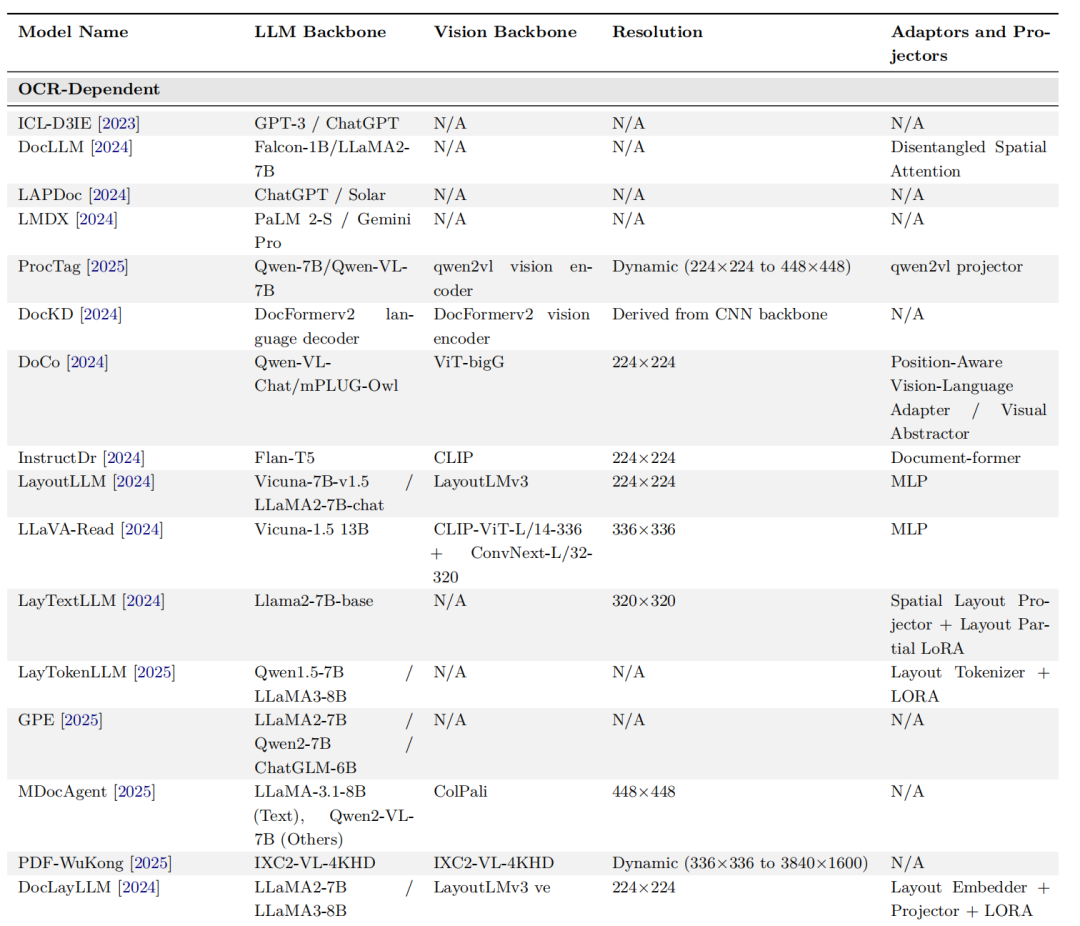
6、OCR-Free的模型对比
5、代表文档理解大模型的创新点
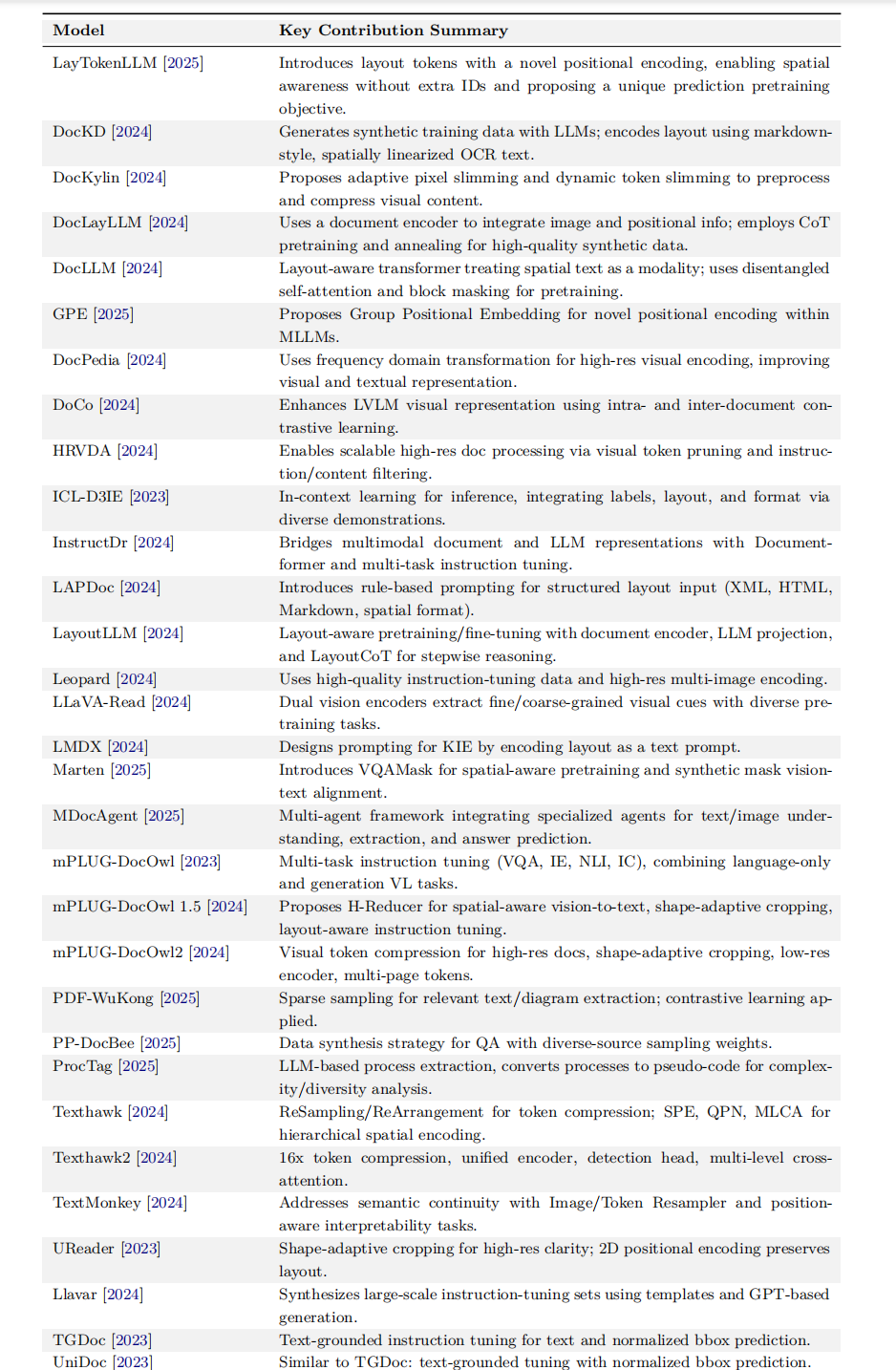
LayTokenLLM,提出带新型位置编码的“布局tokens”,无需额外ID即可实现空间感知,并设计独特的预测式预训练目标。
DocKD,利用大模型生成合成训练数据;以类markdown、空间线性化的OCR文本方式编码版面。
DocKylin,提出自适应像素瘦身与动态token瘦身,用于预处理并压缩视觉内容。
DocLayLLM,使用文档编码器融合图像与位置信息;通过CoT预训练与退火策略生成高质量合成数据。
DocLLM,布局感知Transformer,将空间文本视为独立模态;采用解耦自注意力与块掩码进行预训练。
GPE,提出GroupPositionalEmbedding,在MLLM中实现新颖的位置编码。
DocPedia,用频域变换对高分辨率视觉编码,提升视觉-文本表示质量。
DoCo,通过文档内/跨文档对比学习,增强LVLM的视觉表征。
HRVDA,通过视觉token剪枝与指令/内容过滤,实现可扩展的高分辨率文档处理。
ICL-D3IE,基于上下文学习的推理方法,通过多样示例整合标签、版式与格式信息。
InstructDr,用Document-former与多任务指令微调,弥合多模态文档与LLM表征。
LAPDoc,引入基于规则的提示,支持XML、HTML、Markdown及空间格式的结构化布局输入。
LayoutLLM,布局感知的预训练/微调框架,含文档编码器、LLM映射层与LayoutCoT逐步推理。
Leopard,使用高质量指令微调数据与高分辨率多图编码。
LLaVA-Read,双视觉编码器提取粗细粒度视觉线索,配合多样预训练任务。
LMDX,为信息抽取设计提示,将版式编码为文本提示。
Marten,提出VQAMask实现空间感知预训练,并使用合成掩码对齐视觉-文本。
MDocAgent,多智能体框架,集成文本/图像理解、抽取与答案预测的专用智能体。
mPLUG-DocOwl,多任务指令微调(VQA、IE、NLI、IC),融合纯语言与生成式VL任务。
mPLUG-DocOwl1.5,提出H-Reducer实现空间感知视觉-文本转换、形状自适应裁剪与布局感知指令微调。
mPLUG-DocOwl2,视觉token压缩处理高分辨率文档,支持形状自适应裁剪、低分辨率编码器与多页token。
PDF-WuKong,稀疏采样提取相关文本/图表,并应用对比学习。
PP-DocBee,面向问答的数据合成策略,采用多源采样权重。
ProcTag,基于LLM的流程抽取,将流程转为伪代码以分析复杂度与多样性。
Texthawk,ReSampling/ReArrangement压缩token;SPE、QPN、MLCA实现分层空间编码。
Texthawk2,16×token压缩、统一编码器、检测头与多级交叉注意力。
TextMonkey,用Image/TokenResampler解决语义连贯性,并引入位置可解释性任务。
UReader,形状自适应裁剪保证高分辨率清晰度;二维位置编码保留布局。
Llavar,利用模板与GPT生成大规模指令微调数据集。
TGDoc,文本接地指令微调,同时预测文本与归一化bbox。
UniDoc,与TGDoc类似:文本接地微调并预测归一化bbox。
参考文献
1、https://arxiv.org/pdf/2410.21169
2、https://arxiv.org/pdf/2507.09861
(文:老刘说NLP)