出品丨AI 科技大本营(ID:rgznai100)
本文深度解析腾讯混元最新发布的 SEAT 自适应并行扩展推理框架,让大模型 CoT 从“单引擎飞艇”变身“多发并联火箭”,征服复杂推理任务的星辰大海,避开过度思考迷航。
2018 年,当 SpaceX 猎鹰重装级火箭 (Falcon Heavy) 轰鸣升空, 捆绑着多台发动机并联点火, 以多发并联抵消失效风险,用多级捆绑实现推力飞跃,将人类太空运载能力推向全新高度。
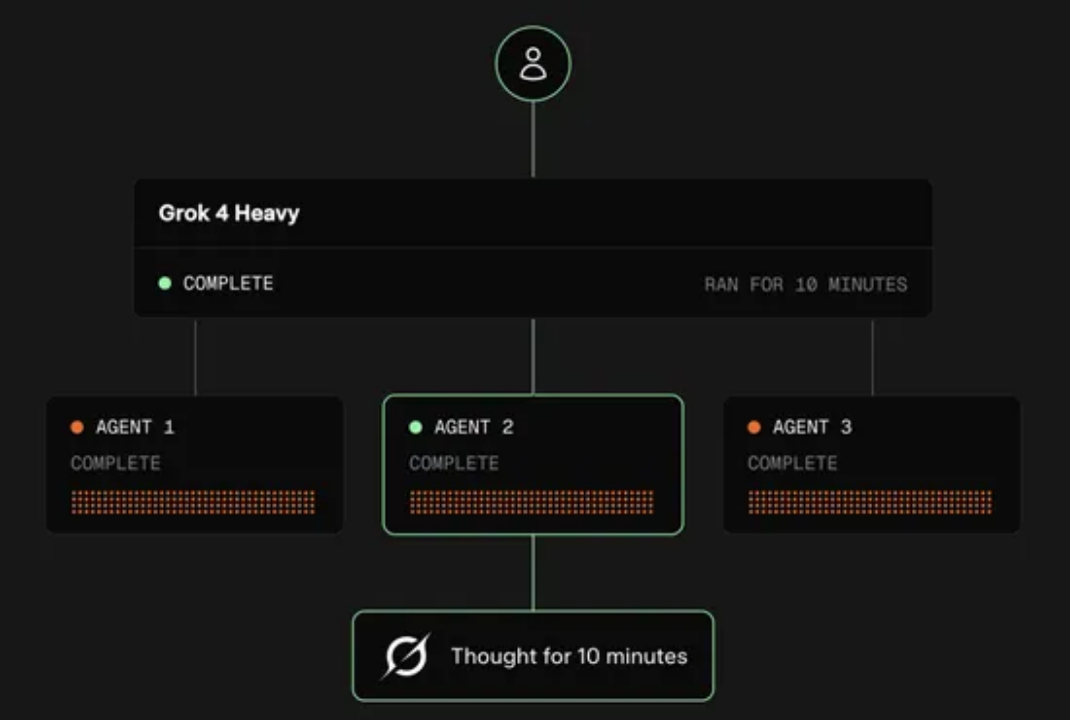
当时没有人意识到,在 7 年后将会有另外一场的技术发布遥相呼应,形成了跨越时间的共振:2025 年7 月 10 日,xAI发布「Grok 4 Heavy」,用多智能体并行架构复刻“多发引擎”设计,让 AI 同时思考多种假设,在 ARC-AGI 基准上以 15.9% 的碾压成绩刷新 SOTA。
就在同一天,腾讯混元团队在 arXiv 上发布论文《SEAT: Adaptive Termination for Multi-round Parallel Reasoning – An Universal Semantic Entropy-Guided Framework》(ArXiv, abs/2507.06829) ,以严谨的论证、详实的技术细节和扎实的实验数据,为大模型的思考注入同款“重型推力”,SEAT 框架的「自适应多轮并行引擎」首次点火:
-
多轮并行推理 – 多流交叉验证突破盲目自信、误入歧途和无限循环等低效推理;
-
语义熵导航 – 多轮迭代依赖动态监控答案收敛时及时停止;
从此,大模型无论是闭源还是开源,都能将复杂推理思维链 (Chain-of-Thought, CoT) 从“单引擎飞艇”升级为“多发并联的星际火箭”,并适配“智能导航”保证长程推理全程精准掌控。
在人工智能的星辰大海中,大型语言模型(LLM)无疑是就是当前最引人注目的旗舰,它拥有强大的马力,知识储备丰富,能回答人们提出的各种问题,今天我们所熟知的快思考语言模型能够轻松应对问答、对话和创作等各种语言任务。但渐渐地,大家不再满足于让大模型局限于语言任务,而是尝试让大模型去探索复杂推理问题的广袤的未知空间,比如解决一个奥数竞赛题题,或者撰写一份严谨的科学报告,又或者是一个需要长程规划的 Agentic 任务。
这时你需要的可能不再仅仅是大模型在海上乘风破浪,而是需要长距离飞行探索天空并能精准降落到目的地。
于是大语言模型就发展出了思维链 (CoT) 技术,从而具备了深度思考的能力,就像是给大模型装上了喷气式引擎,让它能够离地升空,飞得高、看得远,通过一步步的逻辑推理来解决问题。这在很大程度上提升了 LLM 的推理能力,但其局限性也日益凸显,如果你尝试过用大模型来做这些复杂任务就可能遇到过,大模型要么一顿操作猛如虎,输出一堆逻辑链但结果还是错,要么直接摆烂坚持输出一个明显的错误答案,又或者陷入思考死循环绕不出来。大家渐渐发现深度思考模型 CoT 纵然强大,但当面对复杂推理任务时也常常会力不从心,也暴露出“过度思考”、“无效思考”和“盲目自信”等各种缺陷。
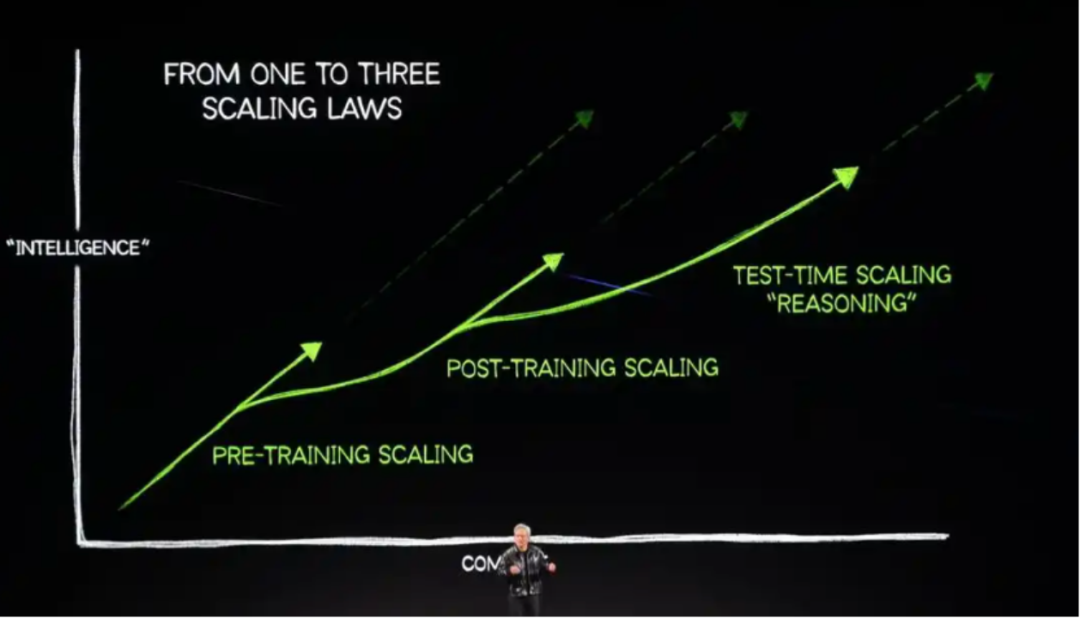
在此之前,模型性能的提升主流做法依赖于“训练时扩展”,即通过增加模型参数量和训练数据集的规模来实现。然而,随着模型规模的急剧膨胀,这种方法的边际效益递减,且带来了高昂的训练成本和算力需求。为了突破这一瓶颈,“测试时计算扩展” (Test-Time Scaling) 作为一个新的研究方向迅速成为前沿热点:
测试时计算扩展的核心思想是,在不改变模型预训练参数的前提下,通过在推理阶段投入更多的计算资源,来提升模型在复杂任务上的表现。这种方法允许模型在给出最终答案前进行更深入的探索,从而显著提高答案的准确性和可靠性。近期大量研究证明测试时计算扩展的巨大潜力,业界相当部分的注意力也从单纯的训练时扩展,转向如何更有效地设计和优化推理时计算策略,“测试时计算扩展”逐渐成为 LLM 能力提升的探索的一个新的趋势,即从“更大的模型”转向“更聪明的推理过程”,这个方向逐渐发展出“顺序扩展 – 深度迭代精进”和“并行扩展 – 多样性广度探索“这两个主要分支:
1.顺序扩展 (Sequential Scaling) ,其核心思想是通过延长推理路径的“深度”来扩展计算。这通常通过生成更长的思维链(Chain-of-Thought, CoT)或采用多轮迭代优化的方式实现。 但是“顺序扩展”思路下,推理容易一条道走到黑,模型常常会陷入错误的推理路径而无法自拔,并且由于缺乏有效的“刹车”机制也不知道自己何时应该停止徒劳的思考。
2.与追求深度的顺序扩展相对,并行扩展 (Parallel Scaling) 通过增加推理路径的“广度”来扩展计算 。其核心策略是让模型针对同一个问题,独立、并行地生成多个(N个)候选答案, 探索了更多可能性然后从中挑选。“并行扩展”思路下,多流推理往往各自为战,缺乏协作和迭代,导致计算效率低下,性能提升也很快会遇到瓶颈。
显然两种主流测试时扩展范式的互补性与局限性变得清晰起来:
-
顺序扩展提供了深度精炼的能力,但有陷入局部最优和“过度思考”的风险;
-
并行扩展提供了广度探索的能力,但缺乏协作和持续优化的机制。
这种内在的矛盾自然地引出了一个核心研究问题,也正是 SEAT 论文开篇所提出的:“我们能否设计一个灵活的框架,有效整合顺序和并行扩展范式的互补优势?”
腾讯混元 SEAT 框架提出的融合二者的一种全新的混合扩展(Hybrid Scaling)范式:利用并行生成进行广泛探索,再利用顺序迭代进行深度精炼,这像是为大语言模型提供了一套强大的升级“深度思考”的外挂,它给 CoT 装上“重装发动机“(多轮并行动力)和“智能导航”(语义熵自适应刹车), 让 AI从“单引擎飞艇”升级为“多发并联火箭”。接下来将逐步拆解 SEAT 提出的这个范式升级的关键环节!
范式升级第一弹:并行推理给 CoT 装上“猎鹰重装”级的澎湃动力
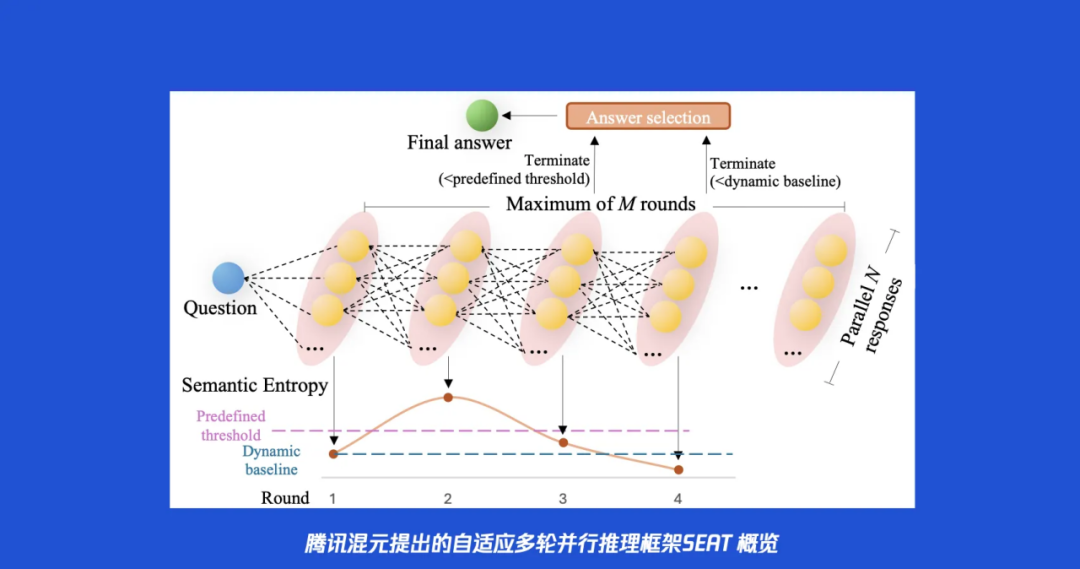
SEAT 的第一步,就是对模型推理的“动力系统”进行一次彻底的系统性升级。它引入了一个 N x M 的多轮并行推理框架,将传统 CoT 的单引擎模式升级为了一台拥有 N 个并行引擎的重装级火箭。
-
N 代表并行(Parallel)的广度:在每一轮(Round)推理中,模型会像“猎鹰重装”的并联引擎一样,同时点燃 N 条独立的思考路径。这 N 个并行的思考分支会同时对问题进行探索, 生成 N 份包含思考过程和答案的候选方案。这极大地拓宽了模型在单一步骤中的探索范围。
-
M 代表顺序(Sequential)的深度:这套框架并非一次性的并行,而是可以进行多达 M 轮的迭代精炼。最关键的是,第 i 轮的 N 个思考分支在开始工作前,会得到一份特殊的“参考资料”,这份资料包含了第 i-1 轮所有 N 个推理分支的完整答案。
这个设计巧妙地融合了并行与顺序的优势:模型在每一轮都能集思广益,看到其他可能性的同时,又能基于上一轮的集体智慧进行更深层次的迭代和修正。各个分支之间不再是单打独斗,而是通过团队协作中进行集合思考。
正如“猎鹰重装”火箭,其“多发并联”的引擎(并行N)提供了强大的探索推力与容错能力,而“多级捆绑”的结构(顺序M)则确保了推理能够逐级精炼,抵达更高的高度。
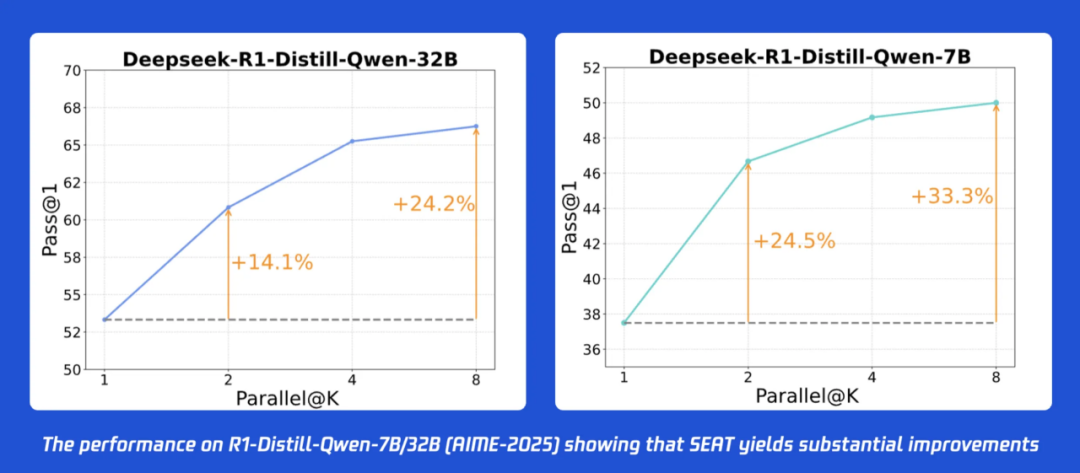
在 AIME-2025 这个极具挑战性的数学竞赛数据集上,实验结果显示:
-
对于 32B 的大模型,仅仅采用 N=2 的最小并行设置,就能带来 +14.1% 的惊人准确率提升。
-
对于 7B 的小模型,效果更为显著,准确率提升高达 +24.5%!
当并行数增加到 N=8 时,性能还能进一步提升。这充分证明了 SEAT 框架提供的“并行引擎”具有极其强大的推力,并且性价比极高。
更值得称道的是 SEAT 实现这种并行的方式。当前,许多工作试图通过干预模型内部的生成过程 (inner-round control)来实现更精细的控制,但这往往需要对模型结构进行修改,或者进行复杂的专门训练,通用性很差。
而 SEAT 采用的是一种 inter-round(轮次间)的控制策略。它把大模型视作一个黑箱,只在每一轮推理的输入和输出端进行信息整合。这意味着:
-
即插即用 (Plug-and-Play):无论你是用 Hunyuan,Qwen,Llama,还是 DeepSeek,任何大模型都可以直接使用 SEAT 框架。
-
无需训练 (Training-Free):它是一个纯粹的推理时策略,不需要任何额外的微调或训练成本。
所以,SEAT 就像一个通用化的“并联引擎”升级的外挂套件,可以轻松地安装到任何现有的“飞行器”(LLM)上,即插即用,立刻带来性能的飞跃。
范式升级第二弹:语义熵的动态监控实现全程的“智能导航”
现在,LLM 升级成为搭载着“猎鹰重装”级引擎的超级火箭。但困扰大模型推理的另外一个问题仍然摆在面前:一台只有引擎没有导航的火箭,最终的结局只可能是在太空中迷失方向,或是在燃料耗尽后坠毁。
如何为这股强大的力量装上“导航”?如何让模型知道自己何时已经“到目的地”啦,可以停止计算,给出答案?
腾讯混元团队在这里引入了整个SEAT 框架的题眼 – 语义熵 (Semantic Entropy)。怎么说呢(忘掉复杂的数学公式),语义熵就是一个衡量 AI 推理“困惑度”的传感器,用一个直观的比喻来理解语义熵:它就像一个“航向一致性”检测仪。在每一轮推理中,我们都有 N 个并行推理分支会给出各自的答案,语义熵衡量的,就是这 N 个答案在“语义层面”上的一致性:
-
高熵 (High Entropy):如果 N 个答案五花八门,语义上南辕北辙(比如,一个答案 是“68”,另一个是“苹果”,还有一个是“不确定,我再想想”),这说明模型的并行推理分支的推导方向分歧巨大,处于高度“困惑”的状态。此时,“航向一致性检测仪”的读数会飙高。
-
低熵 (Low Entropy):如果 N 个答案虽然措辞不同,但最终都指向了同一个语义核心(比如,都指向最终答案“68”),这说明模型的思考已经“收敛”,内部达成了高度共识。此时,检测仪的读数会变得很低。
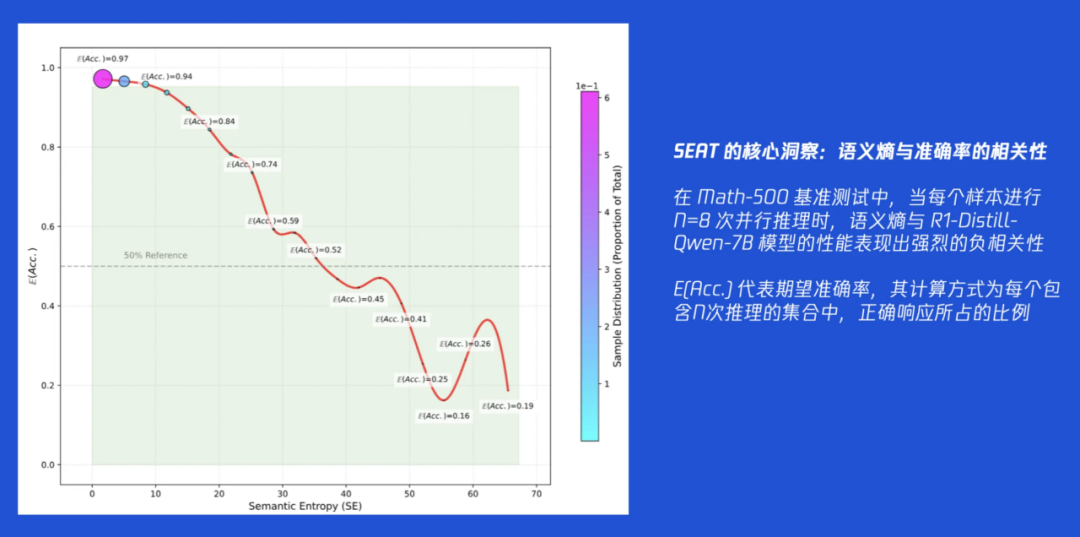
SEAT 论文最重要的实证发现:模型的推理准确率与语义熵存在强烈的负相关性。 这条“黄金法则”在说,当推理结果的“困惑度”降低,则表明模型多路推理分支达成共识,这时它给出的答案有极大概率是正确的!这个发现的可贵之处在于,它意味着我们找到了一个不依赖外部知识、纯粹依靠模型自身输出就能判断其推理质量的自监督指标。这个“导航传感器”是真实、可靠且有效的。
有了这个强大的传感器,SEAT 设计了两种“关闭引擎”的导航策略:
1. 预设航线模式 (Pre-defined Threshold Approach)
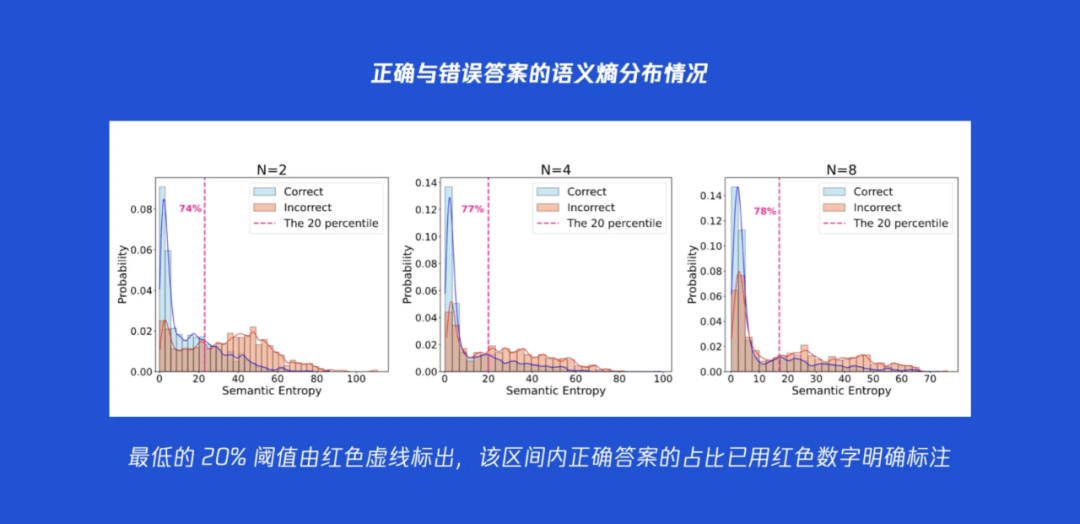
这个方法比较直接。我们事先通过对一批问题进行采样,分析模型在不同“困惑度”(语义熵)下的表现。研究发现了一个有趣的 “80/20”法则:大约 80% 的正确答案,都出现在语义熵最低的 20% 的区间内。 因此,我们可以提前计算出这个“20%分位点”的熵值,并将其设定为一个固定的“目标稳定度”。在多轮推理中,一旦某一轮的语义熵低于这个预设的阈值,导航系统就认为“已抵达预定航线”的终点,立刻停止推理。 这种方法行之有效,但缺点是需要提前进行采样和校准,当更换模型或并行设置时,需要重新操作。
2. 自适应巡航模式 (Adaptive Threshold-free Mechanism)
这是 SEAT 的又一个创新。为了摆脱对预设阈值的依赖,研究者从运筹学问题“秘书问题”中获得了灵感,其核心是在信息不完全的情况下做出最优决策。SEAT 的自适应导航完美地借鉴了这一经典思想:
-
第一步建立动态基准 – 即统计前 T 轮推理产生的语义熵并形成“初始抖动”的基线。我们不评判这个初始值是好是坏,只是客观记录下来。
-
第二步动态巡航与决策 – 从第 T +1 轮开始,每一轮推理结束后,都计算新的语义熵,并与基线的“初始抖动”进行比较。一旦当前轮次的语义熵低于这个基线,导航系统就立刻做出判断:“当前的思考状态已经比刚开始时更加清晰和收敛了,思考取得了实质性进展,可以终止!”
这个策略的精妙之处在于它的完全自适应性。它不关心熵的绝对值是多少,只关心相对的改善。无论面对的是简单问题(初始熵很低)还是复杂问题(初始熵很高),这套系统都能动态地为自己设定一个“过得去”的标杆,并在此基础上寻求超越。这使得 SEAT 框架异常灵活、鲁棒且无需任何前期准备。
范式升级的彩蛋:“智能导航”如何防止“引擎过载”造成熔毁事故
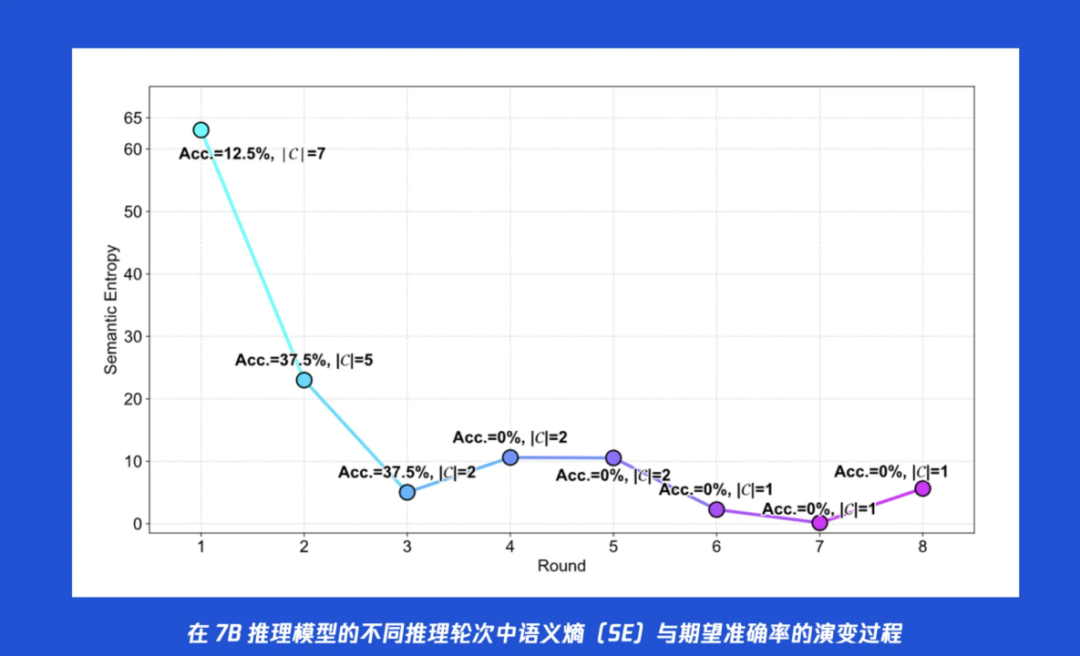
在实验过程中,腾讯混元团队还观察到了 SEAT 一个之前在设计时可能没有太预设的、但在实践中很实用的“副作用”,尤其是在针对小规模模型(如 7B)推理时经常出现的语义熵坍塌 (Semantic Entropy Collapse) 的现象。具体说说什么是“语义熵坍塌”?在很多实际推理或者实验中,当让 7B 这样的小模型进行多轮的并行推理时,它的语义熵在后期会突然暴跌至接近于零。 从“导航传感器”的读数上看,似乎是模型达到了前所未有的“共识”。但当检查此时的答案准确率时,却发现准确率也随之崩盘,同样跌至谷底。通过分析模型的具体输出才发现:模型并非真正地“想明白了”,而是陷入了一种“过度自信的错误”。它丧失了思维的多样性,开始固执地、一遍又一遍地重复同一个错误的答案,并且其思考过程变得极度简化,甚至直接跳过推理步骤。实际上,这就像一台持续超负荷运转的火箭引擎会发生一种灾难性的“引擎过载”的熔毁事故。
此时,SEAT 的“智能导航系统”展现出了它作为“安全员”附加的但是又是极为实用的价值。
以上述发生“熵坍塌”的案例为例,假如模型的准确率在第2轮达到峰值之后便开始下滑。而 SEAT 根据自适应终止策略,一旦发现语义熵已经低于了初始的基准,就可发出“停止”指令!
这意味着,SEAT 能够在模型性能达到巅峰、但还未因“想太多”而陷入“过载自毁”状态之前,就果断地切断动力。它不仅是一个效率工具,更是一个至关重要的安全保护机制。它保护了小模型, 使其能够在复杂的多轮推理中保持稳定的表现,而不会因为能力不足而“烧坏脑子”。
回到我们最初的问题:如何让大模型这艘旗舰,实现精准、高效且可靠的“星际穿越”,去探索 AI 广袤未知的星辰大海?
SEAT 框架基于 Test-Time Scaling 范式给出了一份非常有创新性的答案 :它并非一个复杂的、 需要高昂成本的全新模型,也不要求现有大模型进行额外训练,或者满足什么特定要求,它基本上就是一套完整的、即插即用的深度思考CoT 的“升级”外挂。
-
它通过多轮并行推理,为我们的模型装上了“猎鹰重装”级的强大引擎,提供了前所未有的并行探索动力,通过推理时计算扩展为大模型也能带来高效且显著的性能提升。
-
它通过引入语义熵这个精妙的自监督指标,并设计出自适应无阈值终止策略,为这股强大的力量装上了一套极其聪明的“智能导航系统”。
-
这套导航系统不仅能通过“见好就收”来大幅提升计算效率,更能通过规避“语义熵坍塌”,为模型的推理过程提供关键的安全保障。
腾讯混元发布的 SEAT 推理框架,其核心在于支持基础模型在推理阶段根据任务需求动态切换为更强大的 Heavy 版本。这种设计既提供了算力调度的灵活性,也引入了更复杂的推理控制与引导机制。
相较于单纯追求推理性能,SEAT 更强调在扩展路径中引入“控制”和“引导”的策略。通过 Hybrid Scaling 的融合机制,以及基于语义熵的判断方式,它尝试以更具上下文感知的方式提升大模型在长链条、复杂语境下的推理质量。
在推理能力走向更强的同时,如何走得更稳、更有目标感,或许将成为大模型演化中的关键议题之一。而 SEAT 提出的这些方案,提供了一种新的路径选择。(投稿或寻求报道:zhanghy@csdn.net)
· · ·
📢 AI 产品爆发,但你的痛点解决了吗?
2025 全球产品经理大会
8 月 15–16 日
北京·威斯汀酒店
互联网大厂、AI 创业公司、ToB/ToC 实战一线的产品人
12 大专题分享,洞察趋势、拆解路径、对话未来。
立即扫码领取大会PPT
抢占 AI 产品下一波红利
(文:AI科技大本营)