

TL;DR
前面一篇《谈谈GPU云的经营风险和流动性管理》谈论一些GPU云经营相关的问题, 对于OCI的经营风险进行了一些分析, 正好这几天AWS GB200上线, 因此从AWS的视角再来谈谈这个问题.
相关的还有一篇去年Re:invent的分析:
《AWS Re:Invent 从AWS CTO演讲的教训看AI云基础设施架构》
AWS定制的GB200有很多独特的符合云业务的设计, PCIe互连/机柜可靠性/散热等都有很多考虑, 特别是在ScaleOut和FrontEnd网络融合上有非常特殊的设计, 我们将详细展开说一下.
另一方面是NV过四万亿, 微软MAIA2延期, 然后还有伴随着某个时间发酵而产生的一个问题《华为NPU昇腾芯片是否属于重大战略方向性失误,应该选择GPGPU,导致CANN软件栈面临作废状态?》[1]
本文也将从GPU云的视角补充一些分析… 本文目录如下
1. 先来谈谈NPU的事情
2. AWS Blackwell发布概述
3. AWS GB200机柜架构
4. AWS GB200 ComputeTray架构
5. AWS GB200 网络
6. AWS GB200 管控节点
7. AWS GB200 散热设计
8. 从云的视角来分析
1. 先来谈谈NPU的事情
其实无论是Google TPU, 还是AWS Trainium 或者包括华为的Ascend, 这些NPU对于GPU云的IaaS交付界面来看, 都是存在挑战的.
云的实质是算力证券化, 任何非标的场外交易都会带来显著的成本影响, 一方面是适配导致的技术债务, 特别是训练推理框架长期演进带来的问题. 另一方面是非标产品本身的定价涉及太多的议价问题和客户内部的成本核算的问题, 使得其流动性(弹性)受到影响, 用户无法按需供应的方式灵活的使用.
当CUDA成为一个事实上的IaaS交付界面时, 对于其它自研的XPU来看, 保证PTX指令上的一些兼容性或许是一个更加明智的选择…
另一方面我个人觉得有些事情不必过于苛刻了, 战略方向的问题说的重了点. 从战略上来看, NV不也是在逐渐DSA化么? 例如他们前段时间的一篇论文《Task-Based Tensor Computations on Modern GPUs》, 几个月前做过一个解读:
《CUDA-Next: 基于任务的张量计算的DSL?》
SIMT本身的抽象是挺优雅的, 但是在添加上TC后确实也增加了一些复杂性…一个是从SIMT开始添加DSA, 另一个其实稍微退一步, 类似的在DSA上添加一些SIMT前端是否行了呢? 然后满足一些算子哥的习惯? 当然在memory hierarchy上还有warp调度上还有很多问题要处理…
其实一个是从SIMT逐渐添加TC这样的DSA, 然后再基于Task-Based Tensor进行抽象. 另一个是从DSA到兼容用户习惯和编程需求增加SIMT的一些前端…殊途同归的感觉罢了…
2. AWS Blackwell发布概述
AWS昨天发布Blackwell的官方文章《AWS AI infrastructure with NVIDIA Blackwell: Two powerful compute solutions for the next frontier of AI》[2]来看, 也阐述了很多GPU云的运营逻辑.
从CPU生态来看, 事实上的IaaS交付界面是X86指令集, 虽然ARM生态逐渐繁荣, 但是很多workload还是在X86上, 因此AWS在解释为什么除了GB200还要B200时也谈到了这个问题, 这也是云上要一些侧重生态的标准化算力交付的逻辑.

紧接着很长的章节在阐述Innovation built on AWS core strengths, 即基于AWS核心优势的相关创新. 主要也是围绕着下面这几点.
-
安全/稳定(Robust instance security and stability) -
性能/规模/弹性(Reliable performance at massive scale) -
效率/成本(Infrastructure efficiency)
我们在后面几个章节来详细展开分析.
3. AWS GB200机柜架构
AWS GB200机柜是一个完全自定义的结构, 和标准的NVL72单机柜不同的是, AWS用了两个NVL36双机柜的架构.

相对于单个NVL72的机柜, 优势是CableTray的复杂度降低一半, 故障时的爆炸域降低一半, 售卖规格也可以拆分为36卡和72卡两种. 当硬件故障时至多影响一个机柜, 可以大幅度的提高售卖率和维修停机时间.
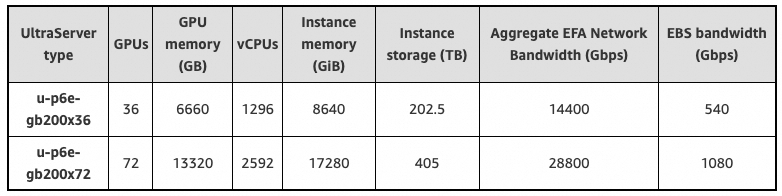
整个机柜上并没有独立的CDU, 每个ComputeTray采用2U高度. 单个机柜包含9个ComputeTray和9个SwitchTray. 两个SwitchTray采用铜缆背靠背连接.
4. AWS GB200 ComputeTray架构
相对于标准的ComputeTray, AWS改动了很多东西. 特别来说ScaleOut和FrontEnd网络合并到了8张400Gbps Nitro上, 实际上单个ComputeTray提供了3.2Tbps的带宽, 相当于配置4个CX8的GB200版本
标准的ComputeTray配置2颗Grace和4颗B200. 然后配置了一个BF3 DPU和4个CX7连接, 如下图所示

ComputeTray的PCIe拓扑在《NVIDIA GB200 NVL Multi-Node Tuning Guide》[3]中可以看到, 如下所示:
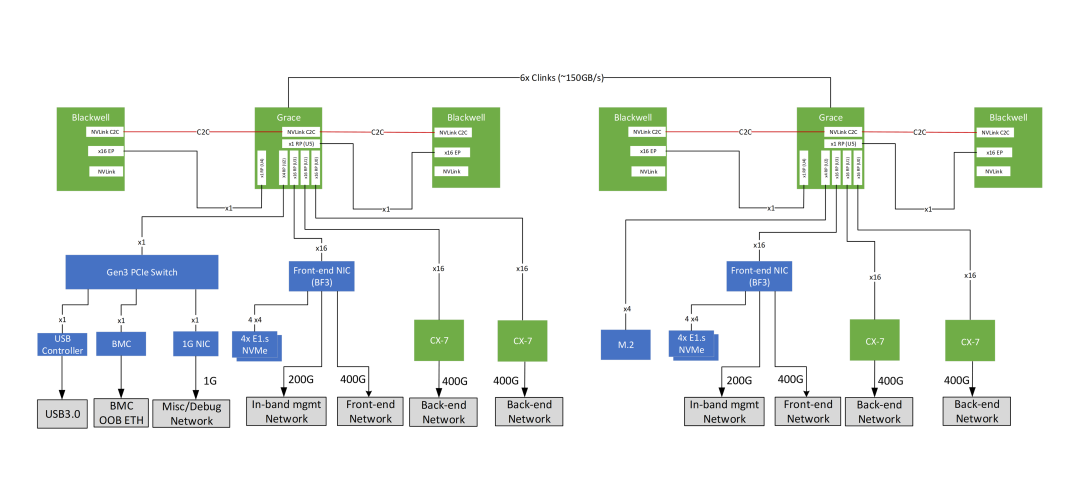
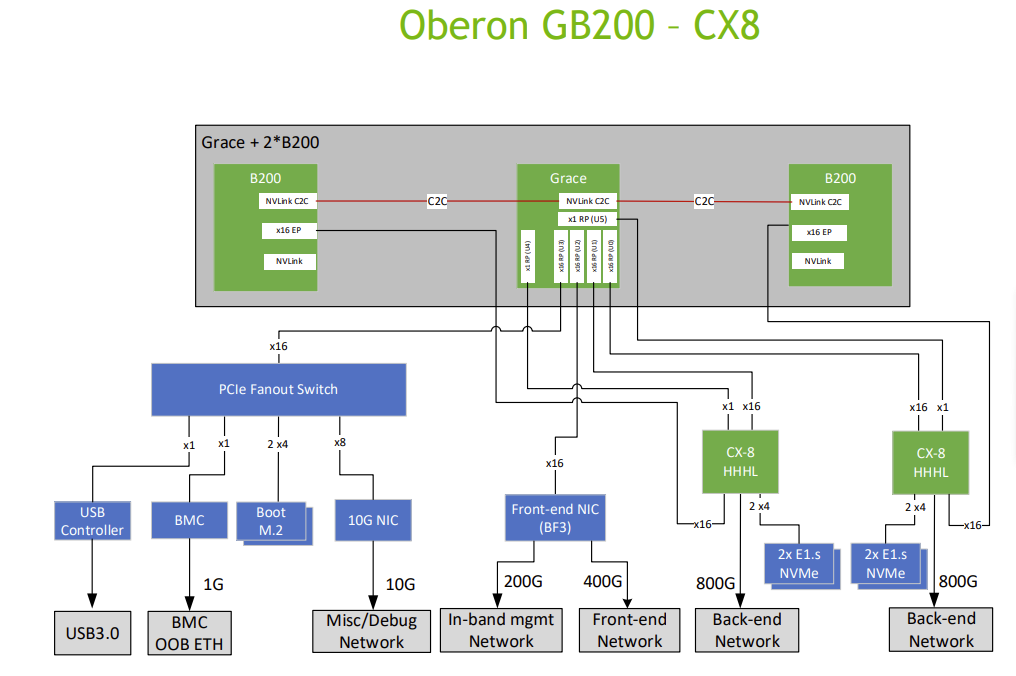
Blackwell通过一个PCIeGen6 x16连接到Grace, 然后BF3和CX7均连接到Grace上. 当然GB200理论上是可以支持CX-8每卡800Gbps的ScaleOut的, 如下图所示:
而AWS采用了9张400Gbps的Nitro构成, 如下图所示:

PCIe拓扑来自于文档《Maximize network bandwidth on Amazon EC2 instances with multiple network cards》[4]如下:
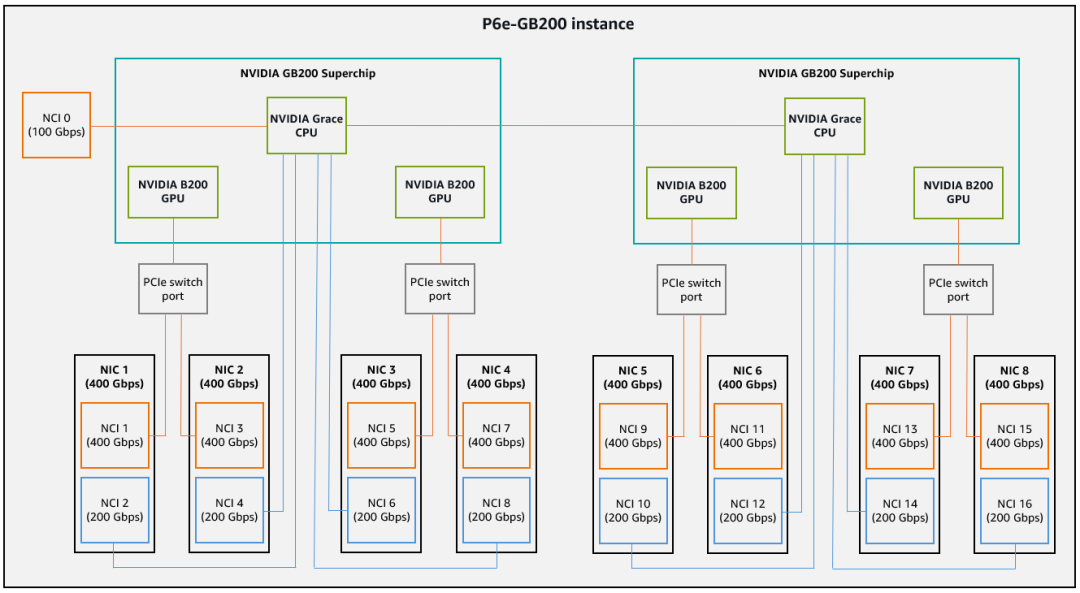
其中有一个Nitro 采用200Gbps作为DPU提供弹性裸金属的能力, 并且分配了100Gbps作为Primary NIC(NCI 0),剩余的60Gbps给了EBS, 40Gbps给了Nitro自身的管控. 这个接口配置为仅支持ENA(不支持EFA-SRD).
然后相对于官方的CX7版本, PCIe需要经过Grace. AWS提供了PCIe Switch可以直接连接到Blackwell. 每个400Gbps的Nitro提供一个x16的接口连接到PCIeSwitch, 同时还有一个x8的接口连接到Grace. 因此单个Nitro上可以创建两个网卡, 一个400Gbps的给GPU使用, 一个200Gbps的给Grace使用.
因此累计单个Grace可以支持4x200Gbps的带宽, 而单个B200虽然逻辑上看到可以支持2x400G, 但是同一张卡上的400Gbps连接GPU和200Gbps连接CPU是共享一个400Gbps的物理网口的. 另一方面文中有一段话:

实质来看, 例如当NCI1和NCI3都为400Gbps的时候, B200并不能运行到800Gbps, 而仅有400Gbps. 因此我估计是因为当前PCIeSwitch只支持Gen5导致的, 或者是PCIeSwitch和B200有兼容性问题暂时降速导致的? 也有可能Asterlab的PCIe Gen6交换芯片还没完全交付, 因此当前B200连接PCIe交换机仅支持Gen并提供400Gbps的能力, 估计后期上线后会采用轮转升级更换PCIeSwitch模组的方式进行升级.
另一方面需要注意的是, 以前通过ShallowSim仿真的一些分析结果来看, GB200的最佳实践ComputeTray还是需要满配4个CX8的版本才能匹配它的性能. 而AWS似乎在硬件上已经考虑到了这个问题, 同时很优雅的设计了FrontEnd和ScaleOut融合的架构.
当然为了解决这个问题, 特别是带宽争抢的问题, AWS给出了两个建议, 一个是给GPU配置4个400Gbps的网卡, 或者配置8个200Gbps的网卡. 我个人觉得配置8个200Gbps的网卡, 同时剩余的1.6Tbps的带宽给Grace也是挺好的一种选择, 这样对于KVCache和一些Agent执行的场景有很大的好处.
5. AWS GB200 网络
首先来看ScaleUP NVLink网络, 和标准的单机柜NVL72不同的是, AWS采用双机柜的模式, 因此SwitchTray为16个, 两个机柜的SwitchTray通过外部铜缆背靠背连接, 成本相对于单机柜的版本虽然高了一些, 但是也带来了一个优势, 这样的双并柜架构的CableTray的线缆密度降低了一半, 可靠性会有很大程度的提高, 并且单个ComputeTray的空间更大更利于散热, 并且当故障时最大的爆炸域仅单个机柜36卡…
然后我们来看ScaleOut网络和FrontEnd网络, 实际上AWS是完全融合了这两张网络的, 在同一张400Gbps Nitro上共享连接到CPU和GPU的带宽. 对于单个ComputeTray上行3.2Tbps的带宽和它们在Trainium 2上的规格是一致的, 这样整个网络是可以复用10u10p的基础设施的.
另外很重要的一点是, 我们可以看到ScaleOut的TOR放置在机柜内, 顶部和底部各放置了3台, Nitro通过铜缆连接到TOR, TOR再通过光上连. 这样第一跳的可靠性由于采用铜缆MTBF会高很多, 而后续的TOR上行光口故障影响带来的流量损失影响也是会小很多的.
另一方面由于AWS EFA采用SRD支持多路径转发, 因此没有必要构造专用的多轨道的拓扑, 并且我们可以看到单个GPU有两个Nitro承载流量, 实际的可靠性也高了很多, 即便是单个Nitro网卡故障, 也可以通过另一个网卡获得400Gbps的ScaleOut能力.
6. AWS GB200 管控节点
我们注意到在视频中还有这样一个特殊的节点

展开来看它应该是一个双路的X86服务器, 配置了两个Nitro网卡, 前段还有2颗交换机芯片对外提供24个接口

但是从实际的部署来看, 9个NVLinkSwitch上有线连接到这个节点, 并且这个节点左侧还连接了至少7根线. 从线缆类型(特别是从接头)来看, 感觉这应该是一个PCIe的连接器.
大概估计这是一个管理节点, 可能NVLinkSwitch的一些Fabric Manager相关的软件被通过PCIe拉远到了这个管控节点上.
7. AWS GB200 散热设计
另一个值得关注的是AWS GB200的散热设计, 它没有采用柜内的CDU, 而是采用能够复用原有数据中心基础设施的IRHX(In-Row Heat Exchanger)的方式, IRHX 系统在靠近服务器行的地方循环冷却液体, 并通过可扩展的风扇冷却的方式, 同时提高了水资源的利用率.

IRHX和算力机柜并排部署(in-Row):
它包含三个组件, 配水柜/水泵柜和风机柜

特别的说, IRHX可以根据这一排的热功耗增加和减少风机柜, 比起其它GPU云新建机房, AWS这样的处理方式做到了对基础设施更小的改动.
8. 从云的视角来分析
我们注意到最近Dell已经交付GB300给Coreweave了, 而AWS的GB200才刚刚上线, 相对来说晚了几个月. 而AWS在整个系统结构的设计上有很多值得我们学习的地方.
从云的弹性售卖逻辑来看, 它提供了36卡/72卡两种规格, 并且有一个专用的管理节点, 未来可能还会有更小的规格提供.
另一方面比起原厂的单机柜NVL72高密度的部署, 它采用了双并柜的方式, 故障时的爆炸半径更小. 例如单个机柜的CableTray故障或NVSwitch故障只会最多影响到36卡, 剩下的36卡还可以继续使用.
它的通过9个Nitro卡提供了3.4Tbps的带宽, 其中3.2Tbps可以用于融合ScaleOut和FrontEnd, 这种方式对于推理中的KVCache和Agent执行有很大的价值. 相对于NV在存储上只有一张BF3 400Gbps, 基于Amazon FSx for Lustre提供更高的存储能力
存储/VPC和ScaleOut的融合可以说是AWS GB200的最大亮点, 并且由于EFA SRD支持多路径转发, 因此交换网络并没有采用多轨道的部署方式, 而是单个机柜的所有Nitro都通过铜缆接入到了TOR中. 再通过TOR上行多根光纤接入到数据中心网络. 这样第一跳由于不会像传统的多轨道方式用光互连, MTBF好了很多, 同时单个GPU配置了两个Nitro, 单Nitro故障后依旧可以通过另一个Nitro继续使用…
另一方面相对对称的CLOS拓扑更加容易部署, 偷偷的出一个思考题, 在GB200上Rail能做多少个, PXN有什么限制… 为什么AWS SRD会这么做…
从经营上来看, 它不光提供GB200的P6e实例, 还考虑到一些用户程序CPU代码还在x86上运行, 以及workload相对较小的情况, 推出了8卡B200的P6实例. 同时它们还在这次宣传中强调了一些热升级的能力. 处处都显示出一个成熟的云服务提供商深度思考后的选择和定制.
当然客观的来讲, AWS也有一些失误, 例如EFA-SRD在生态上和RDMA RC Verbs不兼容, 使得开源生态支持上有一些难度, 例如DeepEP/IBGDA, 这些是值得改进的地方…
华为NPU昇腾芯片是否属于重大战略方向性失误,应该选择GPGPU,导致CANN软件栈面临作废状态?: https://www.zhihu.com/question/1925252282942988983
[2]AWS AI infrastructure with NVIDIA Blackwell: Two powerful compute solutions for the next frontier of AI: https://aws.amazon.com/cn/blogs/machine-learning/aws-ai-infrastructure-with-nvidia-blackwell-two-powerful-compute-solutions-for-the-next-frontier-of-ai/
[3]NVIDIA GB200 NVL Multi-Node Tuning Guide: https://docs.nvidia.com/multi-node-nvlink-systems/multi-node-tuning-guide/system.html
[4]Maximize network bandwidth on Amazon EC2 instances with multiple network cards: https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/efa-acc-inst-types.html
(文:极市干货)