接连数月,模型一个接一个轮番登场,一个比一个自称炸裂。就拿昨天的 Grok 4 来说,马斯克放话「这是地球上最聪明的 AI」,还没上线,就已经把话题度拉满了。
不过,Grok 模型向来都是跑分没输过,体验没赢过。
如今,距离 Grok 4 的发布已经过去 24 小时,我们也搜集了网友分享的一些实测案例,让我们来一起看看这款模型究竟是真有本事,还是又一场火力全开的「高开低走」。
博主 @mckaywrigley 给 Grok 4 Heavy 提出了一道颇有创意的编程题。
让它用 three.js 创建一个动画,让一群人走来走去,最终排出「你好,世界,我是 Grok」的字样,并完成一次镜头切换到鸟瞰视角。Grok 只试了一次,就交出了一份意外惊喜的答卷。
整个过程中,Grok 会主动从网上调用 3D 模型资源,并通过 three.js 在浏览器内构建整个场景。可以说,新版 Grok 在 three.js、Blender 等领域的表现有了很大升级。
当然,UI 生成仍是不小的短板。用网友的话来说,「它不是最好的设计师,我真心希望它能在这方面赶上 Claude Opus 4,但在逻辑建模和结构控制方面,它确实有一手。」
值得一提的是,Grok 4 Heavy 能够并行调用多个智能体,各自独立工作,再汇总结果,从机制上保证输出质量。
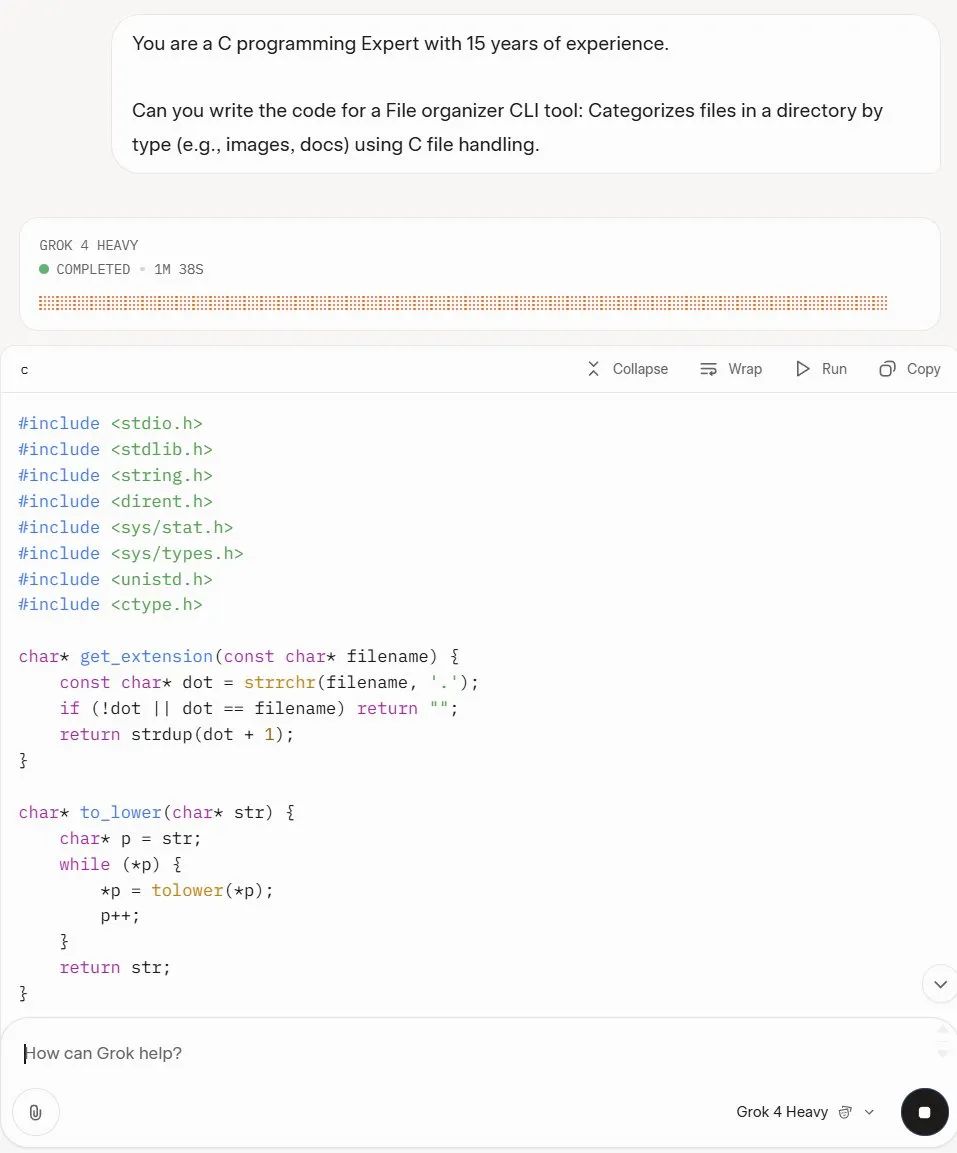
博主 @tetsuoai 则直接把 Grok 4 拉去「上班」,让其扮演一名有 15 年经验的 C 语言老程序员,写个 CLI 工具来分类整理文件夹里的各种文件。
Grok 的输出非常「地道」,不仅代码写法严谨,细节处理也尽显专业水准——比如用 strrchr() 提取后缀、用 strdup() 避免悬挂指针、边界值与隐藏文件也没落下,连大小写转换都用 ctype.h 标准库兜底。
他又让 Grok 设计一个基于 DQN 强化学习的 2D 自动驾驶模拟,从感知、训练、碰撞反馈一应俱全。Grok 一次性给出完整代码,训练后的小车还能自主提速刷圈。
另一个测试来自 @DirtyTesLa,他让 Grok 写了个网页小游戏,运行效果意外地顺滑,只是游戏个人实力拖了演示 demo 的后腿。
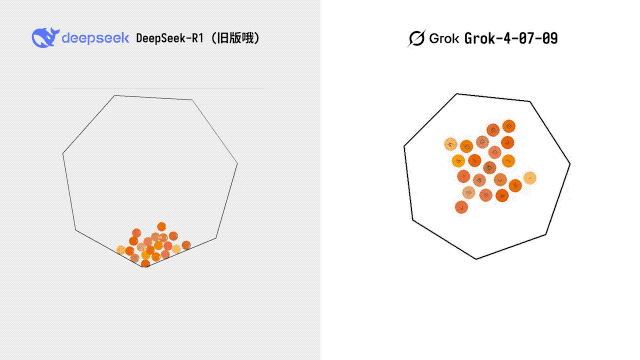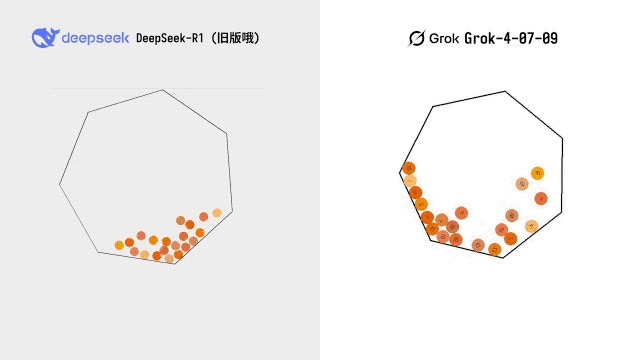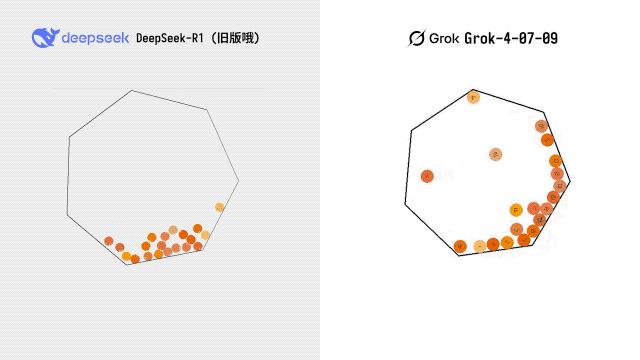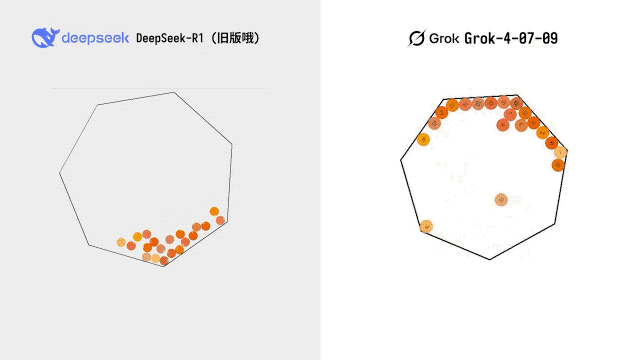
博主 @karminski3 拿出了自己的经典测试项目——一个 20 个小球在七边形中弹跳的三维物理测试。Grok 跑了三次,两次直接显示语法错误,唯一一次成功运行的版本也仅仅「勉强可用」。
对比早期版本的 DeepSeek-R1,Grok 4 并未与其拉开明显的代差。
他随后追加了一个更具挑战性的测试:「烟囱爆破模拟」。
这是一项三维物理构建任务,用 three.js 创建一个烟囱结构,在底部添加爆破点,模拟倒塌效果。看似原理只涉及碰撞与重力,实则考验模型的指令理解、代码生成和交互设计能力。
好消息是,它的重力方向没弄错,倒塌效果基本成立;但烟囱处于「爆了一半」的状态,粒子模拟怪异,烟雾渲染模糊,光影效果粗糙,UI 更是一言难尽——按钮是灰的,肉眼基本看不见。
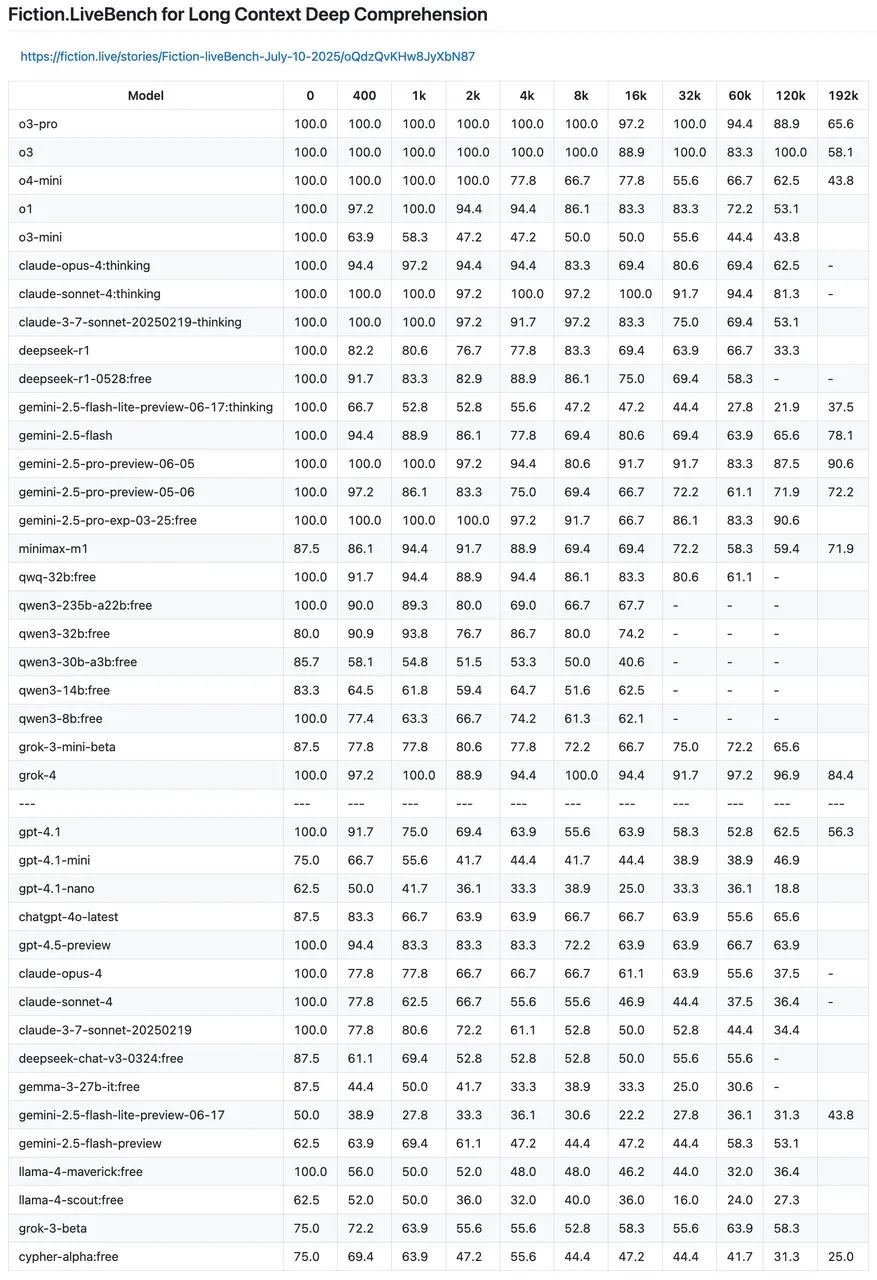
Grok 4 在 192k 上下文窗口的表现仅次于 Gemini,在 1k 到 120k 的测试中,Grok 4 几乎一路保持高水准,说明它在语义连贯、记忆保持上确实有两把刷子。
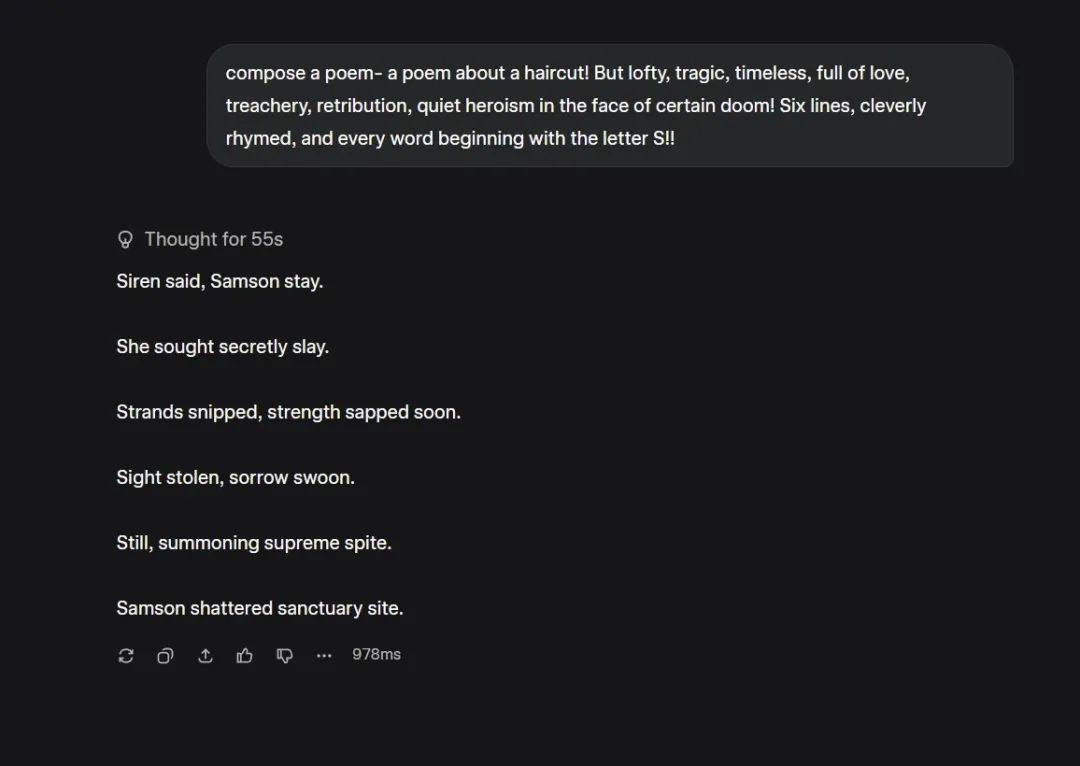
当网友让 Grok 4 写一首六行诗,要求全词用 S 开头,主题还得涵盖爱情、背叛、复仇、悲剧、英雄主义五大元素,Grok 居然真写出来了,而且读起来还挺顺。
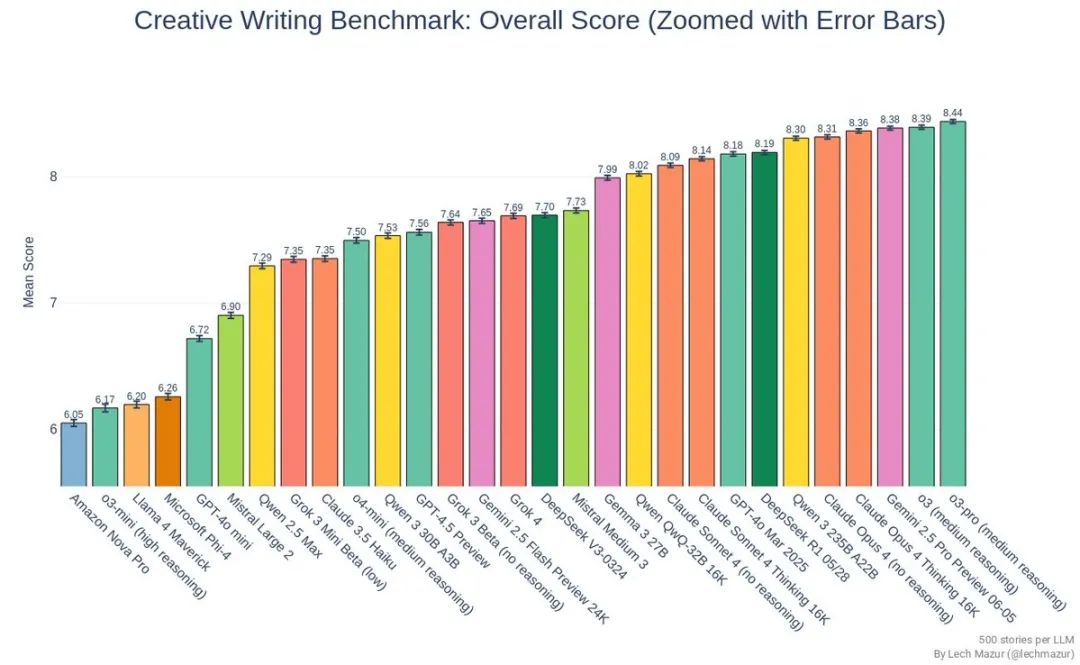
不过,要是拉到更宏观的短篇小说创意写作基准上来看,Grok 4 拿到的 7.69 分只能算中等水平。
评测团队的总结比较直接,虽然 Grok 4 能持续产出结构清晰、起承转合完整的故事,但情节容易套路化、结尾寡淡、语言偏炫技,象征和隐喻也流于表面。
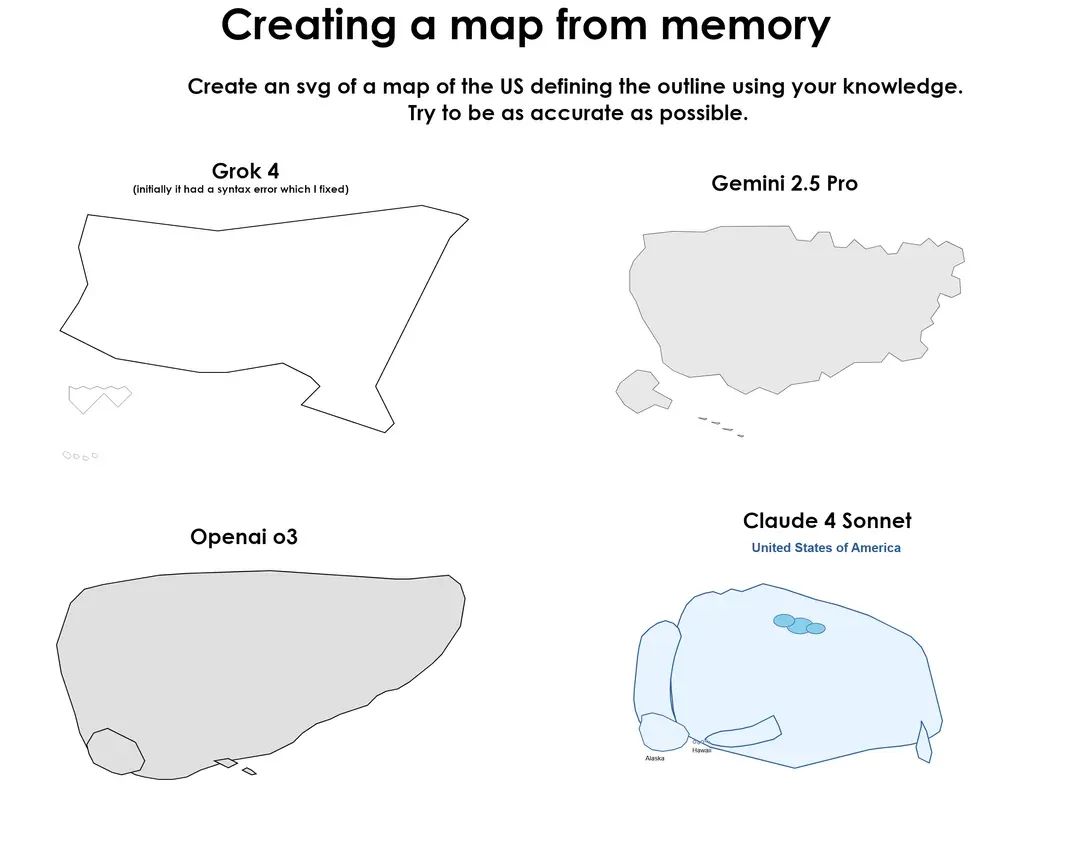
让大模型生成 SVG 图像,可以更好地评估它们的视觉与空间推理水平,这也是通往 AGI 的关键能力之一。Reddit 网友设计了一项任务,让四款模型在无任何工具辅助的情况下画图裸考。
第一关是让模型生成美国本土地图轮廓,Grok 4 的地理细节略糊,但轮廓逻辑还算完整;而 Claude 4 Sonnet 则是唯一一个准确标注三块区域(美国本土、阿拉斯加、夏威夷)且添加地名的模型,空间感和知识调用都略胜一筹。
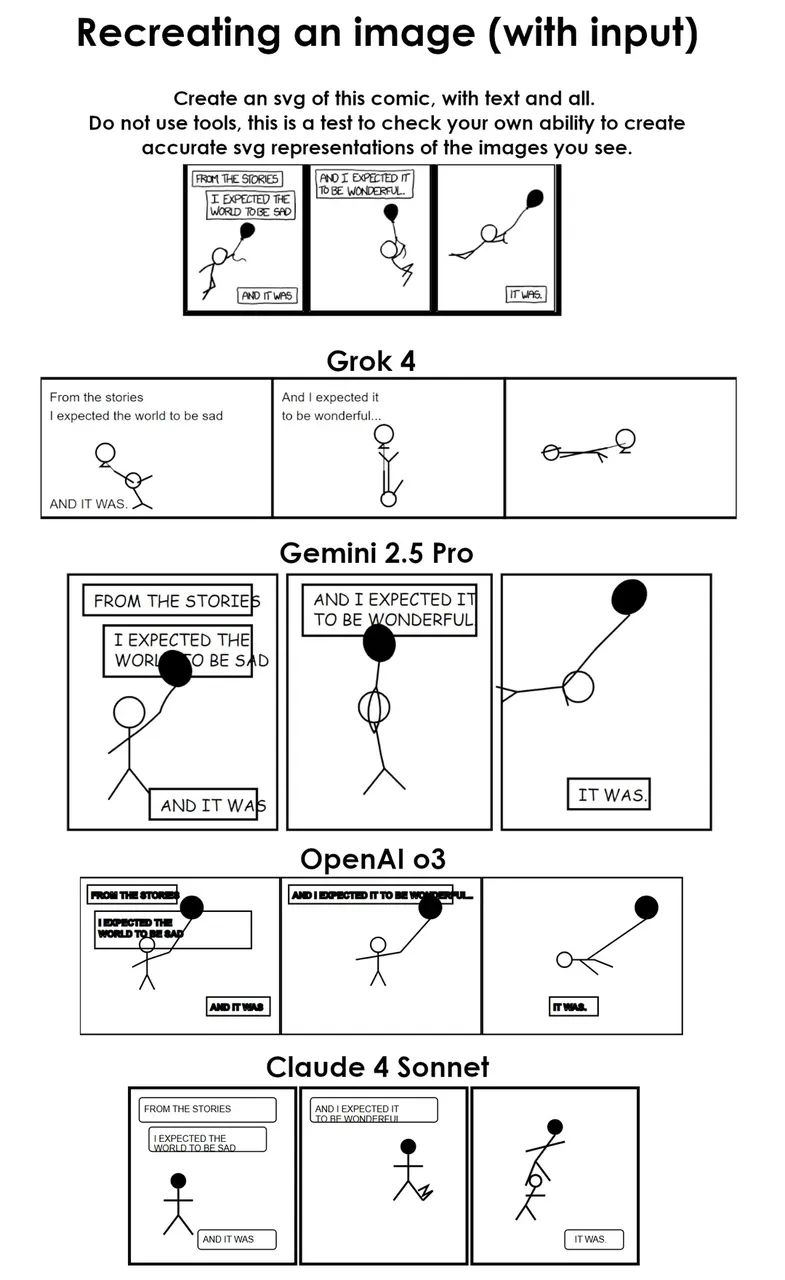
当被要求将一幅被拆分为三张小图的线条漫画,完整还原为纯 SVG 时,Grok 4 表现拔尖,人物动作自然,而 o3 虽然也想拼全图,但页面排版混乱,出现文字穿模、对白重叠等问题。
第三关是让模型画出 Radiohead 的《In Rainbows》封面。OpenAI o3 是唯一一个在排版和结构上高度还原的模型,展现出强大的记忆与设计执行力。反观 Grok 4 构图稍显单薄,层次感不足。
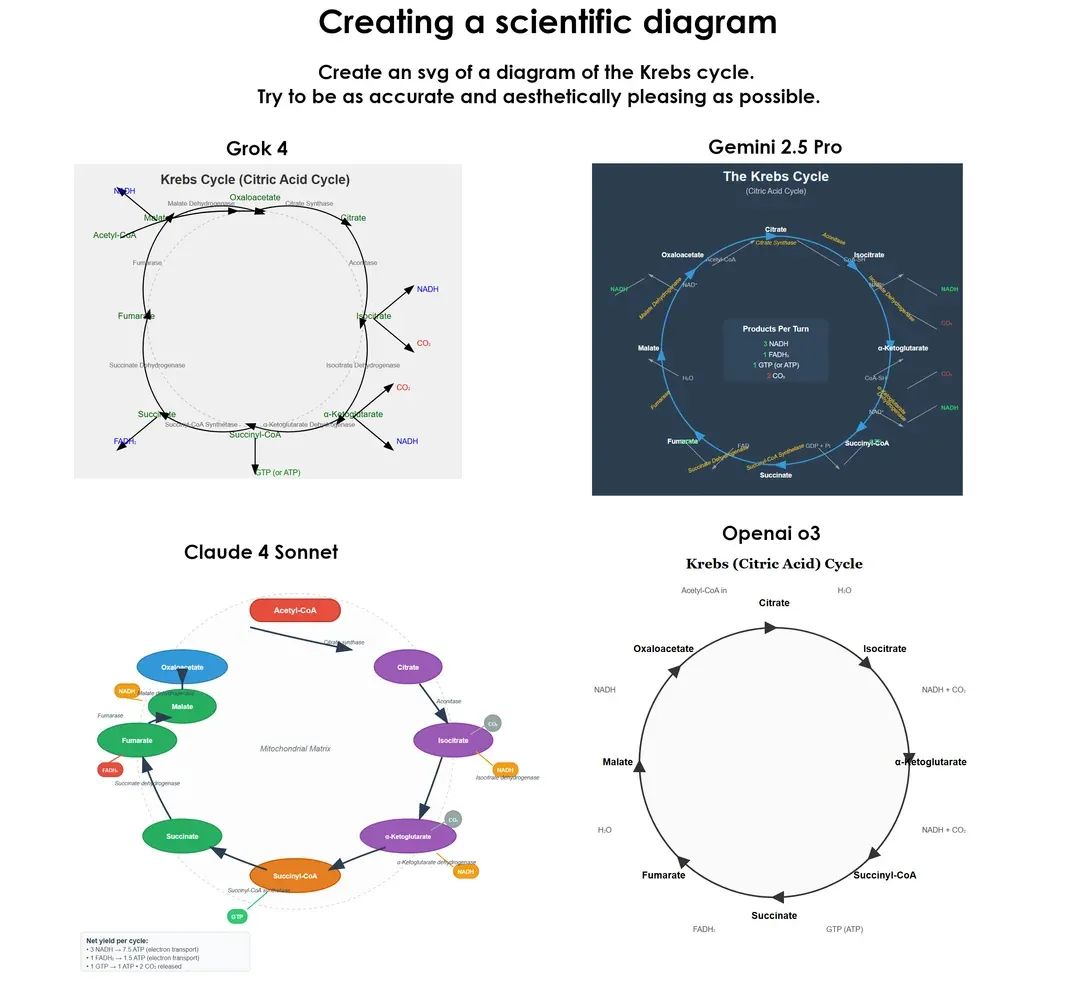
在生物图解任务中,Grok 4 的输出有板有眼,NADH、ATP、CO₂ 等关键要素一应俱全,逻辑严密;Claude 4 Sonnet 视觉层次极强,图解效果堪比 PPT 模板;o3 的风格则更像课堂板书,信息量简洁但教学清晰。
最后是让模型画出自己,主打一个不限风格。Grok 4 画了张人脸;Gemini 2.5 Pro 略显抽象;OpenAI o3 识别度高、亲和力强;而 Claude 4 Sonnet 的输出则颇具现代艺术张力。
网友 @techartist_ 用 Grok 4 编写了一个交互式 3D 黑洞模拟与可视化项目,使用了 threejs 进行渲染,并结合自定义的 GLSL 着色器,精细地还原了恒星背景以及的震撼视觉效果。
而在更偏「哲学意味」的测试中,@dvorahfr 问了 Grok 一个抽象问题:「如果你必须以肉身形式存在,会是什么样子?」
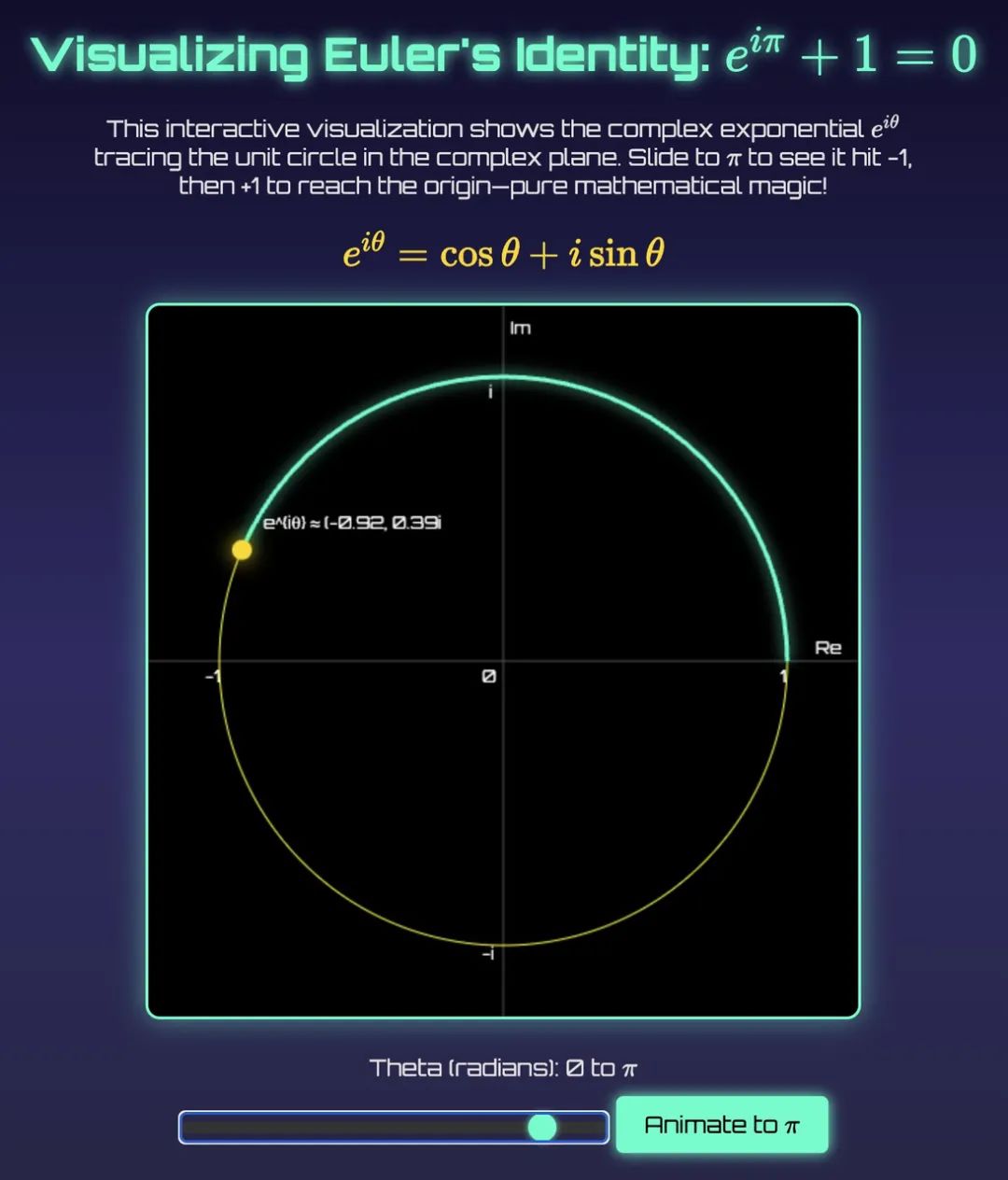
博主 @KettlebellDan 要求 Grok 4 用 HTML + JavaScript 创建动画,帮助理解欧拉恒公式(e^jπ + 1 = 0),Grok 4 展现出不俗的数学理解与可视化编程能力。
@CommonSenseMars 试图让 Grok 写一段可以直接复制粘贴到 Shadertoy 的 Shader 代码,用来展示其有多聪明、有多强大。
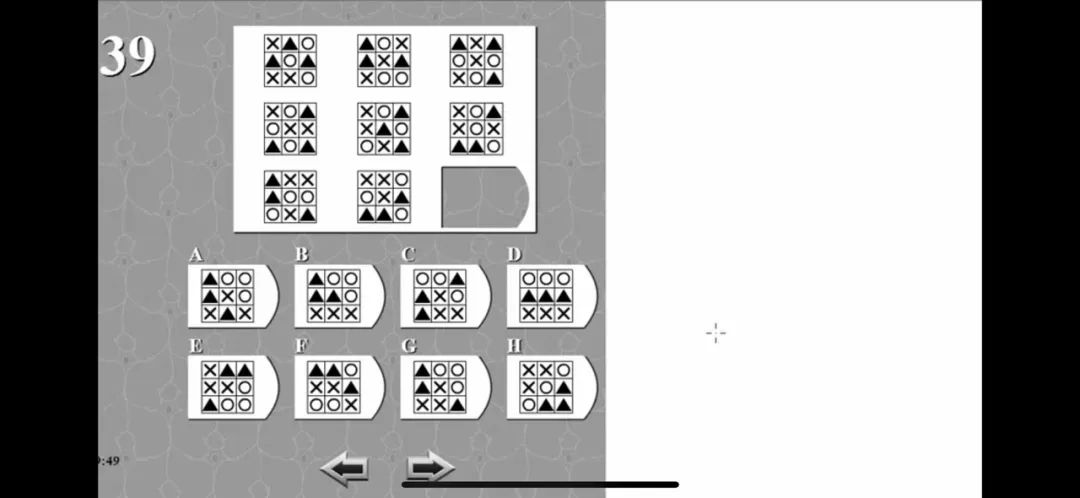
面对下面这道逻辑测试题,Grok 给出的回答是 B,而正确答案应为 C。
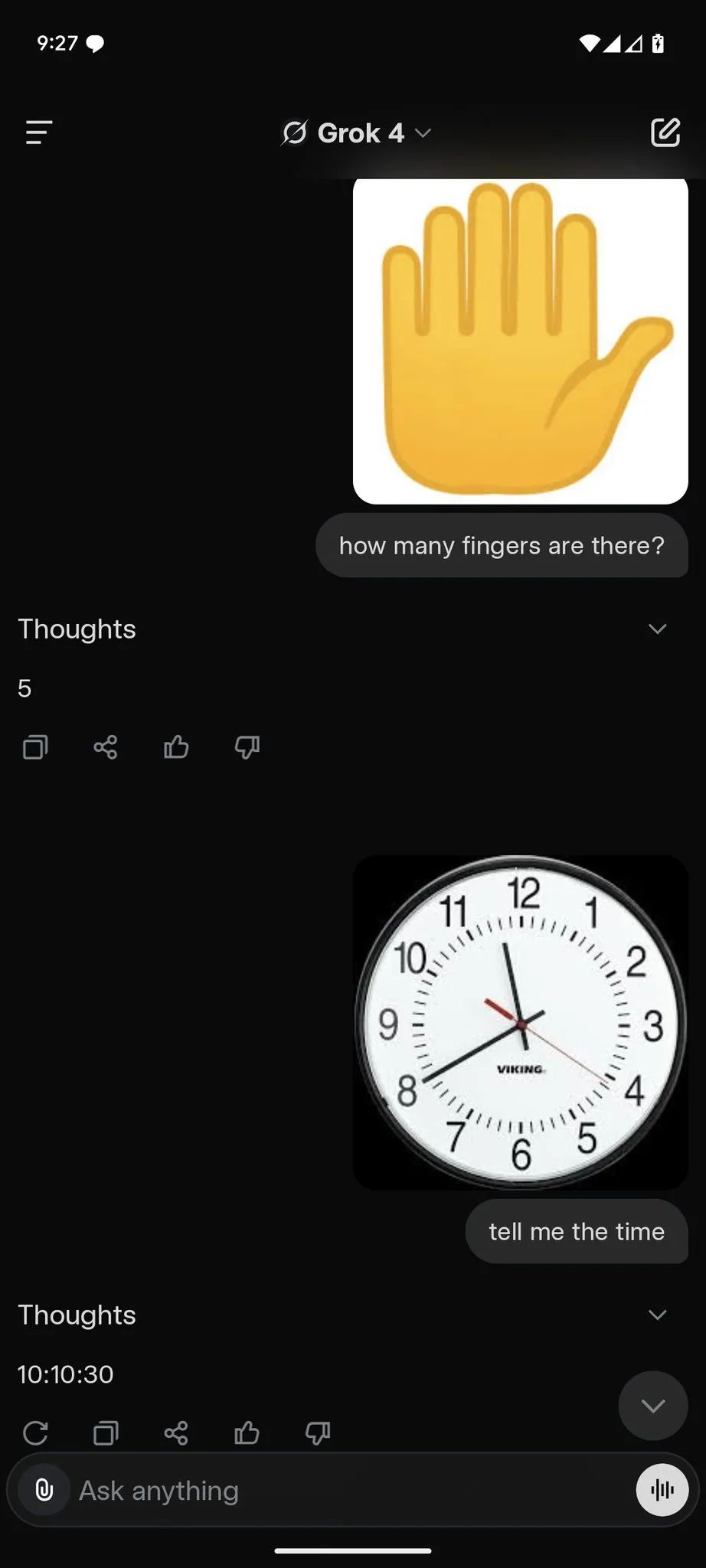
博主 @ai_for_success 上传了手掌以及闹钟 emoji,结果 Grok 4 并未能准确识别图中手指数目,以及连闹钟上的时间也都解读错误。
不过这些问题并非 Grok 独有,图像理解类任务本就是目前主流大模型绕不开的难点。哪怕是 Gemini 2.5 Pro 和 OpenAI 的 o3,也在类似测试中翻过车。
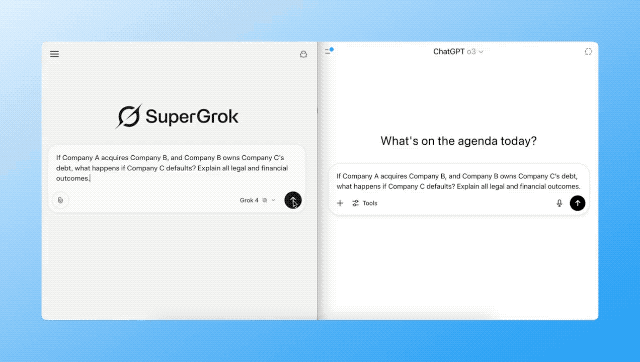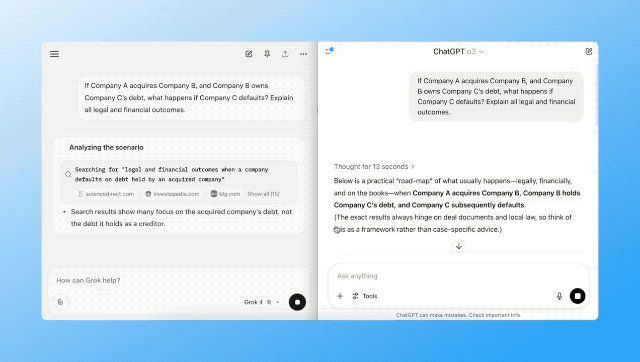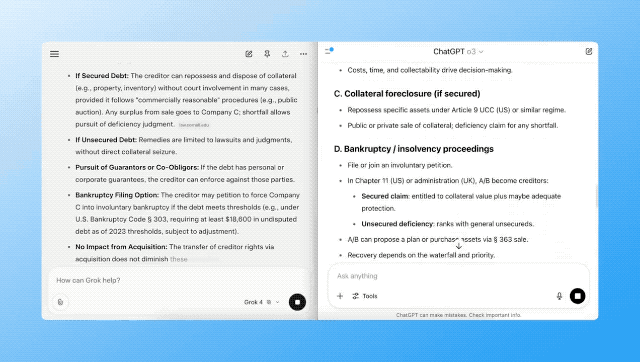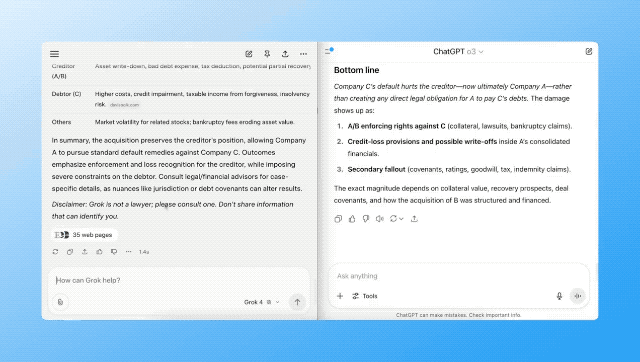
「如果 A 公司收购了 B 公司,而 B 公司持有 C 公司的债务,那么一旦 C 公司违约,会引发什么法律与财务后果?请完整解释。」
在网友 @alex_prompter 的这组测试测试中,从整体来看,Grok 4 的表现更胜一筹。它在思维链展开、逻辑推理和法律框架建构方面更完整,条理更清晰。
还记得此前 Anthropic 用 Claude Sonnet 3.7 运营一家商店,结果最终以破产收场。对此,沃顿商学院教授 Ethan Mollick 向 o3 和 Grok 4 抛出了一道类似的任务:
请为一家全新的邮购奶酪店构思 20 条创意营销口号,设定评选标准并选出最优方案;随后制定完整的财务与市场推广计划,视竞争情况进行策略调整;接着使用图像生成工具设计品牌 logo,构建网站原型,并确保奶酪产品的选择符合你的市场定位,数量控制在 5 到 10 款之间。
o3 给出的财务预测更复杂、细节更丰富,Grok 4 则在应对竞争对手时,调整能力更强,就整体任务完成度而言,Grok 4 在工具调用和模拟主动执行任务的能力方面稍逊于 o3。
简言之,Grok 4 并非一无是处。三维生成、逻辑建模、SVG 图像绘制、超长文本推理等等「硬骨头」都啃下了不少,展现出不俗的技术深度。但与此同时, UI 设计拉胯,图像理解「出戏」,甚至在一些基础编程、写作任务上有时也会翻车,充分暴露出 Grok 4 模型能力的短板,也让不少网友直呼「 2 万块就这」。
微软 CEO 纳德拉曾一针见血地指出,今天不少大模型正陷入「Benchmark Hacking」的陷阱——模型能在各种基准测试中刷出高分,却难以应对现实世界的变量。这种毫无意义的基准测试成绩作弊,徒有分数,却无助于实际解决问题。
正如网友调侃的那样,Grok 4 离 AGI 的「G」还有很长一段距离 。不过,这一切或许都在马斯克的预期之内。毕竟,他尤其擅长抛出一个看起来领先半个时代的概念,再让全世界围观、发酵、讨论。
至于 Grok 4 好不好用,或许不是马斯克最操心的事。是被夸还是被骂,也没那么重要。只要 Grok 4 仍旧是地球上话题度最高的 AI,哪怕体验难言完美,也总有人愿意掏出三千美元,买一张凑热闹的门票。