

FiS-VLA团队 投稿
量子位 | 公众号 QbitAI
让机器人学会聪明且快速精准执行,一直是机器人操控领域的难题。
为了解决这个问题,香港中文大学、北京大学、智平方和北京智源研究院联合创新性地提出了Fast-in-Slow(FiS-VLA),即一个统一的双系统VLA模型。
它通过将慢系统2最后几层的Transformer模块重新构建为一个高效的执行模块,用作快系统1,从而在一个模型中实现了快慢系统融合。

这种创新范式首次在单一预训练模型内实现慢速推理与快速执行的协同,突破了传统双系统分离瓶颈。
从此,系统1不再是“门外汉”,它直接继承了VLM的预训练知识,能无缝理解系统2的“思考结果”(中间层特征),同时自身设计保证其能高速运行。
在真机测试中,研究团队在AgileX和AlphaBot两个双臂机器人平台上分别设计了8项任务,如“擦黑板”、“倒水”、“折叠毛巾”等。FiS-VLA成功率分别达到68%和74%,比Pi0模型提升超过10个百分点。
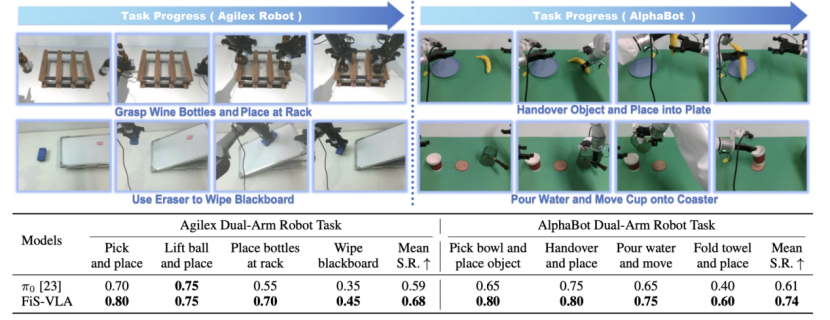
此外,FiS-VLA在泛化任务中表现也十分稳健。无论是未见过的新物体、复杂背景干扰,还是光照条件变化,它都能保持50%以上的成功率,而其他模型则普遍出现性能大幅下滑。
方法:首个“ 异构输入+异步频率”双系统VLA模型
尽管近年来的视觉-语言-动作模型(VLA)开始借助互联网规模预训练的视觉-语言模型(VLMs)提升常识推理能力,但这类模型动辄数十亿参数,以及基于自回归生成动作的策略,导致在执行速度上往往表现不佳。
受心理学家丹尼尔•卡尼曼大脑快慢双系统理论的启发,业界把“双系统”设计引入VLA大模型,利用基于VLM的慢系统2模块处理高级推理,并使用独立的快系统1动作模块负责实时控制。
但是,现有的设计是将两个系统保持为独立模块,限制了快系统1充分利用慢系统2的丰富预训练知识,即系统1这个“运动员”很难充分吸收系统2“学霸”的渊博知识。
团队提出的Fast-in-Slow(FiS-VLA),实现了在一个模型中快慢系统融合。
考虑到FiS-VLA中两个系统在角色上的根本差异,研究者引入异构模态输入与异步运行频率策略,使得模型既能实现快速反应,也具备精细操控能力。
此外,为提升两个系统之间的协调性,研究者提出了一种双系统感知协同训练策略(dual-aware co-training strategy):一方面为系统1注入动作生成能力,另一方面保留系统2的上下文推理能力。
这样就有效解决了传统VLA模型执行频率低、推理与动作割裂的问题,真正做到“谋动并行”。

在模型评估中,相比于现有的SOTA VLA方法,FiS-VLA在仿真任务中提升了8%的平均成功率,在真实环境下提升了11%,并实现了117.7 Hz 的控制频率(动作块大小为8)。
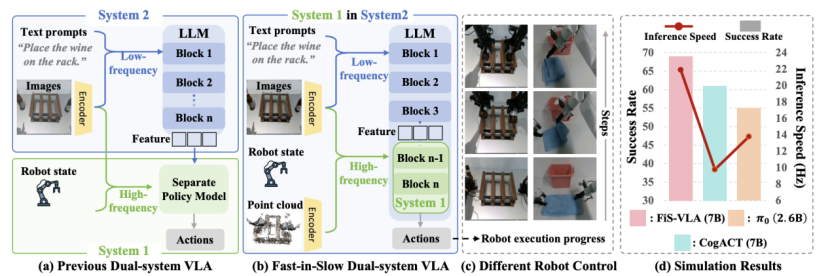
由于系统2与系统1在职责上存在根本差异:系统2负责理解,它处理语言指令和2D图像,提取任务语义,节奏偏慢;系统1负责执行,它读取机器人状态、3D点云和当前图像,生成高频控制动作,节奏极快。
因此,FiS-VLA对这两个系统进行了专门设计:它们接收不同模态的输入,并以异步的频率运行。
两套系统虽任务不同,但运行逻辑连贯、数据互通。系统1使用系统2的中间语义表示作为指导,同时结合自身输入,实现高速精准的动作生成。
为了处理点云数据,研究者设计了一个轻量级的3D tokenizer。它可以把复杂的空间信息压缩成高维token,并通过视觉编码器提取局部几何特征。这一做法不仅高效,还让系统1拥有敏锐的空间感知能力。
在系统运行节奏上,FiS-VLA采用异步频率设计。系统2慢慢思考,系统1快快执行。比如系统2每跑一次,系统1可以连续运行4次。这种机制让推理不会成为瓶颈,而动作响应也足够及时。
值得一提的是,快慢双系统融合正在成为VLA大模型领域的共识,但在异步架构的突破设计上,FiS-VLA目前仍是领跑同行。
训练:“双系统”协同训练,相辅相成
训练过程也很有讲究。
FiS-VLA的核心目标是生成精确且可执行的动作,因此特地采用了“双系统感知协同训练”策略:
对于执行模块(系统1)使用了扩散建模(diffusion modeling)中概率性与连续性的特点,通过向系统1的嵌入空间注入带噪动作作为潜在变量,来学习动作生成,具体如下:
给定初始动作序列ãτ,研究者在随机时间步τ ∼ U(1, T)(其中τ ∈ Z,T = 100)注入高斯噪声η ∼ N(0, I)。前向过程以闭式添加噪声:
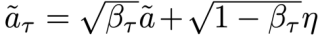
其中βτ为预定义调度表的噪声缩放因子。为训练系统1(π_{θ_f}),将学习过程建模为以下目标的优化问题:
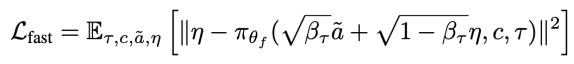
其中c表示条件源,包含系统2提取的低频潜在特征和系统1的高频输入。由于系统1执行模块嵌入在系统2的VLM中,若仅针对扩散动作生成训练模型,可能导致其自回归推理能力灾难性遗忘。
因此,研究者提出联合训练目标,对于推理模块(系统2)保留其高维推理能力,采用自回归逐token预测的范式作为训练目标,生成离散的语言或动作,避免慢系统发生灾难性遗忘。
以离散动作为例:
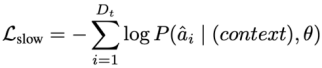
其中D_t为离散动作词元总长度,â_i为第i个真实动作词元,P(â_i | context, θ)为LLM在输入上下文和参数θ(θ_f ⊆ θ)下的预测概率。最终整体训练目标为:
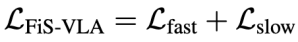
从上面可以看出,两个系统的目标不同,但训练是同步进行的。系统1学“怎么动”,系统2学“想清楚再动”。这种策略避免了模型遗忘系统2的推理能力,也让两个系统在统一模型中共同优化。
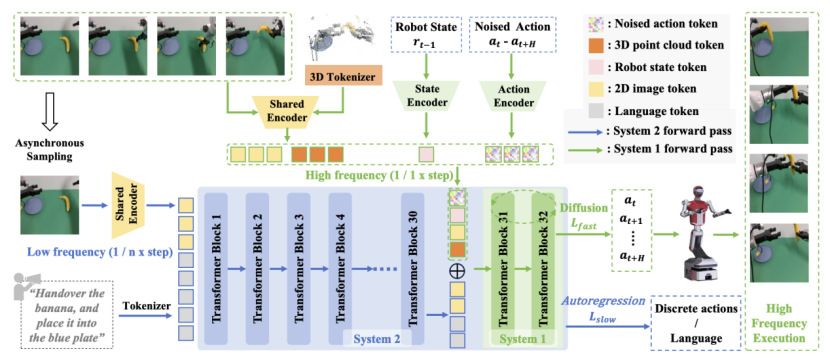
此外,在预训练阶段,研究者用到了超过86万条机器人任务轨迹,涵盖多个机器人平台。FiS-VLA主干采用的是参数量7B的LLaMA2大语言模型,视觉部分采用了SigLIP和DINOv2编码器,兼顾语义和空间表达。
效果:仿真&真机成功率提升显著
在RLBench仿真任务中,FiS-VLA在10个任务上取得了69%的平均成功率,明显优于CogACT(61%)和Pi0(55%)。尤其值得注意的是,FiS-VLA在10个任务中有8个任务表现优越,突显了其在动作生成方面的鲁棒性。
同时,在控制频率方面,FiS-VLA在动作块大小设为1的情况下达到了21.9 Hz的控制频率,运行速度是CogACT(9.8 Hz)的2倍以上,也比Pi0(13.8 Hz)快超过1.6倍。

消融实验
为了更细致地验证模型设计,研究者进行了多轮消融实验。
首先测试了系统1在系统2中共享的Transformer块数量。结果显示,随着共享块数量的增加,操控性能逐步提升,并在使用两个块时趋于饱和。
然后考察系统1的输入模态。实验表明,机器人状态、2D图像、3D点云缺一不可。尤其是3D点云,在精细动作控制中发挥了关键作用。
他们还研究了系统运行频率的配比。系统2与系统1之间的异步运行频率比为1:4时,FiS-VLA取得了最佳性能,在慢速推理与快速动作生成之间达到了理想平衡。这验证了异步协调频率设计不仅提升了动作生成速率,同时也增加了传递给执行模块的观察信息的丰富度。
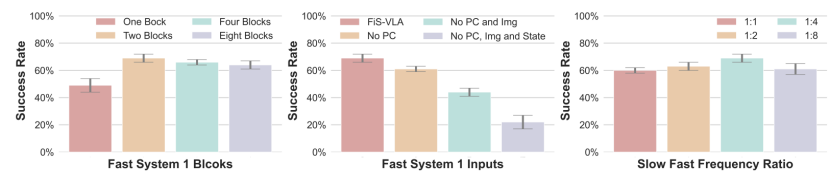
为了进一步提升控制效率,FiS-VLA还引入了“动作分块”机制。即每次预测多个连续动作,而不是逐步推理。这样做能降低误差积累风险,同时提升动作连续性。
结果表明,在动作块设置为8的情况下,模型成功率保持稳定,而控制频率则飙升至117.7Hz。机器人行为更加流畅,决策更少、执行更稳。
泛化能力
更难得的是,FiS-VLA在泛化任务中表现依旧稳健。无论是未见过的新物体、复杂背景干扰,还是光照条件变化,它都能保持50%以上的成功率。而其他模型则普遍出现性能大幅下滑。
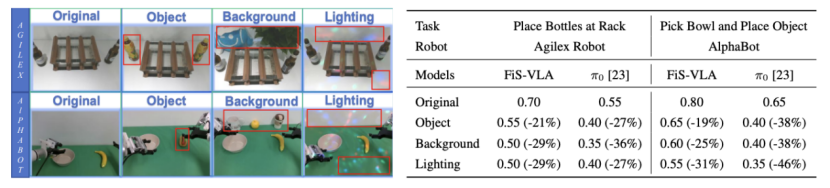
这背后正是快慢系统融合带来的好处:系统2能够理解语义,找到任务核心;系统1能够根据感知迅速反应。二者结合,使模型具备强泛化能力与鲁棒性。
目前FiS-VLA的结构仍是静态配置:Transformer共享层数、系统频率比都需提前设定。研究者计划在未来探索动态调参机制,让模型能根据任务复杂度和环境自动调整运行策略。
这种自适应机制将进一步释放FiS-VLA的潜力,让它更接近通用智能机器人的核心大脑。
总结来看,FiS-VLA不是对已有模型的简单优化,而是一种全新的架构思路。它打通了思考与行动、语义与物理、计划与执行之间的壁垒。
它不仅让机器人“会想”,更让它“快动”;不仅理解复杂任务,还能高频率完成。
这或许就是未来通用智能机器人的基础形态——既有认知大脑,又有灵巧身体,统一于同一个神经系统中。
论文链接: https://arxiv.org/pdf/2506.01953
项目主页: https://fast-in-slow.github.io/
代码链接:
https://github.com/CHEN-H01/Fast-in-Slow
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)