


|
“同时做大脑和本体,看起来可能会非常难,但对我来说,因为我都能做,所以这是一个自然选择。”
|
文|邱晓芬 苏建勋
编辑|苏建勋
“外界对我们的认知,和我们实际的业务状况,确实存在一定差距。”在「星动纪元」的北京办公室中,创始人陈建宇对《智能涌现》表示。
「星动纪元」成立于2023年8月,由清华大学交叉信息研究院助理教授陈建宇创办。2025年7月7日,「星动纪元」宣布完成近5亿元A轮融资,由鼎晖CGV资本和海尔资本联合领投,厚雪资本、华映资本、襄禾资本、丰立智能等跟投,老股东清流资本、清控基金等继续追加投资。
尽管成立不过两年,在机器人硬件业务上,「星动纪元」接连发布了灵巧手、轮式、全尺寸人形等产品,这些动向,让不少人误将星动纪元视作一家机器人本体公司,甚至“觉得我们是一家灵巧手公司”。
这不是陈建宇希望公司被贴上的标签。
做一款通用、智能的机器人,是陈建宇在近十年前看到AlphaGo时就定下的目标,这意味着机器人不能只拥有躯干,更需要大脑去应对不同场景。
“同时做大脑和本体,看起来可能会非常难,但对我来说,因为我都能做,所以这是一个自然选择。”陈建宇对《智能涌现》表示。
在一众具身智能创始人中,陈建宇有着稀缺的交叉领域研究背景,他过往的学术方向兼具了“本体”与“大脑”。
2011年,陈建宇本科被保送到清华大学精密仪器系,这是国内最早从事双足人形机器人研究的单位之一;在美国加州大学伯克利分校就读博士期间,他又着手研究MPC(模型预测控制)和端到端强化学习,这也正是如今具身智能“大脑”的重要技术路线。
事实上,相比硬件层,陈建宇在机器人算法层面的研究成果更显著,他曾提出新一代人形机器人学习算法框架DWL,获得机器人领域难度最高的顶会RSS最佳论文提名奖;他首创的融合生成式世界模型的具身大模型算法VPP,被选为人工智能最顶级会议ICML的Spotlight论文。
在与《智能涌现》三个小时的采访中,有一半的时间,陈建宇都在和我们讨论算法和“大脑”。
但只有算法,或者只有本体,都不是陈建宇认为可以实现“通用人形机器人”目标的路径。他需要的,是一套“体系”,其中包括软硬两套通用架构,其中:
软件层面,「星动纪元」发布了融合理解与生成式的VLA模型ERA-42。这一机器人大脑融合了世界模型,能够对世界深度理解并实时预测;
硬件层面,「星动纪元」正在开发通用化、模块化的机器人产品。让机器人就像乐高一样,根据不同场景需求灵活变化形态,包括双足、轮式、人形等。
此外,由于机器人当下供应链并不完善,「星动纪元」从机器人本体最小单位开始自研,如关节模组、控制单元、电机、减速器等。
当软、硬两层架构成熟后,让机器人实现什么功能、长成什么形态,都会在业务拓展上更加敏捷,这也解释了「星动纪元」在本体上布局迅速的原因:目前其人形机器人业务已经推出三款面向客户的成熟产品:五指灵巧手XHand 1、轮式服务人形机器人Q5、全尺寸人形机器人STAR 1。
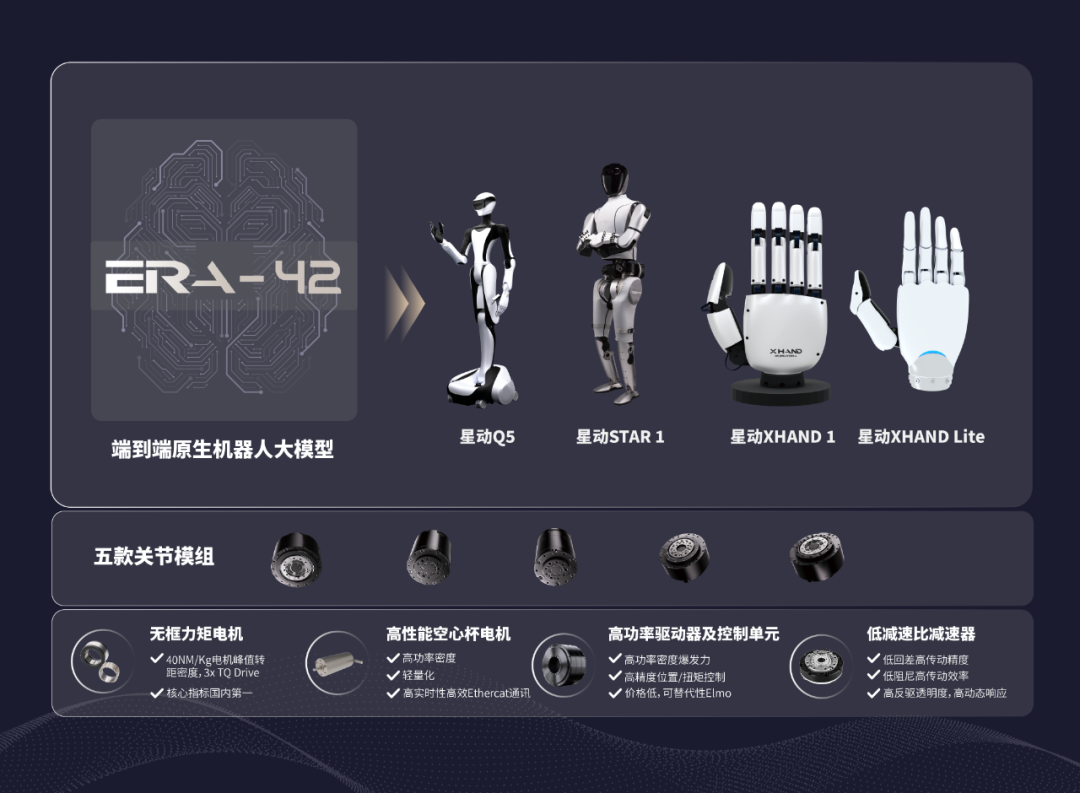
△星动纪元产品线 图源:企业官方
在商业化策略上,陈建宇喜欢谈到一个概念:“沿途下蛋”。比如他认为,机器人灵巧手做出来了,可以先出售,不用苦苦等待整机,这样不仅有利于逐步拉低硬件的成本,还可以获取一定的数据,形成数据飞轮,反哺研发。
据陈建宇介绍,目前,在全球市值TOP 10的科技巨头中,有9家是他们的客户。截至6月,「星动纪元」在2025年已累计交付超200台产品,另有上百个订单在量产交付中。在「星动纪元」的客户名单中,汇集了海尔智家、联想、北自科技等……
近日,《智能涌现》与陈建宇进行过一次长谈,他分享了关于机器人领域算法、本体产品、商业化的种种思考,当中涉及到的陈建宇团队的多篇学术研究,我们也附录至文后,以下为编辑后的访谈实录:
做本体还是做大脑?“这从来不是一个问题”
智能涌现:从你之前在清华、伯克利的学术方向来看,你兼具了“本体”与“大脑”研究经历,这在具身圈子的创始人中算是比较少有的,那在创业方向的选择上,当初你是否会考虑只做本体/大脑?或者说,这个选择对于你来说是个问题吗?
陈建宇:这对我来说从来不是一个问题。主要基于两个判断:
第一,是否需要做本体和大脑?这个答案从一开始就是确定的。如果只有本体没有大脑,机器人就是废铁。如果只有大脑没有本体,那就不是机器人了。我们最终要商业化闭环,一定是软硬一体交付到客户。
第二,我们是否都有能力做?同时做大脑和本体,看起来可能会非常难,但对我来说,因为我都能做,所以这是一个自然选择。
从我个人近十年的经历来说,最开始做过机器人硬件、机电系统,到博士阶段搞软硬件结合、各种控制,再到后面搞AI领域。我搞机器人AI到现在也快十年了,最早从AlphaGo时代开始,我就往这块研究了,大概是 2016、2017 年左右。
智能涌现:2022年AI大模型的出现,给你之后的工作方向带来哪些影响??
陈建宇:我们经历了几个阶段——
第一阶段是,将语言模型与现有机器人工作相结合。2023年ChatGPT刚出来后,我就尝试通过语言提示,让ChatGPT假设自己是一个机器人,进行任务规划,例如规划机器人怎样应用其传感器、先识别目标再行动等,那时它已经能做得比较不错。基于此,我们完成了一篇论文,这是全球首篇结合语言模型和人形机器人的研究。
2023年做出全球第一篇大语言模型和机器人结合的工作,改进了上层语言模型规划与下层强化学习策略的对齐问题。
第二阶段是,受谷歌启发,2023年左右,我们开始了端到端的VLA(Vision-Language-Action)雏形的研究,并成为国内最早复现RT-2的团队。后来,我们发现了实际操作中的一些问题,提出了改进方法,也就是现在大家熟知的快慢系统VLA的框架。
2024年9月,首次提出在VLM基础上增加高频动作处理模块的VLA方案,该架构发表后,行业内头部机构,包括 Physical Intelligence的Pi0(2024年10月),Figure AI的Helix(2025年2月),NVIDIA的Groot N1等均陆续发布类似架构的VLA模型。
RT-2本质上是一个慢系统,侧重于思考,虽然能处理语言,但缺乏对动作的有效处理。我们添加了一个快系统,用于更细致地输出更精细的动作,并以更高频率运转。
第三阶段是,Sora视频生成式模型的出现带来的启发。此前理解物理世界,如英伟达的仿真器,需手动编写物理规律,过程复杂且难以精准建模。而Sora能生成细节丰富的视频,如人走路、手抓物体、倒水等,机器人需要这样的通用世界模型。
因此我们考虑将其引入机器人中,随后我们提出了一系列融合生成式模型的VLA算法框架。
2024年9月发布PAD架构,首次提出融合世界模型,被NeurIPS收录。
2024年12月发布VPP架构,首次提出预训练的视频预测模型,并与PAD架构进行融合,被ICML收录。
2024年9月,提出iRe-VLA框架,首次证明了强化学习可以用于训练端到端的具身大模型并提升其性能。
2025年1月,提出UP-VLA,一个统一理解与预测的具身模型,将理解、预测、策略学习融合,同时预测未来画面与底层动作,被ICML收录。
我们的模型既能预测未来,又能直接端到端控制机器人的具体动作,包括每个关节的细微调整。
比如,杯子放到边缘时,机器人会担心它掉下去,时刻在做预测,这有助于提前做好准备。我们已经迭代了几代大模型,提出了全球首创的融合生成式世界模型的VLA模型。
现在据我们所知,国外顶级的几个团队也在做这件事,上个月Meta使用了类似的方法,融入了世界模型。
智能涌现:听上去你们在模型和算法层面的筹备非常充足,那现在还缺什么?
陈建宇:首先是数据。
语言模型开始做的时候,网上的人类语言数据已经非常多,你只需要把数据扒下来,再做一些处理就可以。但对机器人来说,数据天然就没有这么多。
Waymo公司最近把他们在旧金山的驾驶数据加进去,虽然是很大的体量,但跟语言模型的数据量相比,差得太远了。如果按照这样方式去收数据,可能要收几万年才能达到ChatGPT的训练数据量。
机器人的飞轮效应比自动驾驶更难实现,因为在路面上跑的车本来就很多。
智能涌现:现在很多公司用真机遥操作的方式产生数据,你们会考虑采用吗?
陈建宇:我们采用了组合方式。先是基于非常大量的视频数据做预训练,训练出一个比较通识的基座,再用更精细的遥操数据来调整你的目标。这样对真机遥操作数据的需求量就会减少,而不是直接靠它去做底层的预训练。
智能涌现:对于机器人“大脑”来说,什么样的数据才是真正对模型有用的?
陈建宇:我们需要多样性的数据。举个开车的例子,如果全是开得特别好的数据,模型可能就无法处理稍微危险的情况。因此,一定要涵盖各种各样的不同场景。
比如,学习倒水的视频,不能一直拿着同一款杯子,在同一位置进行。不同姿态、水杯的形状,都会对液体高度产生影响,所以我可能需要多一些维度,以提高其多样性。
此外,并非所有情况都是白墙实验场景,还需要尝试不同的背景。种类多、且每个种类收集大量数据,这样会更有效。
智能涌现:机器人像人,这件事情很重要吗?
陈建宇:人形是重要的,通过训练人形,你可以得到一个厉害的基础,然后你再把这个基础降维到其他形态上。
虽然机器人未来形态可能不同,但很大一部分组件是共用的,包括大模型、关节模组,只是尺寸不同。硬件技术是统一的一套,软件技术也是统一的一套,不论是机器人的手、足式还是轮式,不同的形体,其实用的是我们同一套软硬结合的底座。
这也是我们为什么要做人形机器人的原因。人形不是我们最终的目的,而是一个重要手段。通过与人类行为数据相结合,我们可以更好地利用这些数据。这也与我们的方法是呼应的,因为我们是从海量的人类视频数据中直接学习。
智能涌现:曾经有机器人公司的创始人认为,大脑不重要,本体重要,有本体就不在乎大脑,您怎么看?
陈建宇:训练AI的前提是先有本体,然后继续采集数据,再训练再调整,所以必然慢于本体。
作为初创公司,我们考虑“沿途下蛋”,本体研发出来后先出售。我们现在灵巧手产品的毛利非常高,做人形时也会拉低边际成本。我们现在陆续对整机进行规模化售卖,量产准备也做好了,后面我们的模型和解决方案也会逐步商业化。

△图源:企业官方
智能涌现:那只做大脑的公司,未来能力有可能比你们强吗?
陈建宇:我认为如果只做大脑,会缺少很多东西,商业化模式就会缺失,可能缺少很多供血方式,不一定能走得更远。而商业模式能带来更多资源,从而能投入更多研发,产品也能做得更好。这里面还有飞轮效应,通过商业化,提前积累数据,飞轮效应可能带来很多好处。
只做大脑的公司,不确定性高。如果使用多种本体,那每打通一种本体都需重新做数据打通,耗费大量精力,难以规模化。
大火的VLA路线,“L”的部分太重了
智能涌现:VLA路线是大模型与具身智能的结合,引起了机器人和大模型领域学者的关注。不过现在行业里也有一些不同的声音认为,VLA范式存在着一定的局限,比如训练存在割裂的问题、数据量难以与VLM匹敌等等。您本人如何看待如今大火的 VLA路线?
陈建宇:当前的VLA模型,它的“L”部分(即Language,语言)太重了。模型首先是一个纯语言模型,再拓展到视觉,变成视觉语言模型。在这基础上,再把动作连接起来,变成视觉语言动作模型。
从进化论的角度,这个过程是反过来的——生物是,先有爬虫类的控制动作部分,再逐步发展到大脑皮层,有了视觉和语言,语言是最后进化出来的。事实上,很多训练好的猩猩和猴子也能做很灵巧的工作,但它们不需要语言。
现在,我们反过来了,先有了语言,再逐步补上其他部分。
我觉得对于很多应用来说,(语言)其实是不必要的。对于机器人,第一步就是要先开始干活,重要的是它要做什么动作。我认为这存在一定问题,所以我们最近在研究,在预训练阶段,同时训练语言视觉和动作,而非先专注于语言。这样应该能取得更好的效果。
智能涌现:对于机器人大脑,有的企业会根据场景或者具体功能,分成好多层模型来做,您怎么看待这种技术方式?
陈建宇:大家会按两个维度为机器人大脑做分层。一个是纵向维度,比如感知模型、预测模型、控制模型。此前的无人车或者机器人都是沿着这个pipeline逐步发展的。另一个是横向的维度,按任务类别去训练,一类任务训一个模型。
只要划分了层次之后,它们之间就很难形成聚合效果。比如,按横向任务来划分,会使A任务和B任务形不成合力,即使切分成1000个任务并全部完成,甚至更多,也不可能涌现出新东西。涌现,一定是很多任务综合在一起才行。
而我们是相对统一的,把纵向和横向都合并了。目前,我们已发展到通过统一模型微调学习一个垂直任务,比单独训练单任务的小模型都更好,且更快。
智能涌现:强化学习是推动大模型推理能力跃升的核心,那么您认为强化学习之于机器人的意义是什么?
陈建宇:目前VLA实际上还没有这样的强化学习机制。本质上,VLA仍是一个surprise learning,是一个离线学习过程。类似于,你先观察很多人怎么做,然后直接学习。
以打乒乓球为例,VLA相当于教练手把手教你几遍,然后你就直接去打,可能还是打不好;
而强化学习是,首先你要看别人怎么打,教练再教你更精细的动作,之后你还要自己不断调整练习,尝试打出好球,这也是进一步与物理世界对齐的过程。如果没有这一步,很多比较精细、复杂的工作你可能就做不了。
谈产品、场景、和机器人的未来
智能涌现:现在投资人和行业对你们的定位和观察似乎存在差距,不知您是否有同感?
陈建宇:外界对我们的认知,和我们实际的业务状况,确实存在一定差距。我们是搭建了一套比较全面的体系,这套体系是通用的,可能有的人没有找到其中的逻辑,也可能我们之前没有充分展示。
智能涌现:你所说的“体系”是什么?
陈建宇:分为软件和硬件两部分。如果一句话描述硬件模块,就像搭乐高一样去搭建机器人。我们从硬件的最小单位硬件开始自研,如机器人的关节模组、电机、减速器、控制器等;实现了从零件、到部件的模块化、通用化。
比如我们手是一个模块,可以适配于不同的机器人,甚至里面的关节键拆下后可以用于重新组合成另一款机器人。我们的大脑是端到端通用大脑,适用于不同任务,可以迅速调整到不同的本体上。
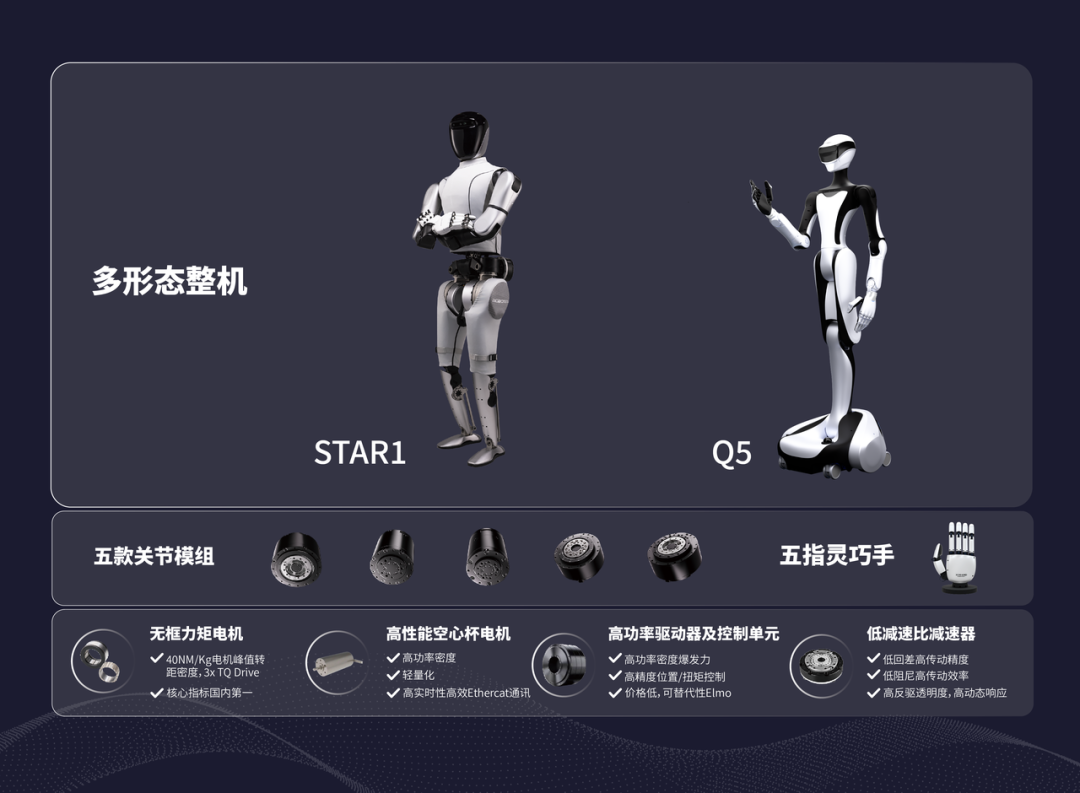
△图源:企业官方
智能涌现:有了这套底座后,未来形态可扩展吗?
陈建宇:非常可扩展,任意机器人都可以,无非是有几条胳膊、几个肘、几条腿,以及各有多少自由度等。
智能涌现:好像把机器人模块化了,可以根场景随意变化形态,那怎么做产品形态定义?
陈建宇:人形可能是机器人终局情况下数量最多的,但是具体的场景下,需求是不同的,所以我们会需要不同的形态。
比如,如果你的场景需要上下楼梯,就需要双足的形态,如果完全是平地,轮式就够了,如果是要在某个3C工厂里替代一个固定的工位,可能只要一个上半身也就够了。
智能涌现:现在终端出货量有多少?
陈建宇:超过200台,客户也涵盖得很广,全球市值前十的科技巨头里,有九家都是我们的客户,有的一家就买几十个,都是拿来用的。
智能涌现:挑选场景的标准大概是什么?
陈建宇:高价值、可复用。
高价值,指的是这个“人”的薪水有多高,就说明这个场景的价值有多高,会在能力边界内找尽量高价值的任务和场景。现在是面向两类高价值场景,一个是工业,一个是服务。
我们工业领域的产品被称之为人形机器人中的六边形战士,手很灵巧,跑跳运动能力非常强,力量、敏捷和智力拉满;另一款服务机器人很小巧,我们会重视它的外观、拟人理论性和交互,这是服务业特有的属性。
智能涌现:目前你们的机器人产品智能化水平如何?
陈建宇:我们把产品根据智能化划分为两个级别,一个是产品化级别,一个是demo级别。

△图源:企业官方
我们的demo产品可以使用螺丝枪打螺钉、拿起扫码枪扫码,或者拿起勺子去舀水,成功率已经很高。
而产品化级别的产品,智能化程度要求更严苛,我们在做物流场景,比如找标签、扫码、分拣等,现在已经能达到不错的成功率,也正在真实场景中落地。
智能涌现:除了物流,你还看好哪个场景?
陈建宇:下一个就是制造领域,因为制造涉及更精细的操作。物流主要是移动物品或搬箱子,更简单一些,而制造则更复杂,比如需使用不同工具找标签、或者做更复杂的手部灵巧操作翻面等。

△制造领域里,星动纪元旗下的机器人STAR 1实训搬运工作
智能涌现:关于人形机器人,现在的零部件大部分是通用的,还是要自己造开模?
陈建宇:我们不会自己去加工具体零部件,不然成本算不过来。
不过,我们自研设计非常深入,到电机这一层,电机、齿轮、控制器电路板、驱动器等全部都是我们自己设计,图纸都是我们设计的。
智能涌现:在生产制造场景中,哪些工作人类仍无法被机器人替代?若所有生产制造场景均能被替代,将会如何?
陈建宇:我认为纯流产线上的人力密集型工作,这些工作理论上都能被替代,但目前难以实现。如果被替代,将带来极大的社会结构变革。机器人先替代苦活、累活、危险活等,因为现在越来越多的年轻人不愿从事这些工作。
我认为这有助于将人类从枯燥劳动中解放出来,让人们从事更有价值的工作。这种替代也将带来更高的生产效率,使所有物品变得更便宜。
未来机器人本身将成为一种终端产品,并可能是规模最大的,可能介于手机和汽车之间。未来家庭可能会拥有一到两个家用机器人或终端机器人,这些机器人将提供服务和情绪价值,这种形态的产品在未来5年就会开始出现。
机器人大战前,先储备粮草
智能涌现:融资目前对你来说的意义是什么?
陈建宇:可以想象未来竞争会比较激烈,要提前做好准。现在是因为还没有开始打商业化的大仗。
现在机器人领域融资的规模和智能汽车、电动汽车、大模型相比,少很多。但未来,机器人的制造规模可能要达到电动汽车的水平,未来,机器人的模型规模可能要到大模型的水平。
智能涌现:海尔能够给予我们的战略帮助会是哪些层面?(注:海尔是本轮投资方)
陈建宇:首先是场景会跟我们去共享,其次,产品定义是现阶段就能进行,比如零售,把机器人放到他们的门店里,利用我们的机器人产品做引流、导览、指示,服务等。
智能涌现:机器人在家庭场景的应用,能几年之内实现?
陈建宇:我觉得是渐进式的。如果快的话,可能3-5年能看到一些雏形,比如说在一些高净值的家庭里面。但对于普通家庭,要求更高,他们需要既普适又便宜的机器人。
智能涌现:据我所知,美的海尔也早就说要进入机器人领域,你们和大公司之间是怎样的关系?
陈建宇:商业中都是竞争与合作并存,要辩证地看待竞争与合作。如果是互联网大厂,我们可以成为硬件供应商。如果是传统制造类,我们则可能成为软件供应商。
智能涌现:汽车公司都有很大的自动驾驶团队,现在都在走端到端路线,硬件又搞了很久,未来汽车行业会都走到机器人赛道上吗?
陈建宇:我觉得机器人会是智能汽车的延伸,但是不会是所有人都选这个。大企业制定战略通常较为严谨,前期可能投入较少进行跟进和研究。
目前,这些大厂并没有真正大力投入机器人,还是在做技术储备,人数投入跟我们创业公司差不多。
智能涌现:大模型公司现在已经趋近于共识,这个领域不会有很多玩家,但在机器人似乎更允许多个玩家存在?
陈建宇:是的,因为机器人更丰富、更多样,不像基座大语言模型那样统一。机器人会有很多不同的形态,而且涉及硬件制造,硬件迭代比软件慢。
机器人的市场足够大,细分更细,存在的玩家也更多。与语言模型不同,语言模型一旦推出,所有人都能瞬间使用,更容易形成垄断。而机器人领域更加基础、分散,有更多的公司存活。
陈建宇教授的过往研究成果附录:
2023年做出全球第一篇大语言模型和机器人结合的工作,改进了上层语言模型规划与下层强化学习策略的对齐问题。相关论文:Doremi: Grounding language model by detecting and recovering from plan-execution misalignment(http://arxiv.org/abs/2307.00329v1),被机器人顶会IROS收录。
2024年9月,首次提出在VLM基础上增加高频动作处理模块的VLA方案,发表了HiRT论文——HiRT: Enhancing Robotic Control with Hierarchical Robot Transformers(https://arxiv.org/abs/2410.05273)。
2024年9月发布PAD架构,首次提出融合世界模型,被NeurIPS收录。 相关论文:Prediction with Action: Visual Policy Learning via Joint Denoising Process(https://arxiv.org/abs/2411.18179)
2024年12月发布VPP架构,首次提出预训练的视频预测模型,并与PAD架构进行融合,被ICML收录。相关论文:Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations, ICML 2025 Spotlight(https://arxiv.org/abs/2412.14803)
2024年9月,提出iRe-VLA框架,首次证明了强化学习可以用于训练端到端的具身大模型并提升其性能。相关论文:Improving Vision-Language-Action Model with Online Reinforcement Learning(https://sites.google.com/view/ire-vla)
2025年1月,提出UP-VLA,一个统一理解与预测的具身模型,将理解、预测、策略学习融合,同时预测未来画面与底层动作,被ICML收录。相关论文:UP-VLA: A Unified Understanding and Prediction Model for Embodied Agent(https://arxiv.org/abs/2501.18867)
封面来源|企业官方







(文:智能涌现)