

今天是2025年7月7日,星期一,北京,晴
今天是小暑,大家注意防暑。
我们继续来看文档智能进展,来看现有中文文档版式分析的标签问题,其实,在实际落地过程中,标签和任务的设定往往会更为重要,如何针对不同的领域文档类型,设定合适的标签,很重要。
另外,我们再看RAG进展,关注几个竞赛获奖方案。比赛是https://liverag.tii.ae/challenge-details.php,被选中的团队需要构建一个 RAG 系统,应用如查询重写、文本检索、提示生成等,指定Falcon3-10B-Instruct来进行答案生成,涉及到6个竞赛方案,可以做个记录。
一、中文文档版式分析的标签问题
目前开源的针对中文场景的版式分析模型用的比较广泛的,主要有3个,360layoutanalysis、doclayout以及PP-DocLayout。
1、360layoutanalysis标签体系
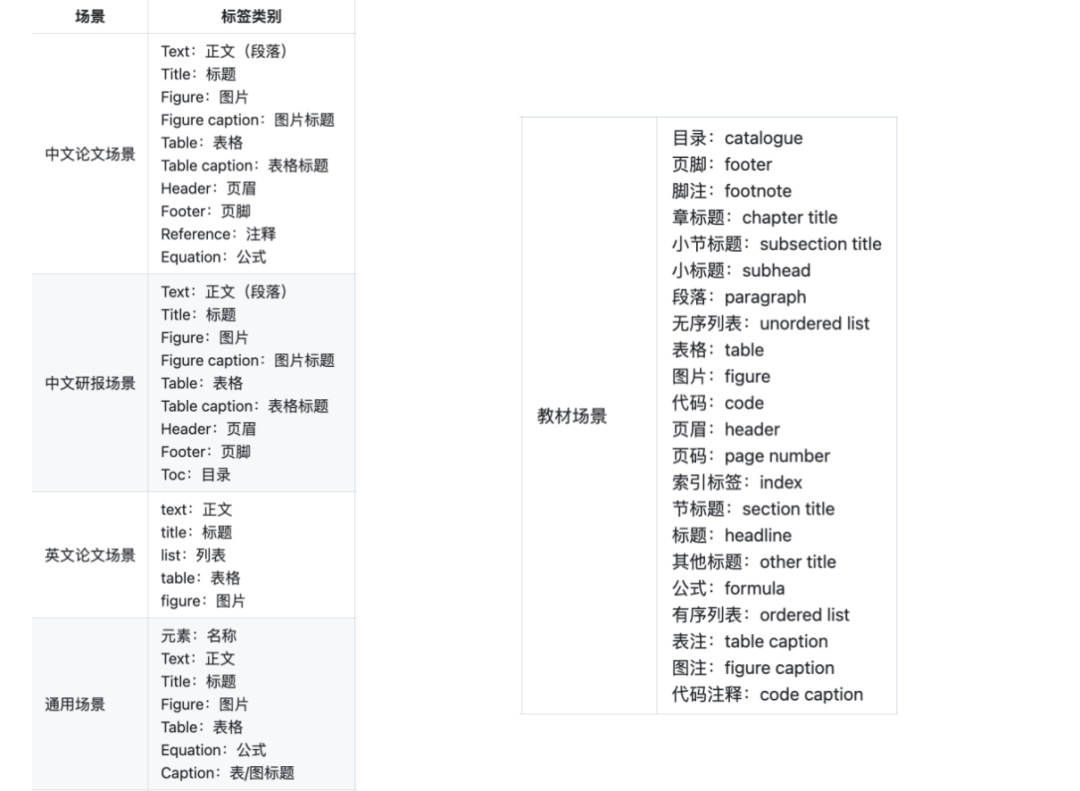
开源了多个场景,包括中文论文、中文研报、英文论文、通用、教材场景等,不同场景有不同的标签。
2、doclayout标签体系
包括10个类别:’title’, ‘plain text’,’abandon’, ‘figure’, ‘figure_caption’, ‘table’, ‘table_caption’, ‘table_footnote’, ‘isolate_formula’, ‘formula_caption

地址在:https://arxiv.org/pdf/2410.12628
3、PP-DocLayout标签体系
包含23个常见的类别:文档标题、段落标题、文本、页码、摘要、目录、参考文献、脚注、页眉、页脚、算法、公式、公式编号、图像、图表标题、表格、表格标题、印章、图表标题、图表、页眉图像、页脚图像、侧栏文本。
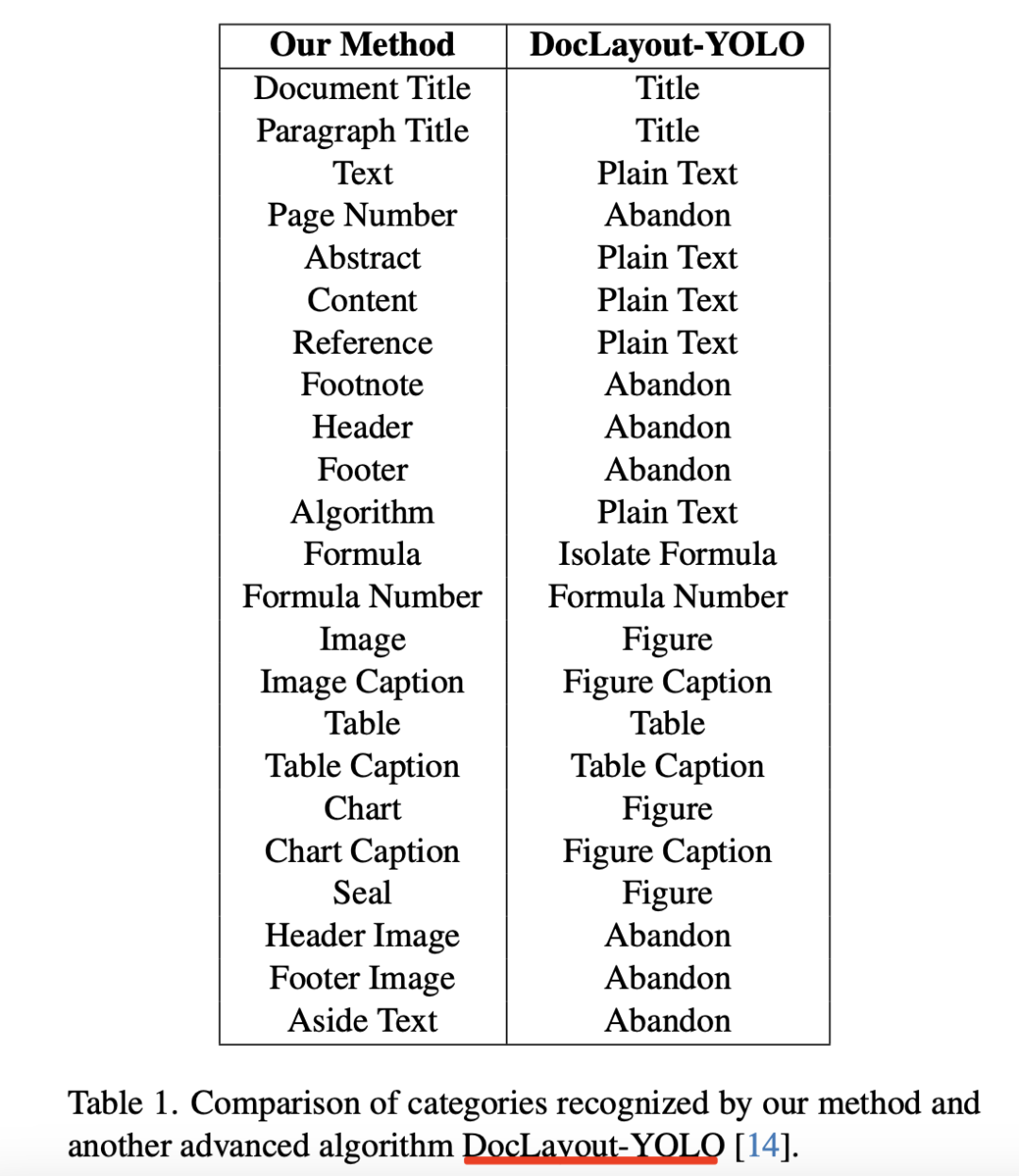
和doclayout相比,进行了进一步的细化:

地址在:https://arxiv.org/abs/2503.17213
4、M6DOC标签体系
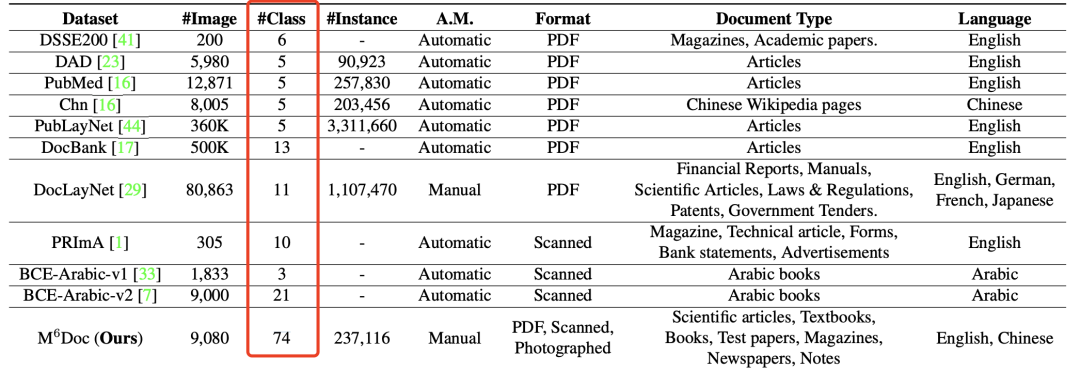
当然,如果要看版式分析这块的精细活,那么必然要提到M6DOC标签,它的标签体系是真的很细致,但数据不开源,也没有对应的开源模型可用。

根据其提供的标注规范,其设计到的标签非常丰富,高达74个标签,
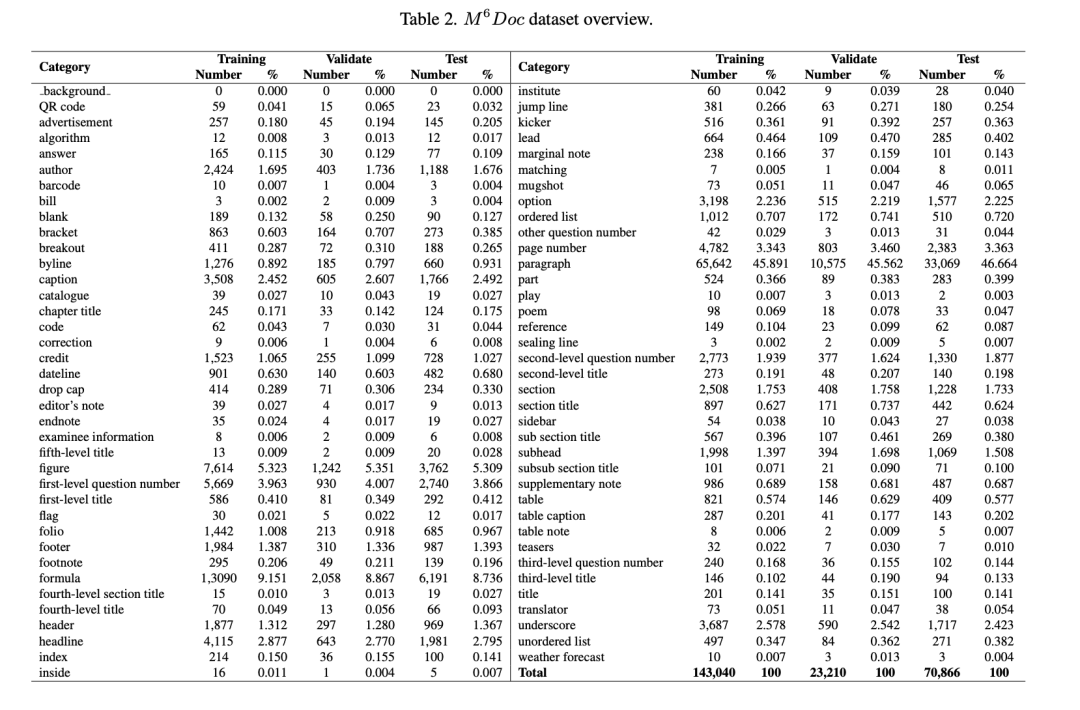
具但是标签分布很不均衡,如下统计数据:
更值得一提的是,其分领域提供了一些标注方案,例如Scientific article、Newspaper、Textbook、Book、Magazine、Test paper、Note,其中以试卷为例,有如下标注体系:
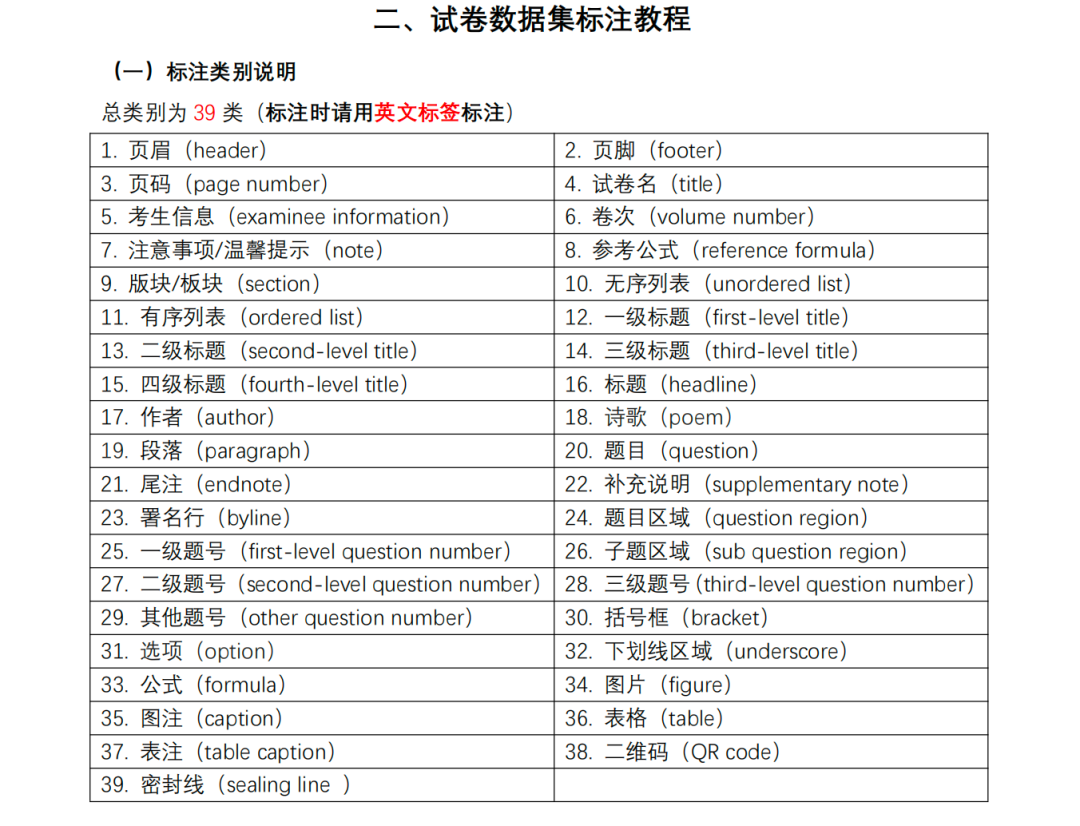
如一个例子如下:

此外,还给出了古籍的标注体系
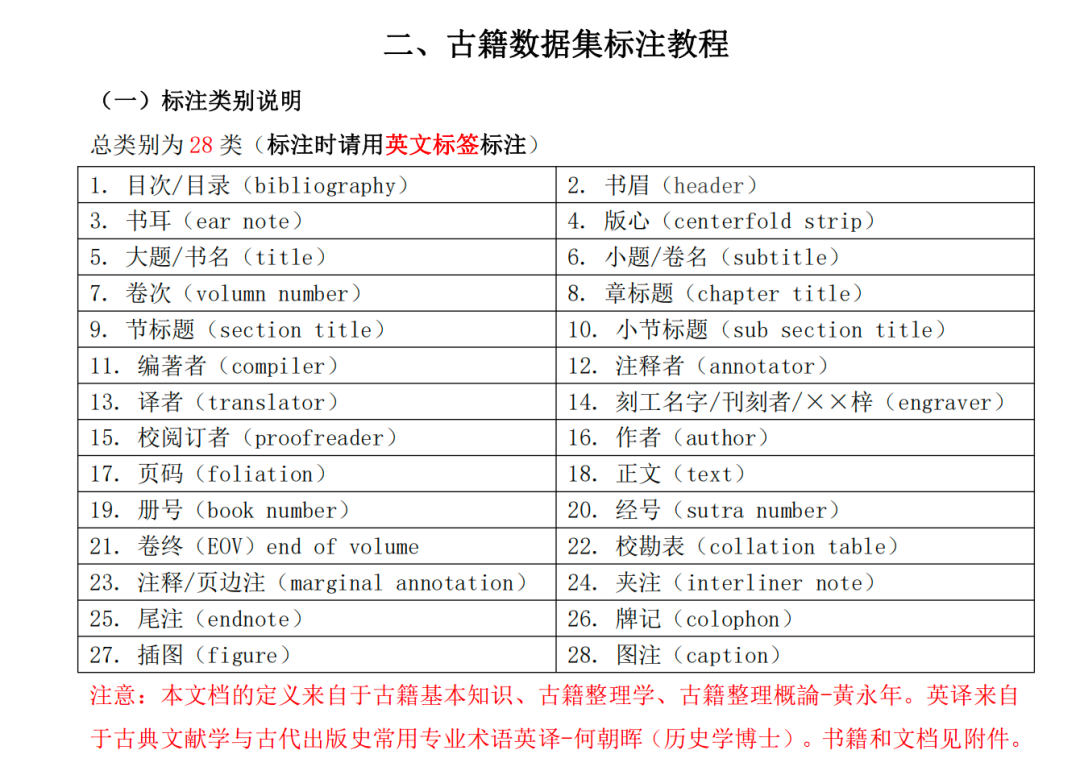
例子如下:

地址在:https://arxiv.org/pdf/2305.08719
二、SIGIR 2025 LiveRAG竞赛获奖方案
RAG进展,关注几个竞赛获奖方案。比赛是https://liverag.tii.ae/challenge-details.php,任务是构建一个 RAG 系统,应用如查询重写、文本检索、提示生成等,指定Falcon3-10B-Instruct来进行答案生成。
获奖方案有6个:
1)TopClustRAG at SIGIR 2025 LiveRAG Challenge
思路是混合检索策略,结合稀疏索引和密集索引,然后使用K-Means聚类对语义相似的段落进行分组。每个聚类中的代表性段落用于构建大特定聚类提示,生成中间答案,这些中间答案经过筛选、重新排序,最终合成为单一、全面的答案。
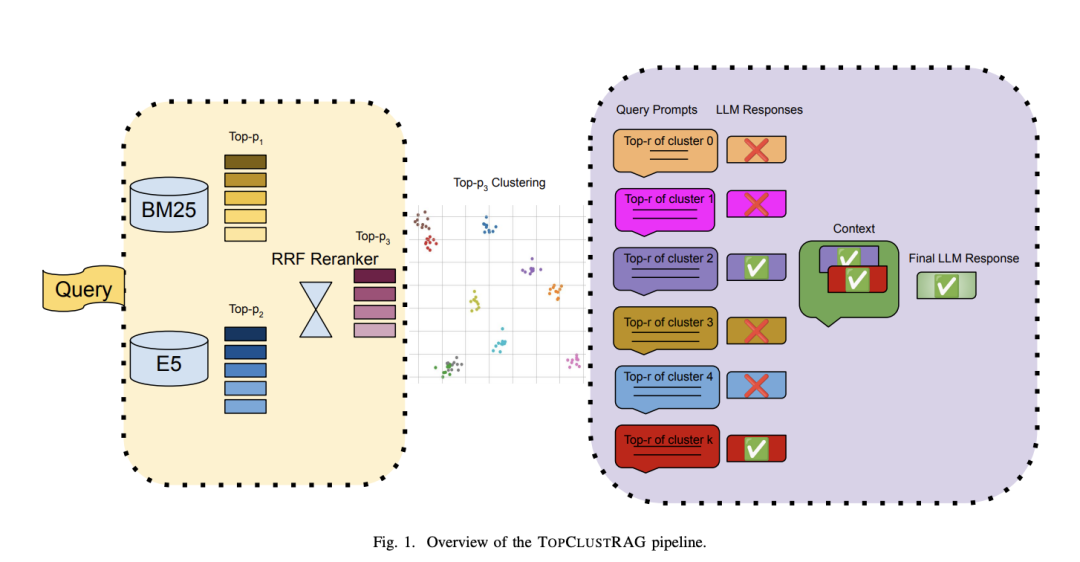
方案在:https://arxiv.org/pdf/2506.15246,
2)RMIT–ADM+S at the SIGIR 2025 LiveRAG Challenge
思路是生成一个假设答案,该答案与原始问题一起用于检索阶段,然后在最终答案生成之前加入了一个重排序步骤。
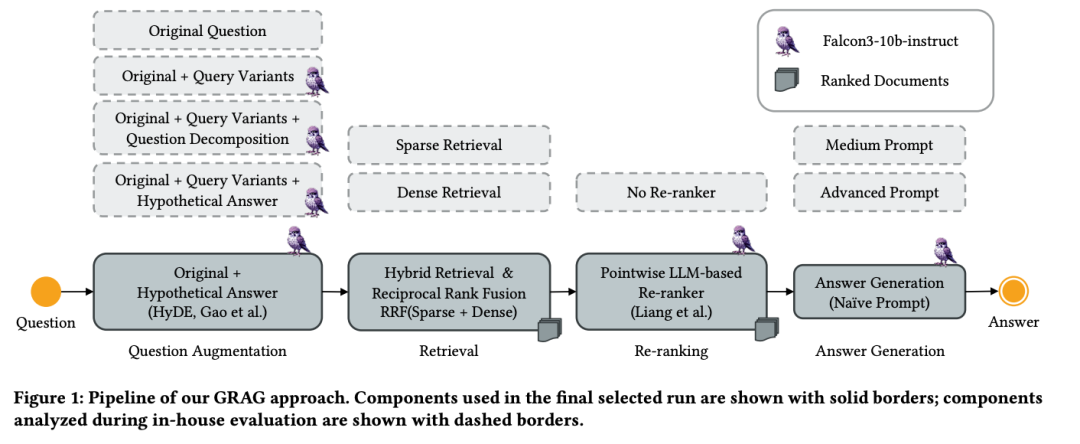
方案在:https://arxiv.org/pdf/2506.14516
3)RAGtifier: Evaluating RAG Generation Approaches of State-of-the-Art RAG Systems for the SIGIR LiveRAG Competition,实现思路是使用InstructRAG结合 Pinecone 检索器和BGE重排。
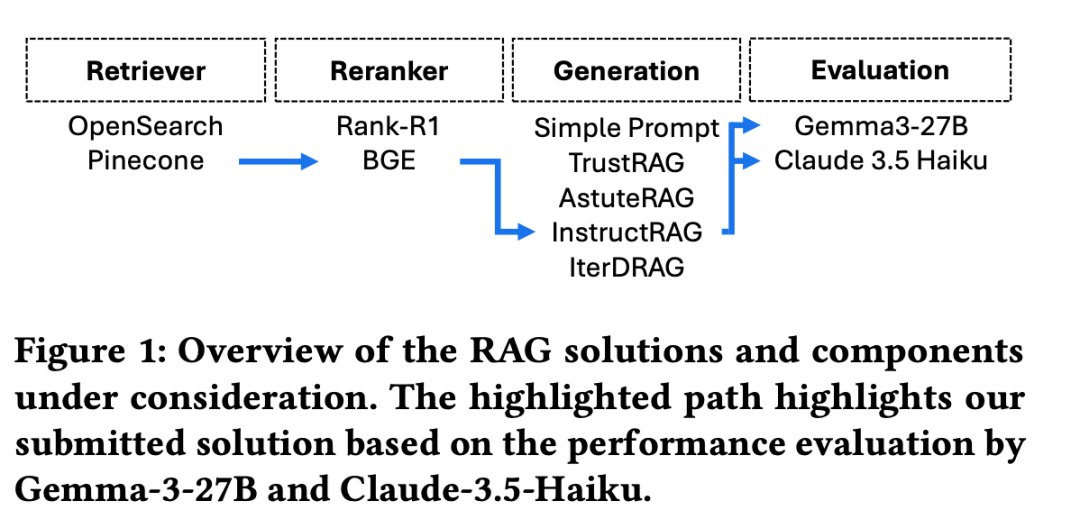
方案在:https://arxiv.org/pdf/2506.14412,https://github.com/rmit-ir/GRAG-LiveRAG
4)LTRR: Learning To Rank Retrievers for LLMs,主要思路是引入查询路由方法,该方法基于查询从检索器池中动态选择,根据检索器对下游性能的预期效用增益对其进行排序。
方案在:https://arxiv.org/pdf/2506.13743,https://github.com/kimdanny/Starlight-LiveRAG,
5)DoTA-RAG: Dynamic of Thought Aggregation RAG,主要思想是查询重写、动态路由到专用子索引以及多阶段检索和排序。
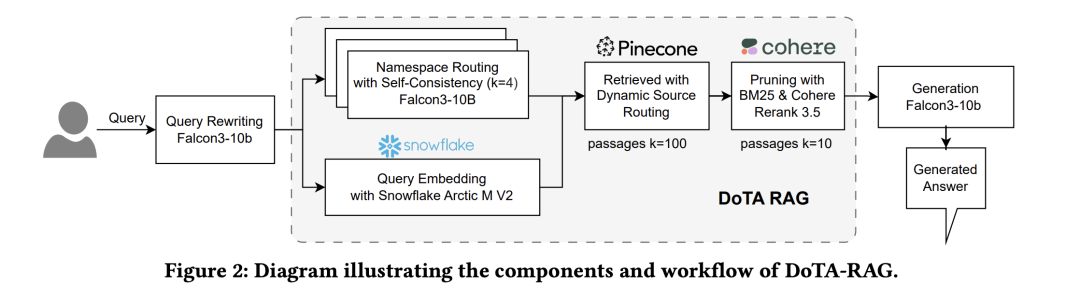
方案在:https://arxiv.org/pdf/2506.12571
6)CIIR@LiveRAG 2025: Optimizing Multi-Agent Retrieval,Augmented Generation through Self-Training,主要思路是多智能体检索增强生成 (RAG) 框架,由专门负责规划、搜索、推理和协调等子任务的智能体组成。
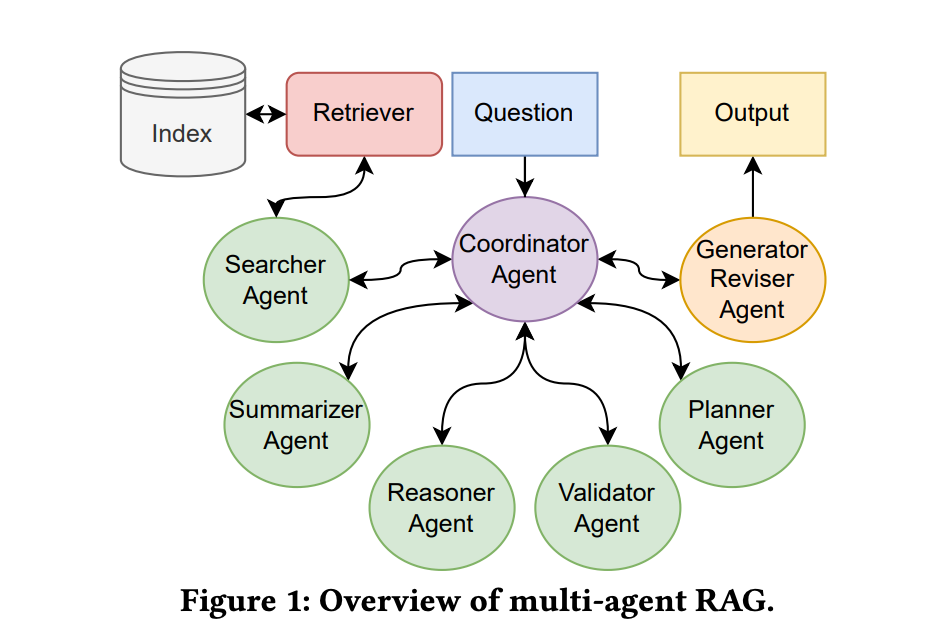
方案在:https://arxiv.org/pdf/2506.10844,https://github.com/muktac5/CIIR-LiveRAG;
(文:老刘说NLP)