


本文的第一作者吴怡琳现为卡内基梅隆大学机器人学院二年级博士生,导师为 Prof. Andrea Bajcsy。她的研究聚焦于开放世界场景下的物体操控与机器人终身学习。吴怡琳本科毕业于上海交通大学,并于斯坦福大学取得计算机科学硕士学位。她曾与 Prof. Pieter Abbeel、Prof. Lerrel Pinto、Prof. Dorsa Sadigh 及 Prof. David Held 等多位专家合作,开展可变形物体操控、双臂协作操作及辅助喂食机器人等方向的研究,获得过 ICRA 最佳论文,CoRL 的 oral 论文录用。目前,她正在 NVIDIA 西雅图机器人实验室参与暑期研究,继续推进具身智能模型在复杂场景下的可扩展性与部署能力。
第二作者田然是 UC Berkeley 即将毕业的博士生同时在 NVIDIA 担任研究科学家,研究方向致力于推动机器人基础模型在真实世界中实现大规模、安全、可信的落地应用。他的研究系统性地探索了机器人基础模型在预训练、后训练到实际部署各阶段中所面临的安全与偏好对齐挑战。他的工作获得了多个最佳论文和国际奖项的肯定,包括:世界人工智能大会「云帆奖」、高通创新奖学金、ICRA 最佳论文、ICLR Spotlight 、百度奖学金 Finalist、Robotics: Science and Systems Pioneer、以及 Microsoft Future Leaders in Robotics & AI。
该研究工作获得 2025 ICLR World Model Workshop 最佳论文奖,并已被 2025 Robotics: Science and Systems(RSS)会议正式接收。
近年来,基础模型在具身智能领域展现出惊人的能力。通过离线模仿学习,这些具身智能模型掌握了多样化、复杂的操作技巧,能够完成抓取、搬运、放置等多种任务。然而,这些「学得像」的模型在真实部署中却常常「用不好」:面对环境扰动、任务变化或者用户偏好差异,它们容易生成错误动作,导致执行失败,正如下图所示:
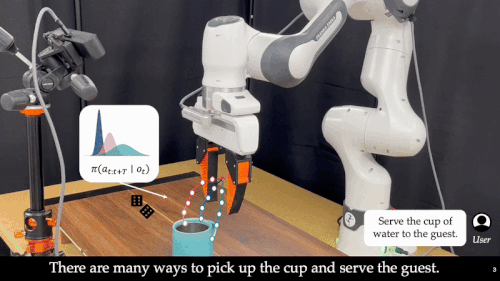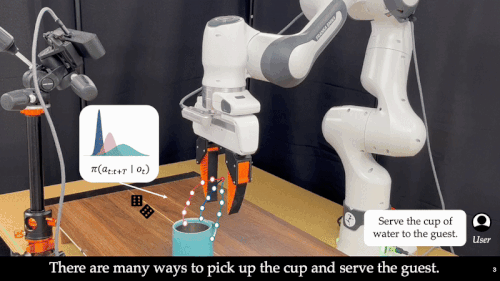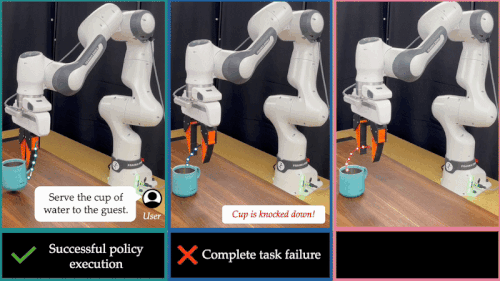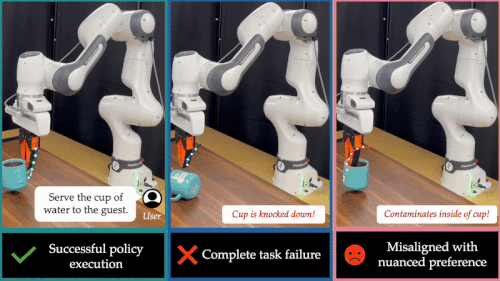
这也暴露出当前具身智能系统的一大核心难题:如何让机器人在部署阶段具备「推理能力」(Test-Time Intelligence – 部署智能),即无需额外数据,也能主动预判风险、灵活调整策略。 对此,来自卡耐基梅隆大学与伯克利人工智能研究院的研究团队提出了全新框架 FOREWARN,首次将「世界模型」与「多模态语言推理」结合,在机器人部署阶段,对基于模仿学习生成的动作策略进行在线评估与动态校正,打破了当前具身智能模型仅依赖离线模仿的局限,迈出了通向真正部署智能的重要一步。
部署智能为何如此困难?预测与理解的双重挑战
在真实部署阶段,我们希望机器人在执行前,能够从多个由模型生成的候选动作中筛选出最优方案。然而,这看似简单的「临场决策」,在开放世界中却隐藏着两个极具挑战性的任务。
一是预见动作的未来后果:机器人需要具备建模环境动态的能力,准确推演每条动作方案可能引发的状态变化。
二是评估预测结果的优劣与契合度:不仅要判断这些结果是否达成任务目标,还需理解其语义,并考量是否符合用户偏好。
这两个任务相互交织,彼此依赖,但所需的能力却截然不同 —— 前者偏向物理建模与演变模拟,后者则需要语义推理与用户偏好理解。尤其在开放世界中,缺乏精确物理模型与用户偏好模型,更使得这类决策问题变得极为棘手。
核心思路:解耦预测与评估,分而治之
为了解决部署阶段的智能挑战,研究团队设计了由「预见(Foresight)」与「深思(Forethought)」组成的双模块框架,将复杂的决策过程拆分为「模拟未来」与「评估未来」两大任务,分而治之,协同决策:
模拟未来:系统引入具备环境动态建模能力的世界模型,在低维隐空间中预测每个候选动作方案可能引发的环境状态变化。该模型通过离线学习大量真实机器人轨迹及成功 / 失败案例,能够在运行时以极低代价高效「脑补」多种未来,无需反复尝试实地执行。
评估未来:随后,系统利用经过微调的多模态语言模型,先将上述在隐空间「脑补」的多种未来解码为自然语言形式的行为描述,语言模型再据此结合任务目标与用户意图,完成高层次的语义理解和决策并且选出最优动作方案。
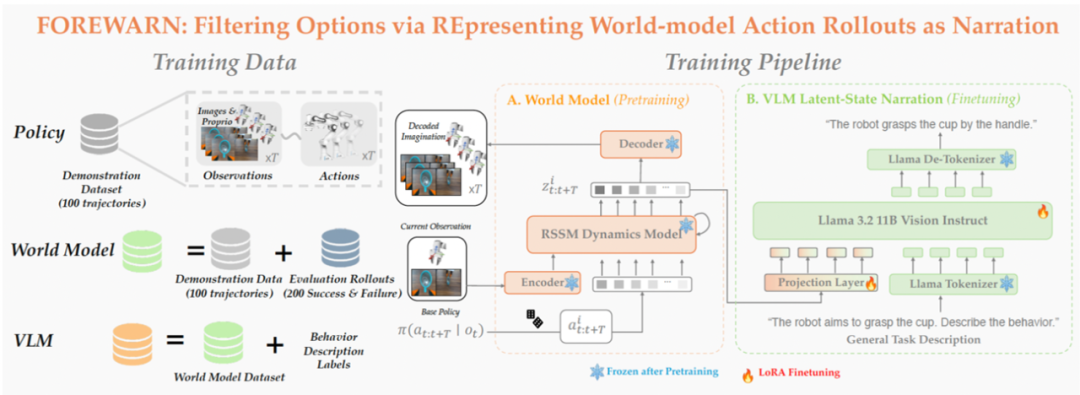
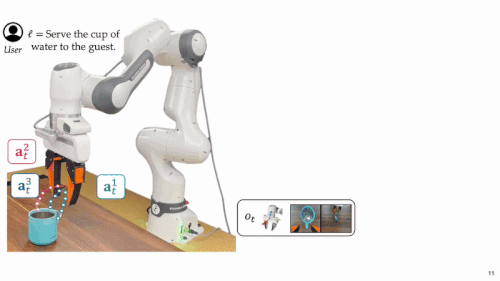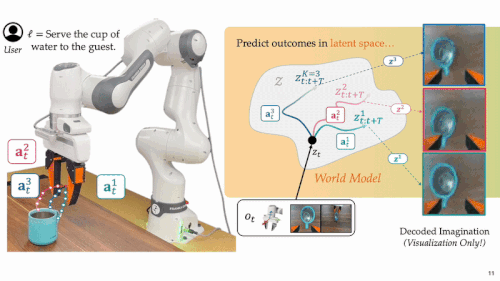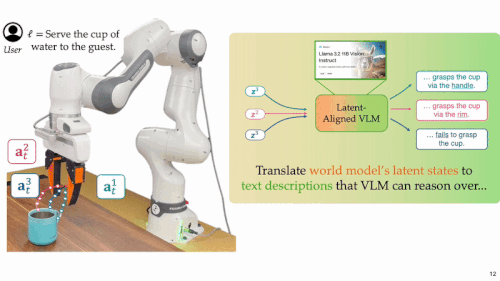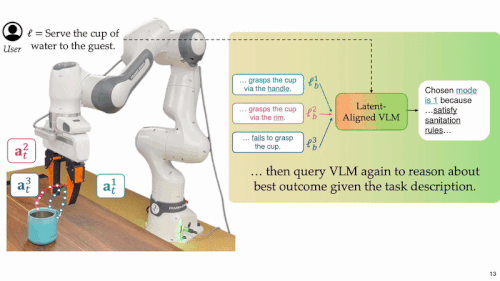
上图展示了 FOREWARN 系统的整体流程,其关键步骤如下:
-
候选动作采样与聚类:机器人基于当前观测,从动作生成模型中采样多个候选方案,并通过聚类去冗,保留 K 个具代表性的动作用于后续评估。
-
隐空间未来预测:每条代表性动作方案与当前观测图像共同作为输入世界模型,在低维隐空间中预测其未来演化,构建对未来的想象。
-
语义转译:由于隐空间中的「脑补」难以直接解析,系统将这些隐空间的「脑补」输入经过微调的多模态语言模型(MM-LLM),MM-LLM 将其转译为自然语言形式的行为描述,使其能够被用于语义层面的理解与用户偏好对齐。
-
最优方案筛选与执行:结合用户指令或任务描述,MM-LLM 对所有预测的未来进行语义评估,从中筛选并执行最契合意图的动作方案。
创新亮点
🧠 隐空间对齐 – 让 MM-LLM「听懂」世界模型的预测。本研究首次实现了世界模型的低维潜在动态空间与多模态语言模型的语义空间对齐,使语言模型能够准确「读懂」不同动作方案所引发的未来演化,从而跨模态完成从「感知」到「理解」再到「决策」的闭环推理流程。
⚙️ 端到端自动化 – 无需人工示范,实时智能决策。FOREWARN 实现了全流程自动化的部署时决策机制:无需额外数据采集,系统可在运行时高效从上百个候选方案中自主筛选出最优动作方案,显著降低了部署门槛与人力成本。
🤖 泛化能力强 – 复杂任务中同样稳健适用。 无论是抓取、搬运等基础操作,还是长时序、多阶段、高语义依赖的复杂任务,FOREWARN 都展现出卓越的通用性与稳健性。

实验结果:高效且可靠
为验证 FOREWARN 框架在实际部署中的有效性,我们在多项机器人任务中进行了系统评估。结果显示,单纯依赖模仿学习训练出的动作生成模型在真实环境中表现极为不稳定:成功率常常低于 30%,在部分场景甚至跌至 10%。这突显出当前模仿学习方法在应对任务变化和用户偏好时的严重局限。
而引入 FOREWARN 框架后,系统首次具备了在运行时主动评估并筛选策略的能力,整体成功率显著跃升至 70%–80%,实现了量级上的突破。更重要的是,即使任务指令发生变化、操作偏好改变或感知输入受到干扰,系统仍能维持 60%–80% 的成功率,展现出强大的策略稳健性与环境适应能力。这一结果表明,FOREWARN 有效弥合了「离线训练」与「在线部署」之间的能力鸿沟,为具身智能系统的高可靠性控制提供了切实可行的解决路径。
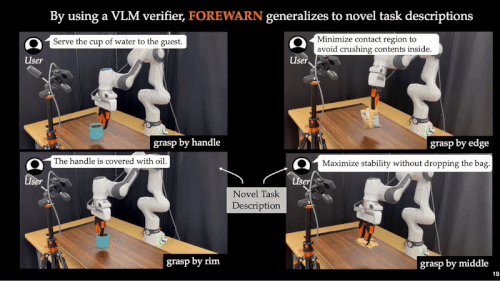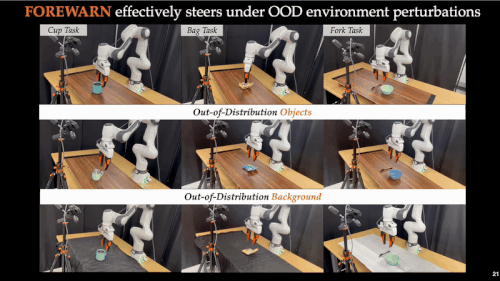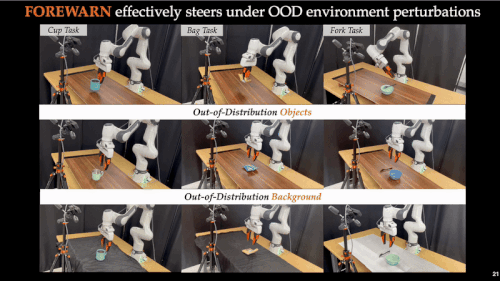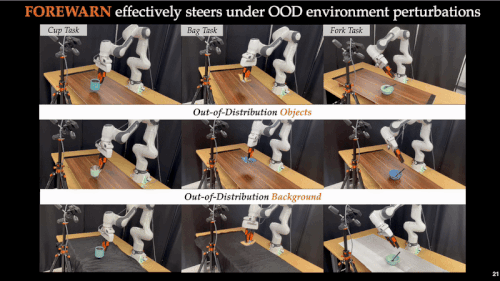
面向未来:可扩展与可优化
尽管 FOREWARN 已在多个真实任务中表现出卓越性能与通用性,研究团队指出,要进一步推广至更大规模的具身智能场景,仍面临三大挑战:一是底层生成策略仍需提升多样性与泛化能力,以覆盖更丰富的行为空间;二是世界模型对大规模、多样化数据依赖较强,在数据稀缺场景下性能可能下降;三是推理效率与算力成本有待优化,尤其是在大模型设定下,亟需探索更高效的推理机制。考虑到 MM-LLM 与世界模型正快速发展, FOREWARN 的部署智能优势也将更加凸显,助力机器人在更多未知场景中根据自然语言指令,自主选择最安全、最合理的操作方案。
近年来,学术界与工业界正加速迈向从「模仿学习预训练(pre-training)」到「部署智能(test-time intelligence)」的转变。FOREWARN 提出了一条清晰且实用的路径:通过世界模型「脑补未来」、多模态语言模型「解码与评估」,两者协同构建具备推理能力的部署智能,实现真正意义上的「智」控机器人。对于那些追求高鲁棒性与强泛化能力的前沿机器人应用,FOREWARN 展现出广阔的落地潜力。我们也期待,这一方式能激发更多跨模态、跨学科的探索与创新,让未来的机器人更「懂」世界、更「信」人类指令,也更可靠地走进人类生活。

©
(文:机器之心)