

Sekai团队 投稿
量子位 | 公众号 QbitAI
LeCun、李飞飞力挺的世界模型,想要实现,高质量数据是关键,也是难点。
现在,国内研究机构就从数据基石的角度出发,拿出了还原真实动态世界的新进展:
上海人工智能实验室、北京理工大学、上海创智学院、东京大学等机构聚焦世界生成的第一步——世界探索,联合推出一个持续迭代的高质量视频数据集项目——Sekai(日语意为“世界”),服务于交互式视频生成、视觉导航、视频理解等任务,旨在利用图像、文本或视频构建一个动态且真实的世界,可供用户不受限制进行交互探索。

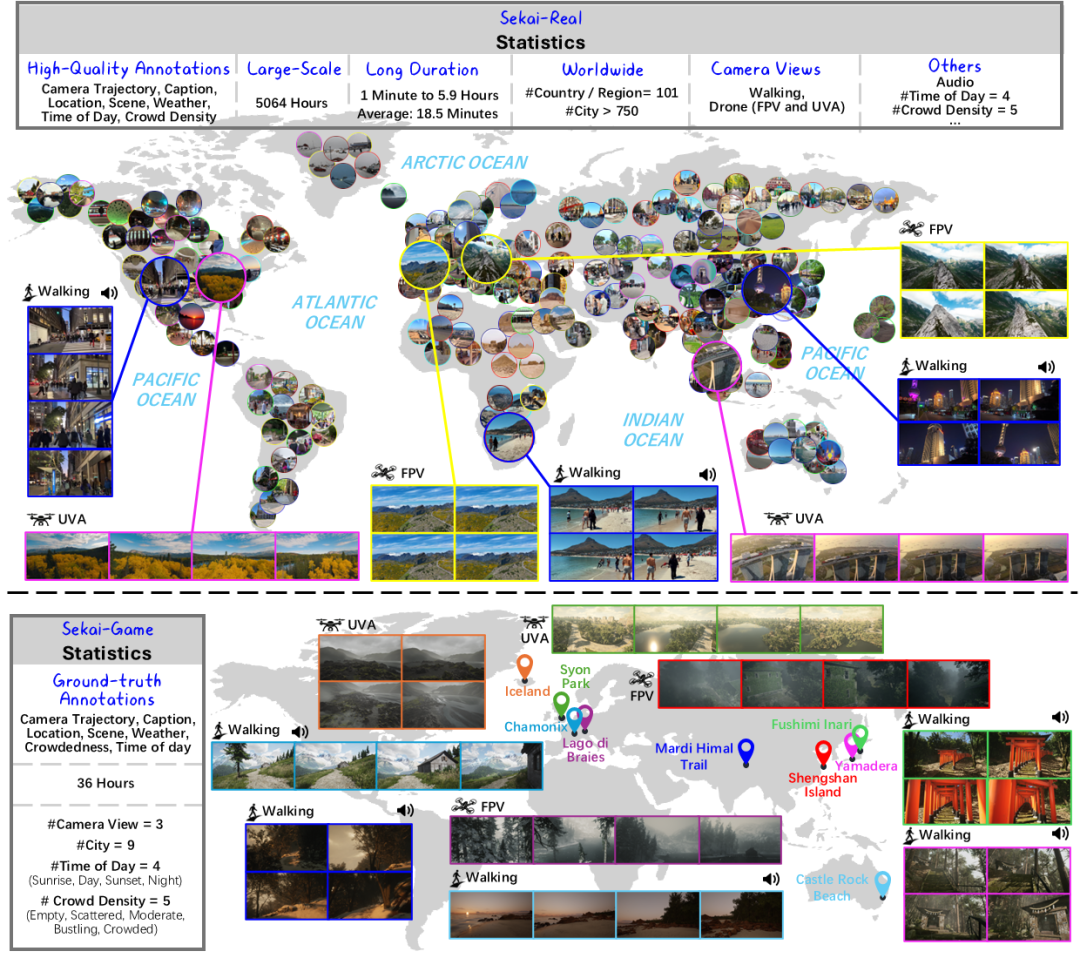
它汇聚了来自全球101个国家和地区、750多座城市的超过5000小时第一人称行走与无人机视角真实世界或游戏视频,配有精细化的标签,涵盖文本描述、地点、天气、时间、人群密度、场景类型与相机轨迹等重要信息。总的来说,具有视频质量高、视频时间长、视角多样、地域丰富及多维度标签等特点。
团队还利用Sekai部分数据,训练了一个初步的交互式视频世界探索模型——Yume(日语意为“梦”)。Yume在输入图片的基础上,通过交互式键鼠操作(移动、视角转动)自回归形式地控制生成视频。
Sekai-Real与Sekai-Game
Sekai通过精心收集YouTube视频和游戏内高清影像,形成了两个互为补充的数据集:面向真实世界的Sekai-Real(YouTube视频)和面向虚拟场景的Sekai-Game(游戏视频)。
在Sekai-Real数据集中,团队从超过8600小时的YouTube第一人称行走和无人机视频中严格筛选,确保原始视频分辨率不低于1080P,帧率高于30FPS,且码率较高;所有视频均发布于近3年内,场景新颖且贴近现实。此外,视频保留了原生立体声,以完整呈现真实世界的声音环境。
为进一步提升数据质量,团队设计了综合考虑视频画质、内容多样性、地点、天气、时间、相机运动轨迹等多个维度的采样模块,优中取优提取了超过300小时的子集Sekai-Real-HQ。
而Sekai-Game数据集则来源于虚幻引擎5打造的高拟真游戏《Lushfoil Photography Sim》。该游戏具有逼真的光影效果与统一的影像规格。团队实机操作并录制超过60小时的游戏实况视频,同时开发工具链精确获取“真值”的坐标、天气与相机运动轨迹等信息。
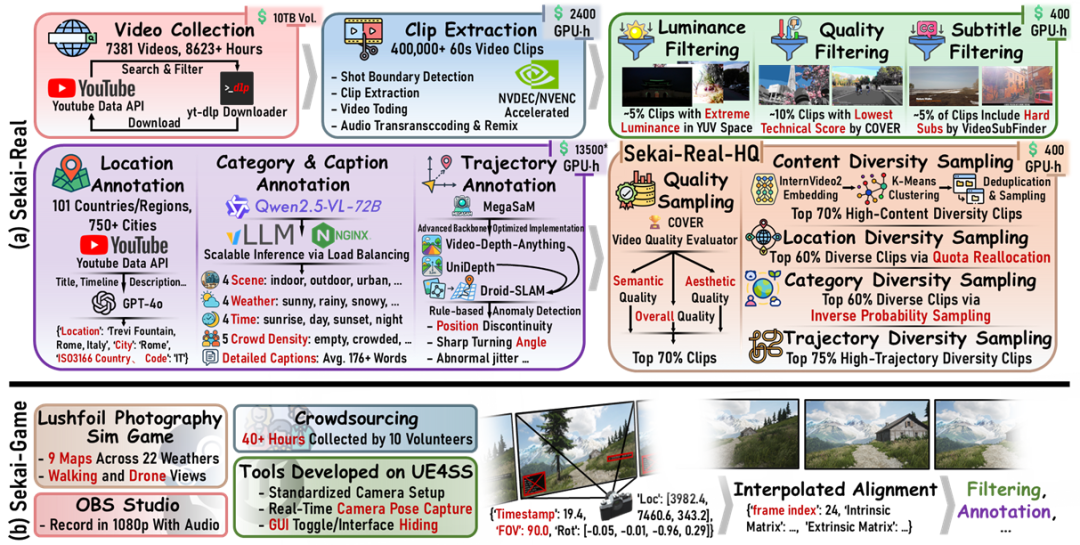
构建Sekai数据集整体流程包括以下四个关键环节:
视频收集阶段:团队从YouTube共收集8623小时视频,从游戏中录制超过60小时视频。
预处理阶段:经过处理后,分别得到6620小时Sekai-Real与40小时Sekai-Game。
-
镜头边界检测:使用PyNVideoCodec库加速视频解码,同时利用CVCUDA库在GPU端高效进行颜色空间转换和直方图计算等图像处理,每个镜头前后各裁剪5秒,最终得到时长在1小时到近6小时的视频片段。
-
剪辑提取与转码:团队将视频片段统一编码为H.265MP4格式,720p分辨率,30fps帧率,4Mbps码率,以标准化视频数据。
-
视频过滤:通过亮度评估、视频质量评分、硬字幕检测等方法去除低质量片段。此外,对Sekai-Real部分带有相机轨迹标注的数据,团队还设计了相应的异常检测算法,排除了相机轨迹存在剧烈反转、视角突变或位移异常的片段。
视频标注阶段:对于Sekai-Real,团队运用大型视觉语言模型高效地进行视频标注。
-
位置标注:利用Google YouTube数据API获取视频元信息,结合GPT-4o模型精准解析区域、城市与国家的结构化位置信息。
-
类别与描述标注:团队采用两阶段策略进行精细标注。首先从场景类型、天气、时间、人群密度四个维度进行分类;其次,结合视频帧与分类结果,使用Qwen 2.5-VL生成详尽的、平均长度176字的视频逐时序描述。
-
相机轨迹标注:使用改进的MegaSaM在超过600小时的样本上提取相机轨迹。
采样阶段:考虑到完整Sekai-Real数据集训练成本高昂,团队开发了一套综合视频质量、多样性(包括内容、地点、类别、相机轨迹)的采样策略,从而获得优中取优的Sekai-Real-HQ子集,用于进一步的模型训练。
对于Sekai-Game,作者团队开发了脚本系统,从游戏引擎中直接获取精确的标注信息,例如天气,相机轨迹等。与Sekai-Real类似,采集到的数据经过分段剪辑、转码、过滤处理后,最终得到约36小时具备精确标注的游戏视频数据。
数据呈现
最终数据具备以下特点:
视频规格:片段时长从1分钟到近6小时,平均时长18.5分钟,Sekai-Real含立体声音轨。
位置信息:精准解析区域、城市、国家三级结构化信息。
内容分类:涵盖场景类型、天气、昼夜、人群密度四大维度。
视频描述:逐时序视频描述平均176字,结合分类标签生成。
相机轨迹:精确标注真实与虚拟数据的相机轨迹信息。
研究团队表示,希望Sekai成为推动世界建模与多模态智能的重要数据基石,广泛助力于世界生成、视频理解与预测、 文本图片生成视频、视听协同建模、自主导航与仿真等领域。未来将继续以实现真实且丰富的时空穿行体验为目标,不断迭代与优化Sekai与Yume项目。
文章链接:
https://arxiv.org/abs/2506.15675
项目主页:
https://lixsp11.github.io/sekai-project/
数据下载:
https://huggingface.co/datasets/Lixsp11/Sekai-Project
项目代码:
https://github.com/Lixsp11/sekai-codebase
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)