
大家好,按照计划,今天这篇文章本来是想谈谈vllm执行1次fwd中的各种细节。但是由于最近异步RL的讨论热度比较高,身边的很多朋友在二次开发中都遇到了在rollout上如何异步的问题,所以今天我们来探究一个更细节的话题:如何使用vllm做最小程度的异步二次开发?那么接下来就有请出今日的主角:AsyncLLM
一、online serving回顾
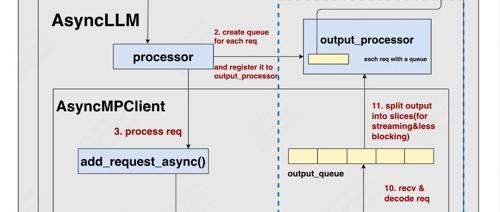
我们在本系列开篇,就讲过online serving的整体流程,这里放出流程图以便大家在后文参考,详细的介绍就不赘述了,大家可以自行看第一篇内容(注:相较于第一篇中的流程图,这里对之前描述有歧义的地方做了细节上的更改)
二、AsyncLLM
接下来,我们就对process0的部分做展开描述。阅读本文前,需要读者对python异步
首先理一下整体流程:
-
假设客户端向/v1/chat/completions发来一条请求,则该请求通过async def create_chat_completion进行处理。
https://github.com/vllm-project/vllm/blob/refs/tags/v0.8.2/vllm/entrypoints/openai/api_server.py#L453
-
而进行处理时,本质上调用的是 OpenAIServingChat中的async def create_chat_completion
https://github.com/vllm-project/vllm/blob/refs/tags/v0.8.2/vllm/entrypoints/openai/serving_chat.py#L118
-
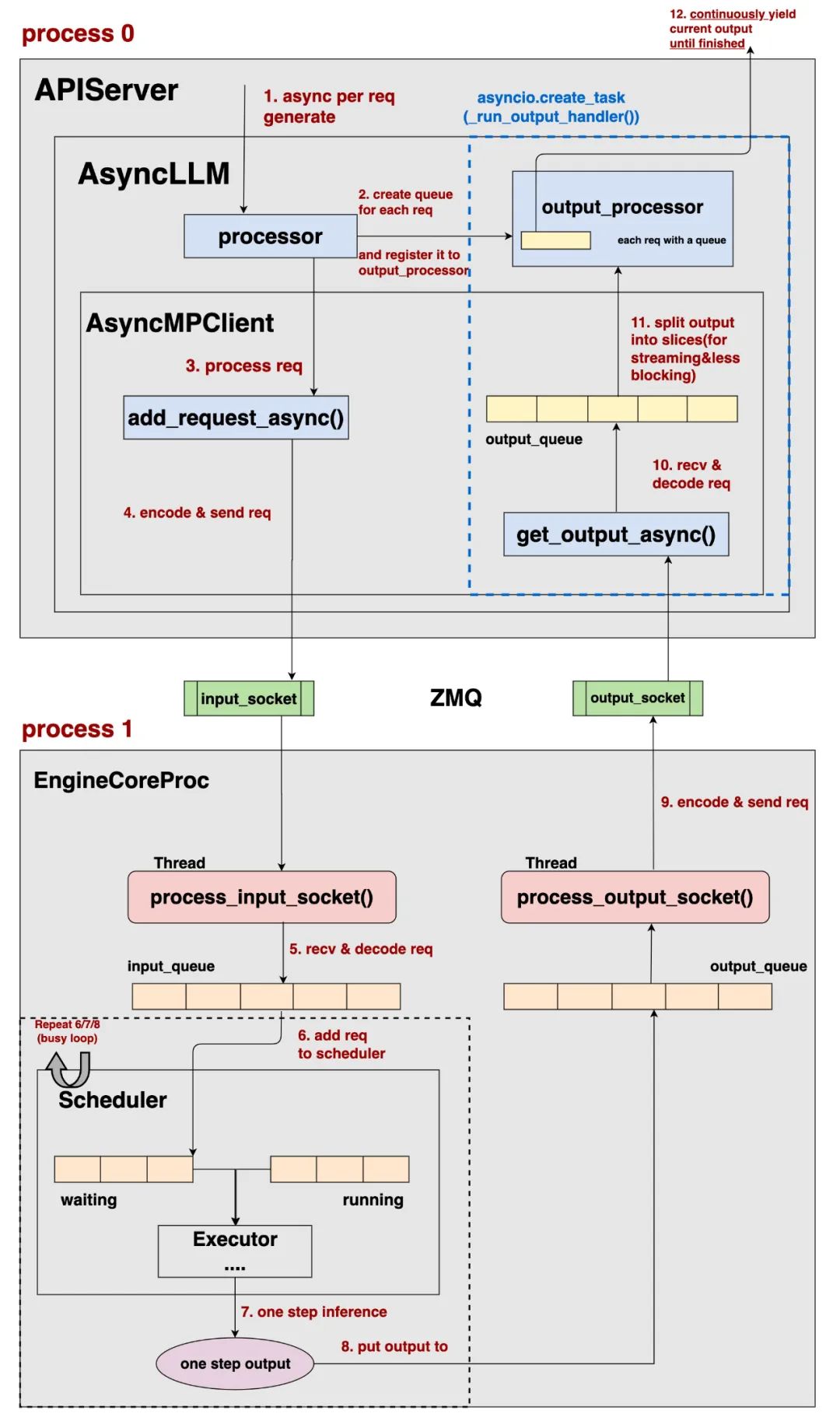
在这个协程函数中,我们会调用 AsyncLLM的async def generate方法,这就是上图中的“1.async per req generate”:
调用入口:https://github.com/vllm-project/vllm/blob/refs/tags/v0.8.2/vllm/entrypoints/openai/serving_chat.py#L252 具体实现:https://github.com/vllm-project/vllm/blob/refs/tags/v0.8.2/vllm/v1/engine/async_llm.py#L228
注意,以上都是假设当前客户端请求并发数=1。所以我们先来看单条请求是如何运转起来的,再来看多条请求的情况。
这里以AsyncLLM的async def generate为入口开始分析。
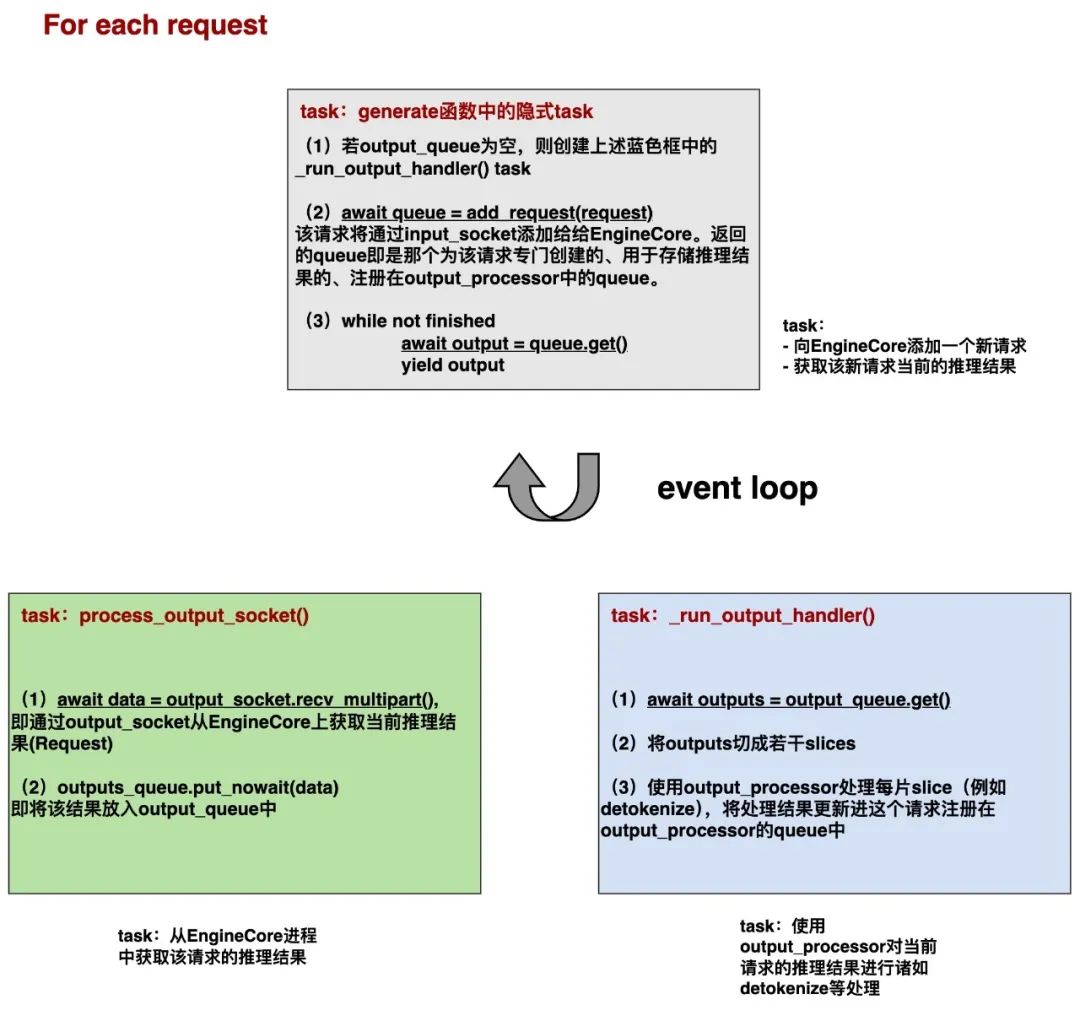
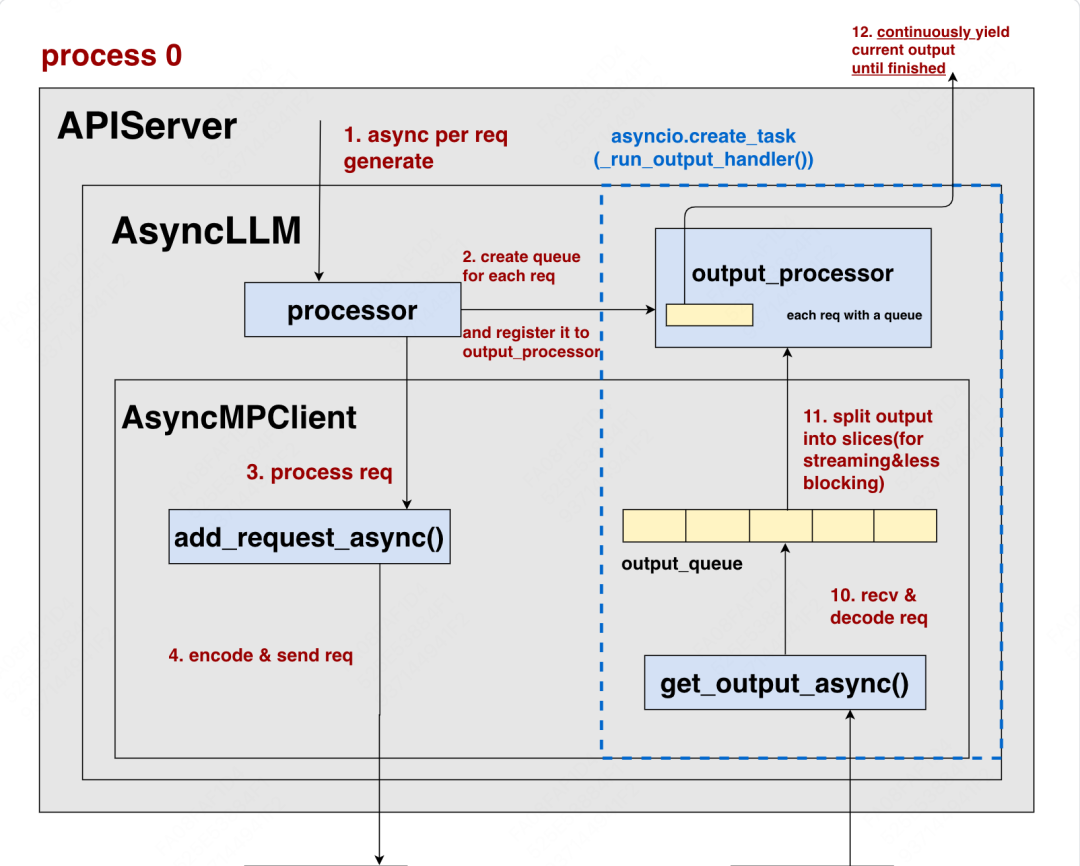
本质上来说,一条请求的async def generate可以被拆解成上述3个asyncio.task,由同一个事件循环(event loop)去交替分配它们的对cpu单核的控制权。
我们直接从一个更广义好懂的层面上理解这3个task。大家可以参考“整体流程”这张图,对于客户端一条新来的请求,它大致要经过下面3个阶段:
-
add_request:将这个新请求添加进EngineCore的Scheduler中,这里需要经过input_socket进行传输(灰色块) -
从EngineCore获取当前推理结果放入output_queue中:这个过程需要经过output_socket进行传输(绿色块) -
使用output_processor对outpue_queue里的结果进行后处理:例如detokenize等操作,最终将后处理结果放入注册在output_processor的queue中(回忆一下,一个请求对应一个queue)(蓝色块)
对于一个请求,如果你想串行执行上面这3个过程,那肯定是低效的:例如,首先你要等请求经过了input_socket,完全添加进Scheduler,然后你又要等请求完全推理完毕后通过output_socket返回给你,最后你还要等一长串tokenid完全detokenize后再返回给用户,这个串行效率简直不可忍受。
一种可行的解决办法例如:在我通过input_socket传输请求给EngineCore上Scheduler的过程中,我可以去检查下是否有新的推理结果可以从output_socket传过来(推理是token by token的,所以推理结果总是在不断更新的),在等output_socket做传输的同时,我再去检查下是否已经有先前已经传递过来的、可以做detokenize等后处理的推理结果。图中await部分即为task交出控制权,以便让别的task可以触发执行的地方。如此一来我们可以实现3个任务的并发,大大提升了单条请求的处理效率。
当你在阅读代码时,你会发现整体上看,是以上述灰色块为入口,而绿色块和蓝色块都是在灰色块内部的执行中被依次创建的(灰色块没有被显式创建成asyncio.task的形式,但你依然可以从task的角度理解它)。虽然它们彼此在创建时有嵌套关系,但不妨碍你将它们最终理解成是一个event loop中的3个task。
好,最后我们再来提一点,也就是图中灰色块async def generate()中的第(3)步,我们前面提到过,由于推理过程是一步步进行的,所以你通过await output = queue.get()返回的可能只是当前部分的推理结果(整个推理过程还没结束,还在EngineCore上持续进行着),所以这里才会使用while循环,持续get output直到最终取得完整的推理结果(finished)。而在这里我们用的是yield output,这也意味着async def generate()返回的是一个AsyncGenerator实例,具体来说:
-
当你对一条请求调用
async def generate()时,其中的代码不会即可执行,而是会返回给你一个AsyncGenerator,我们就用变量名generator来表示这个返回结果 -
当你后续使用
async for output in generator时,相关的代码才会被执行,你才能在for循环的每次遍历中取到真正的output结果 -
对于一个请求,你可以将这个外层的
async for循环也当成是一个隐式的task,每执行完1次遍历后,这个task就会交出控制权给event loop,进而由event loop决定下次应该把控制权交给哪个task(也可能还是这个task)。这样一来,在各个请求间不会发生阻塞(不会因为等待单个请求的结果,而阻塞了别的请求的进行);二来,也不会阻塞单个请求内其余task的执行。
理解好了单个请求内是如何实现并发调度的,理解多个请求的并发就很简单了:vllm使用FastAPI辅助构件online serving,你可以将每个请求理解成是独立的一个个asyncio.task,也是由event loop并发调度。不过如果你已经理解了上述所说的AsyncLLM的async def generate()返回的是一个AsyncGenerator,也理解了对于单个请求,在执行async for output in generator这个循环的每次遍历后都会交出控制权给event loop,你就应该发现了:如果想要自己构建一个异步的推理引擎,那么直接用AsyncLLM + async for就可以奏效,你不需要在外层包装一个APIServer了(当然也看你具体的需求)。
(文:GiantPandaCV)