

闻乐 发自 凹非寺
量子位 | 公众号 QbitAI
LeCun在干嘛呢?
就在扎克伯克亲自带队Meta的AI项目,千亿薪酬挖得硅谷人心浮动之际。Meta在AI领域最负盛名的大佬、图灵奖得主、深度学习三巨头之一的Yann LeCun,却几乎声量全无,他没有参与LLM基础模型的研发,也开始在社交网络上消停了。
LeCun是要离开Meta了吗?
不不不。他可能只是在憋自己想追逐的大招,比如——世界模型。而且就在最近,LeCun团队的世界模型新进展来了。
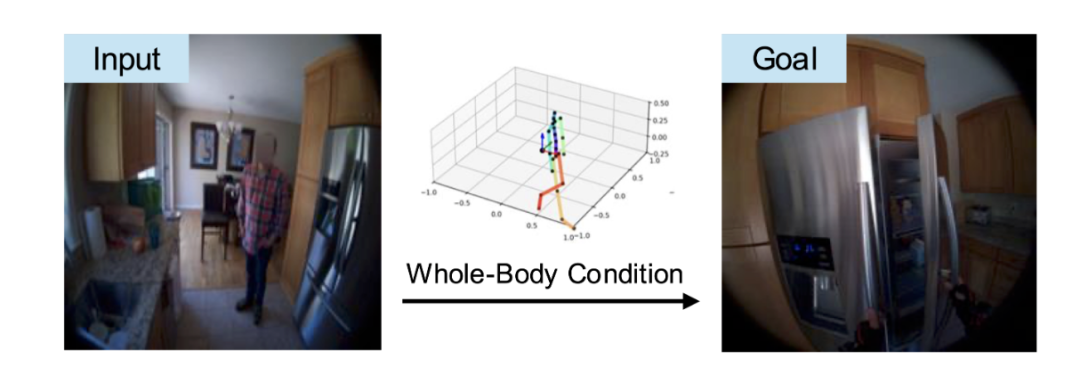
名叫PEVA模型,新突破是让具身智能体学会这人类一样的“预判能力”,首次实现16秒连贯场景预测。怎么说呢?就像人类伸手时会预判手臂进入视野的角度、走路时会提前观察脚下路径,LeCun团队的最新模型,可以让机器人实现这样的能力。
该模型通过结构化动作表示将人体48维关节运动学数据与条件扩散Transformer结合。
利用VAE编码视频帧、自适应层归一化嵌入动作条件及跨历史帧注意力机制等,实现了从全身动作预测第一视角视频的高精度生成与长期时序连贯。

PEVA模型让具身智能体不再依赖“上下左右”这种抽象信号进行训练,而是以第一人称视角的视频+全身姿态轨迹为输入,让它 “模仿” 人类第一视角下的动作与感知。

通过随机时间跳跃与跨历史帧注意力,解决了扩散模型在长时序动作预测中的计算效率与延迟效应问题。
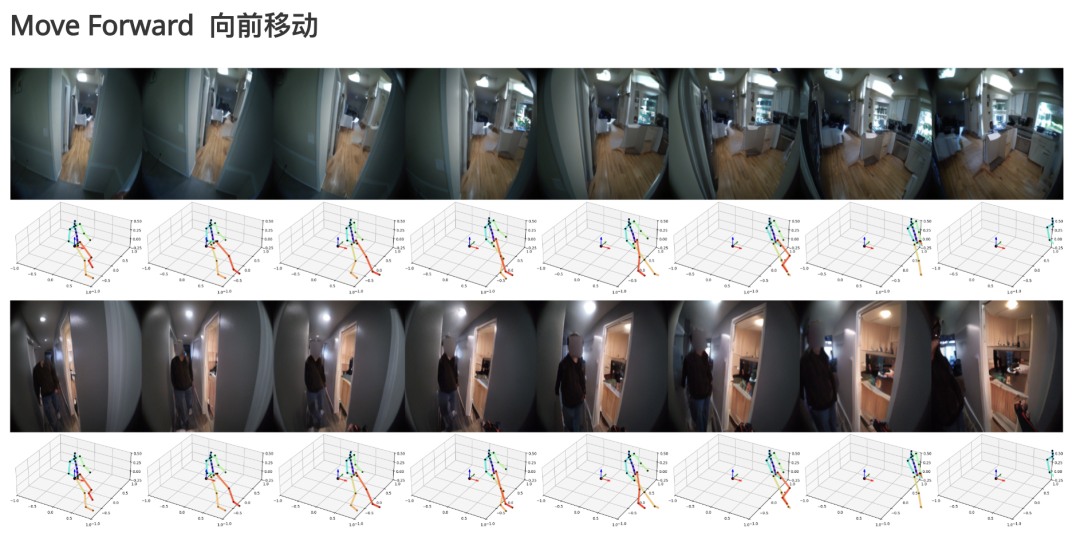
不仅能让智能体精确模拟伸手取物、行走转向等基础动作,更实现了长达16秒的连贯场景预测。

PEVA还具备智能规划能力,能在多个动作选项中筛选出最优解,轻松完成开冰箱、抓取目标物体等复杂任务。

这项突破,或许将改写具身智能体 “笨拙反应” 的历史,让它们真正学会“思考”下一步。
LeCun这是要让AI从“人工智障”进化成“人工预判”啊!

PEVA模型: 像人类一样 “模拟” 世界
LeCun团队认为具身智能体世界模型应具备理解、预测和规划等能力,能够让机器像人一样 “想象” 动作后的视觉效果。
比如,在一个家庭环境中,模型要能识别出沙发、桌子等物体,以及人在房间走动、拿取物品等动作,然后基于这些感知预测未来行动轨迹。
于是,PEVA模型摒弃了抽象控制信号,采用真实物理基础上的复杂动作空间。
关键创新在于用全身动作数据训练模型,让智能体在多样化的现实场景中以第一人称视角行动。
结构化动作表示
人体动作包含“整体移动”(如行走)和“关节精细运动”(如手指抓握),需用高维结构化数据同时捕捉这两层信息。
传统模型使用低维控制信号(如速度、转向),无法刻画全身关节的协同运动对视觉的影响(如伸手时肩、肘、腕的联动如何改变视野)。
结构化动作表示的核心目标是完整捕捉人体运动中“整体动作”与“细微关节变化”的双重信息。
技术实现:
-
运动学树结构编码:将人体动作表示为以骨盆为根节点的关节层级树,包含根关节的3维平移(全局动态)和15个上半身关节的相对旋转(每个关节3维欧拉角,共45维),总维度48维。 -
局部坐标系转换:将全局坐标转换为以骨盆为中心的局部坐标,消除初始位置和朝向的影响,使动作表示具有平移 / 旋转不变性(如无论人在房间何处,相同伸手动作的编码一致)。 -
归一化与差分表示:位置参数缩放至[-1,1],旋转参数约束在[-π,π],并以 “帧间变化量” 表示动作(如从第t帧到t+1帧的关节运动增量),强化时间动态特性。
通过“关节层级编码+局部坐标系转换+帧间差分”的设计,将人体全身运动转化为模型可理解的高维结构化数据,既保留了物理真实性,又支持细粒度的视觉控制。
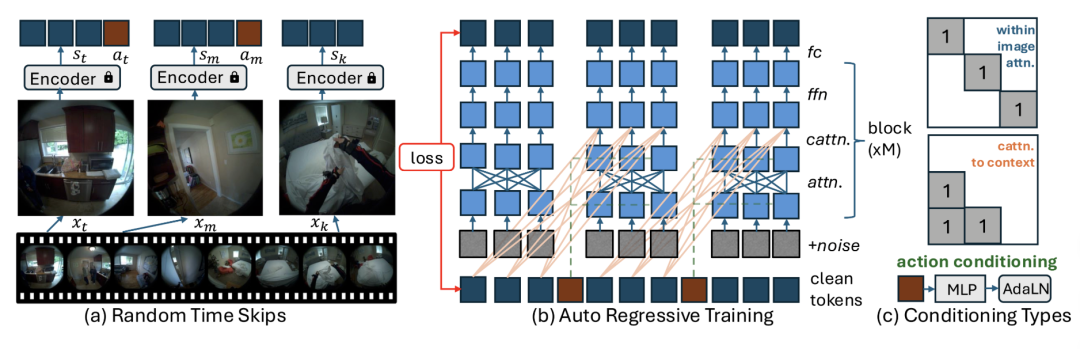
条件扩散Transformer架构
让智能体学会“预测”能力的挑战在于动作与视觉的关系具有高度非线性(如同一手臂动作在不同环境中导致的视觉变化不同),且存在延迟效应(如行走几步后才看到新场景),需高效捕捉长距离依赖。
△PEVA模型设计
架构创新:
-
随机时间跳跃训练:从长视频中随机采样帧(如32秒窗口中选16帧),并将时间跳跃作为动作输入的一部分,让模型学习不同时间尺度下的动作动态(如快速挥手与缓慢挥手的视觉差异)。 -
时间注意力机制:通过跨历史帧的交叉注意力,让当前帧生成时关注过去多帧的 “干净” 特征(未加噪声的真实编码),建模动作的延迟视觉影响(如提前预测转身后续的场景变化)。 -
动作嵌入:将48维动作向量拼接后通过自适应层归一化嵌入Transformer各层,动态调整网络参数,使动作信息直接影响视觉生成过程(例如,动作中的“向前走”信号会引导模型生成视角前移的画面)。
该模型采用自回归扩散训练,通过强制输入真实历史帧编码,结合序列级损失函数,确保生成帧在动作驱动下保持时序连贯(如连续伸手动作的视觉轨迹平滑)。
在训练中使用了Nymeria数据集,该数据集包含同步的第一视角视频与全身动作捕捉数据,覆盖了真实场景中的日常动作(如做饭、行走),提供充足的 “动作-视觉” 对儿用于训练,避免了模拟数据的物理偏差。

训练时随机选择帧子集(如16帧),通过因果掩码并行处理序列前缀,提升长视频训练效率,同时覆盖动作的短期(如手部微动)与长期(如绕桌行走)影响。
实验成果:从“机械执行”到“智能规划”的跨越
PEVA模型让具身智能体实现了从人体关节运动学轨迹到第一人称视频的端到端预测。
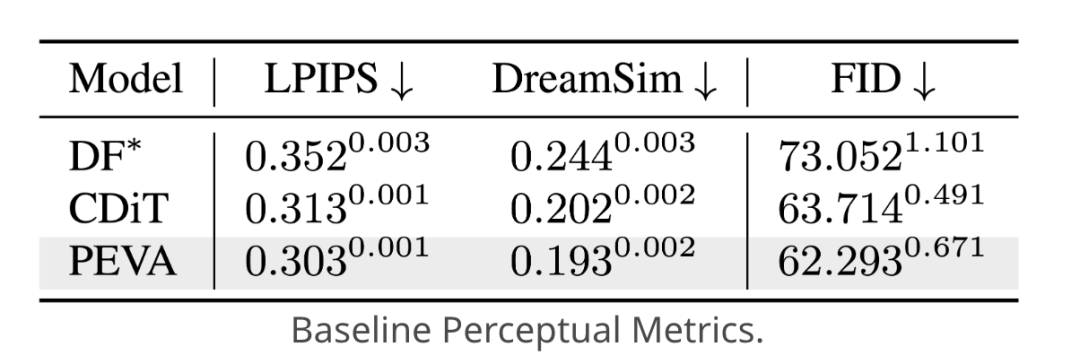
定量分析表明,PEVA模型在多项任务上表现优于基线模型。
在单步预测中,相比CDiT基线,PEVA的LPIPS值降低0.01,FID降低1.42,表明其生成画面与真实画面的视觉相似度更高、生成质量更优。
在原子动作控制实验里,针对 “左手向上”“全身向前” 等基础动作,PEVA的LPIPS值比CDiT基线低5%-8%,证明其能更精准地捕捉细粒度动作带来的视觉变化。
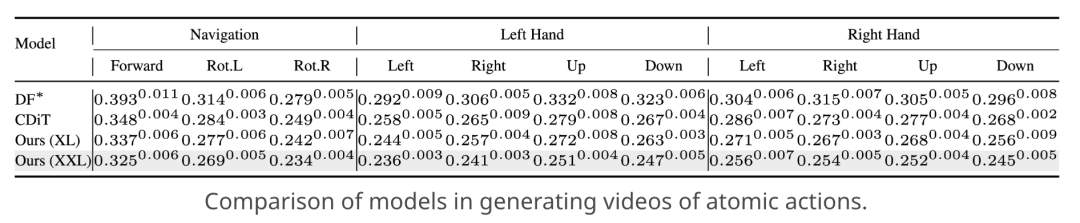
长期视频生成方面,在16秒长序列预测时,PEVA的FID值相比Diffusion Forcing(DF)低15%以上,生成视频的时序连贯性显著增强。
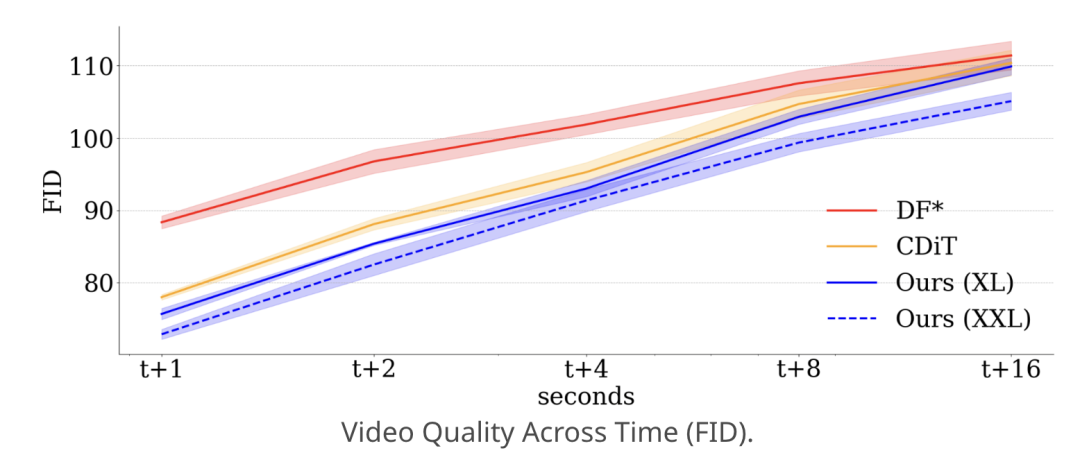
不仅如此,PEVA模型还能准确预测2秒内的画面变化,支持长达16秒的视频生成。

在给定多个可能的动作序列时,模型能通过感知相似度评估自动排除不合理选项,选择与目标场景最匹配的动作路径,展现出类似人类的“试错-规划”思维。
比如,PEVA能够通过感知环境,排除第一行“打开水槽”和第二行“走到户外”的动作序列,找到第三行“打开冰箱”的合理动作。

One More Thing
有意思的是,LeCun曾多次公开表达了对VAE(基于变分推断)局限性的批评,却在PEVA模型的预训练中使用了VAE编码器,并用VAE解码器进行了图像生成的后处理。
LeCun曾称“VAE是生成模型中的酸黄瓜”(可以理解为“不够好但勉强可用”),并调侃其生成样本的模糊性。
于是,此番让VAE扮演“视觉特征转换器”的角色引起了网友们的讨论。
Yann LeCun立场有所改变?

有人认为,尽管LeCun有时不同意某种观点,但他支持各种新可能。
或者,VAE是一种更实用的选择。

如果智能体真能像人类一样预判行动,以后扫地机器人能提前 “想” 清楚路线,估计再也不会卡在桌角反复横跳了。
你最想让机器人帮你搞定什么事呢?
论文地址:https://arxiv.org/abs/2506.21552
项目地址:https://dannytran123.github.io/PEVA/
(文:量子位)