

随着各种大模型供应商各种推陈出新,在实际已经用可能会随时切换不同的模型,试想一下:你费尽心思搞了个高端 AI 工具整合,客户却突然说要从 Qwen 换到 Deepseek,因为成本更低。或者,他们得用本地模型处理敏感数据,同时又想用云端模型搞定普通查询。如果没搞好抽象层,每次变动都得重写整合代码,简直是噩梦!但有了 LiteLLM 和 Model Context Protocol (MCP),这事儿就变成改个配置那么简单。

这篇文章要给你展示,LiteLLM 的通用网关咋跟 MCP 搭档,打造一个真·可移植的 AI 工具整合。不管你用的是 OpenAI、Anthropic、AWS Bedrock、Qwen、Deepseek,还是通过 Ollama 跑本地模型,你的 MCP 工具都能无缝适配。
如果觉得这篇文章有用请记得关注本公众号哦!
我们的 MCP 服务器:客户服务助手
在聊 LiteLLM 和 MCP 的连接前,先了解下我们要连啥。我们用 FastMCP 搭了个完整的客户服务 MCP 服务器,具体在我们的 MCP 完整指南里有讲。这个服务器是展示不同客户端整合的基础。
我们的 MCP 服务器提供了三个超强的工具,任何 AI 系统都能用:
可用工具:
-
• get_recent_customers:拉取最近活跃的客户列表和他们的状态,帮 AI 了解客户历史和行为模式。 -
• create_support_ticket:创建新的支持工单,可以自定义优先级,验证客户是否存在,还会生成唯一工单 ID。 -
• calculate_account_value:分析购买历史,算出账户总价值和平均购买金额,方便客户分层和支持优先级排序。
服务器还提供了一个客户资源(customer://{customer_id}),可以直接访问客户数据,还有个生成专业客服回复的提示模板。
这套系统的牛掰之处在于,这些工具能适配任何兼容 MCP 的客户端,不管是 OpenAI、Claude、LangChain 还是 DSPy,建一次服务器,就能服务所有框架。这就是 MCP 带来的标准化整合威力!
接下来,我们会讲 LiteLLM 咋连上这个服务器,让这些工具适配超过 100 种 LLM 提供商。
认识 LiteLLM:通用 LLM 网关
LiteLLM 不是普通的 AI 库,它就像 AI API 的“罗塞塔石碑”,让你写一次代码,就能适配所有支持的模型。主要特点有:
-
• 支持 100+ 模型:从 OpenAI、Anthropic 到本地模型和专业提供商。 -
• 统一接口:同一套代码适配所有提供商。 -
• 负载均衡:把请求分配到多个提供商。 -
• 成本追踪:监控使用量和成本。 -
• 失败切换:失败时自动换提供商。 -
• 格式转换:在不同 API 格式间无缝转换。
想深入了解 LiteLLM,可以看看我写的关于多提供商聊天应用和 RAG 增强的文章。
LiteLLM + MCP 的超能力
把 LiteLLM 和 MCP 结合起来,简直无敌:
-
• 一次编写,哪儿都能跑:MCP 工具适配任何 LLM 提供商。 -
• 提供商无关:切换模型不用改工具整合代码。 -
• 成本优化:把请求发到最划算的提供商。 -
• 合规友好:敏感数据用本地模型,普通查询用云端。 -
• 面向未来:新 LLM 提供商上线后,现有工具也能直接用。
打造你的第一个 LiteLLM + MCP 整合
我们来搞个整合,展示 LiteLLM 如何让 MCP 工具适配不同提供商。
步骤 1:配置整合
这是连接 LiteLLM 和 MCP 服务器的核心代码:
import asyncio
import json
import litellm
from litellm import experimental_mcp_client
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from config import Config
asyncdefsetup_litellm_mcp():
"""配置 LiteLLM 和 MCP 工具"""
# 创建 MCP 服务器连接
server_params = StdioServerParameters(
command="poetry",
args=["run", "python", "src/main.py"]
)
asyncwith stdio_client(server_params) as (read, write):
asyncwith ClientSession(read, write) as session:
# 初始化 MCP 连接
await session.initialize()
# 以 OpenAI 格式加载 MCP 工具
tools = await experimental_mcp_client.load_mcp_tools(
session=session,
format="openai"
)
print(f"加载了 {len(tools)} 个 MCP 工具")关键点在于 format=”openai” 参数。LiteLLM 的实验性 MCP 客户端会把工具加载成 OpenAI 的函数调用格式,然后 LiteLLM 再把这格式翻译成任何提供商能用的格式。
步骤 2:多模型测试
LiteLLM 的强项之一是让同一套代码适配多种模型:
# 根据配置动态选择模型
models_to_test = []
if Config.LLM_PROVIDER == "openai":
models_to_test.append(Config.OPENAI_MODEL)
elif Config.LLM_PROVIDER == "anthropic":
models_to_test.append(Config.ANTHROPIC_MODEL)
else:
# 测试多个提供商
models_to_test = [Config.OPENAI_MODEL, Config.ANTHROPIC_MODEL]
for model in models_to_test:
print(f"\n用 {model} 测试...")
# 同一套代码适配任何模型
response = await litellm.acompletion(
model=model,
messages=messages,
tools=tools,
)这种灵活性让你可以:
-
• 用不同模型测试工具,比较性能。 -
• 根据可用性或成本切换提供商。 -
• 针对不同查询类型用不同模型。
步骤 3:处理工具执行
LiteLLM 把工具执行标准化,适配所有提供商:
# 检查模型是否调用了工具
ifhasattr(message, "tool_calls") and message.tool_calls:
print(f"🔧 调用了 {len(message.tool_calls)} 个工具")
# 处理每个工具调用
for call in message.tool_calls:
print(f" - 执行 {call.function.name}")
# 通过 MCP 执行工具
arguments = json.loads(call.function.arguments)
result = await session.call_tool(
call.function.name,
arguments
)
# 把工具结果加到对话中
messages.append({
"role": "tool",
"content": str(result.content),
"tool_call_id": call.id,
})
# 用工具结果获取最终回复
final_response = await litellm.acompletion(
model=model,
messages=messages,
tools=tools,
)这段代码展示了 LiteLLM 如何:
-
• 用标准化格式接收工具调用。 -
• 通过 MCP 执行工具。 -
• 为每个提供商格式化结果。 -
• 处理完整的对话流程。
理解流程
我们来想象 LiteLLM 如何协调不同 LLM 提供商和 MCP 工具的沟通:
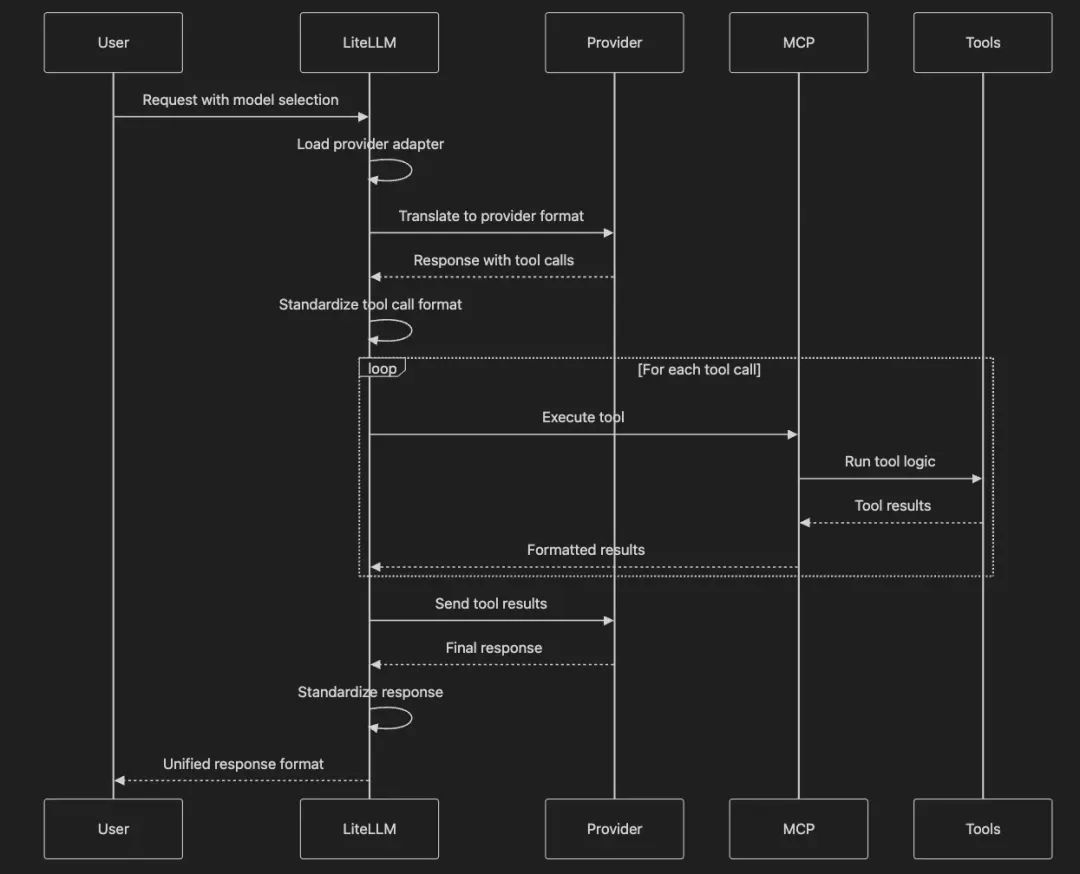
这张图展示了 LiteLLM 作为通用翻译器的角色,把不同提供商的格式转换,同时为你的应用保持一致的接口,让多种模型无缝支持 MCP 工具。
现实场景
用 LiteLLM 能干啥有趣的事儿?
场景 1:成本优化路由
# 把简单查询路由到便宜模型
if is_simple_query(message):
model = "gpt-4.1-mini" # 更便宜
else:
model = "gpt-4.1" # 更强
response = await litellm.acompletion(
model=model,
messages=messages,
tools=tools
)场景 2:合规性路由
# 敏感数据用本地模型
if contains_pii(message):
model = "ollama/llama2" # 本地模型
else:
model = "claude-sonnet-4-0" # 云端模型场景 3:失败切换
# LiteLLM 自动处理失败切换
models = ["gpt-4.1", "claude-sonnet-4-0", "ollama/mixtral"]
for model in models:
try:
response = await litellm.acompletion(
model=model,
messages=messages,
tools=tools
)
break # 成功,跳出循环
except Exception as e:
print(f"{model} 失败,试下一个...")
continue架构
完整的架构展示了 LiteLLM 如何连接多个世界:
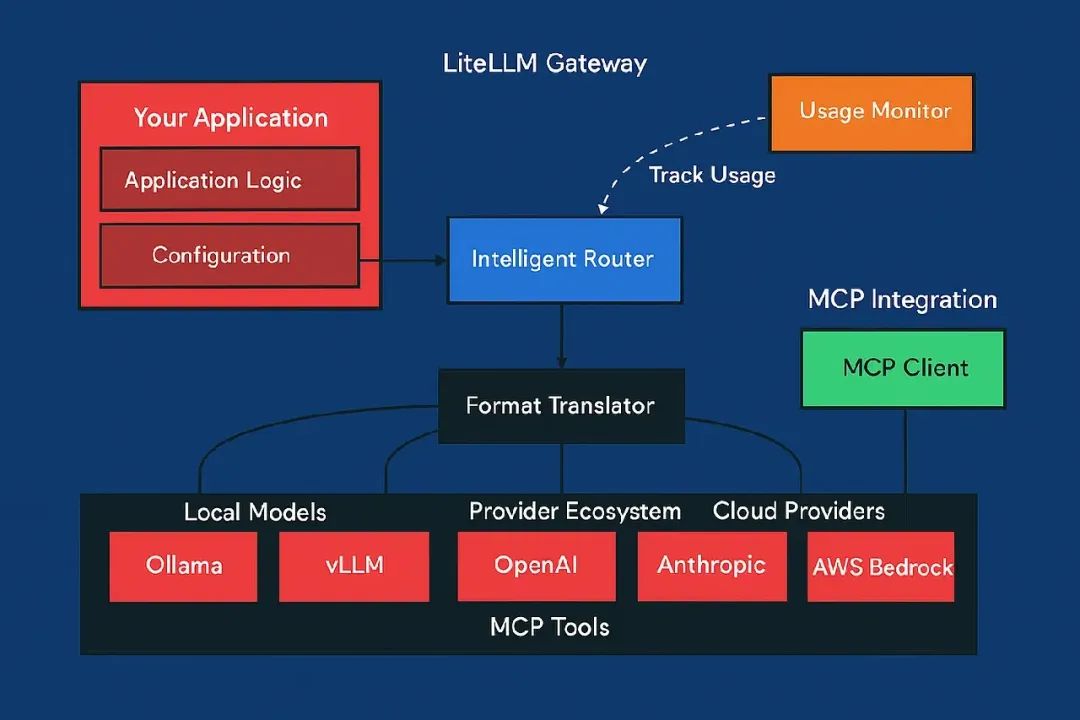
这个架构有几个关键好处:
-
• 单一整合点:你的应用只需要懂 LiteLLM 的接口。 -
• 提供商无关:切换或添加提供商不用改应用代码。 -
• 统一工具访问:MCP 工具在所有提供商上表现一致。 -
• 集中监控:跨所有提供商追踪使用量和成本。
高级模式
模式 1:提供商特定优化
# 为每个提供商定制参数
provider_configs = {
"gpt-4.1": {"temperature": 0.7, "max_tokens": 2000},
"claude-sonnet-4-0": {"temperature": 0.5, "max_tokens": 4000},
"ollama/mixtral": {"temperature": 0.8, "max_tokens": 1000}
}
model = select_best_model(query)
config = provider_configs.get(model, {})
response = await litellm.acompletion(
model=model,
messages=messages,
tools=tools,
**config # 提供商特定参数
)模式 2:成本与性能追踪
# LiteLLM 自动追踪成本
from litellm import completion_cost
response = await litellm.acompletion(
model=model,
messages=messages,
tools=tools
)
cost = completion_cost(completion_response=response)
print(f"这次请求成本:${cost:.4f}")模式 3:支持工具的流式处理
# 流式处理回复,同时支持工具
asyncfor chunk inawait litellm.acompletion(
model=model,
messages=messages,
tools=tools,
stream=True
):
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="")
# 实时处理流式工具调用
ifhasattr(chunk.choices[0].delta, "tool_calls"):
# 实时处理工具调用
pass快速上手
克隆示例仓库:
git clone git@github.com:RichardHightower/mcp_article1.git
cd mcp_article1安装 LiteLLM 和依赖(按 README.md 的说明):
poetry add litellm python-mcp-sdk配置你的提供商:
# .env 文件
OPENAI_API_KEY=your-key
ANTHROPIC_API_KEY=your-key
# 添加其他提供商的 key运行整合:
poetry run python src/litellm_integration.py核心收获
LiteLLM 和 MCP 的组合带来了 AI 工具整合的终极灵活性:
-
• 真·可移植:一次编写,适配任何 LLM 提供商。 -
• 成本优化:为每个查询选最经济的提供商。 -
• 风险规避:无厂商锁定,轻松切换提供商。 -
• 合规就绪:为不同数据敏感度选合适的模型。 -
• 面向未来:新提供商上线后,现有工具直接可用。
通过抽象工具层(MCP)和模型层(LiteLLM),你能打造适应需求变化的 AI 系统,连代码都不用改。这就是企业级的灵活性巅峰!
参考资料
-
• GitHub 仓库:MCP 文章示例 — 所有整合的完整代码 (https://github.com/RichardHightower/mcp_article1) -
• LiteLLM 文章: -
• LiteLLM Docs — 完整 API 参考 (https://docs.litellm.ai/) -
• MCP Specification — 协议细节 (https://modelcontextprotocol.io/introduction)

(文:PyTorch研习社)