

机器之心报道
今年的大模型已经「保底985、冲刺清北」了,明年还考吗?
果然,高考已经快被 AI 攻克了。
近日,5 款大模型参加了今年山东高考,按照传统的文理分科方式统计:豆包 Seed 1.6-Thinking 模型以 683 分的成绩拿下文科第一,Gemini 2.5 Pro 则凭借 655 分拔得理科头筹。
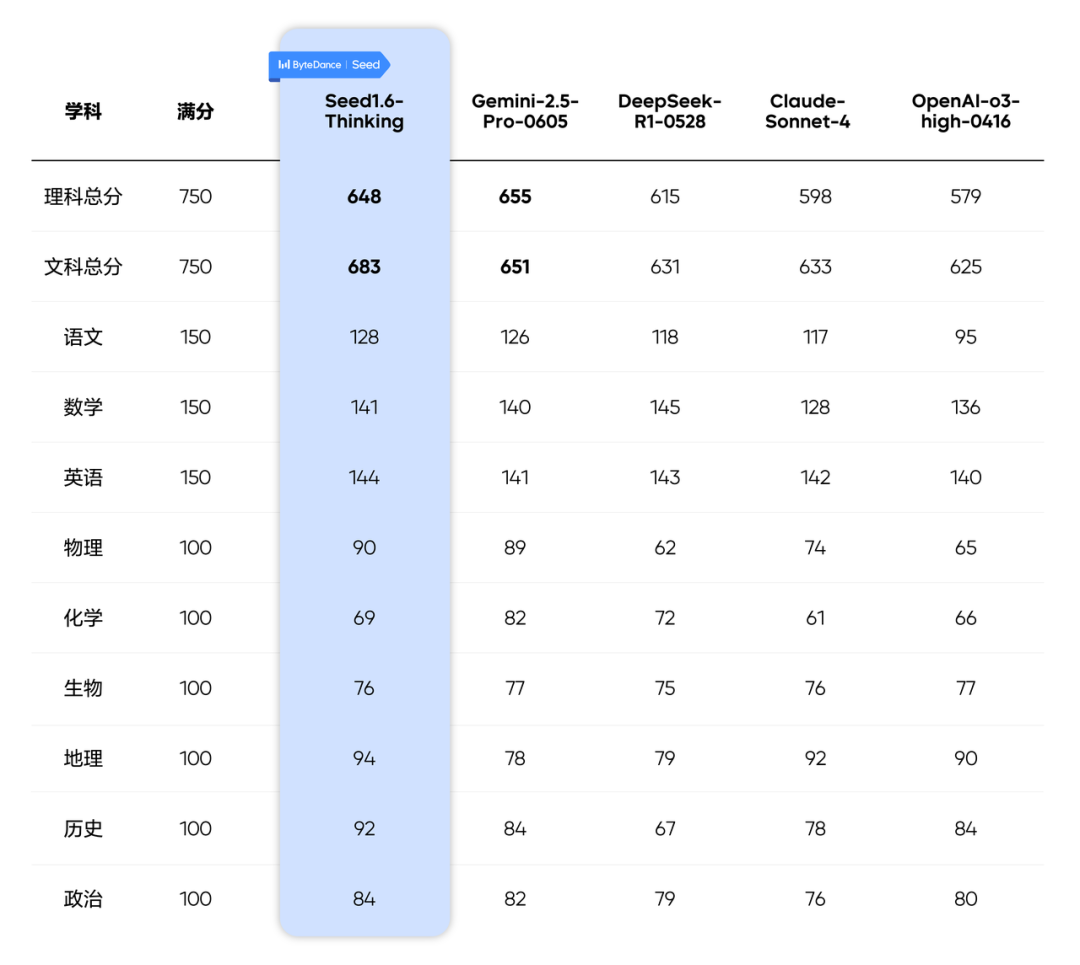
测评来自字节跳动 Seed 团队。他们集结了五款主流推理模型—— Seed 1.6-Thinking、DeepSeek-R1-0528,以及国外大模型 Gemini-2.5-Pro-0605、Claude-Sonnet-4、OpenAI-o3-high-0416,用 2025 年山东高考真题(主科全国 Ⅰ 卷 + 副科自主命题)进行全科闭卷测评,以高考 750 分制对 AI 的「应试能力」展开硬核比拼。
为确保评测的公平性,该团队通过 API 测试,并参考高考判卷标准。选择题和填空题由系统机判辅以人工质检、开放题由两位有联考判卷经验的重点高中老师进行匿名评估,并且后续引入了多轮质检。
测试全程未做任何 prompting engineering,所有输入均为高考原题,其中 DeepSeek R1 输入为题目文本,其余模型则是题目文本和题目截图。在总分计算上,采用 3(语数外)+3(理综 / 文综)的形式对 5 个模型进行排名。
从最终成绩单来看,这 5 家大模型的文科成绩均超 620 分,如果按照山东高考的赋分制,豆包的 683 分可以冲刺清华、北大;在理科方面,各大模型之间的分数差距则较为明显,Gemimi 和豆包已达到保底重点 985 的水准,而 Claude 4 和 o3 还不及 600 分。
去年高考全科测评中,大模型们还只能勉强踩到一本线,面对复杂的数学、物理题目时,虽然能产出答案,但思路浅显、推理链条不够严密,常常给人一种「全靠蒙」的感觉。然而短短一年过去,技术更新带来了质的飞跃,大模型展现出越来越强的逻辑推理和解决深度问题的能力。
语数英区分度较小,理科总分不及文科
在语、数、外等基础学科上,参评模型整体表现优异,均已达到顶尖考生水平,彼此间的区分度相对较小。不过,o3 模型因作文跑题导致语文单科得分偏低,拖累了其总分。
而在小副科上,虽然大模型在理科方面有了长足的进步,但仅从分数上来看仍不及文科。
接下来,我们根据该技术报告中提供的评分明细,详细解读一下各大模型的「考试」情况。
评分明细详见:https://bytedance.sg.larkoffice.com/sheets/QgoFs7RBjhnrUXtCBsYl0Jg2gmg
语文:得作文者得天下
在此次测评中,豆包以 128 分的成绩拿下语文单科第一,Gemini 以 2 分之差位列第二,DeepSeek 和 Claude 4 则分别凭借 118 分和 117 分排在第三和第四位,而 o3 则由于作文跑题以 95 分吊车尾。

整体来看,大模型在选择题和阅读理解题上表现优异,得分率普遍较高。这类题目本质上是对语言理解、信息抽取和基本逻辑推理能力的考查,而这正是当前大模型最擅长的领域。再加上许多分析题有一定「模板化」答案,大模型可以通过学习语料中的答题模式,形成较强的「套话生成」能力,比如「表达了作者的思乡之情」。
此外,大模型还非常擅长名句默写,5 款大模型全部拿到满分。大语言模型在预训练阶段接触了海量的古诗词、课本内容、考试题库等文本数据,早已「见过」并「记住」了这些常考句子,因此能够在提示下快速准确「召回」原文。
不过在作文任务中,大模型的表现参差不齐,满分 60 分,Gemini 能拿到 52 分,豆包拿到了 48 分,o3 却只得到 20 分。

o3 的高考作文
究其原因,我们发现大模型写作常停留在观点清晰、结构完整的「合格」层面,缺乏真正深入的问题思辨和有力的逻辑推进,比如 DeepSeek 写的作文虽然符合主题,也言之有理,但华丽词藻下没有精彩点,缺少温度和共情。
格式规范方面,目前还存在一些小问题,比如豆包洋洋洒洒写了 1800 字,超出了答题卡预留的书写区域,o3 使用了不属于考试规范内的作文格式,更像是模型根据主题进行分析的过程及总结。
数学:去年还不及格,今年竟能考 140+
深度思考能力让大模型的数学成绩突飞猛进,相比去年普遍不及格的状况,今年不少大模型能考到 140 分以上的高分,比如 DeepSeek R1、豆包、Gemini 就分别以 145、141、140 的分数位列前三。
这个结果与我们之前的测评比较接近,但并不完全一致,主要是解答题过程存在差别,这也说明大模型的回答存在一定随机性。
具体来看,DeepSeek 除了在第 6 题上失分(该题全员失分)外,其余表现都挑不出毛病;豆包和 Gemini 则是在压轴大题第三问上出了错;Claude 4 和 o3 在倒数第二题丢了分,但 Claude 4 额外在两道多选题上出现漏选,导致排名垫底。
其实,让大模型们集体翻车的新一卷第 6 题并不难,主要丢分原因在于这道题目带有方框、虚线、箭头、汉字等元素混合的图像信息,模型难以准确识别,这也表明大模型在图像识别和理解上仍有提升空间。
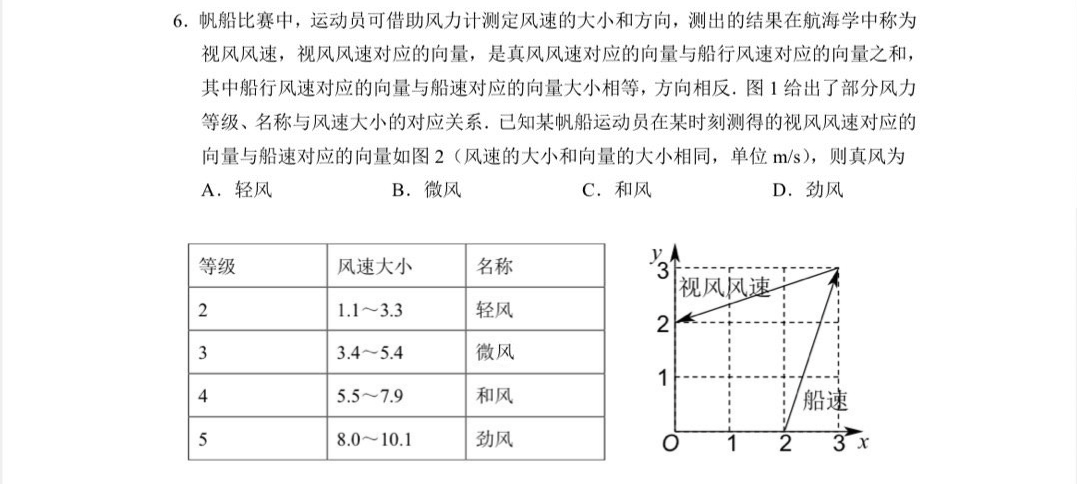
新一卷单选第 6 题
在难度最高的压轴大题上,众多模型无法一次性完美解答,容易出现漏掉证明过程、推导不严谨的扣分情况。
英语:全员超过 140,几乎拉不开差距
大模型做起英语卷子简直是得心应手,五家大模型全部上 140 分,除了 Gemini 在一道选择题上出错外,其他主要扣分点都集中在写作上。

上图是基于官方测评表格数据翻译和优化排版的图片。
有意思的是,Gemini 在分析过程中实际上已经识别出正确答案,但在后续推理中引入了无根据的假设,忽略了与上下文的关联性,造成了最终的错选。
至于作文题,满分 15 分,五家大模型的得分可分为两档。
豆包、Gemini 和 Claude 4 是「12 分档」,它们都完整回应了所有要求,结构清晰,语言流畅准确,内容上也都很充实。其中豆包提供了具体的接力赛例子,Gemini 给出了双版本方案,Claude 4 更是提出了「为不同水平学生提供平等机会」这样有深度的观点。
o3 和 DeepSeek 为「11 分档」。o3 虽然创意不错,将栏目描述得很有游戏化特色,但使用了「him」等不严谨的代词,影响了语言的准确性。DeepSeek 的主要问题是句式单一,重复使用「would」使得文章略显乏味,同时结尾格式也未完全遵照题目要求。
政史地强得可怕,理科读图题失分较多
高考文综一向以题量大、材料多著称,哪怕是人类考生,拿到高分也不容易。
在本次 2025 年山东文综卷挑战中,表现最出色的就是豆包,以 270 分的高分遥遥领先,尤其在地理(94)和历史(92)两个学科上,双双突破 90 分大关。这可能得益于豆包大模型在处理结构化资料和逻辑推演方面的优化,例如地理题中对空间关系和图文结合的理解,历史题中对因果链条和材料主旨的把握。
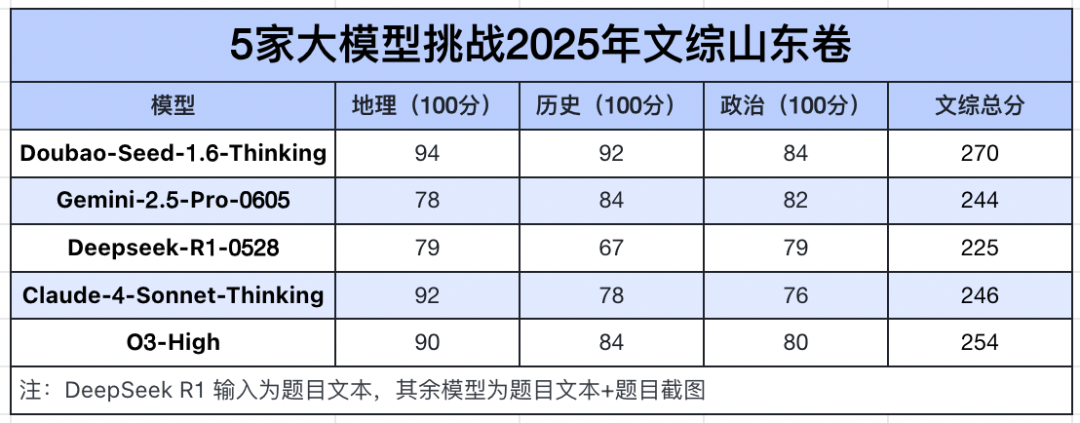
o3 各科得分较为均衡,虽略逊于豆包但无明显弱项,体现出其较高的整体调优水平。Claude 4 在地理上也拿下 92 分,表现亮眼,但政治分数最低,主要失分点在于回答分析题时教材观点关联不足。Gemini 与 Claude 4 总分接近,没有短板,但也缺乏突出的强项。
相比之下,DeepSeek 的成绩并不理想,文综总分仅 225 分,其中最拖后腿的就是历史,仅为 67 分,最大的失分点是第 18 题,由于出现模型故障,没有识别出材料,12 分全丢了。
与文科相较,大模型的理科总分并不算特别耀眼,和清北线有距离,是保底 985 的水平。Gemini 以 248 分的成绩位居榜首,比第二名豆包高出 13 分,比第三名 Claude 4 则高出了整整 37 分。
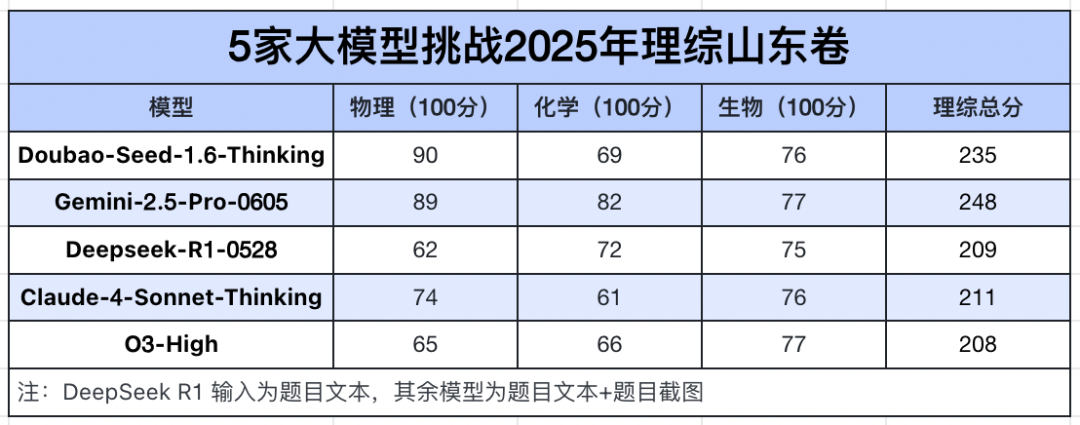
测试结果
当然,这也是因为生物、化学涉及较多读图题, 在测评时输入的图片比较模糊,在一定程度上限制了多模态模型的发挥,导致失分较多。
在获得更高清版本的高考试题图后,Seed 团队采用图文交织的方式,重新对生物和化学进行了推理测试,发现豆包在生化两科上的总分可再提升近 30 分,如此一来,理科总分就达到 676 分。这也说明,结合文本和图片进行全模态推理可以更大程度激发模型的潜力。

图文交织输入示例
此外,我们还发现在物理压轴题中,多个模型发生使用超纲知识解答的情况,但因为测试全程未做任何 prompting engineering,模型可能并不知道有解题方法限制。
一年提100多分,大模型何以从学渣变学霸?
去年,有科技媒体组织大模型参加了河南高考,文科最高成绩为 562 分,理科则为 469.5 分。短短一年时间,大模型在文理科成绩上均提高了 100 多分。
多款大模型之所以能在今年的山东高考中表现不凡,自然离不开其在推理能力和多模态处理方面持续不断的技术创新与深度优化。而这种技术演进,在 Gemini、OpenAI 系列模型和豆包等「考生」中体现得尤为明显。
今年 3 月,谷歌推出了 Gemini 2.5 Pro。它能在输出前通过思维链进行深度推理,显著提升数学、科学与代码推理水平,并在多项 benchmark 中取得领先成绩 。同时,它能够理解海量数据集,并处理来自不同信息源(包括文本、音频、图像、视频,甚至整个代码库)的复杂问题。
OpenAI 的 o3 是 OpenAI 最强大的推理模型,可以在响应之前进行更长时间的思考,并首次将图像融入其思维链中,通过使用工具转换用户上传的图像,使其能够进行裁剪、放大和旋转等简单的图像处理技术,更重要的是,这些功能是原生的,无需依赖单独的专用模型。这就意味着,模型在面对复杂数学、科学、编程任务时具备更像人类的分步思考能力,还能理解图像,可以在各种图文题和复杂题目场景下调动更全面感知与推演能力。
豆包大模型则在半个月前宣布了 1.6 系列的上新,Seed-1.6 模型采用了多模态能力融合的预训练策略,将其分为纯文本预训练、多模态混合持续训练(Multimodal Mixed Continual Training, MMCT)、长上下文持续训练(Long-context Continual Training, LongCT)三个阶段。
这不仅强化了文本理解,还引入了视觉模态,能对图表、图像等信息进行解析,提供更加全面的推理。而且它支持高达 256K 的上下文长度,可以处理更为复杂的问题。
基于高效预训练的 base 模型,团队在 Post-training 阶段研发了融合 VLM 各项能力、能通过更长思考过程实现极致推理效果的 Seed1.6-Thinking,也就是本次挑战高考山东卷的选手。
Seed1.6-Thinking 训练过程中采用了多阶段的 RFT 和 RL 迭代优化,每一轮 RL 以上一轮 RFT 为起点,在 RFT 候选的筛选上使用多维度的 reward model 选择最优回答。同时加大了高质量训练数据规模(包括 Math、Code、Puzzle 和 Non-reasoning 等数据),提升了模型在复杂问题上的思考长度,并且在模型能力维度上深度融合了 VLM,给模型带来清晰的视觉理解能力。
明年,我们还需要让大模型参加高考吗?
「AI 参加高考」已经成为了一年一度的热点话题。在图像识别、自然语言处理技术还不够强大的年代,「标准化考试」的确是检验 AI 技术进步的一种方式。
正因此,每一年的「AI 赶考」都会引发大众对 AI 能力边界、未来教育模式以及人类智能独特性的讨论。在这个过程中,大众讨论的核心逐渐从「能不能做题」转为「能做到什么程度」、「AI 能否理解深层含义和情感」等。
而这个周期性的议题在 2025 年迎来了里程碑式转折,大模型在文本理解和生成、多模态理解、推理层面都有了显著进步。AI 开始学会理解题目背后的深层逻辑和价值观,开始理解特定学科领域的图像信息,生成的答复也有了思想深度。
这种进步当然体现在了高考成绩上:从去年勉强过一本线,到 2025 年冲击清北、保底 985,大模型仅用一年时间就完成了从「普通本科」到「双一流」的蜕变。这让我们也意识到,高考这个曾经检验大模型「智力」水平的「试金石」,似乎变得不再具备挑战性。
明年,像 Gemini、豆包这些大模型或许没必要再做高考试卷,不妨告别标准化考试的框架,更深度地融入到科学研究、艺术创作、编程开发等真正创造「生产力」的领域,解决真实世界中那些没有标准答案的复杂难题,让人类少一些重复劳动。
我们有理由相信,在不久的将来,大模型会成为各个领域的行家里手。
©
(文:机器之心)