


近日北京大学联合华中科技大学、亚马逊公司发布了一项最新的研究成果:TCPA(Token Coordinated Prompt Attention for Visual Prompting),即一种即插即用的 token 协同提示注意力,通过为不同 token 动态匹配不同提示进行注意力交互,以 3% 的计算开销,提升高效微调方法对多样化鉴别性信息的提取能力。
本文的第一作者为北京大学硕士生刘子宸,本文的通讯作者为北京大学王选计算机研究所研究员、助理教授周嘉欢。
目前该研究已被人工智能顶会 ICML 2025 正式接收,相关代码已开源。

论文标题:
Token Coordinated Prompt Attention is Needed for Visual Prompting
论文链接:
https://arxiv.org/abs/2505.02406
代码链接:
https://github.com/zhoujiahuan1991/ICML2025-TCPA
接收会议:
ICML 2025 (CCF A类)
作者单位:
北京大学王选计算机研究所,华中科技大学人工智能与自动化学院,亚马逊公司
当前视觉提示学习在高效微调预训练视觉模型中展现出广泛潜力,但现有方法普遍忽视 token 间的功能差异,导致特征表达同质、判别能力受限。
针对这一问题,北京大学研究团队提出 Token Coordinated Prompt Attention(TCPA),通过引入差异化的提示交互机制,有效提升特征的多样性与表达能力。
作为一种即插即用的通用模块,TCPA 在多个主流测试基准上均取得了一致的性能提升,展现出出色的泛化能力与参数效率,为视觉提示学习提供了新的特征建模思路。

技术背景:视觉提示学习中统一提示机制限制模型表达能力
近年来,预训练-微调策略已成为深度学习的重要范式,推动了计算机视觉领域的发展。但随着模型和数据规模激增,该策略面临存储和计算成本高昂的挑战。
为此,视觉提示学习作为一种高效适配方法,通过在视觉 Transformer 中引入少量可学习提示,无需更新原模型参数,实现预训练模型在下游任务的高效迁移。
现有视觉提示方法主要有两类:一种是在输入层添加提示,引导模型关注关键区域;另一种是在 Transformer 各层引入提示 token,持续增强特征提取。
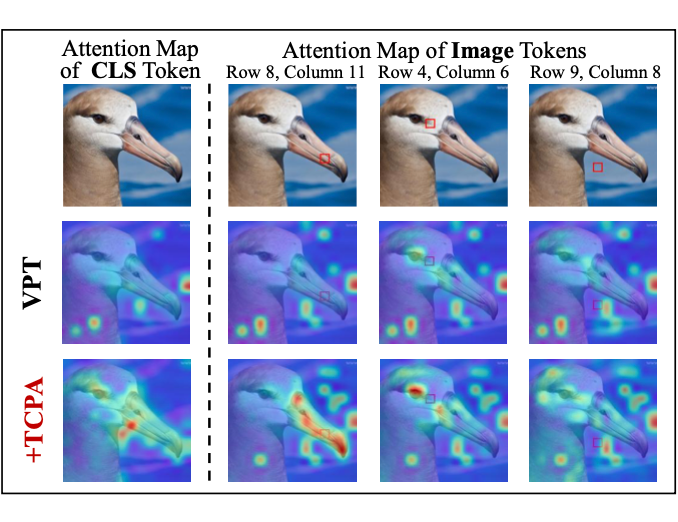
尽管成效显著,这些方法通常对所有 token 采用相同提示,忽视了 CLS token 与图像 token 功能及判别信息的差异,导致不同 token 关注的区域趋同,限制了视觉 Transformer 的表达能力。

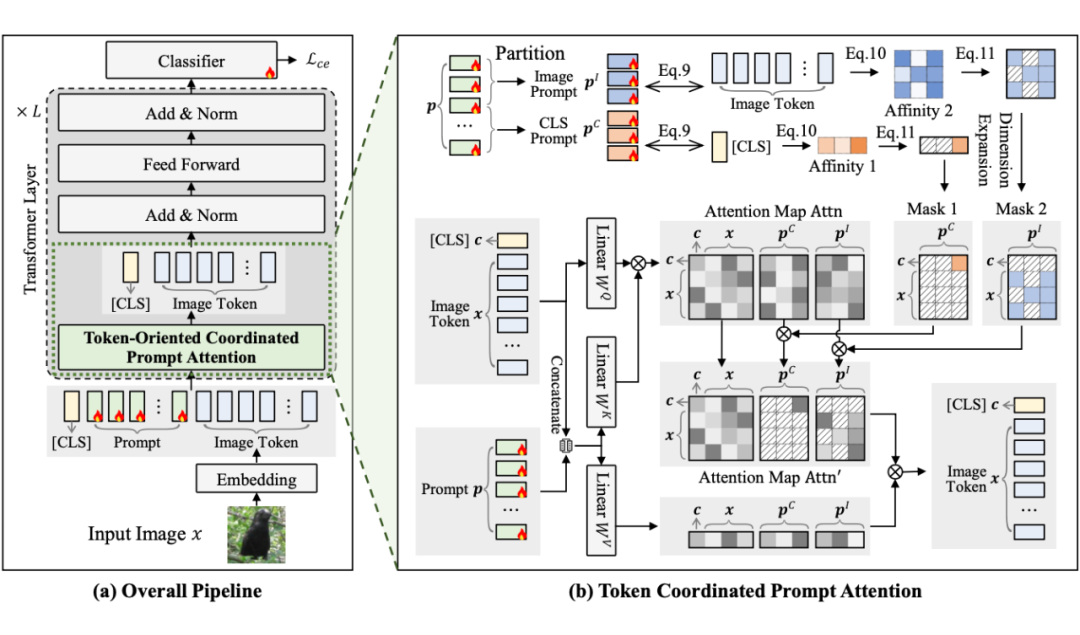
方法简介:Token协同提示注意力,促进多样化鉴别性信息提取
为解决上述问题,本文提出了一种即插即用的模块—— token 协同提示注意力(Token Coordinated Prompt Attention,TCPA)。
该模块为不同 token 分配具针对性的协同提示,实现更精细的基于注意力的交互,使每个提示都能在判别性与完整性信息的提取中发挥作用。
2.1 CLS和Image Token间的协同注意力
考虑到 CLS token 用于聚合全局信息,而图像 token 侧重于局部特征提取,我们设计了专门对应 CLS token 和图像 token 的 CLS 提示与图像提示,并在 Transformer 的注意力模块中分别与其独立交互,从而提升所提取特征的判别能力。
2.2 不同Image Token间的协同注意力
由于不同图像 token 对应的图像区域各异、所需提取的信息不同,我们进一步将 CLS 提示与图像提示分别扩展为 CLS 提示池和图像提示池,每个池中包含多个提示。系统可为每个 token 自动分配最合适的协同提示,进而提升特征中的判别信息多样性。

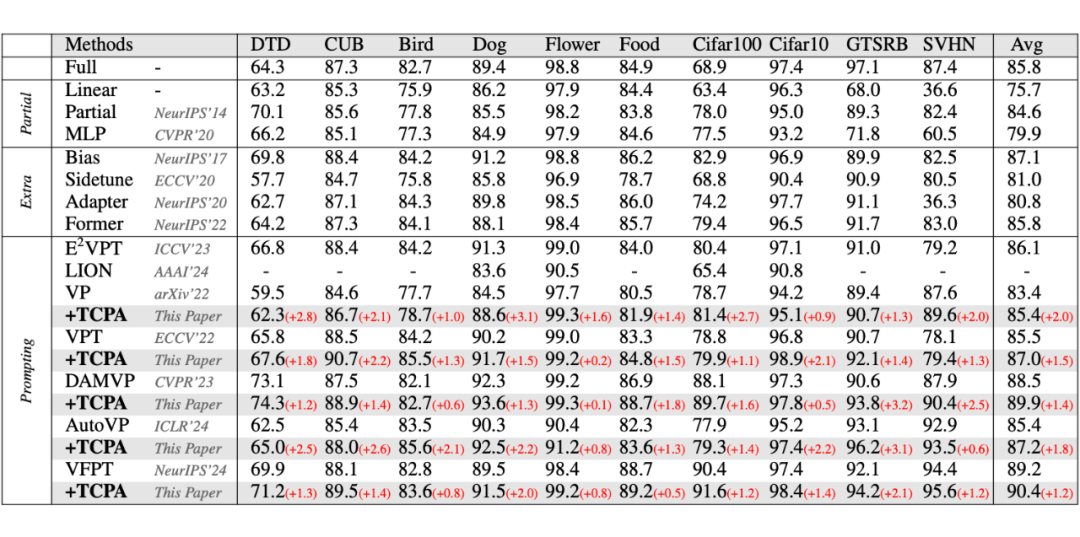
实验结果
在 HTA 测试基准上的结果显示,在引入 TCPA 后,DAMVP 在十个数据集上的整体平均性能提升了 1.4%。
类似的性能增益也在其他方法中得到验证:VP+TCPA 在十个数据集上提升 0.9%–2.8%,VPT+TCPA 提升0.2%–2.2%,AutoVP+TCPA 提升 0.6%–3.1%,VFPT+TCPA 也获得了 0.5%–2.0% 的性能提升。
这一效果主要得益于 TCPA 对 CLS token 与图像 token 在功能角色和注意力机制中差异的显式建模,使得提示的使用更加精细化,从而更充分地学习下游任务相关知识,并提升判别信息的提取能力,最终有效推动模型性能提升。

应用价值
本工作提出的 TCPA 具备以下几方面的重要应用价值:
-
轻量可插拔,部署友好:无需更改原有模型结构,能够灵活集成于主流视觉提示框架中,降低了实际部署成本;
-
资源友好,适合边缘设备:通过提升特征判别力、减少冗余交互,有效降低计算与存储开销,适合资源受限的设备与应用环境;
-
具备工程推广潜力:对已有提示方法进行增强,易于在工业界模型迁移与快速部署中落地实施。

未来展望
面向未来,TCPA 模块在以下几个方向具有广阔的研究与拓展空间:
-
拓展至多模态任务:可进一步应用于图文匹配、视觉问答等跨模态场景,增强不同模态间的语义对齐;
-
融合参数高效化技术:探索与 LoRA、提示压缩等技术的结合,在保证性能的同时进一步减小模型体积;
-
向通用视觉学习拓展:未来可将该机制推广至开放域识别与增量学习任务,推动视觉提示学习朝着更智能、更高效的方向发展。
(文:PaperWeekly)