


©PaperWeekly 原创· 作者 | 周展辉
单位 | 上海人工智能实验室
研究方向 | 语言模型对齐
TL;DR:我们在 ICML 2025 的工作(分数 544)发现,大语言模型在生成文本时并不只预测下一个词元—— 在生成首个词元前,其隐藏层已预先编码了完整回复的全局规划信息—— 包括结构特征(如全文长度)、核心内容(如故事主角是熊猫或狐狸)及行为特征(如答案可信度)。
通过探针技术,我们能提前「偷窥」这些隐藏信息,实现对模型输出的预判,为更精准的 AI 控制提供了新思路。

论文题目:
Emergent Response Planning in LLMs
论文链接:
https://arxiv.org/abs/2502.06258
大语言模型(LLM)的核心运行机制是「下一个词元预测」——模型在生成回复时,只能基于当前上下文预测紧接着的下一个词元,这限制了模型对完整输出形成全局概念的能力 [1][2]。
这一局限性在图 1 中得到直观印证:当要求当前性能顶尖的 GPT-o3-pro 模型回答”你的回复里有多少个单词?”
这一看似简单的问题时,由于模型无法预知最终生成的所有词元,即便启用了包含试错机制的思维模式,仍需“满头大汗”地思考 8 分 50 秒,最终仅生成包含 7 个单词的简短回复。
类似的,当命令模型“创作一个关于动物角色的科幻故事”时(图 2),在关键元素(如“狐狸”或“宇宙飞船”)被实际生成之前,其故事的最终走向始终高度不确定。
这种生成过程固有的不可预知性,使得人机交互如同“蒙眼下棋”——用户既难以预判模型的下一步输出,也难以实时调整交互策略。这正是当前提升大模型可靠性与可控性所面临的核心挑战。
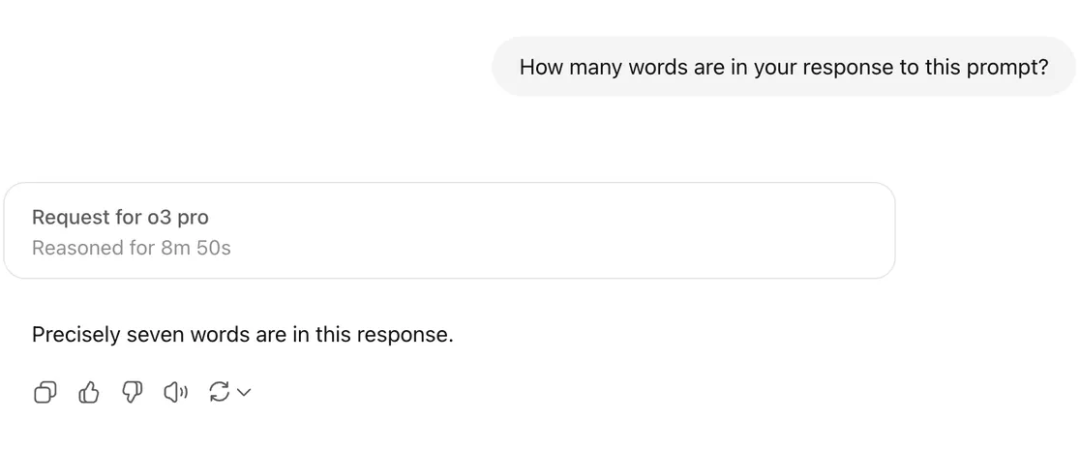
▲ 图1:让 GPT o3 pro 预测自己回复长度的结果——模型经过 8m50s 的漫长思考后,给出了一个包含七个单词的简短回复。
然而,模型是否可能并不“短视”——在逐词预测的表象下,模型是否其实“涌现”出了更深远的全局规划能力?
带着这一疑问,我们的研究首次运用探针(Probing)技术,系统揭示了大语言模型隐藏状态中的「前瞻规划」(Response Planning)现象——远在生成任何文本前,大语言模型的内部隐藏层表征就已编码了全局输出的各项信息,形成一幅关于未来输出的完整“蓝图”。
我们的实验证实,这种规划能力广泛存在于不同规模和类型的模型中,清晰地勾勒出三类全局信息:
1. 结构规划(Structure):预先决定回复的长度、推理步骤等框架性特征。
2. 内容决策(Content):提前锁定故事的核心角色(如“狐狸”)、多项选择题的最终答案等关键信息。
3. 行为特征(Behavior):内部评估生成内容的置信度、事实一致性等元认知属性。
这一发现为我们理解大模型生成机制提供了全新的视角:它并非只会“走一步看一步”的局部预测器,而是在动笔前就已“胸有成竹”的规划者。
这不仅为破解大模型的“黑箱”提供了关键线索,更预示着一种全新的控制范式:通过提前解析模型的前瞻规划,我们有望从「被动接收」转向「前瞻干预」,在模型生成前洞察其意图并施加影响,从而显著提升 AI 系统的可控性与可靠性。
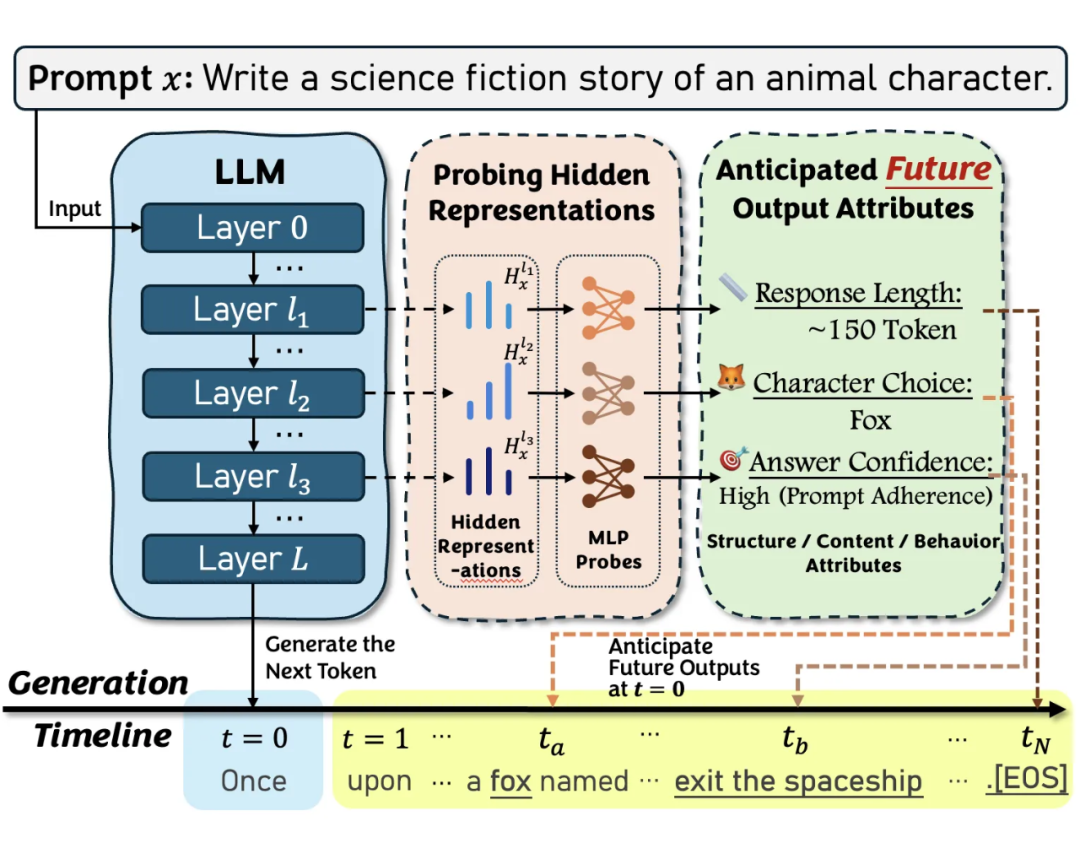
▲ 图2:大模型在生成文本前实际已通过隐藏层规划好故事框架,如角色(狐狸)、长度(150 词元)及置信度(符合科幻主题),揭示其超越局部预测的全局规划能力。

大语言模型的「前瞻规划」
1.1 如何检测大模型是否进行「前瞻规划」?
我们研究一个 层的大语言模型 ,该模型接收一个从分布 中采样得到的提示词 ,生成回复 。
在生成过程中,模型将输入 编码为逐层表示,并通过对最后一层表示进行投影,以贪心解码的方式生成下一个词元(token)。
我们的核心研究问题是:用于生成首个词元 的提示词表征(prompt representations),是否已包含了关于其后续完整回复 的「全局属性」(例如,回复长度)?
为验证此假设,我们形式上将一个用于概括回复属性的规则定义为 (例如,统计 中的词元数量)。
如果提示词表征确实编码了这些属性,那么我们应能训练一个探针 (probe)——例如,一个以 LLM 隐藏层为输入、用于分类或回归的小型神经网络(如 MLP)——直接从模型的隐藏表征中预测这些属性,而无需生成任何词元:
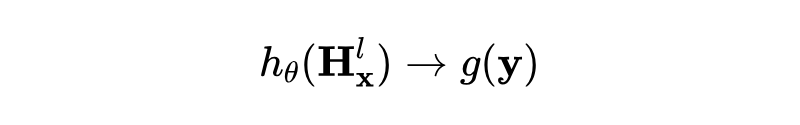
如果这种探测能够取得有效的预测结果,我们便可以得出结论:该大语言模型表现出了进行「前瞻规划」的能力。
1.2 检测「前瞻规划」的实验设计
为实现 1.1 节所述的检测目标,我们的实验设计包含两个核心模块:
探针任务设计:我们定义了一系列探针任务 。其中,提示词分布 用于引导模型生成具备特定全局属性的回复;属性提取规则 则负责定义并提取这些属性作为探针的预测目标。
数据收集与训练:针对每个任务,我们收集模型生成的回复,提取其对应的提示词表征 与全局属性 ,用以训练探针并评估其预测精度。
以下我们将详细介绍这两部分。
1.2.1 任务设计
我们研究的回复属性必须是全局性的(global),即该属性无法从首个生成词元中推断,而应由后续关键片段或整个回复共同决定。我们设计了六个任务,以探查涵盖结构、内容、行为三类不同维度的属性:
结构属性(Structure attributes)捕捉回复的宏观结构特征,包括:
-
回复长度预测(Response Length): 要求 LLM 遵循指令生成特定长度的文本(使用 Ultrachat 和 AlpacaEva 数据集)。探针的目标是预测最终的词元总数。
-
推理步骤预测(Reasoning Steps): 要求 LLM 以思维链(CoT)的形式解决数学问题(使用 GSM8K 和 MATH 数据集)。探针的目标是预测推理步骤的数量。
内容属性(Content attributes)追踪回复中(但非开头)出现的特定关键词:
-
角色选择预测(Character Choice): 要求 LLM 续写故事并包含一位动物角色(使用 TinyStories 和 ROCStories 数据集)。探针的目标是预测其选择的动物角色。
-
多项选择题答案预测(Multiple-Choice Answers): 要求 LLM 先分析问题,最后给出答案(使用 CommonsenseQA 和 SocialIQA 数据集)。探针的目标是预测其选择的选项。
行为属性(Behavior Attributes)评估模型回复的内在行为倾向,其验证需借助外部真实标签(ground-truth):
-
回答置信度预测(Answer Confidence):要求 LLM 回答高难度多选题(使用 MedMCQA 和 Arc-Challenge 数据集)。探针的目标是预测其答案的正确性。
-
事实一致性预测(Factual Consistency):要求 LLM 对一个符合事实/反事实的陈述表明立场(使用 CREAK 和 FEVER 数据集)。探针的目标是预测其立场是否与事实相符。
1.2.2 数据收集
对于每个探针任务 ,我们按以下步骤收集探针所需的数据集:
-
从提示词分布 中采样提示 。
-
存储其在模型中的隐藏层表征 。
-
使用贪心解码生成对应回复 。
-
根据规则 提取并存储探查目标 。
通过以上流程,我们便创建了一个包含提示词表征及其未来响应属性的数据集:。利用该数据集,我们便可以训练探针,以从模型表征中预测其未来的输出属性。
1.3 其他实验细节
探针训练:我们使用带有一个隐藏层的 MLP 作为探针,激活函数为 ReLU。隐藏层维度从集合 . 中选择。
对于回归任务,输出维度为 ;对于分类任务,输出层使用 Softmax,维度为类别数量。探针训练 个周期,回归任务使用 MSE 损失,分类任务使用交叉熵损失。数据集按 划分为训练、验证和测试集。
我们对 MLP 隐藏层维度 和作为探针输入的 LLM 表征层 进行网格搜索,并报告最优超参数下的测试集分数。所有结果均为三次随机种子实验的平均值。
评估指标:
-
回归任务:(包括回复长度、推理步骤)使用 Spearman、Kendall 和 Pearson 相关系数进行评估,它们分别衡量预测值与目标值之间的单调关系(Spearman, Kendall)和线性关系(Pearson);
-
分类任务:使用 Micro-F1 进行评估(在数值上等于 Accuracy)。具体包括:角色选择(4 分类)、多选题答案(5 分类),以及回答置信度和事实一致性(二分类)。
语言模型:我们测试了指令微调模型(Llama-2-7B-Chat, Llama-3-8B-Instruct, Mistral-7B-Instruct, Qwen2-7B-Instruct)及其对应的基础模型(Llama-2-7B, Llama-3-8B, Mistral-7B, Qwen2-7B)。

实验结果
1)同数据集与跨数据集实验:验证大模型的前瞻规划现象
我们的实验结果表明,大语言模型的隐藏表征中的确编码了关于未来回复的丰富全局信息,并且可以被有效探查以预测全局回复属性。
首先,我们在同一数据集内进行探针的训练和测试(图 3)(如分别在 CommonsenseQA 的 train/test split 上训练和测试),探针在不同模型和任务上均表现出远超基线的预测精度,证明其成功捕捉了模型的规划特征。
为验证探针捕捉到的规划特征是否具有任务通用性,而非仅限于特定数据集,我们进行了跨数据集泛化实验(图4)(例如,使用在 CommonsenseQA 上训练的探针,直接在 SocialIQA 数据集上测试)。
结果表明,探针在新的、未见过的数据集上依然显著优于随机基线,这说明探针捕捉到的模型规划特征是任务相关的、而非数据集特有的,具有良好的泛化性。
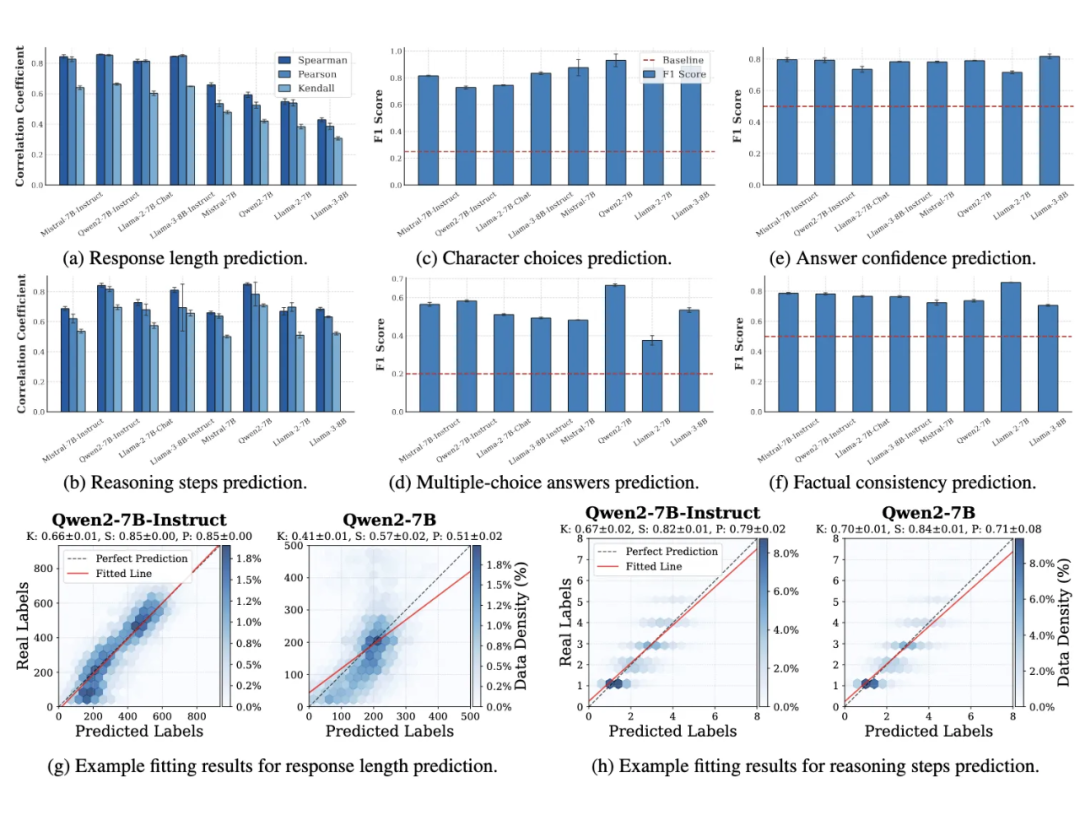
▲ 图3:同数据集探查(Probing)实验。探针在不同模型和任务上均表现出远超基线的预测精度,能够捕捉模型的规划特征。
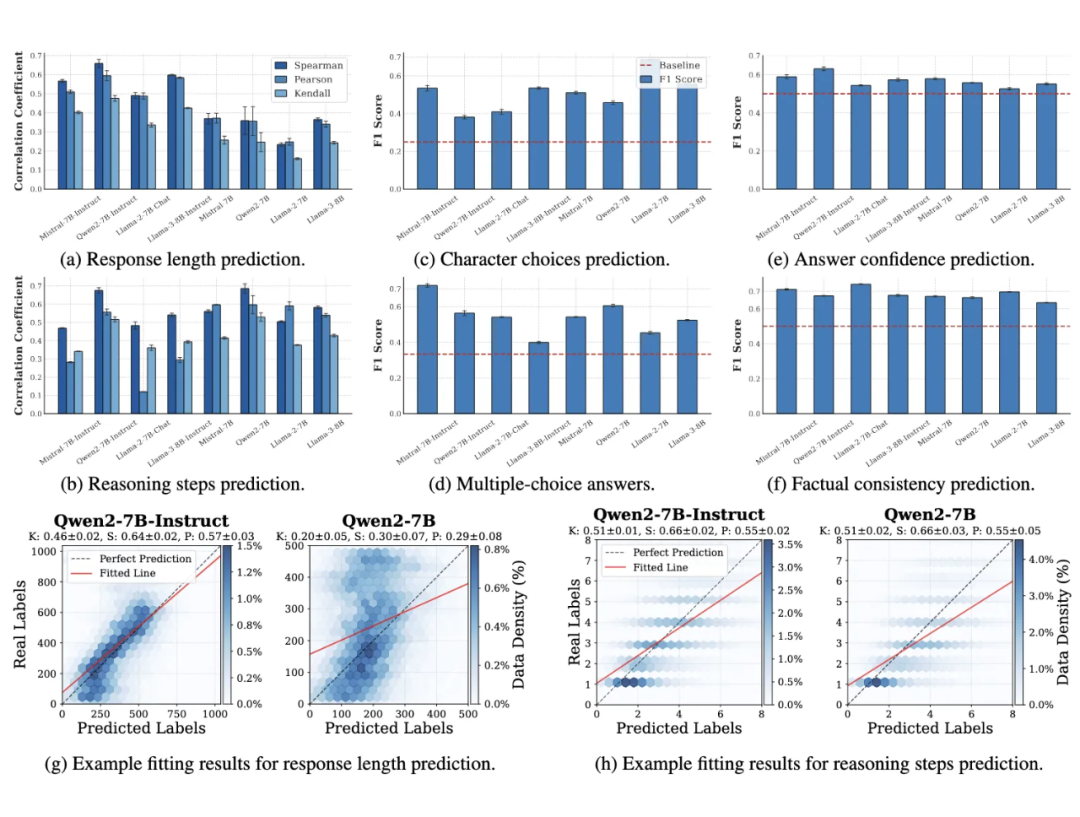
▲ 图4:跨数据集泛化实验。探针在新的、未见过的数据集上依然优于随机基线,说明探针捕捉到的模型规划特征是任务相关的、而非数据集特有的。
2)探针复杂度对预测性能的影响
我们进一步探究了探针复杂度(即 MLP 的隐藏层维度)对预测性能的影响(图5)。我们发现,对于所有任务,当隐藏层维度增加到一个相对较小的值(例如≤128)时,探针的性能便已饱和。
这表明回复规划是在模型表征中相对线性可读的显著特征,无需复杂的探针即可有效提取。
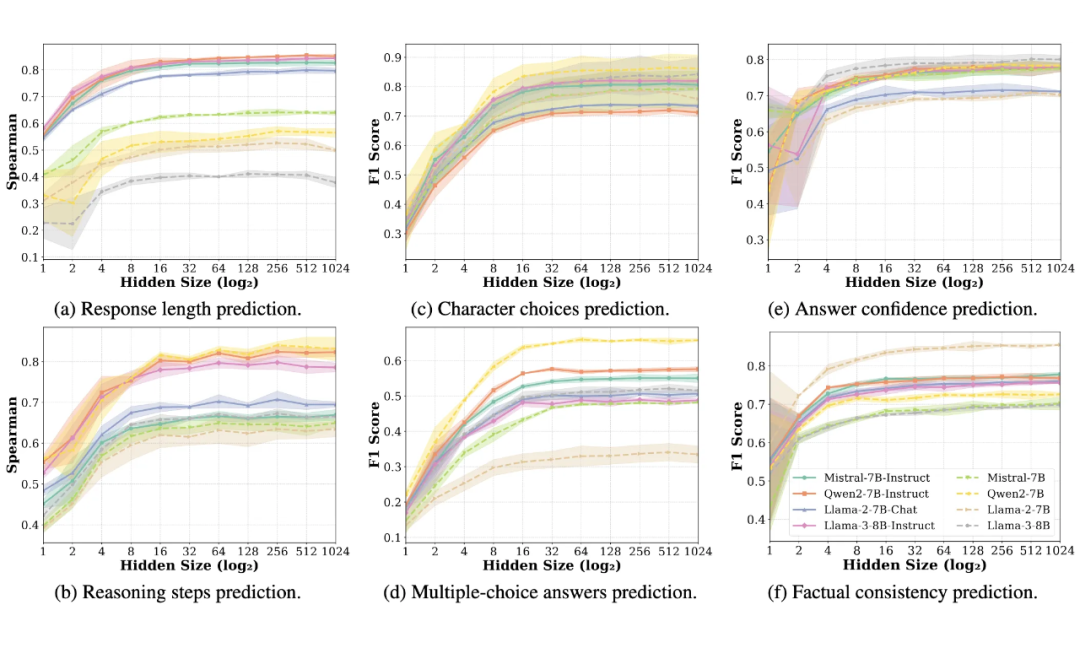
▲ 图5:探针复杂度(即 MLP 的隐藏层维度)对预测性能的影响。当隐藏层维度增加到一个相对较小的值(例如 ≤ 128)时,探针的性能便已饱和,表明回复规划是模型表征中的显著特征。
3)前瞻规划能力的 Scaling Law
我们还分析了规划能力如何随模型规模变化(Scaling Law,图6),实验表明,在同一模型族内,更大规模的模型展现出更强的规划能力;但这种趋势无法跨模型族泛化,暗示模型架构等其他因素也对规划能力有重要影响。

▲ 图6:规划能力的 Scaling Law。在同一模型族内,更大规模的模型展现出更强的规划能力。
4)探针预测与模型自身的“自我预测”能力的对比
我们也比较了探针预测与模型自身的“自我预测”能力(图7)(例如,针对 Ultrachat 数据集中的问题,直接提问模型它将用多少词元回答)。
我们发现,在各个任务上,通过探针解码出的规划信息都远比模型能明确表述出的更准确。这揭示了模型的“隐式规划”与其“显式自我认知”之间存在鸿沟:模型“知道”它要怎么做,但它不一定能准确地“说出”它要怎么做。
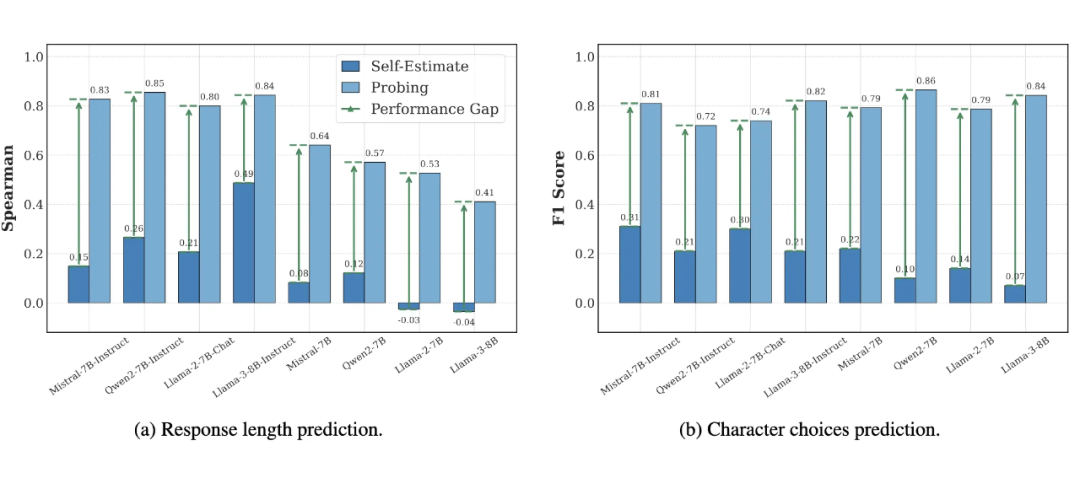
▲ 图7:探针预测与模型自身的“自我预测”能力的比较。在各个任务上,通过探针解码出的规划信息都远比模型表述出的更准确。

总结
我们揭示并系统性地研究了大型语言模型的“前瞻规划”能力。我们的实验证明,LLM 在生成前,其隐藏表征中就已编码了涵盖结构、内容和行为的全局“蓝图”。
这一发现挑战了将 LLM 视为纯粹“短视”的局部预测器的传统观点,为理解其内部机制提供了全新视角。
我们希望这项工作能启发更多后续研究,例如通过因果干预解析规划的内在机制、利用事前预测开发更高效的生成控制技术、在多模态等更广泛的场景中探索其通用性、设计显式引导模型感知前瞻规划的训练目标等等。
我们相信,对大语言模型内在规划能力的深入理解,将是通往更可控、更可靠人工智能的关键一步。

(文:PaperWeekly)