

南京大学博士生蒋俊鹏 投稿
量子位 | 公众号 QbitAI
在AI应用中,表格数据的重要性愈发凸显,广泛应用于金融、医疗健康、教育、推荐系统及科学研究领域。
深度神经网络(DNN)凭借其强大的表示学习能力,在表格数据建模上展现出令人瞩目的潜力。
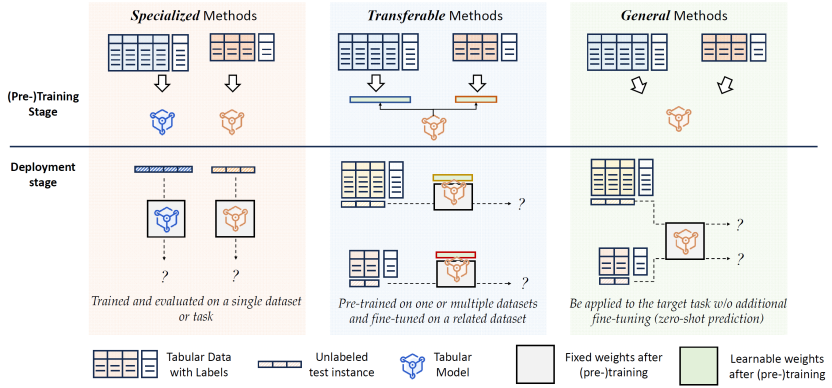
南京大学团队系统介绍了表格表示学习这一研究领域,他们将现有方法按泛化能力划分为三大类:专用模型(Specialized)、可迁移模型(Transferable)和通用模型(General)。
除此之外,他们还比较了DNN与传统方法——树模型的优劣,并剖析表格数据学习中的核心挑战,讨论了集成学习方法以及开放环境下的表格学习和多模态表格任务等扩展方向。同时,考虑到不同数据集之间方法表现差异显著,研究团队还探讨了数据集收集、评估与分析的系统策略,旨在建立跨数据集的稳健评估体系。

背景
表格数据本质上是一种结构化的信息表示方式,在组织与表达复杂数据关系方面具有天然优势。
此研究聚焦于有监督的表格机器学习任务,主要包括分类与回归两类常见问题。
除了结构化的组织形式外,表格数据通常还具有属性类型异质性,即包含数值型、类别型或混合型等多种数据类型,且这些数据可能是稠密的,也可能是稀疏的。此外,许多表格数据集在数据质量方面也面临诸多挑战,例如测量噪声、缺失值、异常值、数据不准确,以及隐私保护等问题,这些因素都会加大建模的复杂性。
最常见的有监督表格任务是分类和回归,其目标分别是学习从训练数据到离散目标或连续目标的映射关系。如图所示,每一行表示一个样本(及其对应的标签),每一列对应一个特定的属性或特征。理想情况下,模型学习得到的映射应具备良好的化能力,能够准确预测来自同一分布的新样本的输出结果。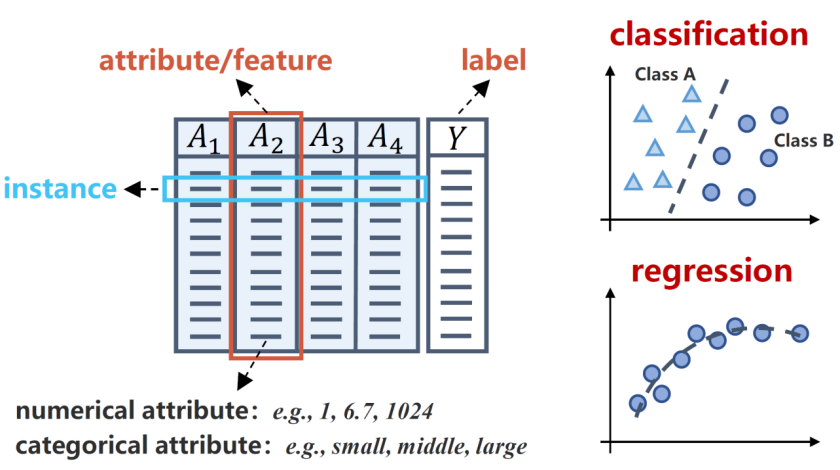
近年来,随着深度学习的迅猛发展,计算机视觉与自然语言处理等领域取得了突破性进展,深度神经网络(DNN)能够从原始输入中自动提取语义表征(representation),不仅提升了模型的泛化能力,还促进了跨任务的知识迁移。这种能够建模复杂特征交互关系、学习层次结构的能力,使得将深度学习方法应用于表格数据成为研究热点。
在十多年前,深度神经网络(DNN)就已被应用于表格数据的分类与回归任务,常见的架构包括堆叠式受限玻尔兹曼机和去噪自编码器等。早期的表征学习主要用于降维与数据可视化,尽管在探索特征表达方面有所突破,但整体泛化性能仍难以超越传统的树模型。
但是,随着神经网络结构设计、训练策略优化和表征能力增强,DNN 在表格数据相关应用中已取得显著进展,如点击率预测、异常检测、推荐系统与时间序列预测等。现代深度学习方法在多个方面的改进,推动了 DNN 在表格数据建模中的复兴,其性能已逐步接近甚至超过传统树模型。
方法
类似于深度学习的发展路径——从专用学习到迁移学习,最终演进为基础模型——团队将面向表格数据的深度学习方法划分为三类:专用方法(specialized methods)、可迁移方法(transferable methods) 和 通用方法(general methods)。这一分类不仅反映了深度学习技术的演化趋势,也体现了模型泛化能力的不断提升。
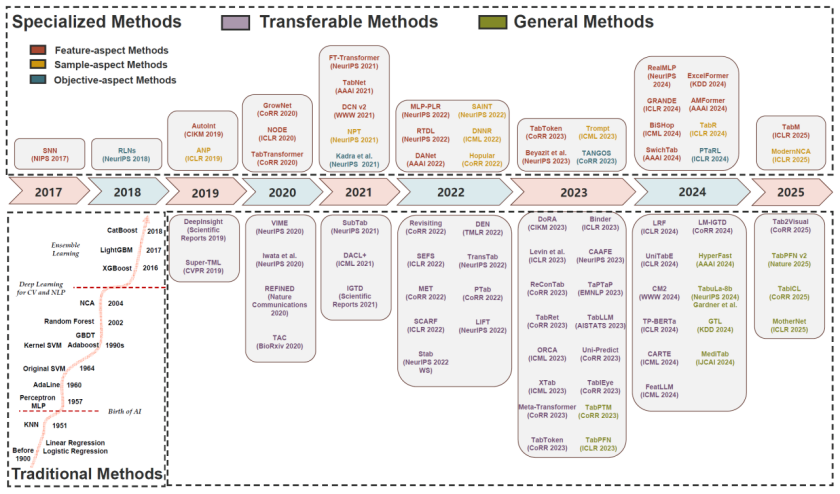
专用方法
专用方法是最早提出、使用最广泛的一类方法,团队也将从这一类开始展开介绍。表格数据由特征(列)、样本(行)以及任务目标(标签)构成,共同定义了数据的结构和建模目标。团队将围绕如何从特征层面和样本层面获得高质量表示展开讨论。具体来说,给定输入数据,并参考通用学习目标,重点考虑以下三个方面:
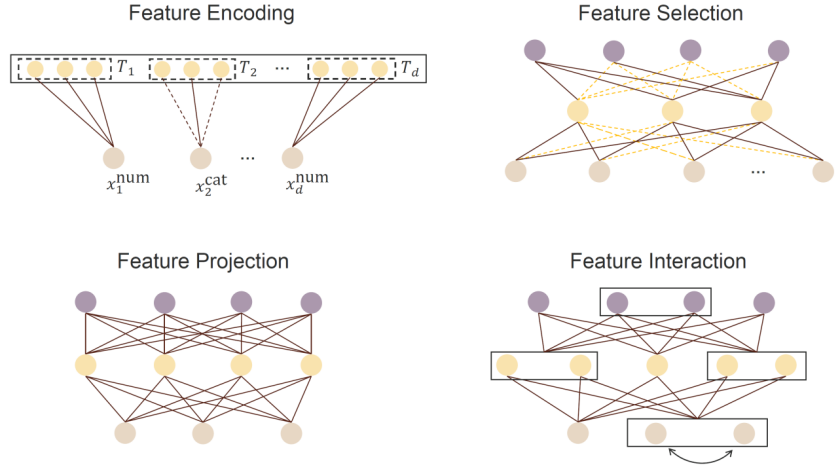
特征维度(Feature Aspect):关注如何将原始的表格输入(可为不同形式)转换为中间表示。我们将数值型特征与类别型特征作为两个基本维度,探索二者之间的关系建模(如特征重要性、特征交互),以增强模型对输入空间的理解。
样本维度(Sample Aspect):除了特征表示外,我们还研究如何检索并利用“邻近样本”,从而捕捉样本之间的关系,提升模型的预测能力。这一过程中,我们特别关注目标样本与其“抽取邻居”之间的相似性建模。
目标维度(Objective Aspect):讨论如何修改损失函数及整体优化目标,以引入合适的归纳偏置。通过引导模型向任务目标靠近,我们能够将先验知识或任务偏好融入到训练过程中,从而提升模型的泛化性与可解释性。
可迁移方法
与从零开始训练一个表格模型相比,基于预训练模型(Pre-Trained Model, PTM)进行学习,往往能够提升学习效率,并显著降低对算力资源和数据规模的依赖。例如,在房价预测任务中,若要训练一个面向某一区域的回归模型,直接利用来自相邻区域的一个已训练好的预测器,将有可能有效提升新模型的性能。这种“借力”的方式,能够在有限数据下加速模型收敛,并增强其泛化能力。
基于预训练模型(PTM)进行学习通常包含两个阶段:首先是在一个或多个上游任务上对表格模型进行预训练;其次是面对下游任务时,采用一定的适配策略将预训练模型迁移到目标任务,或辅助目标模型的学习。重用一个或多个预训练模型的核心挑战在于:如何有效地“桥接”预训练模型与目标任务之间的差异。
团队根据预训练模型的来源,将其分为三大类。
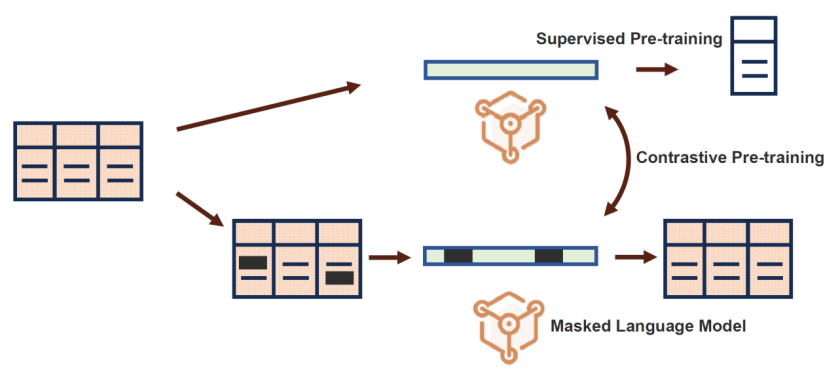
同构迁移的表格预训练模型(Homogeneous Transferable Tabular Model):首先,预训练模型可能来自与目标任务相同形式的任务,即特征维度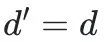 且类别数
且类别数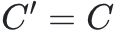 但数据分布
但数据分布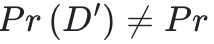 或模型结构不同。例如,预训练模型可能来自不同领域的监督学习任务,或来自无标签数据的自监督预训练。
或模型结构不同。例如,预训练模型可能来自不同领域的监督学习任务,或来自无标签数据的自监督预训练。
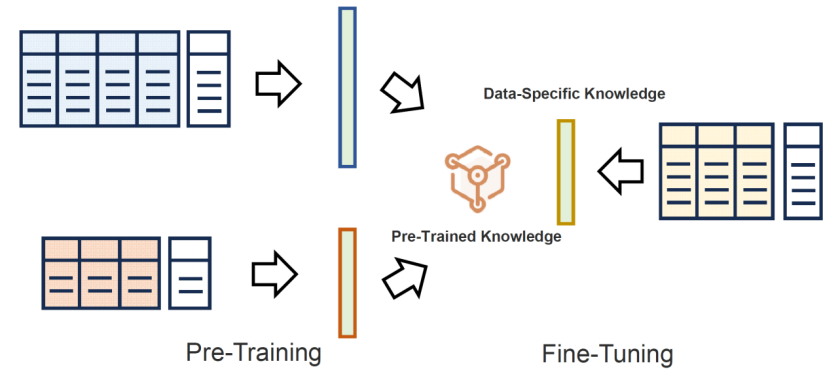
异构迁移的表格预训练模型(Heterogeneous Transferable Tabular Model):其次,我们考虑与目标任务存在轻微差异的预训练模型,即除了分布或模型结构的差异外,预训练模型在特征维度(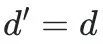 )或类别集合()上也与目标模型不同。因此,适配策略Adapt(.)需要具备处理这种异构性的能力。
)或类别集合()上也与目标模型不同。因此,适配策略Adapt(.)需要具备处理这种异构性的能力。
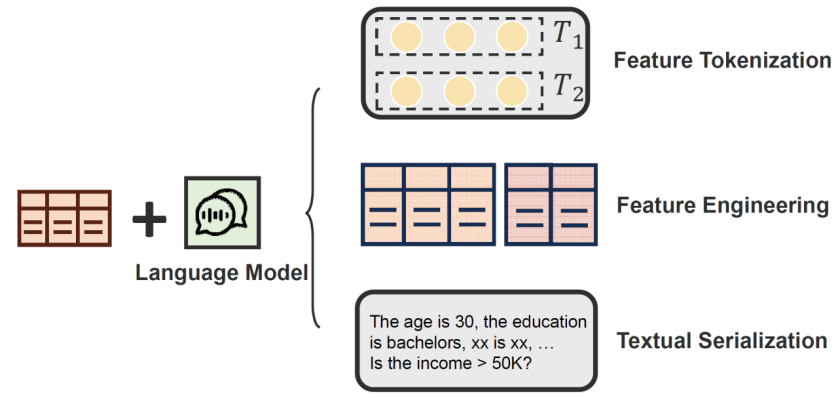
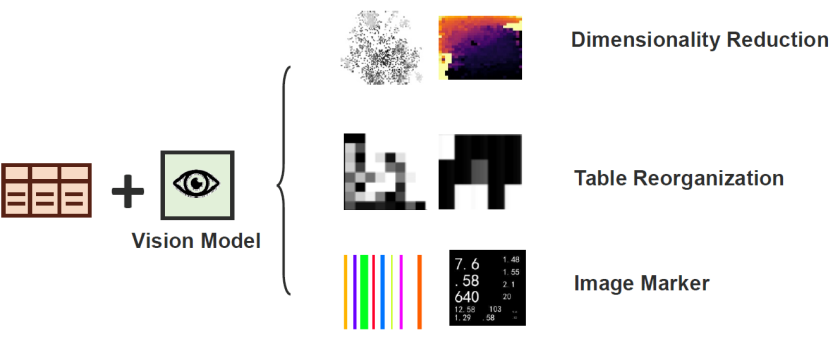
跨模态迁移的表格预训练模型(Cross-Modal Transferable Tabular Model):此外,预训练模型还可能来自其他模态的数据,比如视觉或语言领域。在大多数情况下,这类跨模态的预训练模型难以直接用于表格预测任务。因此,需要借助表格任务中的辅助信息(如属性名所携带的语义)来进行桥接。在这种情形下,大型语言模型等预训练模型可以通过理解属性语义,提供有价值的外部知识。
通用方法
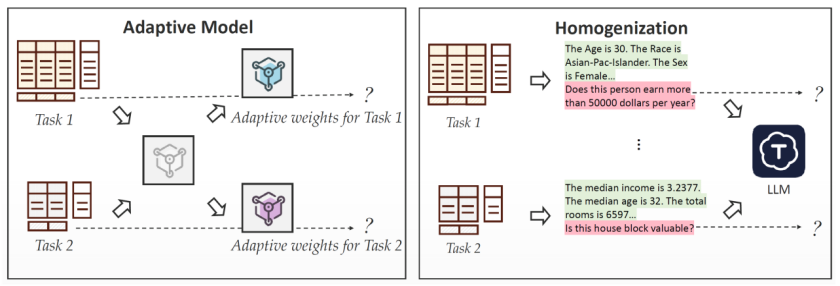
通用模型(也被称为“表格基础模型”)是在可迁移模型基础上的进一步发展。它将预训练表格模型的泛化能力扩展到了多种异构的下游表格任务中,无需额外的微调。换句话说,给定一个预训练模型,它可以直接应用于一个下游表格任务,对测试样本进行预测。
因此,通用模型在形式上类似于可迁移表格模型,但更强调其“零样本”能力(zero-shot),即无需任务适配即可处理各类异构数据集。为了实现这一目标,研究者致力于构建具有高度适应性的模型架构,能够同时应对不同特征空间和类别空间的数据。
一个显著的优势是,通用模型不再依赖适配函数,从而进一步降低了在不同任务中进行超参数调优的计算成本。其最终目标,是在多种下游表格数据集D上,相较于直接在D上训练模型或使用可迁移模型进行适配,获得更强的泛化性能。
预训练已经在视觉和语言等领域带来了巨大变革,但由于表格数据本身的高度异构性,这一范式在表格领域的应用仍然非常有限。表格数据集在维度数量(即列数)和每一列的语义含义上差异巨大,即便是在同一个应用场景下也如此。例如,不同的医疗数据集可能记录了患者信息的不同维度和细节;即使是相同位置的特征(如第D列),其含义也可能完全不同(比如“年龄”与“身高”)。
这与图像和文本数据形成了鲜明对比:在同一语言或格式下,不同来源的数据通常共享相同的“词汇”(如像素、图像块或子词),并且这些“词汇”之间的关系也具有一定相似性(如相邻像素往往具有相似颜色)。而在表格数据中,缺乏这种统一的词汇与结构关系,使得在多个数据集上联合训练一个模型变得困难,更不用说将一个预训练模型直接迁移到新的任务上了。
为了解决表格数据中固有的异构性,研究者提出了两大策略:一是提升模型对异构数据的适应能力,二是对表格数据进行格式的统一处理,从源头减少差异性。基于此,团队将当前通用表格模型的实现策略分为三类:
第一类是基于原始特征的建模方法,直接从表格的数值和类别特征出发;
第二类是以 TabPFN 为代表的基于上下文的方法,这一方向发展迅速,因此我们单独讨论;
第三类则是基于语义的信息,通过引入特征名称、任务类型等语义信息来统一异构任务的建模过程。
挑战与评估
挑战
与图像、文本等其他数据类型不同,表格数据因其独特的结构特征,在建模过程中面临诸多挑战。
特征异质性(Heterogeneity of Features)
表格数据通常同时包含数值型特征与类别型特征,而这两类特征在处理方式上存在显著差异。数值型特征往往具有不同的数值范围和分布特性,因此需要进行归一化或标准化处理。而类别型特征则涉及类别数量的多寡及其语义表示,需要采用如独热编码或嵌入向量等方式进行转换。因此,表格学习方法在设计时必须充分考虑这类混合特征的处理策略,以最大程度地保留每类特征的信息表达能力。
缺乏空间或序列结构(Lack of Spatial Relationships)
与图像中的像素位置或文本中的词序不同,表格数据的列顺序通常不具备空间或语义上的意义,因此表格数据在特征维度上具有排列不变性。此外,大多数表格学习任务都基于独立同分布(i.i.d.)的假设,即每一行样本之间是相互独立的,这进一步使得表格数据难以利用如时间序列或视频数据中所存在的时间或空间依赖性。这种缺乏内在结构的特点,使得传统深度学习架构(如卷积神经网络或递归神经网络)难以直接适用于表格数据建模。
低质量与缺失数据(Low-quality and Missing Data)
与图像或文本数据相比,后者往往因具有上下文或空间冗余而能较好地应对缺失或损坏的数据,表格数据对不完整或错误的记录则更加敏感。缺失值可能引入显著偏差,严重影响模型的预测效果;而噪声数据或错误数据则会降低模型的稳定性和可靠性。因此,数据预处理中的数据清洗和缺失值填补成为保障表格机器学习准确性和鲁棒性的关键步骤。
特征工程的重要性(Importance of Feature Engineering)
高效的表格模型在很大程度上依赖于输入特征的质量。与图像或文本数据不同,后者中的深度神经网络能够自动从原始数据中学习有用的特征表示,表格数据的方法往往需要依赖领域知识和精心设计的手工特征工程。识别和建模表格特征之间复杂的非线性交互关系通常需要借助复杂的特征变换和专业洞察,这对提升模型的预测性能起着决定性作用。
类别不平衡(Class Imbalance)
许多表格数据集中存在类别分布不均的问题,尤其是在分类任务中,某些类别样本数量远少于其他类别。类别不平衡会使模型倾向于预测多数类别,从而导致少数类别的识别性能下降。为应对这一挑战,常用方法包括过采样、欠采样,以及设计专门的损失函数(例如焦点损失)等。此外,采用AUC、F1分数等评价指标,有助于在不平衡数据环境下更公平地衡量模型表现。近年来的研究也指出,深度模型与传统模型在处理类别不平衡时存在差异,强调了在设计和评估时需要格外关注这一问题。
大规模数据集的可扩展性(Scalability to Large Datasets)
表格数据集可能达到大规模且高维的特点,这给计算效率和模型泛化能力带来了挑战。随着维度的增加,尤其当特征数量远超过样本数时,过拟合的风险也随之升高。因此,开发高效的训练算法、合理的内存管理策略以及充足的计算资源变得尤为重要。如何在保证泛化能力的前提下,有效扩展表格模型以应对海量数据,依然是一个重要且具有挑战性的研究方向。
模型选择与超参数调优(Model Selection and Hyperparameter Tuning)
表格模型对超参数设置非常敏感。选择合适的模型架构及调节学习率、网络层数、树的数量等超参数,往往需要大量计算资源和时间。尽管自动化机器学习(AutoML)技术不断进步,但在实际应用中,高效地找到深度表格模型的最优配置仍是一大难题,也是提升模型预测性能的关键环节。
特定领域的约束(Domain-Specific Constraints)
某些应用领域如医疗健康或金融领域对模型开发提出了额外的法规和伦理要求。例如,医疗领域需遵守隐私保护法规(如HIPAA),并向医生提供可解释的模型结果;金融领域则需满足公平性法规和行业标准。这些限制可能影响算法的选择,要求模型结果具备可解释性,并需额外进行验证、解释和审计,以确保合规和透明。
表现评估
团队对从传统到现代的表格方法进行了评估,旨在从多个角度提供全面的性能对比。针对某个模型在数据集上的表现,团队采用标准指标来衡量预测标签与真实标签之间的差异。
单任务评估
在分类任务中,准确率(Accuracy)或错误率(Error Rate)是最常用的主要指标。针对标签分布不平衡的问题,还会使用AUC和F1分数进行补充评估;期望校准误差(ECE)用于计算预测概率的加权平均误差。除了错误率和ECE指标外,其他指标数值越高越好。
在回归任务中,常见指标包括均方误差(MSE)、平均绝对误差(MAE)和均方根误差(RMSE),其中MAE和RMSE与原始标签尺度相同,数值越低代表性能越优。此外,决定系数(R²)也被广泛采用,数值越高表示拟合效果越好。
由于表格机器学习涉及的数据集种类繁多,任何单一模型难以在所有场景中都表现优异。因此,模型评估不仅需考察其在单个数据集上的表现,还需结合多数据集的综合指标来反映模型的整体效能。
多任务评估
早期研究中,多数据集模型性能评估主要依赖于“平均排名”(Average Rank,又称Friedman Rank)方法,常结合“临界差异比较”(Critical Difference Comparisons)一起使用。具体做法是针对每个数据集,基于某一指标(如准确率、AUC、RMSE)对模型进行排序,随后计算各模型在所有数据集上的平均排名。为了保证结果的统计稳健性,还会通过假设检验判断排名差异是否显著,常用的多重比较检验包括Wilcoxon-Holm检验、Friedman检验和Nemenyi检验等。针对平均排名可能因部分数据集上表现不佳而下降的问题,引入了“达到最高准确率的概率”(PAMA),即模型在多少比例的数据集上取得了最高准确率。此外,还有“P95”指标,用于衡量模型在多少比例的数据集上达到了最高准确率的95%以上,考虑了接近最优的情况。
随着研究的深入,更多多样化的评估指标被提出。算术平均(Arithmetic Mean)指标直接对各数据集的性能进行平均,但由于不同数据集的指标尺度差异,容易导致结果失真。为此,通常会对性能指标进行归一化处理,如分类任务中的归一化准确率、回归任务中的归一化RMSE(nRMSE)。有时会使用“平均归一化误差”(Mean Normalized Error),但其对归一化方法的依赖可能限制了独立优化。为克服这些缺陷,提出了“移位几何均值”(Shifted Geometric Mean, SGM)误差,该方法通过乘法方式汇总误差,降低极端值的影响,使跨数据集或数据划分的比较更加稳定。
除了绝对性能,模型之间的相对比较同样重要。相对提升(Relative Improvement)指标量化了某模型相较于基线(例如简单的多层感知机MLP)的性能增益,体现了相对效率。近年来,受ELO评分系统启发,提出了基于ELO的评估方法,将模型间的对比视为跨数据集的成对竞赛。ELO评分通过迭代调整排名,动态反映模型间的相对表现,提供了更细粒度和动态的评价。
基准评测: benchmark和数据集
一个全面的基准应涵盖多样化的数据集,以测试模型在不同任务类型和特征类型上的泛化能力。基准数据集应包括二分类、多分类和回归任务等多种类型。例如,Delgado 等人评估了179个分类器,涵盖17个模型家族,测试了121个数据集,结论显示随机森林及其变体总体表现最为优异。Kadra 等人研究了基于参数化技术的多层感知机(MLPs),如集成和数据增强,在40个分类数据集上的效果。同样,Gorishniy 等人展示了MLPs、ResNet和基于Transformer的模型在11个数据集上的有效性。Grinsztajn 等人则在45个数据集上对比了树模型和深度神经网络(DNN)方法,深入探讨了两类方法的差异。
基准测试应涵盖不同规模的数据集,包括样本量和特征数量较大的数据集以及较小规模的数据集。数据集规模的多样性有助于评估不同模型的扩展性和效率。McElfresh 等人在176个分类数据集上评估了19种方法,其中包括8种传统方法和11种深度学习方法。研究结果表明,预训练的TabPFN模型在平均表现上领先,即使其训练集仅随机采样了3000个样本。然而,由于超参数调优次数有限以及严格的时间限制,该研究中的某些深度表格方法的评估可能未能达到最佳效果。
为了保证评测的稳健性和泛化能力,基准中应包含来自多个领域的数据集。常见的表格数据领域包括医疗、生命科学、金融、教育和物理学等。此外,一些数据集来源于其他领域(如图像或语音),通过特征提取得到表格形式的数据。Attention-and-contrastive-benchmark 在28个表格数据集上评估了注意力机制和对比学习方法,并将其与传统深度学习和机器学习方法进行了比较。Ye 等人则重点研究基于深度神经网络(DNN)的模型,使用覆盖超过300个数据集的基准,涵盖多种任务类型、规模和领域。更丰富的数据集集合使我们能够更全面地评估某种表格方法在不同应用场景中的泛化能力。
带语义的benchmark
近来的研究也开始关注带有丰富语义信息的表格数据评估,例如结合任务相关的元信息或整合属性名称。UniTabE 提供了一个规模达7TB、包含130亿条表格样本的大规模预训练数据集,涵盖投资、时间序列分析、金融、经济等领域,数据类型包括数值型、类别型及文本数据。CM2 提出了用于跨表预训练的OpenTabs数据集,收录了大量带有列名语义的大规模表格,约包含4600万个样本。TP-BERTa 从OpenTabs中筛选出样本数不少于1万且特征数不超过32的数据集,构建了101个二分类数据集和101个回归数据集,共约1000万个样本。GTL 从Kaggle整理了384个公开表格数据集,包括176个分类任务和208个回归任务,涵盖众多工业领域。TabLib 收集了6.27亿个表格,总数据量69TiB,并包含8670亿个上下文令牌,数据来源涵盖CSV、HTML、SQLite、PDF、Excel等多种文件格式,主要来自GitHub和Common Crawl。T4(The Tremendous TabLib Trawl)针对TabLib中的隐私敏感数据进行了过滤,最终筛选出420万个表格,包含21亿行数据。
上述基准和数据集中,带语义的数据集主要用于表格大语言模型(LLMs)的预训练,而其他数据集则更多用于传统方法的评估。此外,已有多个工具箱实现了针对表格数据的模型方法,涵盖传统方法和深度表格方法。要构建一个全面的表格数据基准评测,需要考虑数据集的多样性和数据质量等多方面因素。
模型评估
鉴于表格方法对数据的高度敏感性以及深度方法本身存在的额外随机性,进行稳健的评估显得尤为重要。同时,由于部分方法计算代价较高,确保评估效率同样不可忽视。
模型选择
模型选择通常在验证集上进行,包含超参数调优和提前停止两部分,这对于确保评估的可靠性至关重要。鉴于深度方法中超参数众多,自动化搜索工具如Optuna被广泛采用,通过多次试验探索最优超参数。在调优过程中,模型在验证集上进行评估,同时也会使用多个随机种子重复训练,以获得更为可靠的结果。每次试验及最终训练中,通常采用提前停止策略防止过拟合,并以验证集表现最优的训练轮次作为最终模型。
性能评估
为评估模型的泛化能力并防止过拟合,常采用独立的训练/验证/测试集划分,典型比例为64%/16%/20%。但固定划分可能导致结果不稳定。随着深度学习的发展,研究者提出了更稳健的评估协议,以更真实反映模型性能。主要有两种方式:(1)固定数据划分,采用不同随机种子多次训练并评估(2)采用交叉验证,每个fold重新生成训练/验证/测试划分。此外,也有结合两者的混合策略。
近期研究表明,基于固定验证集的超参数调优不够稳定,易导致对验证集过拟合发现其在大多数TabZilla数据集上效果不佳,转而采用5折交叉验证实现更稳健的超参数选择。由此,Ye等人进一步指出部分元特征对模型性能影响更大。对于小规模数据集,已有多种替代评估策略,但这显著降低了超参数搜索的效率。Nagler等人指出,仅仅通过重新打乱数据划分即可提升泛化性能,使得基于holdout的模型选择在保持较高计算效率的同时,也能与交叉验证竞争。
论文链接:https://arxiv.org/abs/2504.16109
代码链接:https://github.com/LAMDA-Tabular/Tabular-Survey
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)