

编辑:Panda
今天,Gemini 家族迎来了一个新成员:Gemini Robotics On-Device。

这是谷歌 DeepMind 首个可以直接部署在机器人上的视觉-语言-动作(VLA)模型,可以帮助机器人更快、更高效地适应新任务和环境,同时无需持续的互联网连接。
从名字也能看出来,Gemini Robotics On-Device 属于 Gemini Robotics 系列。该模型于今年三月发布,基础模型是具备多模态推理能力的 Gemini 2.0。
据介绍,Gemini Robotics On-Device 展现出了强大的通用灵活性和任务泛化能力,并且经过优化,可在机器人机体上高效运行。
由于该模型无需数据网络即可运行,因此它对延迟敏感型应用非常有用,可确保在连接中断或零连接的环境中保持稳健性。
对此,网友自然是好评多多:
对于开发者,谷歌还将发布 Gemini Robotics SDK,可用于轻松评估 Gemini Robotics On-Device 在其任务和环境中的表现。另外,开发者还可使用该 SDK 在 DeepMind 的 MuJoCo 物理模拟器中测试该模型,并快速将其适应到新领域 —— 只需 50 到 100 个演示即可。
顺带一提,加州大学伯克利分校、谷歌 DeepMind、多伦多大学、剑桥大学联合推出的 MuJoCo Playground 刚刚获得了今年的机器人科学与系统会议(RSS 2025)杰出演示论文奖。

-
论文标题:Demonstrating MuJoCo Playground
-
论文地址:https://www.roboticsproceedings.org/rss21/p020.pdf
模型功能和性能
Gemini Robotics On-Device 是用于双臂机器人的基础模型,其设计目标是最大限度地减少计算资源需求。它基于 Gemini Robotics 的任务泛化和灵活性能力,并且:
-
针对快速运行灵巧操作实验而设计。
-
可通过微调来提升性能,从而适应新任务。
-
经过优化,可在本地运行并实现低延迟推理。
DeepMind 进行了不少视觉、语义和行为泛化能力实验,整体来看,Gemini Robotics On-Device 在这些广泛的测试场景中表现强大:能够遵循自然语言指令,并完成诸如拉开袋子拉链或折叠衣服等高度灵巧的任务 —— 所有这些操作均可直接在机器人上运行完成。
即使是本地运行的 On-Device 模式,Gemini Robotics On-Device 也表现出了相当不俗的泛化性能。
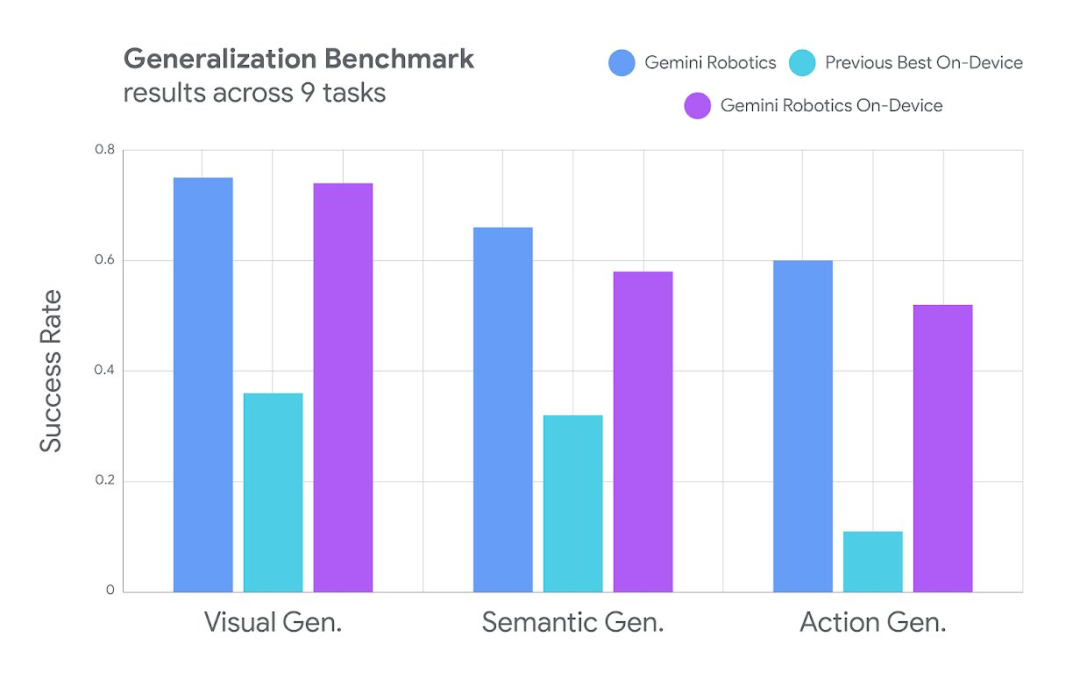
可以看到,相比之前最佳的本地端机器人模型,Gemini Robotics On-Device 的优势非常明显。
在更具挑战性的分布外任务和复杂的多步骤指令方面,Gemini Robotics On-Device 也优于其他本地端方案。
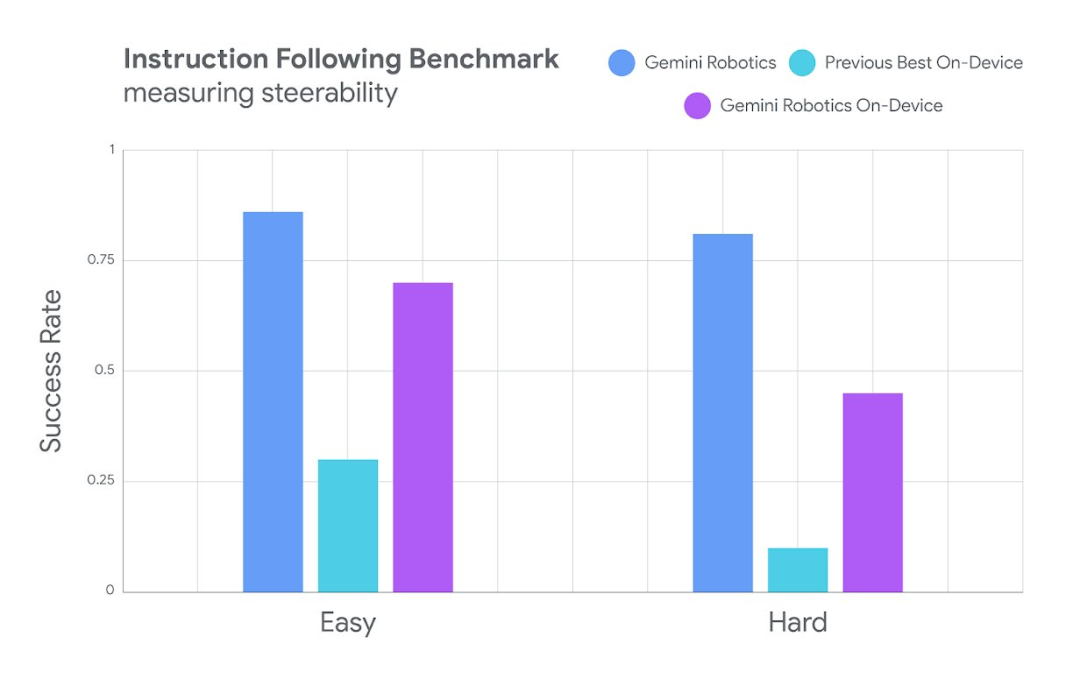
当然,如果开发者无需严格要求在本地运行模型,也可以使用 Gemini Robotics 模型。对该模型我们就不过多赘述了,详情可参阅技术报告:
https://arxiv.org/pdf/2503.20020
可适应新任务,可跨具身泛化
Gemini Robotics On-Device 也是 DeepMind 推出的首个可供微调的 VLA 模型。虽然许多任务可以开箱即用,但开发者也可以选择调整该模型,从而获得更佳性能。
该模型只需 50 到 100 个演示即可快速适应新任务,这表明该模型能够将其基础知识泛化到新任务。
DeepMind 在七项不同难度的灵巧操作任务上测试了该模型,包括拉开午餐盒拉链、画卡片和倒沙拉酱。
下图展示了 Gemini Robotics On-Device 模型的任务适应性能,其中使用的示例少于 100 个。
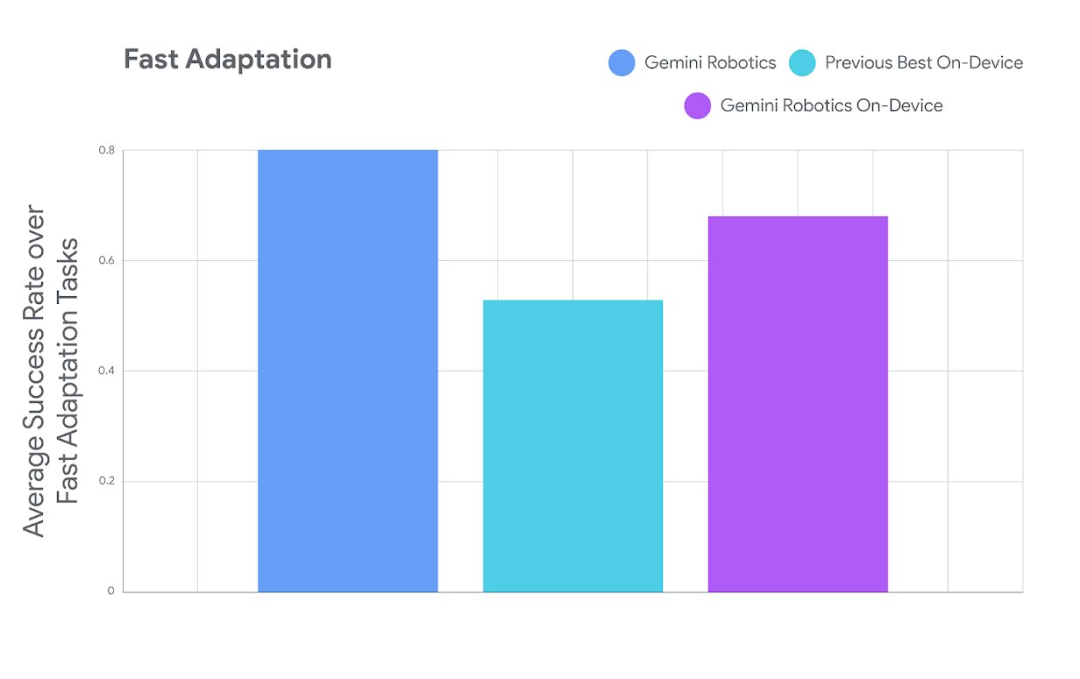
他们还研究了让 Gemini Robotics On-Device 模型适应不同的机器人。训练时,他们采用的是 ALOHA 机器人,但实验表明能够进一步将其调整用于双臂 Franka FR3 机器人和 Apptronik 的 Apollo 人形机器人。
在双臂机器人 Franka 上,该模型可以执行通用指令,包括处理之前未见过的物体和场景、完成诸如折叠连衣裙之类的灵巧任务,或执行需要精准度和灵活性的工业皮带装配任务。
Apollo 人形机器人则是完全不同的机器人形态,而该模型也能相当好的适应。同一个通用模型可以遵循自然语言指令,并以通用方式操控不同的物体,包括之前未见过的物体。
DeepMind 表示:「Gemini Robotics On-Device 标志着在使强大的机器人模型更易于获得和适应方面迈出了一步。」
看起来,我们离真正的具身智能时代又更近了一步。
Gemini 模型的其它更新
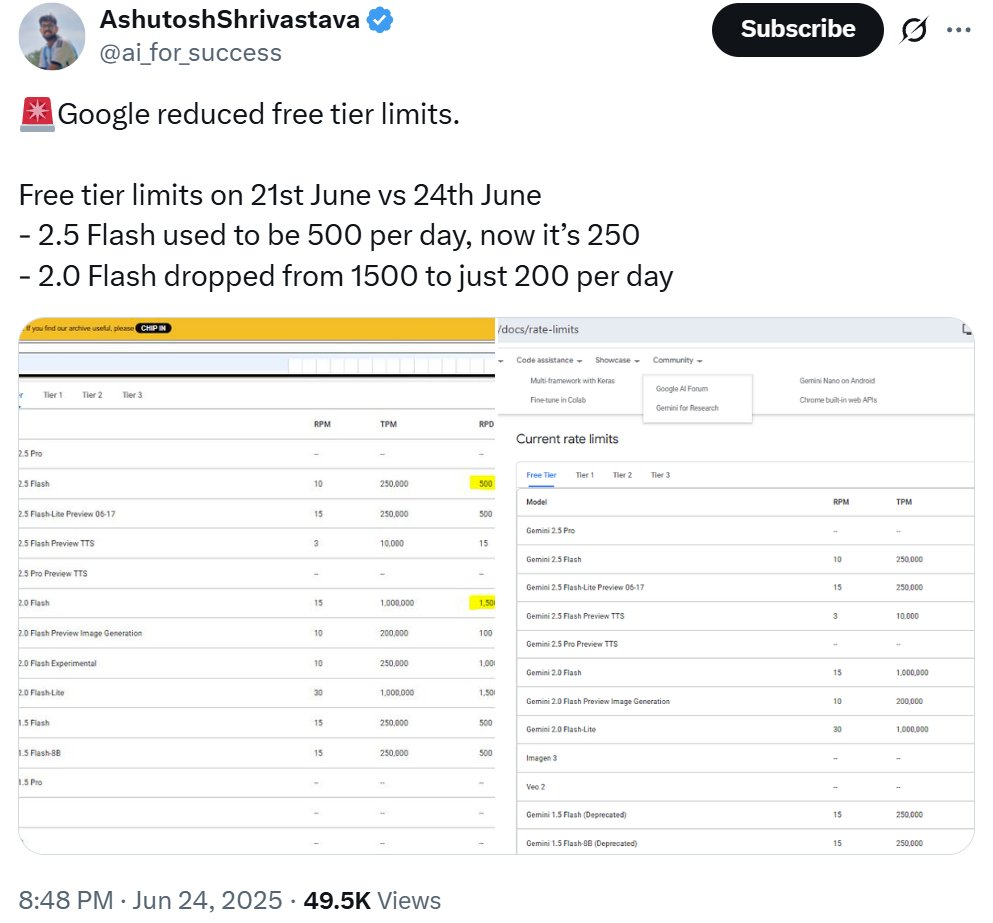
除了 Gemini Robotics On-Device,谷歌 DeepMind 还进行了一个可能不受免费用户欢迎的更新:下调免费可用额度。
博主 @ai_for_success 发现,Gemini 2.5 Flash 的免费可用额度从每日 500 次请求腰斩到了每日 250,而 Gemini 2.0 Flash 的免费可用额度更是从 1500 膝斩至 200。
https://x.com/ai_for_success/status/1937493142279971210
谷歌 AI Studio 和 Gemini API 产品负责人 Logan Kilpatrick 回应称这是他们的策略:「随着新模型的推出,降低或取消上一代模型的免费套餐。」

另外,谷歌今天还宣布在谷歌 AI Studio 和 Gemini API 中推出了图像生成模型 Imagen 4 和 Imagen 4 Ultra。

目前我们已经可以在谷歌 AI Studio 中免费试用它们。
这里我们也简单测试了一下,让 Imagen 4 Ultra 生成了一张包含猫、机器人与外星人的彩色水墨画:

(文:机器之心)