

随着大规模多模态模型的兴起,如何利用AI技术生成叙事性视频成为研究热点。现有的方法,如MINT Video和TTT-Video,尝试一次性生成完整视频,但在处理长视频时,尤其是在维持视觉连贯性和叙事一致性方面,仍然面临诸多挑战。
此外,单个视频片段的生成虽然在质量上有所提升,但在多片段组合时,常常出现过渡生硬、内容重复等问题。这些问题不仅影响了观众的观看体验,也限制了AI在动画制作领域的应用范围。
为了解决这些难题,哈尔滨工业大学发布了创新框架AniMaker,通过多个智能体的协同工作,实现从文本故事到动画视频的自动化转换。

AniMake框架主要由4个主要智能体组成:导演智能体、摄影智能体、评审智能体和后期制作智能体,这些智能体各司其职,相互协作共同完成动画的创作过程。
导演智能体是整个动画创作流程的起点,其任务是从文本故事中生成详细的脚本和故事板。导演智能体首先利用Gemini 2.0 Flash模型根据输入的文本故事生成包含镜头描述的原始脚本。然后,通过验证脚本的一致性和叙事流畅性,确保故事的连贯性。

接下来,在故事板实现阶段,导演智能体构建一个视觉库,包括角色库和背景库。角色库利用Hunyuan3D模型生成角色的参考图像,背景库则通过FLUX1-dev模型生成背景的参考图像。再通过GPT-4o模型根据验证后的镜头描述和视觉库中的图像生成关键帧,这些关键帧将作为后续视频生成的基础。
摄影智能体负责将故事板转化为具体的视频剪辑。这一过程面临的挑战包括角色外观的扭曲、动作的不一致性以及物体的不一致性。为了解决这些问题,AniMaker引入了MCTS-Gen策略。MCTS-Gen的核心思想是通过生成多个候选剪辑,并从中选择最优的剪辑,以确保每个剪辑不仅自身质量高,而且与前后剪辑保持一致性和连贯性。
MCTS-Gen的运行过程包括四个主要步骤:扩展、模拟、回溯和选择。在扩展阶段,摄影智能体从当前路径的终端节点生成多个初始候选剪辑,并利用AniEval框架对这些剪辑进行评分和排序。在模拟阶段,根据UCT得分进一步扩展树结构,选择得分最高的节点生成新的候选剪辑。回溯阶段将新生成剪辑的评分向上传播,更新父节点的评分。
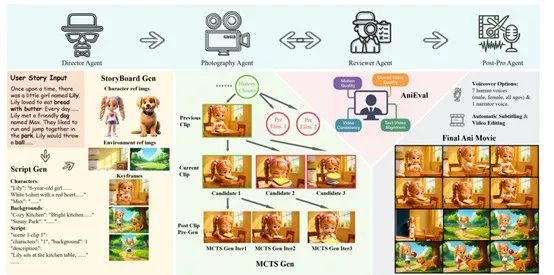
最后,在选择阶段,选择评分最高的剪辑加入到当前路径中,并继续生成新的候选剪辑,直到达到预设的候选数量。
评审智能体的任务是对生成的视频剪辑进行评估,以确保其质量和连贯性。现有的评估指标,如CLIP Score和Inception Score,虽然能够在一定程度上评估视频生成模型的性能,但在区分同一模型生成的不同候选剪辑时往往表现不佳。此外,广泛使用的VBench评估框架也存在诸多局限性,例如其“动态度”指标过于简单,仅测量像素变化,而不能准确反映角色动作;“一致性”指标则基于单剪辑分割,不适合多镜头动画的评估。
为此,AniMaker提出了AniEval评估框架。AniEval在EvalCrafter框架的基础上进行了改进和扩展,涵盖了整体视频质量、文本–视频对齐、视频一致性、运动质量等多个维度的14个细粒度指标。例如,DreamSim指标用于评估帧间的一致性;
CountScore指标用于检测对象在镜头间出现或消失的问题;面部一致性指标则通过在Anime Face Dataset数据集上训练的InceptionNext模型来评估动画角色面部的一致性。AniEval还支持基于上下文的评分,即在评估每个剪辑时,会考虑其前后的剪辑内容,从而为多镜头动画生成提供更准确的评估。

后期制作智能体负责将视频剪辑序列转化为最终的动画影片。这一过程包括三个阶段。首先,利用Gemini 2.0 Flash生成详细的旁白脚本,指定旁白内容、对话、情感语调以及期望的声音音色。
然后,根据角色属性选择合适的声音档案,并根据文本长度进行音视频同步的评估。通过CosyVoice2模型生成音频轨道,并验证其持续时间和内容的准确性。最后,利用MoviePy库进行影片的组装,整合经过验证的字幕,并进行全面的编辑,以确保视觉、旁白和字幕之间的精确同步。
(文:AIGC开放社区)