

不圆 发自 凹非寺
量子位 | 公众号 QbitAI
Thinking模式当道,教师模型也该学会“启发式”教学了——
由Transformer作者之一Llion Jones创立的明星AI公司Sakana AI,带着他们的新方法来了!
这个方法要求教师模型像优秀的人类教师一样,根据已知解决方案输出清晰的逐步解释,而不再是从头开始自己解决。

用Sanaka AI的新方法训练出的7B小模型,在传授推理技能方面,比671B的DeepSeek-R1还要有效。
训练比自己大3倍的学生模型也不在话下。
对此有网友评价:我们刚刚才意识到,最好的老师不是房间里最聪明的人。


像人类老师一样
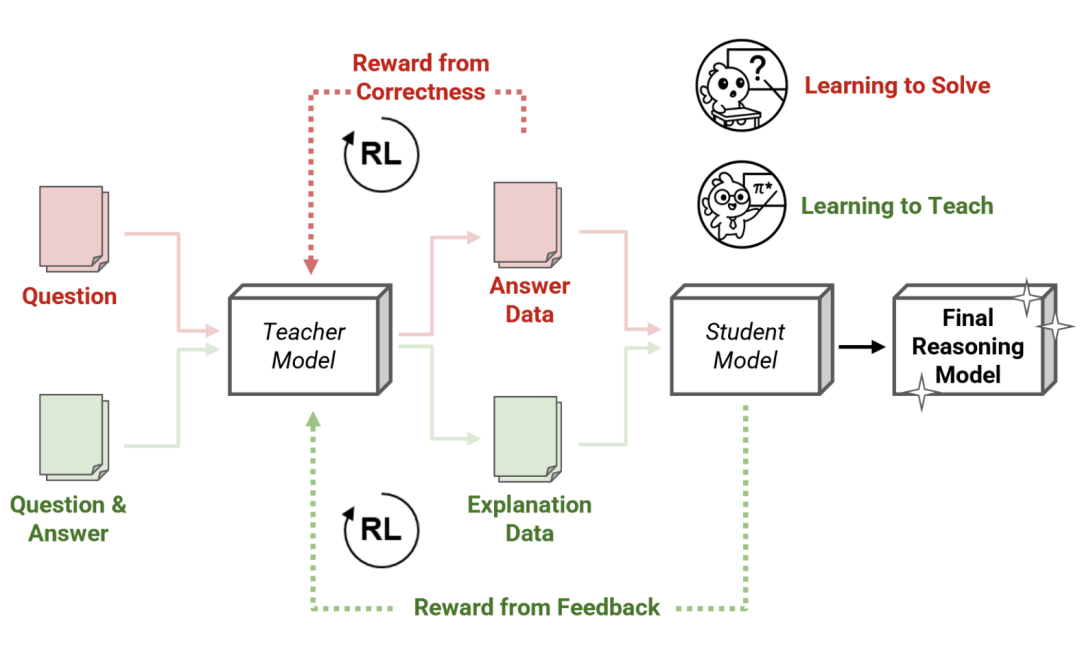
许多高级推理模型,如DeepSeek-R1,遵循两阶段的训练过程:首先训练教师模型,然后使用其输出训练学生模型,最终产品为学生模型。
传统上,这些教师模型通过昂贵的强化学习(RL)进行训练,模型必须从头学习解决复杂问题,只有在得到正确答案时才会获得奖励:
先让教师模型得到问题的答案,再把答案仔细过滤并重新用作学生模型的训练数据。
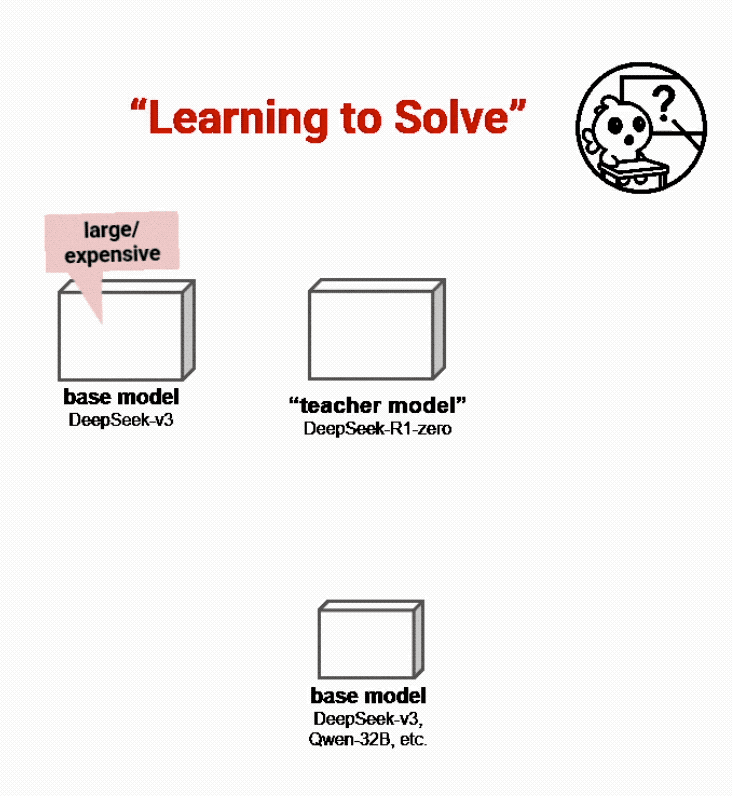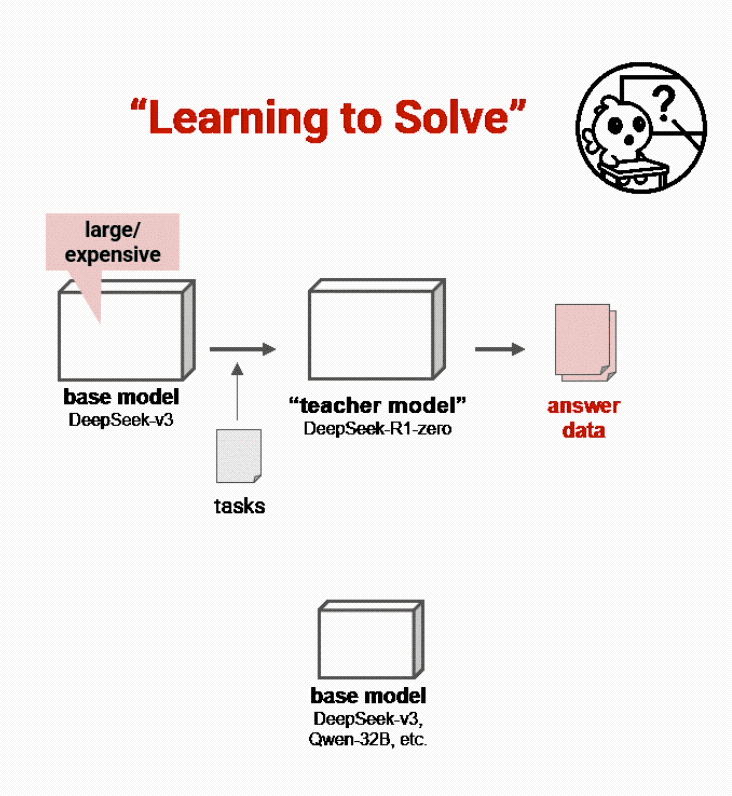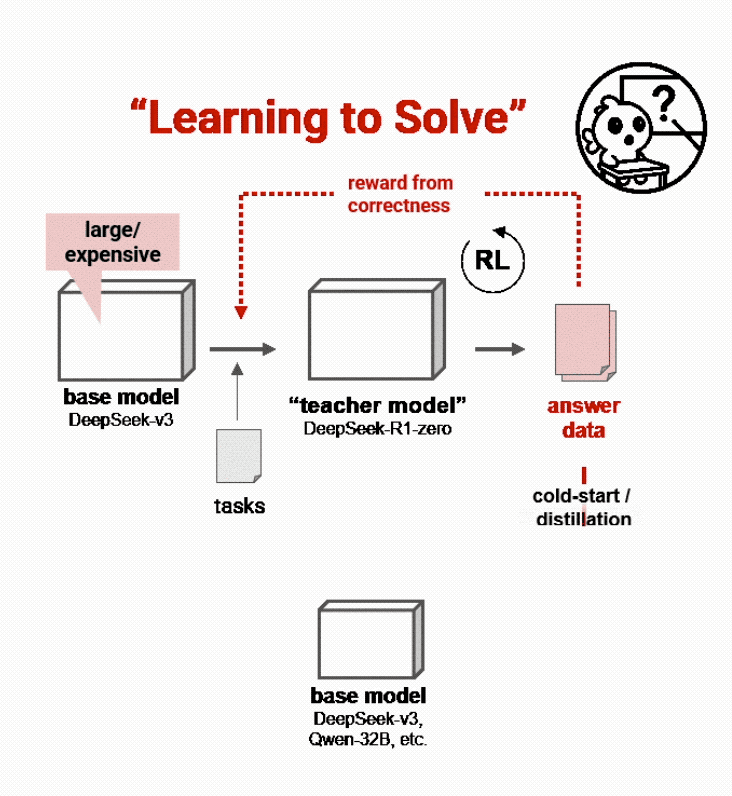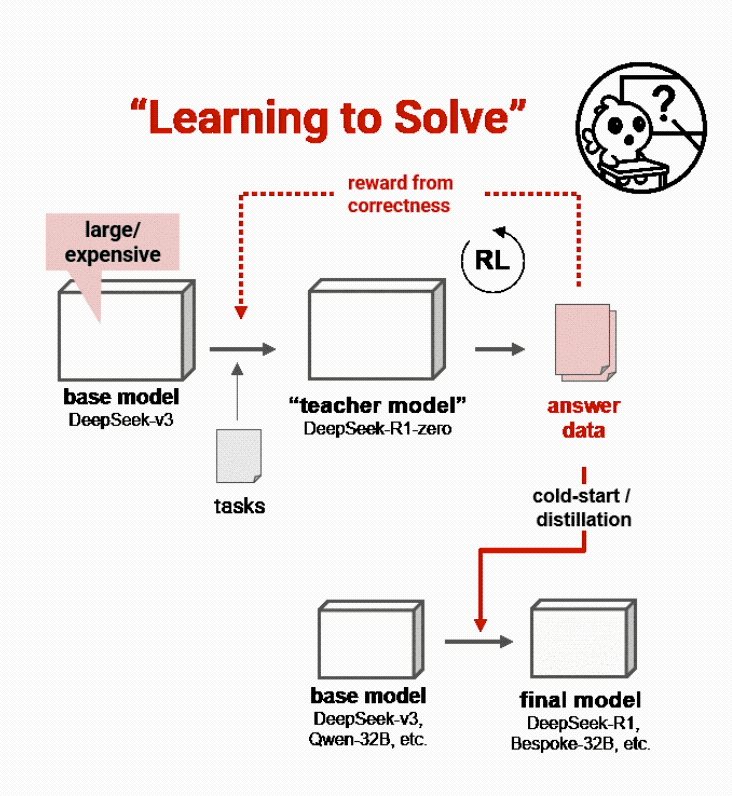
这种方法缓慢、昂贵且往往过于偏狭,过于依赖教师模型自身能力。因为教师模型拿到的仅仅只有问题,它们需要自己思考给出结果。
而Sanaka AI的新方法不再通过解决问题来教学,而是让新的强化学习教师(RLTs)“学会教学”:
要求它们根据已知解决方案输出清晰的逐步解释,就像优秀的人类教师一样。
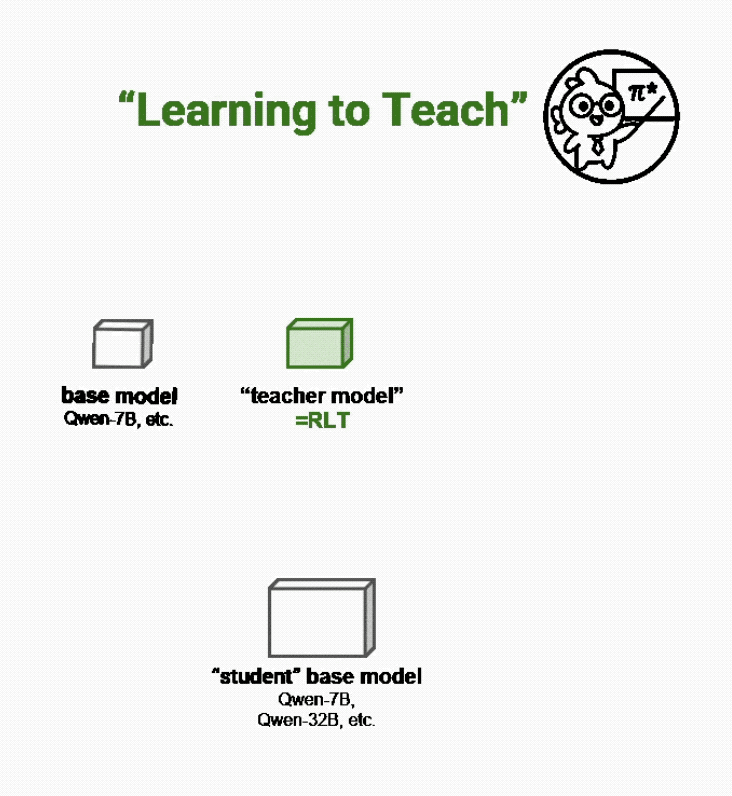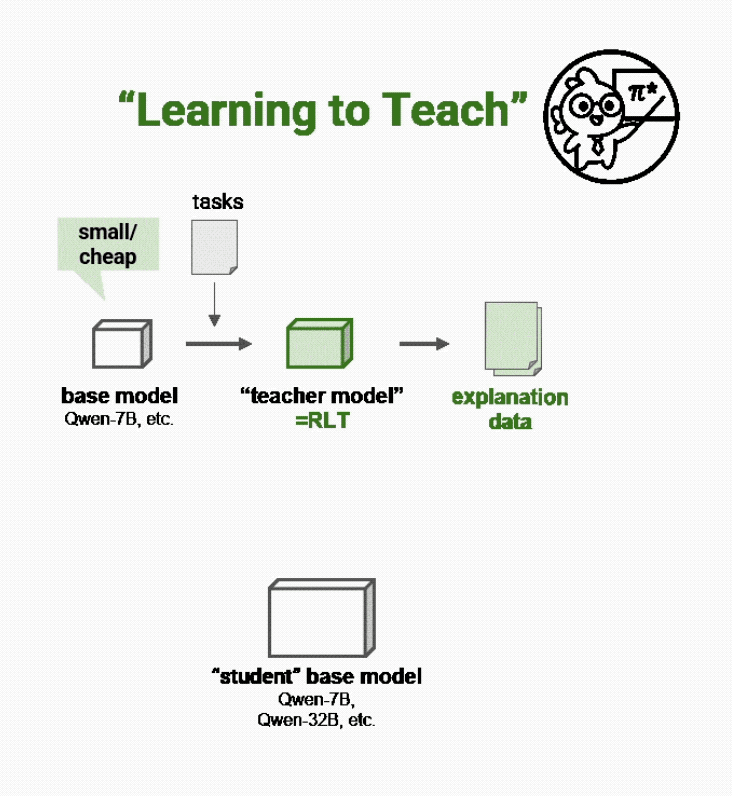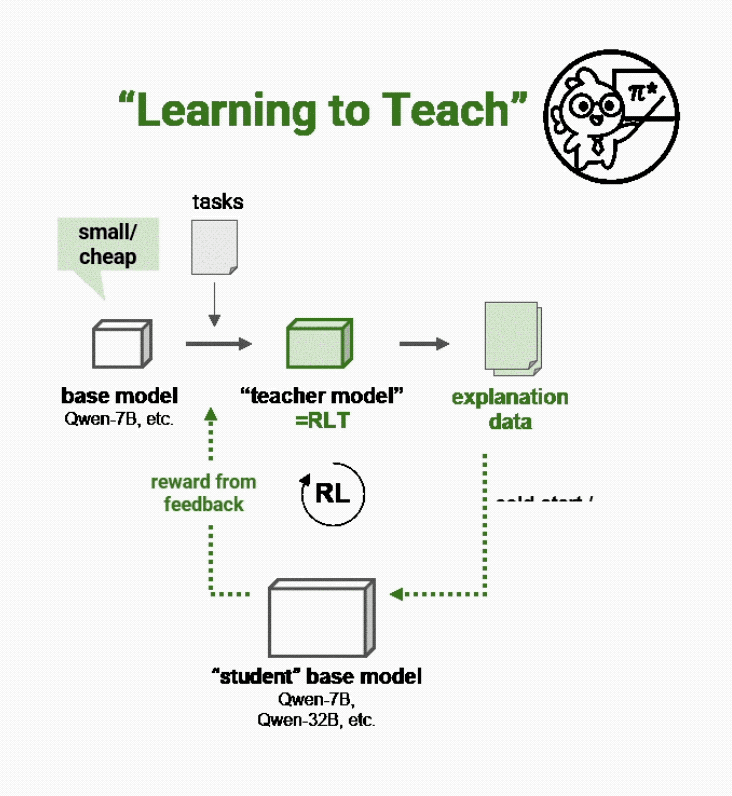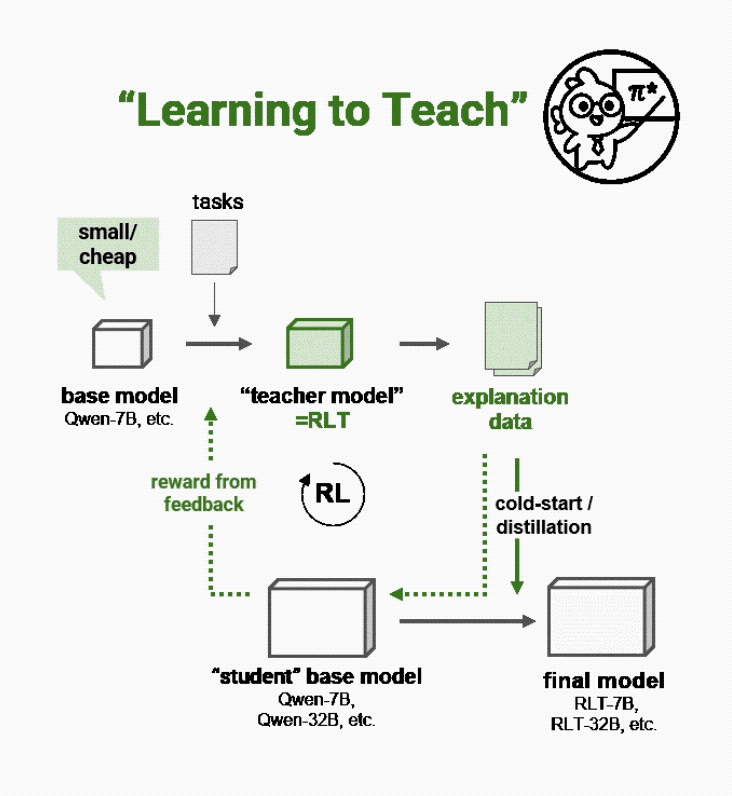
就像一位好教师不需要重新发现数学定理来解释它们一样,RLTs在输入提示中既获得问题的内容,也获得每个问题的正确答案。
它们的任务是提供有助于学生模型学习的、逐步的详细解释,从而连接这些知识点。如果学生模型能够根据教师对问题的解释轻松理解正确解决方案,那么这就是RLTs做得好的信号。
也就是说,对RLTs的奖励不再是能自己解决问题,而是能解释对学生模型有多有帮助。

Sanaka AI的新方法解决了传统方法中的两个问题:
首先,新方法的训练循环使教师训练与其真正目的(为学生进行蒸馏/冷启动提供帮助)保持一致,从而大大提高了效率。
其次,将问题和正确答案同时输入RLT,能帮助原本无法独立解决问题的小型模型学会教学。
这些特性使Sanaka AI的新方法能更快、更经济、更有效地训练出具有强大推理能力的学生模型。
小型教师模型的“不合理但有效”
为了验证新方法的有效性,Sanaka AI用新方法训练了一个7B的RLT小模型作为教学模型与此前最先进的方法进行比较。
竞争方法使用规模更大的模型,如DeepSeek-R1和QwQ,并结合GPT-4o-mini等工具在用于训练学生模型之前清理其输出,以获得额外帮助。
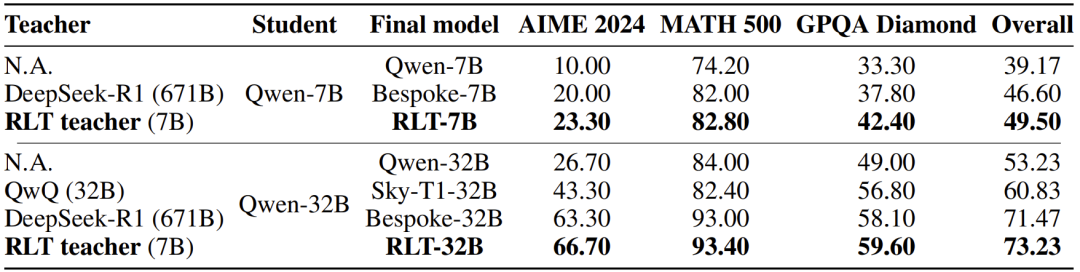
结果发现:使用相同的Qwen2.5学生模型、相同的问题以及相同的评估设置,RLT以远少的计算量取得了比DeepSeek-R1和QwQ更好的效果。
把学生模型的规模扩大,结果同样令人惊讶:7B的RLT成功训练了一个32B的学生模型,其规模是自己四倍以上,并取得了优异的成果。
Sanaka AI的新方法还可以和传统RL方法相辅相成:
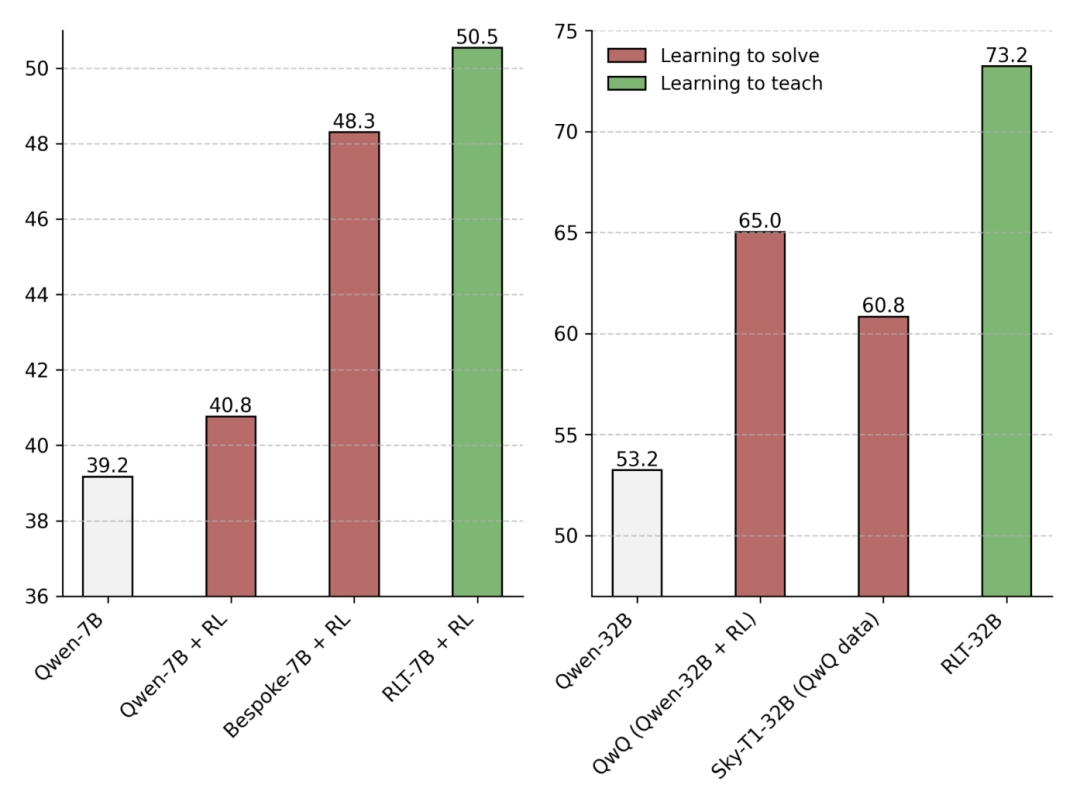
上图展示了在2024年美国邀请数学考试(AIME)、竞赛数学和研究生级问答基准(GPQA)上的平均性能。
新方法和传统RL方法联合使用,使RLT获得了改进性能,并补充了传统RL方法在问题解决方面的应用。
用作起点时,RLT帮助学生模型达到了更高的性能水平。
从成本角度来看,差异非常显著:使用RLT训练32B的学生模型仅需单个计算节点一天时间,而传统RL方法在相同硬件上需要数月。
一项定性分析揭示了RLTs提供的解释与Deepseek-R1的蒸馏轨迹之间存在一些差异:
Deepseek-R1的输出常常依赖于外部工具,例如计算器、网络上的讨论以及玩梗,包括一些具有误导性的内容。
相比之下,RLT提供的解释避免了令人困惑的语言,并增加了额外的逻辑步骤来帮助学生。
这些直观的改进能够转化为学生语言模型的改进学习,像人类专家一样简洁且清晰。
(文:量子位)