


AI 正在重构搜索本身的体验。
从早期的 AI Summary,到现在各家产品产品推出的 Deep Research,搜索的广度和深度,一直在被拓展。
Agent 时代,又从智能体的角度对搜索进行了能力的升维。
不仅仅是简单搜索,复杂问题乃至千字问题、研究任务、复杂的商品购买需求、投资任务,甚至直接解决用户的内容创作难题,比如快速生成几分钟的视频或者一份需要花很长时间才能完成的 PPT。
搜索意味着用户有问题要解决,Agent 智能体,可能是在今天解决搜索问题的更好答案。
纳米 AI 推出的「超级搜索智能体」就是基于这样的思路而诞生的一款产品,基于搜索但不止于搜索。
结合了今天的多 Agent 协作、多模型协作、MCP、AI 浏览器等能力,纳米 AI 超级搜索智能体是在当前的模型技术架构下,国内公司对于 AI 搜索和 AI 智能体的一个新的解决方案的尝试。

在 AGI Playground 2025 上,360 集团副总裁、纳米 AI 负责人梁志辉详细分享了 360 对于 AI 时代的搜索、智能体搭建以及 AI 浏览器的看法,和 360 在这些产品上的探索与经验。
以下内容基于演讲内容,由 Founder Park 整理。
超 7000 人的「AI 产品市集」社群!不错过每一款有价值的 AI 应用。

-
最新、最值得关注的 AI 新品资讯;
-
不定期赠送热门新品的邀请码、会员码;
-
最精准的AI产品曝光渠道
01
从问答到智能体,
AI 搜索的三个阶段
「纳米 AI 超级搜索智能体」是我们一周多前发布的新产品,这个产品主要是希望通过大模型的加持来改善大家的搜索体验。自从大模型产品出现后,很多人的搜索习惯应该都发生了改变,我自己也是这样。
传统搜索确实存在很多痛点。
从从业者的角度看,过去使用传统搜索时,我们必须输入关键字。但这里有一个很明显的问题,无论是国外的谷歌,还是国内的百度及 360,一旦关键词超过 20 个,基本上得到的答案质量就会很差。我们做过统计,搜索引擎里超过 40% 的用户需求是找网址或资源,但超过 60% 的需求是在提问。随着大模型的到来,用户提问的比例基本上升到了 90%,剩下的 10% 可能是创作、改写等需求。
在传统搜索时代,浏览器呈现给你的链接很多,大家会发现大部分的链接都是雷同的,因为它优先返回的是那些关键字相似、点击率高的网页,但它们不一定能解决你的问题。
所以我们看到,自从有了大模型,大家的搜索习惯被改变了。过去大家主动将问题拆分成关键词,并控制其数量和长度,到现在流行一个词叫「vibe」,大家会「vibe」地提出各种问题,比如「vibe coding」,我们也可以称之为「vibe search」。在这种趋势下,用传统的搜索引擎或检索思路,已经完全解决不了现在用户的许多需求了。
我们看到一个数据,过去的搜索关键词大约是 5 到 10 个字,而用了 AI 搜索或大模型产品后,大家提问的长度基本超过 20 字。在一些能自主解决通用问题的场景下,用户提的关键词或提示词会越来越长,我们见过最夸张的提示词高达数千字。在这个不经意的过程中,大家在很多场景下的习惯正被大模型逐步改变。

面临这样的时代变迁,360 也在尝试用 AI 来改造传统搜索。
在 1.0 时代,无论是谷歌、必应还是国内的搜索引擎,最直接的想法是让 AI 总结问题,把答案放在搜索结果之前。
但这面临几个问题:第一,这种解法不够纯粹,它仍然基于统计+检索的思路,提前总结了用户常问的问题,很多用户用了之后,感觉跟用大模型的体验没有太大区别,提升有限。今天无论是谷歌还是国内的厂商,都在逐步提升这一体验。
在第二阶段,我们尝试让大模型和搜索结合起来,用大模型做意图识别,实现多意图的全网搜索,这样能够实现一个深层次的答案。但说实话,随着现在模型能力的提升,我们发现这种体验跟用 DeepSeek 的区别并不大。
所以我们在想,既然模型的调用能力越来越强,价格越来越便宜,大家对 AI 提的问题也越来越复杂,我们便尝试把搜索升级到 AI 搜索的 3.0。也就是说,以前你可能提的是一个问题,但今天你提的可能是一个研究任务。
有了研究任务,现在 AI 的自我规划能力、分布执行能力很强,还有各种各样的工具。我们把整个产品的底层重构了,当它接到一个指令后,能够自动判断是简单需求还是复杂需求。对于复杂需求,它还可以做分解规划、分布执行和分布理解,然后交付一个专家级的结果。
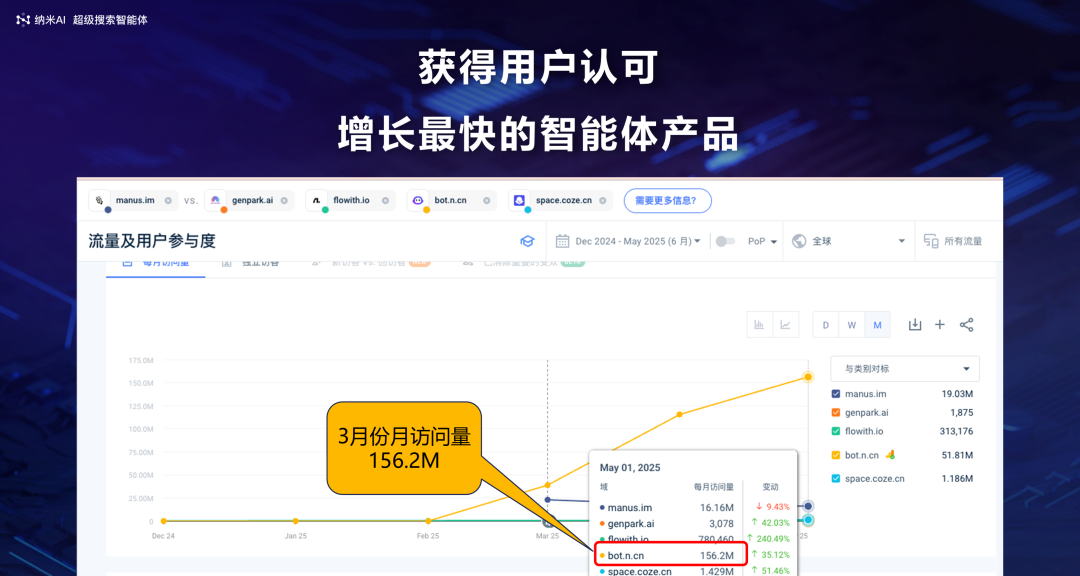
发布后发现效果很明显。这里有一张曲线图,可以看到,与其他友商相比,截至今年四五月份,我们的月度使用量已经超过 1.5 亿,基本上是第二名的十倍左右。
02
选择搜索场景
是因为用户习惯在这里
在选择赛道的过程中,我们思考的是。有了通用的超级智能体能力,可以帮用户解决什么问题。
最后我们依然选择以搜索为主要场景,原因有三个。第一,搜索是用户被培养了 20 年习惯的入口,需求非常强烈,工作、生活、办公、学习都要用到。但传统搜索不完美,它像一个懒惰的图书馆管理员,接到你的需求后告诉你去某个书柜找书,你还得自己去读、去分析。有了 AI 之后,就变成 AI 帮你读、帮你分析。
第二,我们做过统计,发现在大模型对话里,用户的大部分需求主要是以搜索为目的。无论是我们做的类似 DeepSeek 满血版的大模型入口,还是其他友商的产品,大家用大模型的第一需求依然是搜索,但大家提的问题越来越长,可能一次搜索解决不了。所以在这种场景下,我们觉得在 AI 搜索场景里结合超级智能体的能力,可以达到我们做产品期待的目标:高频、刚需、有痛点。解决简单问题是高频需求,而解决复杂任务则是有痛点的事情。
可以看到,如果只是一个很简单的问题,也许大模型只需要翻一下维基百科就能回答,我们定义这种叫做「简单问题」或「快问快答」。很多场景下,今天所有的 AI 搜索都能做到直接给答案,你不需要去翻阅非常多的链接,就能在 10 秒之内对问题得到解答。但是我们发现,有 20% 的用户需求是单次推理解决不了的。
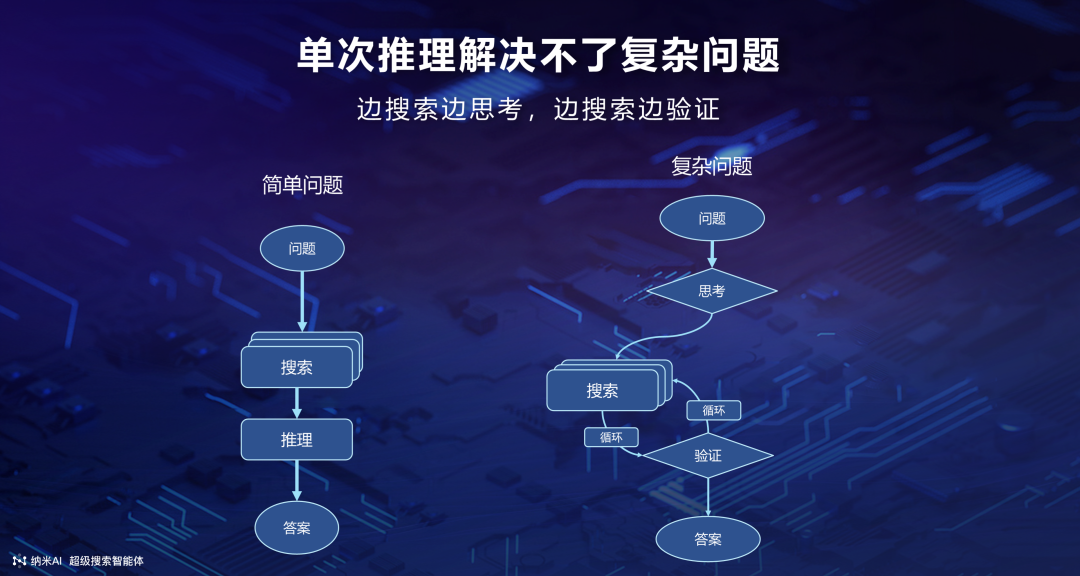
如图所示,在简单问题的场景下,可能大模型帮你做多次搜索、单次推理,问题就解决了。但遇到一个复杂问题时,就需要对大量的网页、书籍、图片、视频等去做搜索,然后不停地让模型边搜边思考、边搜边验证。国内外的产品都在逐步推出一种叫「Deep Research」的能力。这样的一张图其实跟谷歌前段时间发的开源项目很像,相当于把过去的单次搜索变成一个循环推理的过程。在这种场景下,我们的超级搜索能够对用户的很多复杂意图,比如一口气提 10 个有关联性的问题,模型自己就能够去进行边搜索边思考和边搜索边验证。
用语言描述可能比较难理解,可以看下面这个视频。
但还有一种更复杂的任务,比如你要做大件投资,或者买学区房,这个任务会变得更复杂。
我们提出了一种框架,即遇到复杂任务时,会利用多 agent 结构。用户提出问题后,会有一个专门的任务分解智能体和一个任务调度智能体,来调度一堆小智能体完成这种复杂任务。最后有一个多模态生成智能体,能把结果变成图文并茂的报告,或者超过一分钟的视频。有了这样的能力之后,我们就可以让大模型来帮你做一个投资决策,让大模型像一个高盛分析师一样帮你做投资报告。
03
超级搜索智能体的三个技术挑战
过去形容大模型有一种现象叫「garbage in, garbage out」*。在传统搜索过程里,大家追求的一般都是点击率,很多场景下一些不知名的小站或 SEO 内容,很容易比官方内容的点击量更高。可以看到,针对这种复杂任务,有了 AI 超级搜索智能体之后,它会自动推理并去寻找官网、对应的研报和深度高质量的信息,通过分析这些信息,并对其中的图片、视频做拆解后,来重新给你组成一个新的图文并茂的报告。刚才看到的 K 线图、数据表格,实际上都引用自各种专业的 PDF 文档。
附:如果输入系统的数据或信息本身存在错误、无效或低质量问题,那么系统输出的结果也必然是错误、无效或无价值的。
在打造这样的超级智能体的过程里面,我们面对三个非常大的挑战。
第一,今天大模型的编程范式在变。过去我们只是让大模型做阅读总结,但今天我们实际上是让大模型做任务分解。23 年有个项目很火,叫 AutoGPT,但当时受限于模型和智能体编程框架的能力,很多场景下它不能分解一个可执行的任务。今天我们利用国内的很多模型,通过组合之后能够实现非常稳定的分解效果。
我们有一个很大的优点,大家过去看到的很多超级智能体都是面对海外的,需要海外信用卡和账号。而 360 推出的纳米 AI 超级搜索智能体,只要你在国内,无论下载 APP 还是电脑客户端,都可以直接使用。我们是完全基于合规的场景,用国内的各种模型组合之后,来让模型的组合能力超过原来单个模型的能力。
第二个挑战在于,如何调度模型去完成非常多的任务。我们现在已经能够稳定地让模型调用 50 个工具,甚至分析 500 个复杂文档,最后给出一个答案。在这种场景下,长调用链对模型的推理能力、执行能力都要求非常高。为了保证交付成功率,我们围绕超级智能体打造了一整套 AI 专用的底层能力。我们甚至觉得这有可能是在 AI 时代的一种新的、像冯诺依曼的计算架构:大模型变成了新时代的 CPU,MCP 工具箱相当于计算机的总线,而知识库相当于计算机的记忆和存储能力。
在此基础上,为了扩展大模型的手和脚,我们专门做了一个 AI 专用的浏览器、AI 专用的搜索,还有一个 AI 专用的代码生成工具。围绕这几个能力,我们期待能够打造一个开放式的、基于纯国产模型的智能底座,让我们的智能体首先做到可用,人人可用,每个人都能在国内的网络环境底下直接跑起来。
国内最火的这些大模型,基本上我们都已接入并提供给用户去用。我们背后大概有 80 多个大大小小的模型,这 80 多个模型是我们组成「团队」来实现超长思维链和调用链的一个非常关键的智能底座。
我们把这 80 个模型做了一些分类:有的模型负责做高级推理,比如像 DeepSeek R1 或 Qwen 3 这样的模型;有的模型基于工具调用能力,比如豆包或通义千问 Plus 等 function call 模型;还有一些专业模型,是我们自己内部做小模型训练的,举个例子,像专门为快速搜索打造的小模型,或者做快速翻译的小模型。有了这样一个智能底座,在一个非常大的用户体量上,我们就能有不同的能力让不同的模型来组合发挥。
最后,我们在做的这个产品,无论是在手机上还是 PC 上,其实都是开放了智能体的打造能力的。只要你会写 prompt, 就能使用国内外能力最强的 100 多个 MCP。有一些付费的 MCP,你甚至都不需要海外注册,相当于我们直接就内置了一些付费的 key。
在这个过程里,我们会看到其实哪怕是一个高中生,使用手机版纳米 AI,他都可以去构建一个基于 MCP 能力的智能体。
在这种场景下,过去的智能体可能只能去做一些有限的工作,比如说角色扮演。但是在我们这样一个超级智能体里面,相当于已经内置了能力非常强的 MCP 工具,就可以基于我们的 MCP 工具去打造一些过去光靠大模型实现不了的一些效果。
为此我们还做了很多自研的 MCP,因为我们发现在 MCP 市场虽然有很多大厂也都进来了。但是有很多 MCP 工具,其实不是专门为国内的环境或者模型去打造的,所以我们又重做了很多常见的 MCP,比如说生成网页、视频生成。
有了这样的一个能力之后能干什么呢?过去我们做一个视频,可能需要跟大模型进行多次的交互,生成脚本、修改脚本,然后去调各种工具,才能够生成一个一分多钟的视频。但今天我们只需要一句话,在纳米 AI 搜索里面,它就可以去生成一个超过一分钟的带 BGM、带脚本、带字幕的复杂视频。
除了生成视频以外,其实我们还有对应的一些多模态知识库的生成能力。
过去大家说自己长文本能力很强,可能可以分析 10 个文档,最多也就 100 个文档。但今天我们有了一个最强的多模态知识库的能力,可以一口气帮你分析 500 份文档。点击上传文件按钮,批量上传 500 份候选人简历,输入你的需求:「帮我找出这里具有 5 年以上工作经验,本科以上学历,计算机专业背景的候选人」,AI 会自动调取工具,分别打开 500 份简历,分析简历内容,筛选出符合以上要求的候选人,最终以表格的形式呈现给你。
04
超级智能体需要 AI 浏览器
同时纳米 AI 还有更强的超级搜索能力。
过去,国内的产品只能检索国内的一些网站,国外的产品只能检索一些国外的网站。今天我们的纳米 AI 搜索,对国内国外都实现了超过 1,000 亿的内容的抓取。与此同时,我们发现在很多复杂场景,比如说像投资决策,以及知识视频的分解,只有一些静态的网页数据是不够的。所以我们的搜索引擎还具备了搜索各种 PDF、视频网站、音频内容和检索各类社交网站的能力,甚至可以去检索一些像电商金融这样相对专门的网站。
在这个过程中,有些东西我们是靠 MCP 的能力来实现的;有些东西我们是通过 API 的调用来实现的;那也有些东西我们是通过我们的浏览器来做到的。
提到浏览器,我们可能会发现今天很多的通用智能体都在说自己有浏览器的能力,能够实现各种信息的抓取、搜索等等能力。但同时,很多开源项目,或者是一些海外的智能体用到一些国内场景的时候,问题很多。
举个例子,你会发现无处不在的一些登录要求。国内基本上稍微正规一点的网站都必须要登录,在这种场景底下,靠云浏览器要实现云端的登录,用户其实是很不放心的。这可能就不是一个技术的问题,而是一个信任的问题。
其次,国内很多网站的嵌套一般比海外网站更复杂。比如在每个 div 互相嵌套的场景底下,要模型能够稳定快速地实现信息的识别,去遍历整个网页信息,基本上就做不到了。在这个过程中,我们基本上重做了我们整个浏览器的底层。在大模型的基础上,我们提供了一个浏览器的运行环境。有了这个东西,相当于就是可以让大模型像人一样去操作浏览器,比如说它可以自主分解你的指令,分解指令之后它会识别网页上的所有的可点击元素,甚至对于弹窗,都会主动地关掉。甚至可以帮你去把一些商品添加到购物车,完成一些自主的行动指令。以及对页面里面的一项评论,还有赞、评、踩,以及更多的一些多模态信息,全部能够读取出来。
然后最重要的一点,在很多场景底下,如果有光靠模型自己解决不了的问题,我们也训练了一个智能体,让智能体能够知道在什么场景底下要求助人类,比如说需要登录的时候让人类来进行扫码。
以及,AI 浏览器还可以打破信息孤岛。今天所有的网站其实都是一个一个的信息孤岛,很多场景底下它其实是不允许搜索引擎检索信息的。但今天有了一个被 AI 操纵的浏览器之后,它就可以充分利用这些网站内部的深度检索,能够让你去检索到以前靠百度、360、谷歌都检索不到的一些内容。
浏览器有了这样的一个能力可以解决什么问题呢?
国外的很多产品都喜欢说帮用户做 Deep Research。但我们会发现其实国内的用户在绝大部分场景底下是没有做 Deep Research 需求的。往往是当他们要去买一个电冰箱或者做股票投资的时候,才会进行大量的检索和搜索。所以我们做了一个购物的智能体,利用了 AI 专用的浏览器,可以通过智能体把世界上任何一个网站都可以被大模型去进行操纵。
这里面可以看到,纳米 AI 搜索是带了一个浏览器的。这个浏览器就跑在你本地的计算机里面。接到任务后,大模型会自动分解任务,让四个浏览器并行帮用户在小红书、淘宝、京东等去搜索,最后把这些笔记的信息、电商的优惠信息做整合之后,再生成一个图文并茂的报告;会告诉用户买一个 8,000 元的电冰箱、1 万元的一个电视机,应该找哪些品牌;以及线上的一些用户的真实反馈是怎么样的。
我试过很多最近发布的通用 agent,会发现大家都会存在同一个问题,也就是在具体的一些任务的时候,成功率会很低。其中和成功率相关的一个最核心的点就是他们非常依赖类似于浏览器的操纵能力,但今天我们通过重做整个浏览器的底层,把浏览器的一些模拟人的行为封装成各种 API,让大模型去进行调用。最后能够把调用 API 做网页分析、网页提取和网页行动的能力,做到行业里面成功率最高。这个事情是非常非常厉害的。
今天大模型的生成能力很强,除了能够生成图片、视频,还可以生成各种各样的应用、互动网页,甚至是 PPT。举一个例子,就是如果有了这样的一个能力之后,其实今天用 AI 来生成 PPT 的能力已经远远超过很多人自己哧吭吭哧做一晚上的效果。
从内容逻辑到视觉设计,纳米 AI 生成的内容都很精美、专业,彻底解决了 PPT 的老大难问题。做个简单的比喻。过去,你要做一份 PPT,可能要熬夜加班去搜索写作,然后做排版。这个过程里面付出的工资成本可能是几百到上千不等。今天通过大模型来帮你去搜索,帮你生成代码,以及做最后的 PPT 渲染。得到这样一个 PPT 大概我们会消耗 100 万的 token,那换算成国内的一些模型的费用,也就是大概是 8 到 10 块之间。
我觉得未来会有越来越多这样的智能体,也许以后大家会每个人都可以变成一个超级个体。

(文:Founder Park)