


极市导读
本文介绍了 Mirage Persistent Kernel,它能自动把小语言模型(LLM)推理转化为一个融合的 GPU kernel,消除启动开销,实现计算通信重叠,显著降低推理延迟,特别适合小规模 LLM 优化,但也存在资源利用和多 GPU 适配等局限。>>加入极市CV技术交流群,走在计算机视觉的最前沿
来源自 https://zhihaojia.medium.com/compiling-llms-into-a-megakernel-a-path-to-low-latency-inference-cf7840913c17
一个LLM编译器,它可以自动将LLM推理转换为单个megakernel——一个融合的GPU kernel,能在一次启动中执行所有必要的计算和通信。这种端到端的GPU融合方法将LLM推理延迟降低了1.2-6.7倍。我们的编译器使用简单——只需几十行Python代码就可以将LLM编译成高性能megakernel。
核心理念是什么? 传统的LLM系统通常依赖于一系列GPU kernel启动和外部通信调用,导致硬件利用率不足。我们的编译器可以自动将这些操作(跨越多层、多次迭代和多个GPU)融合为一个megakernel。这种设计消除了启动开销,实现了细粒度的软件流水线,并使计算与跨GPU通信重叠。
团队成员: Xinhao Cheng[1], Bohan Hou[2], Yingyi Huang[3], Jianan Ji[4], Jinchen Jiang[5], Hongyi Jin[6], Ruihang Lai[7], Shengjie Lin[8], Xupeng Miao[9], Gabriele Oliaro[10], Zihao Ye[11], Zhihao Zhang[12], Yilong Zhao[13], Tianqi Chen[14], Zhihao Jia[15]
项目地址: https://github.com/mirage-project/mirage/tree/mpk
降低LLM推理延迟最有效的方法之一是将所有计算和通信融合到单个megakernel_——_也称为persistent kernel中。在这种设计中,系统只需启动一个GPU kernel就能执行整个模型——从逐层计算到跨GPU通信——无需中断。这种方法带来几个关键性能优势:
-
消除kernel启动开销,即使在多GPU设置中,也可以避免重复的kernel调用; -
实现跨层软件流水线,使kernel能在计算当前层的同时开始加载下一层的数据; -
重叠计算和通信,因为megakernel可以同时执行计算操作和跨GPU通信以隐藏延迟。
尽管有这些优势,将LLM编译成megakernel仍然具有很大挑战。现有的高级ML框架——如PyTorch[16]、Triton[17]和TVM[18]——都不原生支持端到端的megakernel生成。此外,现代LLM系统是由各种专用kernel库构建的:NCCL[19]或NVSHMEM[20]用于通信,FlashInfer[21]或FlashAttention[22]用于高效注意力计算,以及CUDA或Triton[23]用于自定义计算。这种碎片化使得将整个推理流水线整合到单个统一kernel中变得困难。
我们能通过编译来自动化这个过程吗? 基于这个问题,我们来自CMU、UW、Berkeley、NVIDIA和清华的团队开发了**Mirage Persistent Kernel[24] (MPK)**——一个编译器和运行时系统,可以自动将多GPU LLM推理转换为高性能megakernel。MPK释放了端到端GPU融合的优势,同时只需要开发者付出最少的手动努力。
MPK牛逼在哪?
MPK的一个关键优势是通过消除kernel启动开销并最大程度地重叠计算、数据加载和跨GPU通信,实现了LLM推理的极低延迟。
图1. 比较MPK与现有系统的LLM解码延迟。我们使用了39个token的提示词并生成了512个token,未使用推测解码。
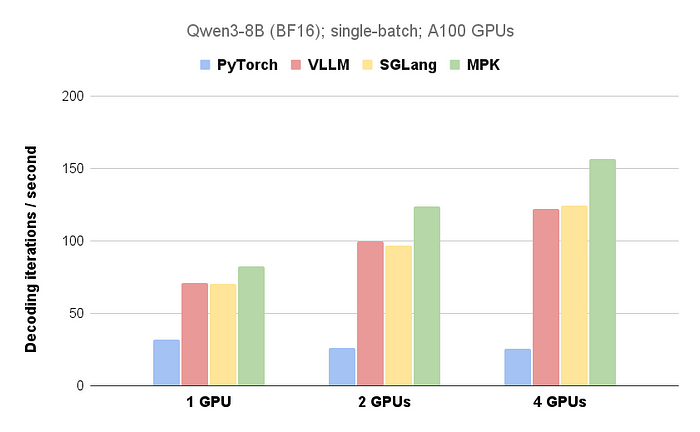
图1展示了MPK与现有LLM推理系统在单GPU和多GPU配置下的性能对比。在单个NVIDIA A100 40GB GPU上,MPK将每个token的解码延迟从14.5毫秒(这是像vLLM和SGLang这样的优化系统所能达到的水平)降低到了12.5毫秒,接近10毫秒的理论下限(基于以1.6 TB/s的内存带宽加载16 GB的权重)。
除了单GPU优化之外,MPK将计算和跨GPU通信融合到单个megakernel中。这种设计使MPK能够最大程度地重叠计算和通信。因此,MPK相比当前系统的性能提升会随着GPU数量的增加而增加,这使其在多GPU部署中特别有效。
接下来是什么?
本博客的其余部分将深入探讨MPK的工作原理:
-
第1部分介绍MPK编译器,它将LLM的计算图转换为优化的任务图; -
第2部分介绍MPK运行时,它在megakernel中执行这个任务图以实现高吞吐量和低延迟。
第1部分:编译器:将LLM转换为细粒度Task Graph
大型语言模型(LLM)的计算通常表示为一个computation graph,其中每个节点对应一个计算操作(如matrix multiplication、attention)或集体通信原语(如all-reduce),边表示操作之间的数据依赖关系。在现有系统中,每个operator通常通过一个专用的GPU kernel来执行。然而,这种kernel-per-operator execution model往往无法充分利用流水线机会,因为依赖关系是在粗粒度层面(跨整个kernel)而不是实际数据单元层面强制执行的。
LLM的计算通常表示为一个computation graph,其中每个节点是一个计算operator(如matrix multiplication、attention)或集体通信原语(如allreduce),边表示operator之间的数据依赖关系。现有系统通常为每个operator启动一个专用GPU kernel。然而,这种kernel-per-operator方法往往无法充分利用流水线机会,因为依赖关系是在粗粒度层面(跨整个kernel)而不是实际数据单元层面强制执行的。
考虑一个典型例子:matrix multiplication之后的allreduce操作。在现有的kernel-per-operator系统中,allreduce kernel必须等待整个matmul kernel完成。但实际上,allreduce的每个数据块只依赖于matmul输出的一部分。这种逻辑依赖和实际数据依赖之间的不匹配限制了计算和通信重叠的潜力。
图2. MPK编译器将LLM的computation graph(在PyTorch中定义)转换为优化的细粒度task graph,以暴露最大并行性。右侧展示了一个替代方案——但这是次优的task graph,它引入了不必要的数据依赖和全局同步障碍,限制了跨层的流水线机会。
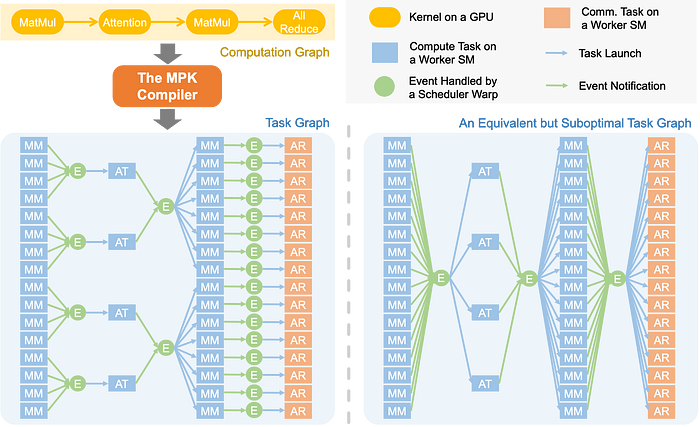
为了解决这个问题,MPK引入了一个编译器,可以自动将LLM的computation graph转换为细粒度task graph。这个task graph在sub-kernel级别明确捕获依赖关系,实现更激进的跨层流水线。
在MPK task graph中:
-
每个task(如图2中的矩形所示)代表分配给单个GPU streaming multiprocessor (SM)的计算或通信单元。 -
每个event(显示为圆圈)代表任务之间的同步点。 -
每个task都有一个指向triggering event的出边,当所有相关task完成时该event被激活。 -
每个task还有一个来自dependent event的入边,表示task可以在event激活后立即开始执行。
Task graph使MPK能够发现在computation graph中可能被忽略的流水线机会。例如,MPK可以构建一个优化的task graph,其中每个allreduce task只依赖于产生其输入的对应matmul task——实现部分执行和重叠。
除了生成优化的task graph外,MPK还使用Mirage kernel superoptimizer[25]为每个task自动生成高性能CUDA实现。这确保每个task都能在GPU SM上高效运行。(关于kernel superoptimizer的更多信息,请参见这篇文章[26]。)
第2部分:运行时:在MegaKernel中执行Task Graph
MPK包含一个on-GPU运行时系统,它在单个GPU megakernel中完全执行task graph,实现了对任务执行和调度的细粒度控制,在推理过程中无需任何kernel启动。
为实现这一点,MPK将GPU上的所有streaming multiprocessors (SMs)静态划分为两种角色:workers和schedulers。worker和scheduler SM的数量在kernel启动时固定,并与物理SM的总数匹配,避免了任何动态上下文切换开销。
Workers
每个worker在一个SM上运行并维护一个专用任务队列。它遵循一个简单但高效的执行循环:
-
从队列中获取下一个任务。 -
执行任务(例如矩阵乘法、attention或跨GPU数据传输)。 -
任务完成时通知触发事件。 -
重复以上步骤。
这种设计确保workers保持充分利用,同时使任务执行能够在各层和操作之间异步进行。
Schedulers
调度决策由MPK的分布式schedulers处理,每个scheduler运行在一个single warp上。由于每个SM可以容纳多个warps,每个SM最多可以同时运行四个schedulers。每个scheduler维护一个已激活事件的队列。它持续执行以下操作:
-
出队已满足依赖关系的已激活事件(即所有前置任务已完成)。 -
启动依赖于已激活事件的任务集。
这种分散式调度机制最小化了协调开销,同时实现了跨SM的可扩展执行。
图3. MPK运行时在megakernel中执行task graph。
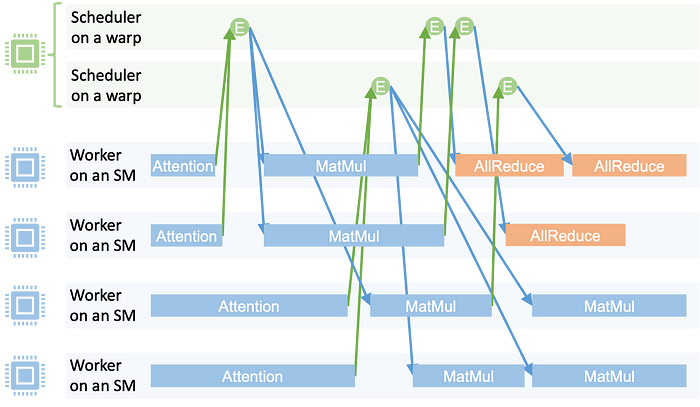
事件驱动执行
图3展示了MPK的执行时间线。每个矩形代表在worker上运行的任务;每个圆圈代表一个事件。当任务完成时,它会增加其对应触发事件的计数器。当事件计数器达到预定阈值时,该事件被视为已激活并进入scheduler的事件队列。然后scheduler启动依赖于该事件的所有下游任务。
这种设计实现了细粒度软件流水线和计算与通信的重叠。例如:
-
不同层的Matmul任务可以与attention任务并行执行。 -
一旦获得部分matmul结果,就可以开始Allreduce通信。
由于所有调度和任务转换都发生在单个kernel上下文中,任务之间的开销极低——通常仅为1-2微秒——从而实现了多层、多GPU LLM工作负载的高效执行。
展望未来
我们对MPK的愿景是使megakernel编译既易于使用又具有高性能。目前,您只需几十行Python代码就可以将LLM编译成megakernel——主要是用于指定megakernel的输入和输出。我们对这个方向感到兴奋,还有更多值得探索的地方。以下是我们正在积极开发的几个关键领域:
-
支持现代GPU架构。我们的下一个重要里程碑是扩展MPK以支持下一代架构,如NVIDIA Blackwell。一个主要挑战在于将warp specialization(新型GPU的关键优化)与MPK的megakernel执行模型集成。 -
处理工作负载动态性。MPK目前构建静态task graph,这限制了它处理动态工作负载(如**mixture-of-experts (MoE)**模型)的能力。我们正在开发新的编译策略,使MPK能够支持megakernels内的动态控制流和条件执行。 -
高级调度和任务分配:MPK在task级别实现了新的细粒度调度。虽然我们当前的实现使用简单的轮询调度来在SM之间分配任务,但我们看到了高级调度策略的令人兴奋的机会——例如优先级感知或吞吐量优化策略——用于延迟SLO驱动服务或混合批处理等用例。
我们相信MPK代表了GPU上LLM推理工作负载编译和执行方式的根本性转变,我们渴望与社区合作推进这一愿景。
个人见解
MegaKernel和之前TensorRT、triton、tvm的区别就是对kernel的合并更加激进些(后者也会进行kernel合并,比如conv + bn,但并不会都合并为一个),实际上就是一个大的定制化kernel。
让 LLM 始终运行在同一个 kernel 里,极大减少了 kernel launch 和数据搬运开销,实现 LLM 推理的低延迟与高吞吐。个人觉得比较适合1B、3B、7B这种可以单卡容纳的小模型,这种级别的LLM有overhead可以被巨大kernel优化,但是比较大的模型(32B、70B)相应的overhead不明显,一个kernel和多个kernel对性能的影响不大。
而且这个方式不够灵活,对资源利用会比较大(在编译kernel的时候为了性能会强行设置然后assert一些资源,和之前trt的做法一些,有些牺牲显存换取性能的意思,这个会更明显些),多gpu适配难度比较大。
比较适合小的LLM。
参考资料
[16] PyTorch: https://pytorch.org/
[17] Triton: https://github.com/triton-lang/triton
[18] TVM: https://tvm.apache.org/
[19] NCCL: https://github.com/NVIDIA/nccl
[20] NVSHMEM: https://developer.nvidia.com/nvshmem
[21] FlashInfer: https://github.com/flashinfer-ai/flashinfer
[22] FlashAttention: https://github.com/Dao-AILab/flash-attention
[23] Triton: https://github.com/triton-lang/triton
[24] Mirage Persistent Kernel: https://github.com/mirage-project/mirage
[25] Mirage kernel superoptimizer: https://github.com/mirage-project/mirage
[26] 这篇文章: https://zhihaojia.medium.com/generating-fast-gpu-kernels-without-programming-in-cuda-triton-3fdd4900d9bc
(文:极市干货)