


新智元报道
新智元报道
【新智元导读】清华大学软件学院发布生成式时序大模型——日晷(Sundial)。告别离散化局限,无损处理连续值,基于流匹配生成预测,缓解预训练模式坍塌,支持非确定性概率预测,为决策过程提供动态支持。
最近,清华大学大数据系统软件国家工程研究中心的⼀项时序⼤模型⼯作被ICML 2025接受为Oral⽂章。

论文链接:https://arxiv.org/pdf/2502.00816
代码链接:https://github.com/thuml/Sundial
开源模型:https://huggingface.co/thuml/sundial-base-128m
在论文刚发布时,这项工作就引起了学界和业界关注。

在HuggingFace发布一周后,日晷在时序预测板块的Trending排名第四,下载量达 6k。
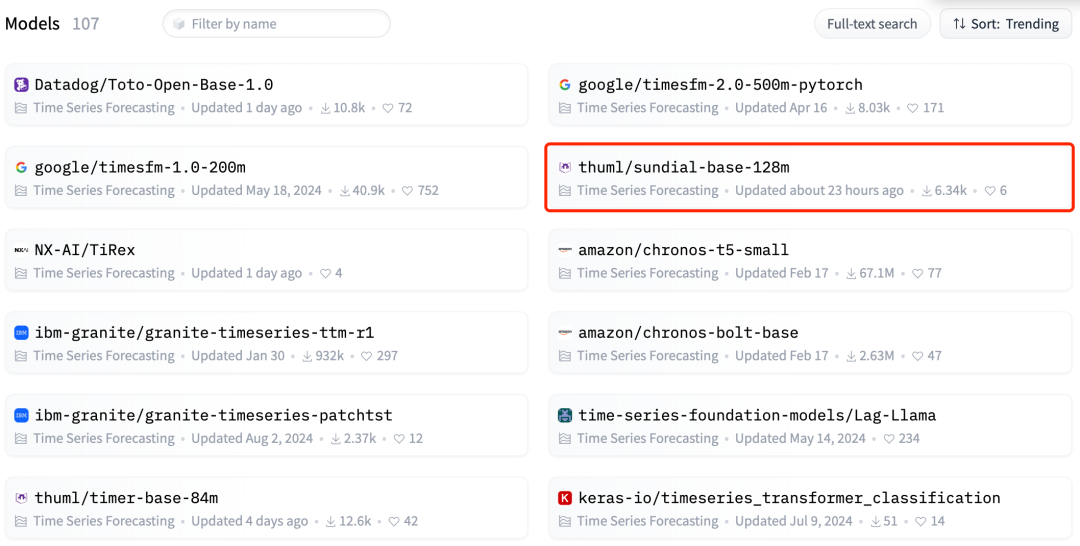
HuggingFace 时序预测(Time Series Forecasting)板块
该工作的主要贡献如下:
-
针对时序预测的非确定性,提出基于流匹配的预测损失函数,能根据历史序列生成多条预测轨迹,并缓解时序大模型预训练时的模式坍塌。
-
构建了首个万亿时间点规模的高质量时序数据集,发布了支持零样本预测的预训练模型。
-
相较统计方法和深度模型,无需专门微调在多项预测榜单取得效果突破,具备毫秒级推理速度。

时间序列揭示了数据随时间的变化规律,时序预测在气象、金融、物联网等多个领域中发挥着重要作用。
针对时序数据的统计学习,机器学习,深度学习方法层出不穷,然而,不同方法都有各自的优势区间:
深度学习模型虽好,但在数据稀缺时容易出现性能劣化;
统计学习方法虽快,但需逐序列拟合,缺乏泛化性。
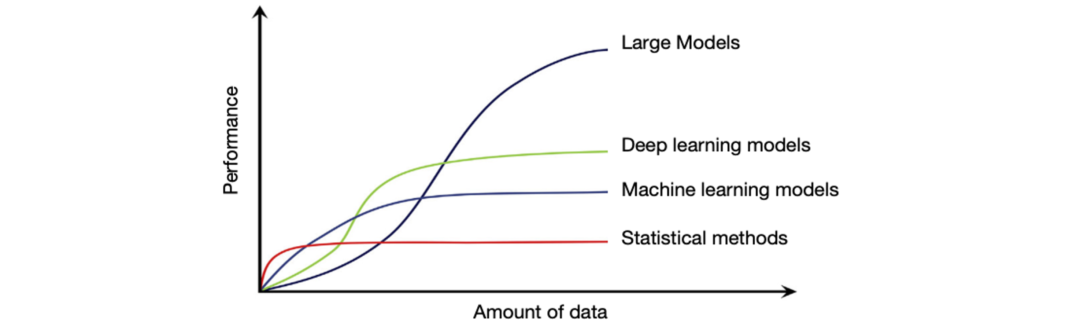
训练数据与模型效果的规模曲线同样适用于时序分析
最近研究旨在构建时序大模型:在大规模时序数据上预训练,在分布外数据上预测(零样本预测)。
由于不需要训练,其资源开销主要集中在推理,速度媲美 ARIMA 等统计方法,并拥有更强的泛化性。
谷歌,亚马逊,以及 Salesforce 等公司相继自研时序大模型,用于在特定场景下提供开箱即用预测能力。
目前业界的深度模型主要支持确定性预测:给定历史序列,产生固定的预测结果。
然而,时序预测存在非确定性,对预测结果的把握取决于信息的充分程度。
深度学习以数据驱动的方式建模时序变化的随机过程,实际观测到的序列也是上述随机过程的一次采样。
因此,时序预测不光存在信息完备的难题,即使信息充分,未来结果也存在一定的不确定性。
决策过程往往更需要对预测结果的风险评估(例如方差,置信度等),因此概率预测能力至关重要。
概率预测并非难事
均方损失函数能建模高斯先验的预测分布,尖点损失函数(Pinball Loss)可实现分位数预测。
然而,为时序大模型赋予概率预测能力充满挑战:大规模时序数据往往呈现复杂多峰分布——相似的历史序列,在不同领域/样本中可能出现完全不同的未来变化。

时序预测的非确定性来自时序数据的分布异构性。时序数据还存在其他异构性:例如维度异构,语义异构等。目前时序大模型尚处于如何有效处理时序数据异构性的阶段
在大规模时序数据的复杂异构分布上训练,以往模型往往给出「过平滑」的预测结果(上图右)。
虽然从优化目标来看,该结果是全局最优的,但预测结果没有提供实际有效的信息。
作者团队将该现象称为时序模型「模式坍塌」,源自使用带先验的损失函数,限制了模型的假设空间 (Hypotheses Space)。
为缓解模式坍塌,Moirai使用混合分布处理模棱两可的预测情况。然而,混合分布依然引入了概率先验,不够灵活。
亚马逊Chronos将时间序列离散化,使用交叉熵优化学习弱先验的多峰概率分布。
但是,交叉熵损失依赖离散化,存在精度损失和词表外泛化(Out-of-Vocabulary)等问题,不够原生。
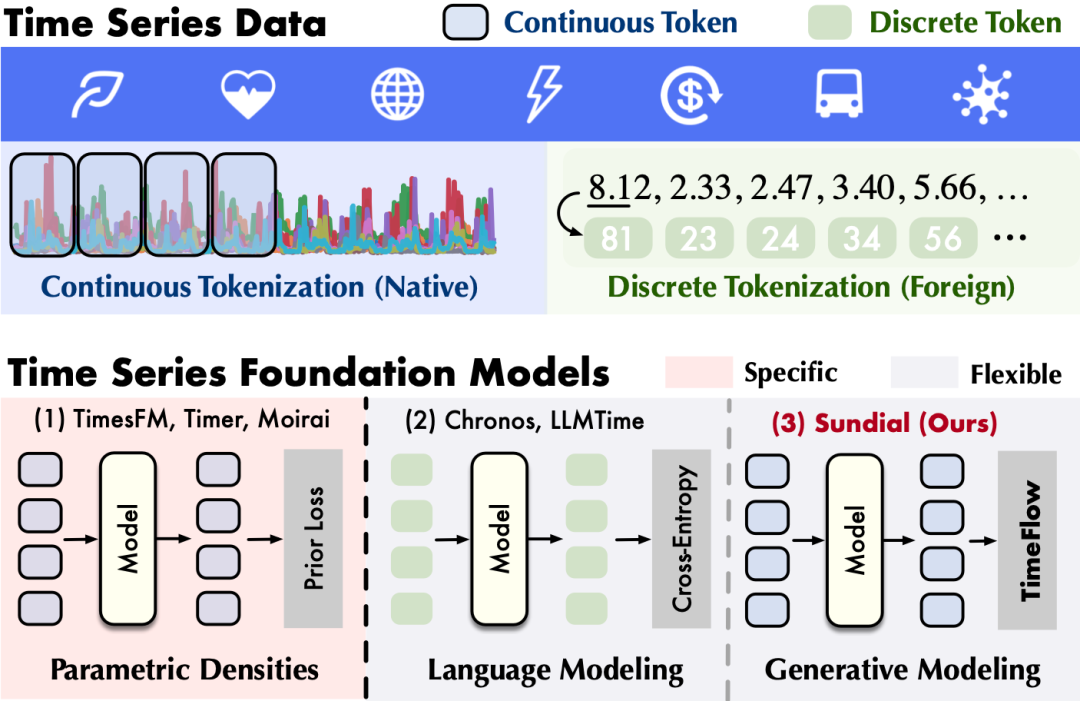
日晷相较此前时序大模型的区别:(1)时序原生性:无需离散化,使用 Transformer 直接编码连续时间值,突破语言建模(Language Modeling)(2)分布灵活性:不引入分布先验,基于生成模型学习灵活的数据分布,突破参数先验(Parametric Densities)
针对原生性和灵活性的矛盾,该工作深入原生连续编码和生成式建模,提出首个基于流匹配的生成式时序大模型。
无需离散化,在连续值序列上进行处理和预测;无需假定预测分布,释放模型对大规模时序数据的学习能力。
日晷模型主体为可扩展Transformer,使用重归一化,分块嵌入和多分块预测等技术适配时序数据特性,并融入了FlashAttention,KV Cache等进行效率优化。
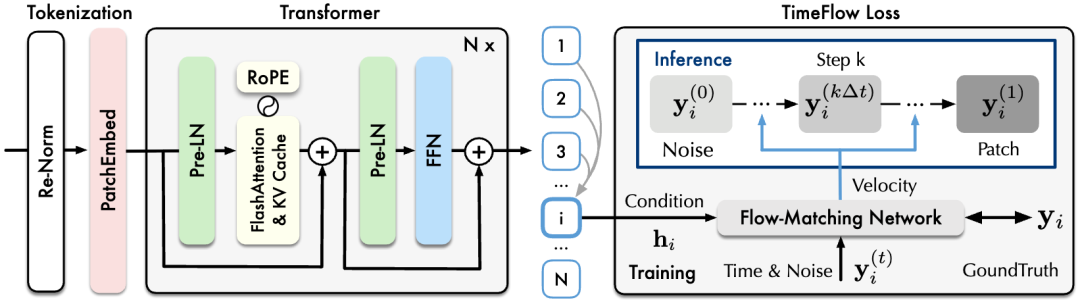
日晷可视作一种ARMA模型(自回归和与移动平均):Transformer自回归地学习任意长度的时间序列表征;基于该表征,时间流(TimeFlow)将随机噪声转换为非确定性预测结果
基于Transformer提取的上下文表征,研究人员提出时间流预测损失(TimeFlow Loss),将历史序列表征作为生成条件引入到流匹配过程中。
流匹配是生成式建模的前沿技术,通过学习速度场,将简单分布变换为任意复杂分布,从简单分布中采样随机噪声,能够生成服从复杂分布的样本。
所提出的损失函数不引入任何概率先验,模型将采样随机性引入训练过程,扩展了预测分布的假设空间,增强了模型的拟合能力,使其能更加灵活地处理时序数据的分布异构性,
推理时,通过多次从简单分布中采样,模型能够生成多条符合历史变化的预测轨迹;基于多条预测样本,能够构建预测序列的分布,从而估计预测值,方差和置信区间等。
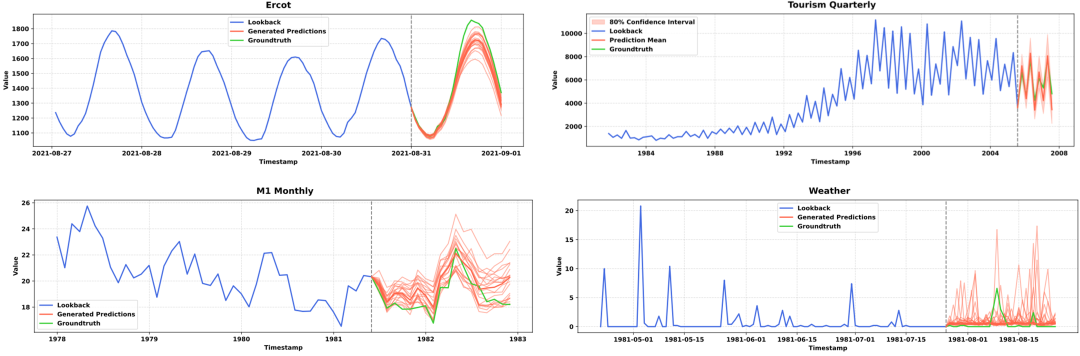
日晷可多次采样生成未来可能出现的情况,隐式构建预测值的概率分布,使用者可在此基础上计算关心的分布指标,或者引入反馈信号进行调优
该工作构建了领域最大的时序数据集TimeBench,由真实数据和合成数据构成,覆盖气象、金融、交通、能源、物联网等多个领域,包含小时到日度等多种采样频率和预测时效,总计万亿(10^12)时间点。
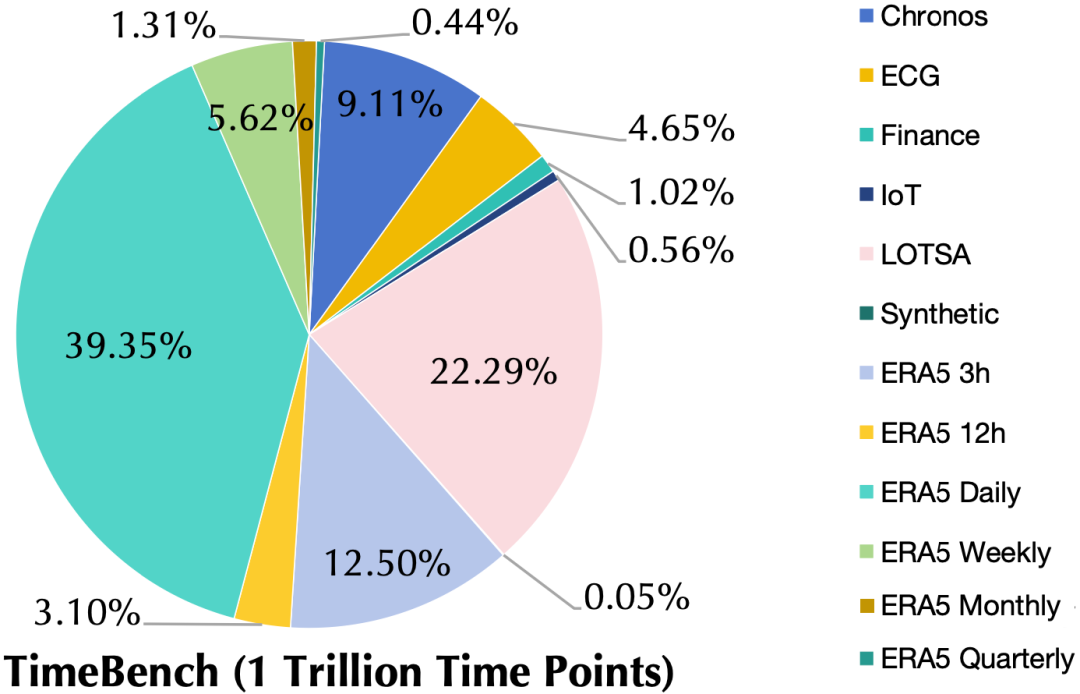
TimeBench 由大量真实数据和少量合成数据组成,覆盖多种时序预测的应用相关领域
在万亿数据基础上,模型在扩展的数据量/参数规模中预训练,验证了生成式时序大模型的「规模定律」。
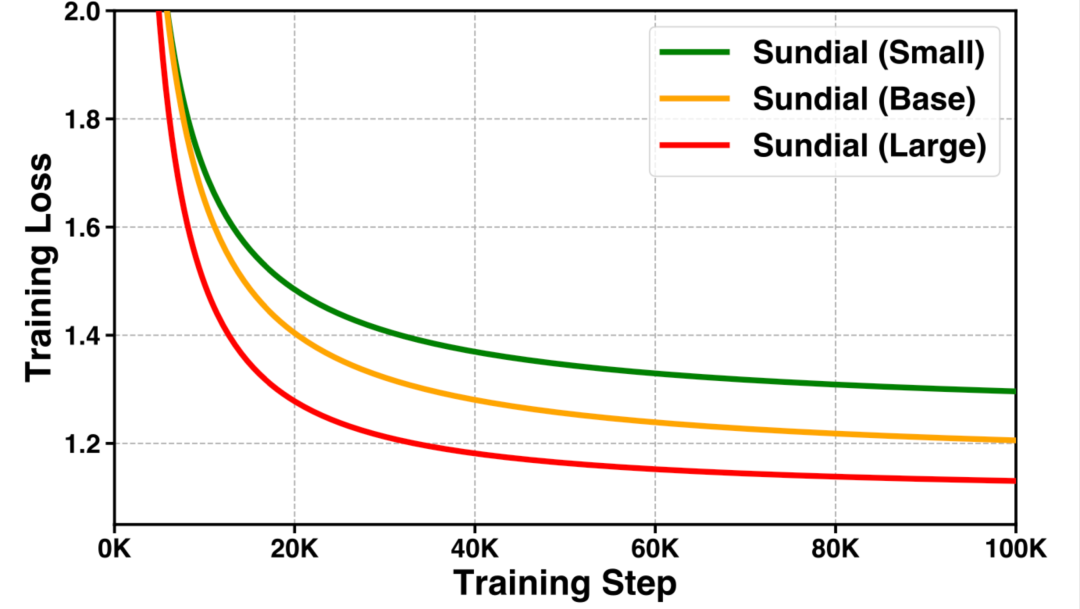
不同参数规模的模型训练曲线
日晷在多项榜单中进行了测试,涵盖多种输入输出长度,包含点预测以及概率预测场景:
-
GIFT-Eval 榜单:日晷的零样本预测能力超过此前Chronos,Moirai,以及分布内训练的深度模型。

GIFT-Eval 为 Salesforce 发布的预测榜单,包含24个数据集,超过144,000个时间序列和1.77亿个数据点,跨越7个领域,10种频率,涵盖多变量,短期和长期的预测场景
-
FEV 榜单:日晷大幅超过 ARIMA 等统计方法,取得了与 Chronos 相当的效果,仅需1/35的推理时间。
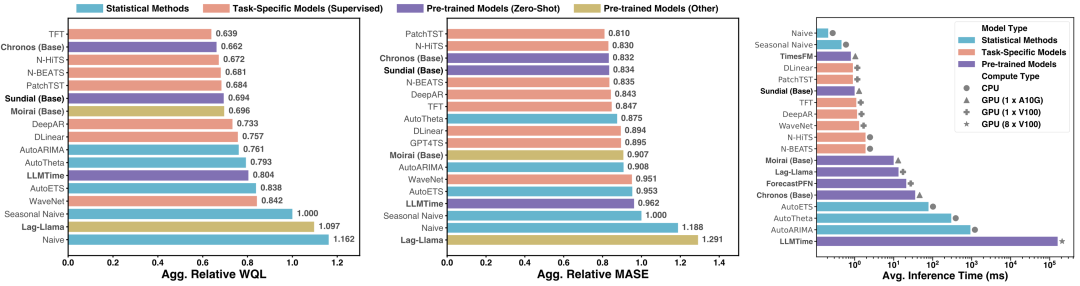
GIFT-Eval 为 AutoGluon 发布的预测榜单,包含27个数据集,指标从左到右依次为:概率预测(WQL),点预测(MASE)和推理时间(ms)
-
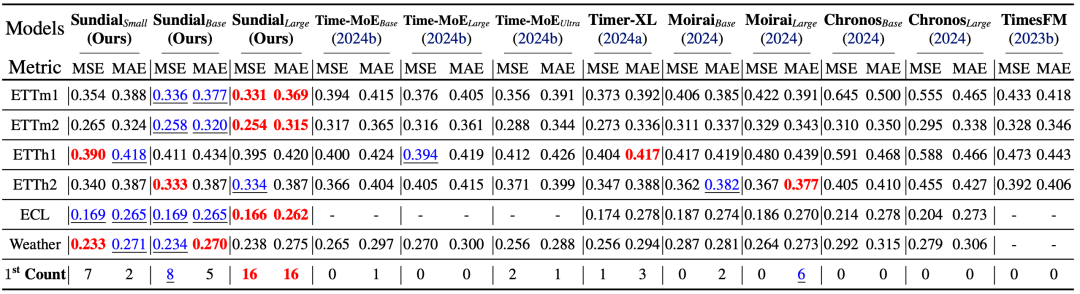
Time-Series-Library 榜单:日晷取得了第一的零样本预测效果,随参数规模扩大,效果持续提升。
目前 HuggingFace 上开源了基础模型,仅需不到十行代码,就可调用模型进行零样本预测,并提供了均值预测,分位数预测,置信区间预测等示例。

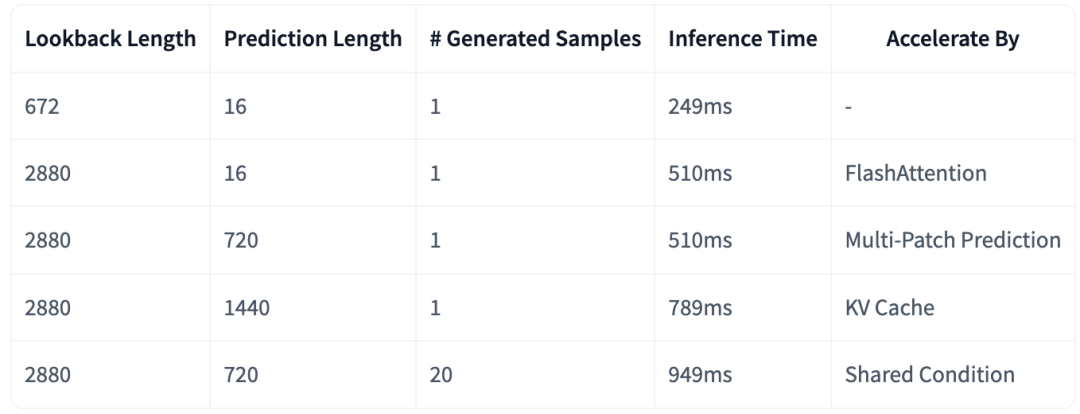
模型可在CPU上直接推理,生成多条预测结果的时间不到一秒。
日晷结合了连续值编码、Transformer和生成式预测目标,缓解了时序数据预训练的模式坍塌问题。通过万亿规模预训练和工程效率优化,模型提供了开箱即用预测能力和毫秒级推理速度。
所提出的生成式预测范式有望扩展时序模型的应用前景,使其成为许多行业的决策工具。
未来,该工作计划探索在多变量预测场景下的训练和微调技术,融入特定场景下的机理知识和决策反馈,进一步释放时序大模型的泛化性和可控性。
(文:新智元)