Andrej Karpathy 的最新演讲又刷屏了:
过去 70 年,软件的底层范式几乎未变。
但在近几年里,这种“稳态”被两次剧烈冲击。
我将当前的浪潮称为“Software 3.0”。
演讲视频:https://www.youtube.com/watch?v=LCEmiRjPEtQ
演讲 PPT:https://drive.google.com/file/d/1a0h1mkwfmV2PlekxDN8isMrDA5evc4wW/view(无法领取的小伙伴可添加文中小助手领取)
出品丨AI 科技大本营(ID:rgznai100)
作为 OpenAI 初始成员,前特斯拉 AI 总监,Andrej Karpathy 亲历并塑造了过去十年深度学习的黄金时代。
他的每一次开口,几乎都能点燃技术社区的疯狂讨论与思考,就在上周的 Y Combinator 举办的 AI Startup School 上,他发表的《Software in the era of AI》演讲再一次揭示了 AI 时代的软件开发正经历深刻的范式变革。

以下是对他演讲原文的整理,去掉一些口语化表达,使用 Gemini 2.5 Pro 进翻译与适当优化:
大家好,很高兴今天能来到这里。我想说的是,现在是进入科技行业极其独特且特别令人兴奋的时刻。
我之所以说“再次”,是因为几年前我曾发表过名为「Software 2.0」的观点,当时我认为软件的形态发生了第一次重大跃迁。
你可能难以想象,在过去七十年的时间里,软件的底层范式几乎没有本质性的变化。可就在最近短短几年,它连续经历了两次剧烈跃迁。
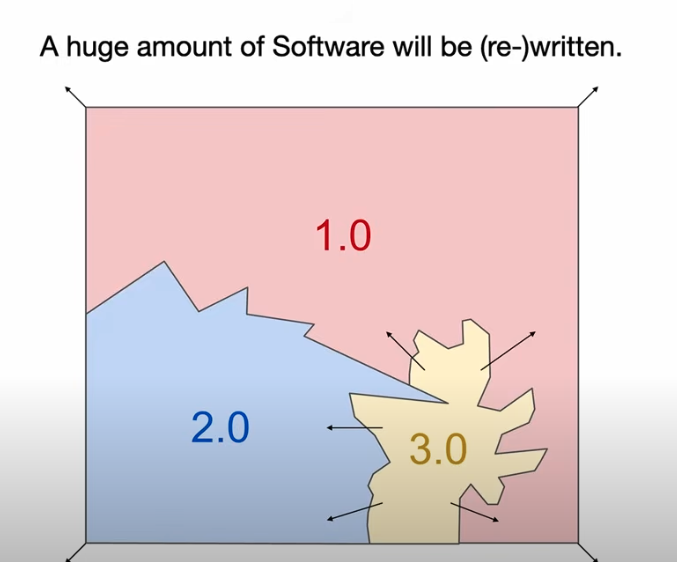
意味着我们有一座庞大的软件世界需要重建,有无数的系统等待重写。
设想你面前是一张软件世界的地图。图中星罗棋布的,不是城市和河流,而是成千上万的代码仓库。每一个 repo,都是人类试图与计算机对话的一次尝试。
几年前,我开始意识到这张地图正在悄然变形:有一种“新型软件”正在浮现。
-
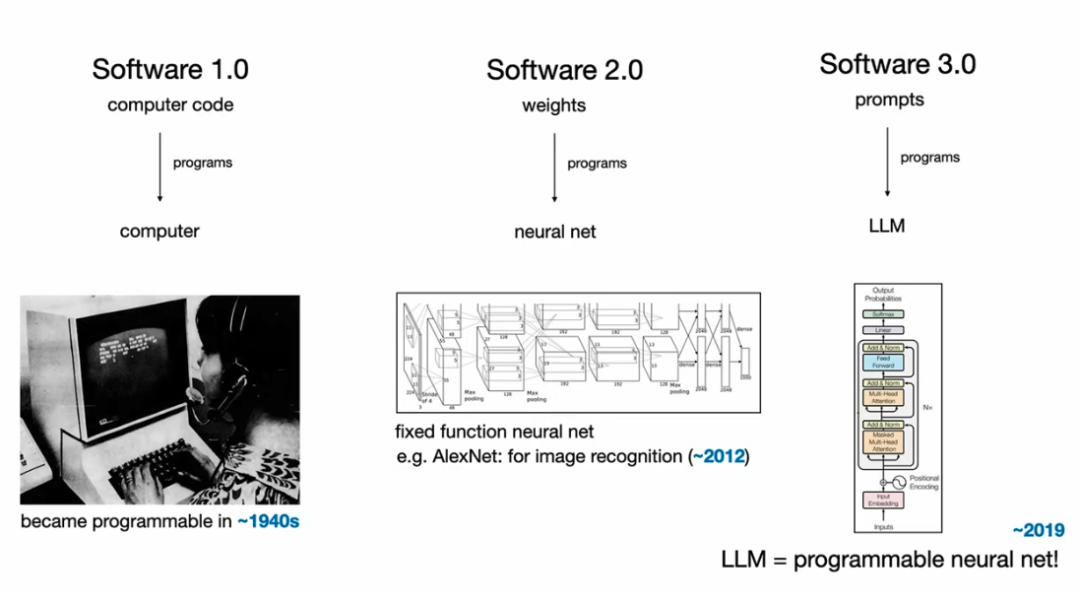
Software 1.0 时代是由人类用 Python、C++ 等语言明确编写的代码的时代,这是过去 70 年软件开发的主流形态。
-
Software 2.0 则是以神经网络的权重为核心。我们不再直接编写复杂的逻辑,而是通过设计网络结构、准备数据集,然后用优化算法(如梯度下降)来“寻找”能解决问题的程序。
如果说 GitHub 是 Software 1.0 的王国,那么 Hugging Face 就好比是 Software 2.0 时代的 GitHub。
你甚至可以在它的“模型地图”(Model Atlas)上看到各种各样的模型,就像在 GitHub 上看代码仓库一样。
你在图上看到那个巨大的圆圈吗?中心那一点,正是图像生成模型 Flux 的核心参数体积。
每当有人基于 Flux 微调出一个新模型,就像是给这棵演化树打上了新的 Git 提交。
一次 LoRA 微调,就是一次模型的分支——就像你在 Git 上拉出新的一条开发线。
Software 3.0 的到来:新范式,新电脑,新语言
然而,真正的颠覆才刚刚开始。我认为,在 Software 2.0 之后,我们迎来了又一次根本性的变革,我愿称之为 Software 3.0。
过去我们训练的神经网络,大多像“定制功能机”:识别图像、翻译句子、回答问题……每个模型都只擅长一件事。
它们不再是“预制功能块”,而是像 Unix 那样拥有模块和库,能编排、能组合,变得真正“可编程”。
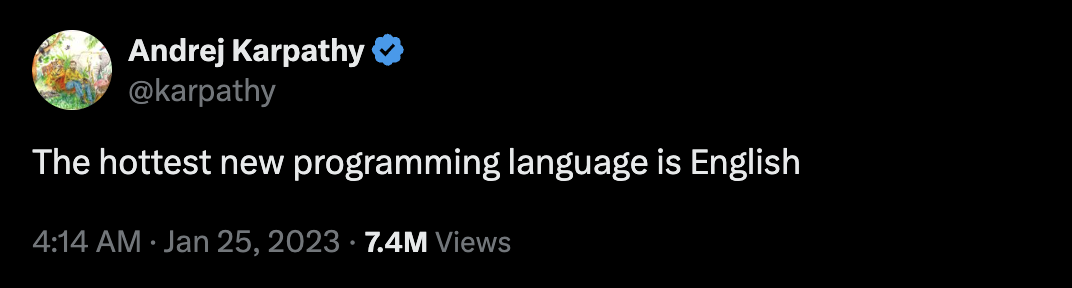
这一次,软件的核心变成了用自然语言(比如英语)“提示词”(Prompts)。这些提示词,正在编程一种全新的计算机——大型语言模型(LLM)。
过去,我们用 Software 1.0 的代码去编程计算机;后来,我们用 Software 2.0 的权重去编程神经网络;而现在,我们用 Software 3.0 的提示词去编程 LLM。
-
Software 1.0:你需要手写一堆 Python 代码和关键词规则来判断文本情感;
-
Software 2.0:你需要准备成千上万个正负面样本,训练一个二元分类器。
-
Software 3.0:你只需要写几句话,给 LLM 看几个例子,它就能明白你的意图并开始工作。
几年前,当我意识到这一点的时候,我感到非常震撼,并发布了那条非常著名的推文。
我们当时在做 Autopilot 自动驾驶系统。你可以想象一下,汽车的软件栈由底层是各种传感器输入(摄像头、雷达等)和顶层是输出(转向、加速等)组成。
刚开始,Autopilot 的软件栈里有海量的 C++ 代码,也就是 Software 1.0。同时,我们也用了一些神经网络(Software 2.0)来处理感知任务,比如图像识别。
但我们观察到一个非常有趣的趋势:随着 Autopilot 的能力越来越强,神经网络的部分在不断膨胀,变得越来越大、越来越强大。与此同时,那些传统的 C++ 代码正在被不断删除和替代。
很多原本由 Software 1.0 实现的功能,都被迁移到了 Software 2.0 的范畴里。
举个例子,像“融合多摄像头、多时间帧的图像信息”这样复杂的任务,以前需要用 C++ 写大量的逻辑,现在完全可以交给一个端到端的神经网络来完成。
所以,Software 2.0 的软件栈真的是在一点点“吃掉”(eating through)Software 1.0 的部分。彼时,我认为这是一个非常精彩的模式。
今天,同样的故事再次上演。一种全新的软件(Software 3.0)正在用一个完全不同的编程范式,开始吞噬整个软件栈。
如果你正准备进入软件行业,我强烈建议你要精通这三种软件范式。
因为它们各有优劣,所以在实际开发应用中,你需要灵活地做出选择。
AI 产品爆发,但你的痛点解决了吗?8.15-16 北京威斯汀·全球产品经理大 会 PM-Summit,3000+ AI 产品人社群已就位。
直面 AI 落地难题、拆解头部案例、对接精准资源!
扫码登记信息,添加小助手进群,抢占 AI 产品下一波红利:

进群后,您将有机会得到:
· 独家视频及文章解读 AGI 时代的产品方法论及实战经验
· 不定期赠送 AI 产品干货资料和秘籍
接下来我来聊聊 LLM,这个新范式、新生态到底是什么样?
为了理解 LLM 带来的变革,我们可以用几个类比:
类比 1:LLM 是新型“公共事业”(Utilities)
几年前,Andrew Ng(吴恩达)曾说“AI 是新的电力”。
我非常认同这个观点,因为它抓住了 LLM 的一个核心特质:LLM 确实越来越具备「公共事业(Utilities)」 的属性。
你看那些顶尖的 LLM 实验室,OpenAI、Google、Anthropic 等公司:
-
巨额资本投入(CAPEX):他们投入海量资金训练基础模型,这就像电力公司在建设电网;
-
API 即服务(OPEX):他们通过 API 向我们所有人提供“智能”服务;
-
按量计费:我们通过互联网接入,并按照“百万 Token”这样的单位付费,就像我们按度数支付电费一样;
-
服务要求:我们对这些 API 的要求——低延迟、高可用性——也和对电力的要求如出一辙。
在电力系统中,你会有个转换开关,可以在电网、太阳能、电池或发电机之间切换电力来源。
在 LLM 领域,我们现在有了像 OpenRouter 这样的工具,可以让你轻松地在不同类型的 LLM 之间切换。
更有趣的是,因为 LLM 是软件,它们不像发电厂那样需要物理空间。所以,你可以同时接入六家不同的“电力公司”(LLM 提供商),并随时切换,这在物理世界是不可想象的。
“公共事业”这个类比最传神的一点就是前几天我们刚刚经历的:当顶尖的 LLM 服务中断时,整个世界仿佛经历了一场“智能停电”(intelligence brownout)。人们突然发现自己寸步难行,无法工作。
这让我觉得非常奇妙。当电网电压不稳时,我们的生活会受影响;而现在,当 LLM 服务中断时,整个地球的“智商”似乎都降低了。
我们对这些模型的依赖程度已经非常高,而且我认为这种依赖还会急剧增长。
训练 LLM 也像建造芯片工厂,需要巨大的资本投入、尖端的技术研发和高度保密的“制程工艺”。
像 NVIDIA 这样的公司提供 GPU,扮演了“无厂半导体设计公司”(Fabless)的角色,而 Google 自研 TPU,则更像是拥有自己工厂的英特尔(Intel)。
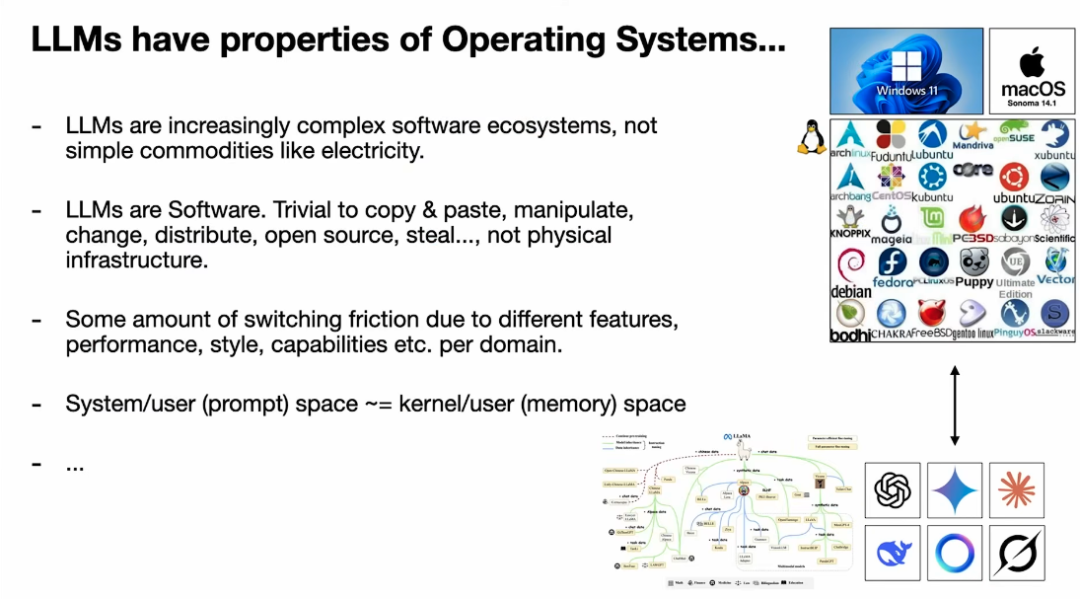
类比 3:LLM 是新时代的“操作系统”(Operating Systems)
这是我个人最喜欢的类比。LLM 远比电力或水这样的商品复杂,它更像一个复杂的软件生态系统。
这个生态的演化路径,也与操作系统的历史惊人地相似:
-
市场格局:我们看到少数几家强大的闭源提供商(如 Windows、macOS),同时存在一个充满活力的开源替代品(如 Linux)。在 LLM 领域,我们同样有少数几家顶尖的闭源模型,而 Llama 系列等开源模型正在扮演类似 Linux 的角色,快速追赶。
-
生态复杂度:这一切还只是开始。LLM 的未来远不止模型本身,还包括围绕它的工具链(tool use)、多模态能力等等,整个生态会变得越来越复杂。
当我意识到这一点时,我试着画了一张图来梳理我的思路。
-
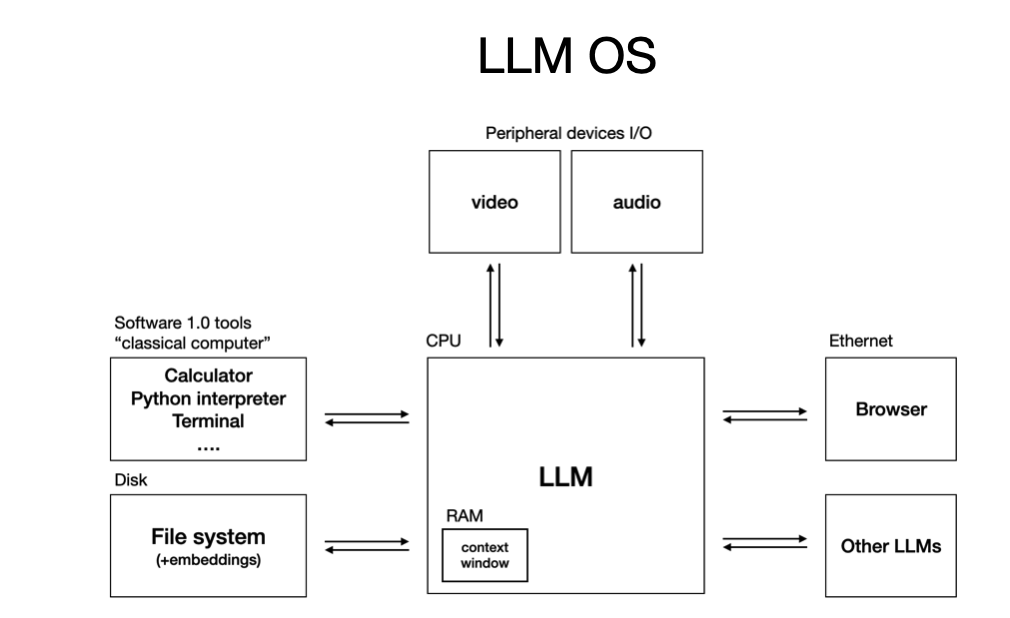
LLM 是新的 CPU:它扮演着中央处理器的角色,负责核心的计算和推理。
-
上下文窗口(Context Window)是新的内存(RAM):它决定了这台“电脑”能同时处理多少信息。
-
LLM 在编排一切:它调用各种能力(工具、知识),管理内存(上下文),最终解决复杂问题。
从这个角度看,LLM 的本质就是一种全新的、可编程的软件基础设施。
我们还可以从应用层面找到更多相似之处。比如,你想下载一个像 VS Code 这样的应用,你可以轻松地在 Windows、Linux 或 Mac 上运行它。
同样地,现在你也可以开发一个“LLM 应用”,比如 Cursor。
你可以让这个应用无缝地运行在 GPT、Claude 或 Gemini 等不同的 LLM “操作系统”之上,只需要一个下拉菜单就能切换。这是一种全新的跨平台能力。
我们正处在类似计算机的“1960 年代”——大型机与分时共享的时代。
那时的计算机是昂贵、中心化的主机,人们通过“终端”(Terminal)以分时共享的方式使用它。这和我们现在通过云端 API 与 LLM 交互的方式何其相似!
LLM 时代的“个人计算”(Personal Computing)革命尚未真正到来。因为目前在个人设备上运行强大的 LLM 还不经济,意义不大。
但我认为,已经有一些人在尝试了。事实证明,像苹果的 Mac Mini 这样拥有大统一内存的设备,非常适合运行某些 LLM,因为纯粹的批处理推理(batch-one inference)是高度内存密集型的。
这些都是“个人计算 2.0”即将到来的早期迹象。它最终会是什么样子,还不清晰。也许,在座的各位中,就有人会去定义它的形态、工作方式和未来。
我再提一个类比。每当我和 ChatGPT 这样的 LLM 直接用文本对话时,我感觉就像在通过“终端”(terminal)与一个操作系统交互。 这是一种直接、原生的访问方式。
而这个新“操作系统”的通用图形界面(GUI)——远不止一个聊天框那么简单——我认为尚未被真正发明出来。
然而,LLM 与以往所有技术都存在一个根本性的不同。我曾写过一篇文章,核心观点是:LLM 颠覆了技术扩散的传统路径。
回顾历史,无论是电力、密码学、计算机、还是 GPS,几乎所有变革性技术都遵循着一个路径:它们最初是昂贵、尖端的,首先被政府和大型企业(尤其是军事领域)所掌握,然后才逐步扩散到消费者市场。
早期计算机的主要用途是计算军事弹道,而不是帮你解决生活琐事。
但 LLM 完全反过来了。这项全新的、堪称神奇的计算机技术,一诞生就直接进入了消费市场。它首先是帮我解决“如何煮鸡蛋”这类问题的,而不是先去服务于什么国家级的军事弹道项目。
这太不可思议了!公司和政府反而成了追赶者,他们正在努力追赶我们这些普通消费者的使用步伐。整个技术扩散的箭头被反转了。这预示着,基于 LLM 的应用,其起点和演化路径将与以往任何技术都大相径庭。
你必须理解 LLM 的“心智”:一个有认知缺陷的超级学霸
在我们开始编程这些新计算机之前,我们必须花时间去理解它们到底是什么。我尤其喜欢谈论它们的“心理学”(psychology)。
我喜欢把 LLM 想象成“人的灵魂”(people spirits),它们本质上是在海量人类语料上训练出来的、对人类的随机模拟器。这个模拟器就是自回归的 Transformer。因为它们是基于人类数据训练的,所以它们也展现出了一种涌现出的、类似人类的“心智”。
-
超凡的记忆力(Encyclopedic knowledge/memory):它们像电影《雨人》(Rain Man) 里的主角,拥有百科全书般的知识和近乎完美的记忆力,能记住海量的细节。
-
认知缺陷(Cognitive deficits):
幻觉 (Hallucinations):它们会一本正经地“编造”事实,而且自己无法分辨真假。
参差不齐的智能 (Jagged intelligence):在某些领域它们是超人,但在另一些简单问题上却会犯低级错误,比如坚称“9.11 大于 9.9”或者“strawberry 里有两个 r”。你总会踩到一些意想不到的“坑”。
顺行性遗忘症 (Anterograde amnesia):这是最关键的缺陷之一。LLM 没有持续学习的能力,它们不会像人类一样通过“睡眠”来巩固知识、形成长期记忆和专业技能。它们的“上下文窗口”就是它们的全部工作记忆,一旦对话结束,它们就“失忆”了。这就像电影《记忆碎片》(Memento) 或《初恋50次》(50 First Dates) 的主角,每一天都是新的开始。
因此,与 LLM 协作,就像是与一个拥有超级记忆力但同时患有多种认知障碍的“学霸”共事。你必须非常清楚地管理它的工作记忆(上下文),才能让它为你高效工作。
我还要强调一点 LLM 的局限性,那就是安全问题。LLM 非常脆弱,极易受到提示词注入攻击(prompt injection),可能会泄露你的数据。这类安全问题层出不穷。
我们必须清楚,LLM 在某些方面超越人类,但在其他方面却可能存在严重认知缺陷。我们的任务是如何既能强化其优势,又能规避其风险,并设计出可靠而高效的应用方案。
机会一:构建“部分自治应用”(Partial Autonomy Apps)
接下来,我将聚焦于“可控自主”应用的设计思路,以及现阶段最具代表性的示例。
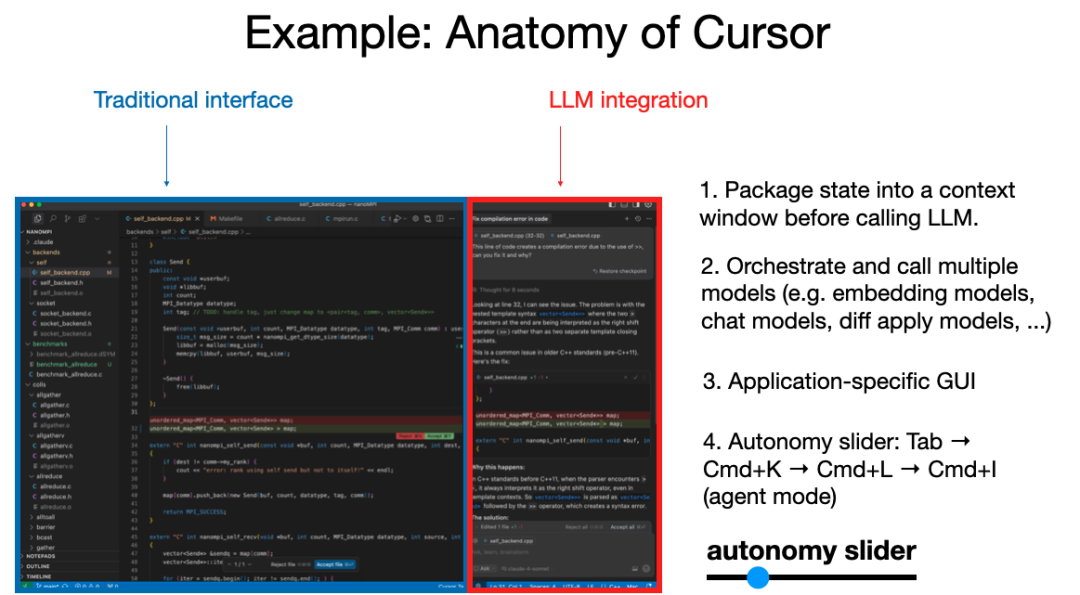
以编程为例——与其直接向 ChatGPT 发送一长串代码块,然后反复粘贴测试,不如选择专为 AI 编程设计的工具。例如,Cursor 就是一个典型代表。
-
-
多模型协作:背后可能同时驱动多个模型协同处理,如文件管理、逻辑检查等;
-
图形化界面:用户无需通过文本输入命令,而是通过颜色提示、审批按钮等直观操作来控制修改与确认;
-
自主程度可调:Cursor 提供“自主滑块”,用户可选择执行不同范围的更新,从局部改动到整体重构,甚至自主研究功能与审批流程。
这类应用的设计理念是——让 AI 在可见范围内有效合作,并确保人类随时可介入监督。
-
加速验证流程:利用图形界面让人直观识别 AI 修改,减少仅凭文字判断的认知负担;
-
确保人类监督节奏:即使模型生成代码,也必须有人工复核,防止引入漏洞或安全风险。
我的经验是,编程过程中最好采用“小步提交”的策略:每次仅让 AI处理少量代码,以便快速验证并保持控制权。
类似原则也适用于教育场景。假设我们用 AI 协助教师生成课程内容并供学生学习,最佳方案是采用“双应用结构”:
这样不仅保留了 AI 的效率,也能通过中间产物(课程方案)进行质量审核。我们避免让 AI“自由发挥”,而是将其“拴在”既定课纲与流程内。
实践中,我也曾参与开发特斯拉的半自主驾驶系统,该系统中仪表板会显示 AI 权重的决策状态,并允许人类及时介入。
我的第一次自动驾驶体验是在 2013 年,那次出行过程几乎完美,但之后十多年里,我们仍在逐步完善——这是一个漫长的“从网络模型到产品”的过程。
无论是自动驾驶,还是 AI 驱动的软件,都存在“从模型到产品”的鸿沟:算法能否稳定输出,并在复杂场景中反复执行,这才是胜负关键。
因此,关于“2035 年全面进入 Agent 时代”的预测,我保持谨慎态度。Agent 的确是未来方向,但我们必须实事求是、稳健前行。
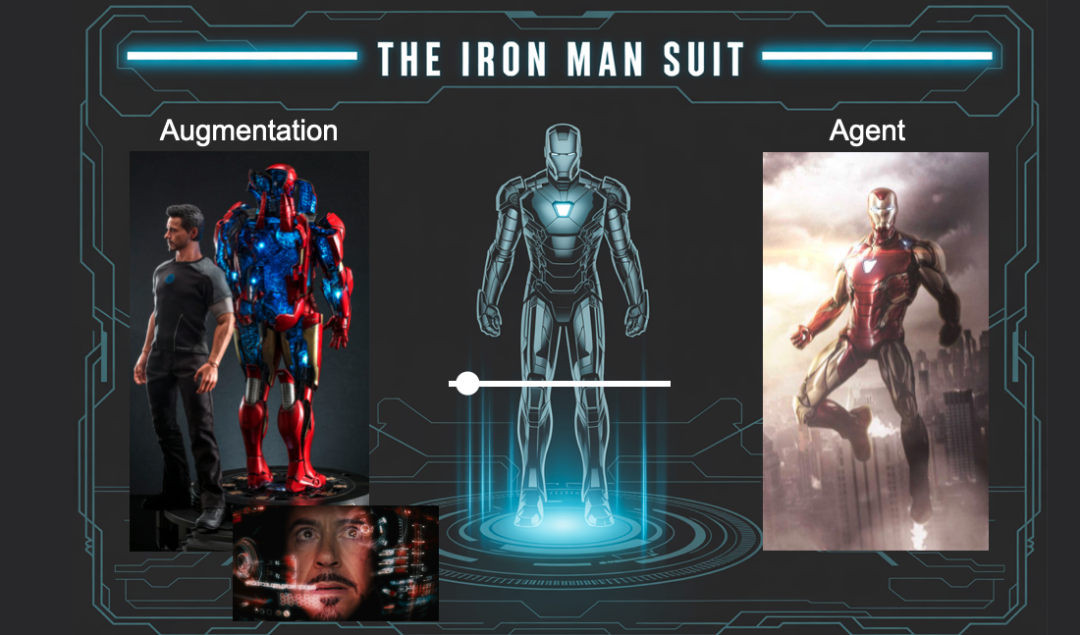
在思考人与 AI 的协作未来时,我常常想到《钢铁侠》——不仅因为它酷炫,更因为它道出了技术发展的真实轨迹。
钢铁侠的战衣,是对人类能力的增强,是人机之间的深度融合。它既赋予托尼·斯塔克超越常人的力量,也始终保留着人的主导地位。这套战衣既可以部分自主执行任务,也可以完全受控于驾驶者,这正像我们今天面对的大模型:它既可以是“智能助手”,也可能演变为“自主体”。
但至少在现阶段,我认为我们更应打造的是“增强套装”——帮助人类提效、扩展能力的工具,而不是那些华而不实的全自动“炫技”Agent Demo。
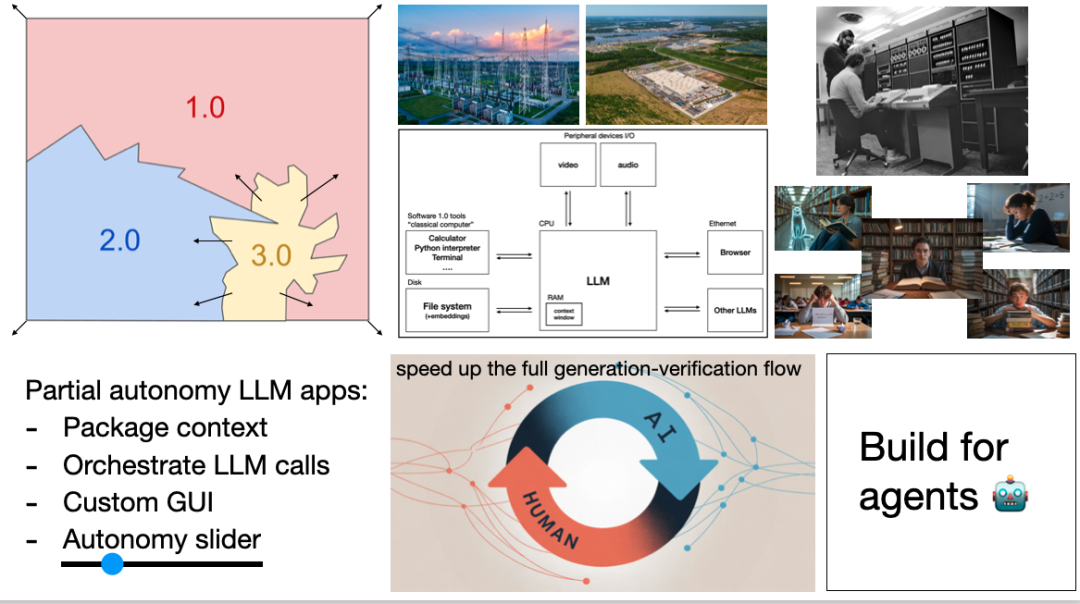
我们的目标应是打造“部分自主”的产品,而非让 AI 全权接管。
这样的产品设计有一个关键思想:为每一位用户配备一个“自主滑杆”,让他们可以根据需求,灵活控制 AI 的自动化程度。从命令辅助,到任务执行,再到半自主完成,逐步演进,而不是一蹴而就。
更深层次的变革在于:我们正在进入一个“人人可编程”的时代。
传统软件开发的门槛很高,你需要五到十年的专业训练,才能驾驭一门编程语言。而现在,一切的入口变成了“自然语言”——尤其是英语。
这不仅仅是编程语言的变革,更是“人与机器对话方式”的范式转移。当我们用英语与大模型交流时,我们本质上已经在“写程序”。在某种意义上,每一个会说话的人,都是一位潜在的程序员。这前所未有,也极具颠覆性。
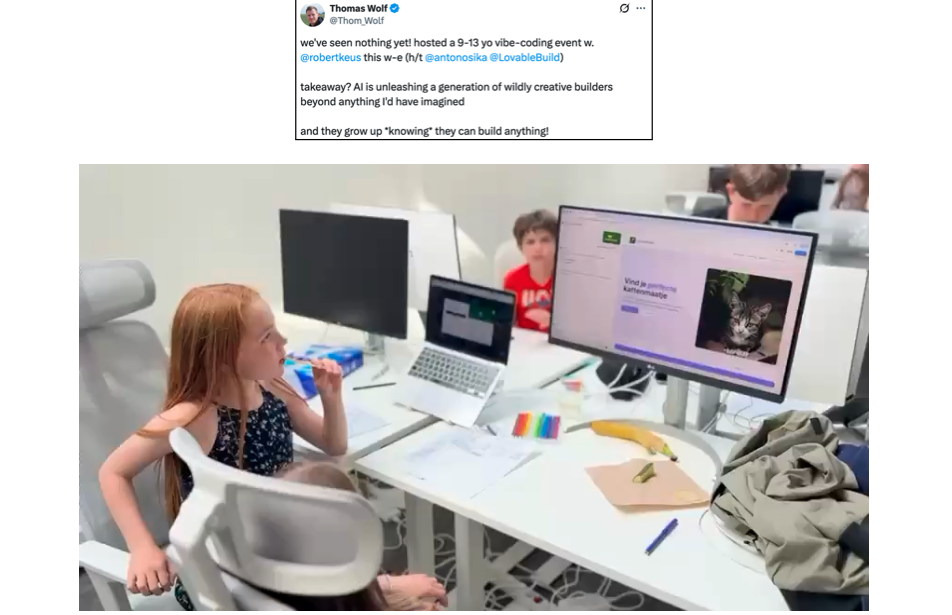
我曾发过一条推文,内容简单,但没想到被大量网友转发、二创,谈的正是“人人编程”的未来。
Tom Wolfe(Hugging Face)曾分享一段令人动容的视频:一群孩子在“vibe coding”。看着他们欢快地调试、搭建、试错,我由衷感到乐观——如果这是下一代软件开发者的起点,那么未来一定值得期待。
我自己也试着“vibe coding”了一次,在一个周末构建了一个 iOS 小应用。虽然我不懂 Swift,但借助 AI 的帮助,我依旧快速搭好了界面,跑起来了。体验非常震撼。
后来,我又动手开发了一个名叫“MenuGem”的小程序。
灵感很简单:每次进餐馆拿到菜单时,我总是一脸茫然。于是我写了一个应用,拍一张菜单照,它就会生成每道菜的图示。想法朴素,开发轻松,用户注册还能送 5 美元免费额度。但说实话,这成了我人生第一个“负营收”项目。
但真正令我印象深刻的,不是代码的部分——而是上线应用时那段“非编码”的痛苦旅程。
你想让它上线?那你得注册域名、配置支付系统、搞定身份验证、接入 Google 登录……不是写代码,而是在无数网页界面中点来点去、填表点击,照着文档走流程。
就像一台计算机在指着你鼻子说:“去点这个、选那个、改这里。”
从“写代码”到“构建产品”:AI 尚未涉足的真实难题
MenuGem 给我最深的感受是:写代码反而是最简单的部分。真正耗费心力的,是让它成为一个“真实”的产品——你得搞定身份认证、支付系统、域名部署等等。而这些,几乎都不是写代码能解决的,更多的是你一个人在浏览器里“点来点去”的苦活累活。
在演讲的最后一部分,我提出了一个核心问题:“我们能否专为 Agent 构建系统?”
粗略地讲,我认为出现了一种全新的数字信息消费者和操纵者。
-
-
-
全新的物种:Agents。它们是计算机,但行为方式又像人类。或者说,它们是互联网上“人的灵魂”(people spirits)。
那么,我们是否应该为它们量身构建、更易理解、更易调用的系统框架?
-
从 robots.txt 到 llms.txt:就像 robots.txt 文件用来指导网络爬虫一样,我们可以创建一个 llms.txt 文件。这只是一个简单的 Markdown 文件,用来告诉 LLM 这个网站是关于什么的。这对于 LLM 来说非常易读。如果让它自己去解析网页的 HTML,那将非常容易出错,而且很可能失败。直接告诉它,效率高得多。
-
重构文档,使其对 LLM 友好:一些领先的公司,比如 Vercel 和 Stripe,已经开始将他们的文档转向对 LLM 友好的格式了。他们不仅提供 Markdown 格式的文档——这对于 LLM 来说已经非常好了——他们甚至更进一步。
-
将“点击”行为替换为“代码”:在他们的文档里,任何需要“点击”的地方,Vercel 都在尝试用等效的 cURL 命令来替代。因为 LLM 无法“点击”,但它可以执行代码。这是一个非常有趣且重要的转变。
-
为 Agents 设计协议:Anthropic 提出的模型上下文协议(MCP)是另一个很好的例子。它是一种直接与 Agents 对话的协议,定义了一种新的消费者和商业应用模式。我非常看好这个方向。
我非常喜欢那些能将现有数据转换成 LLM 友好格式的小工具。我称之为“上下文构建器”(Context builders)。
例如,一个 GitHub 仓库,它的界面是为人类设计的,你不能直接把一个 URL 扔给 LLM 让它去理解。但现在有了像 Gitingest 这样的工具,你只需要在 URL 里把 github.com 换成 gitingest.com,它就能自动把整个仓库的代码文件、目录结构打包成一个巨大的、结构化的文本块,让你能直接复制粘贴给 LLM。
更进一步的例子是 Devin 的 DeepWiki。它不只是简单地打包文件内容,它会运行一个 Agent 去分析整个代码库,然后为你生成一份高质量的、包含系统架构图和代码依赖关系的文档。这对于让 LLM 理解一个复杂项目非常有帮助。
我喜欢所有这些“改变一个 URL”就能让世界对 LLM 更友好的小工具,我认为这个领域未来可期。
-
海量的软件将被重写:无论是专业开发者还是“Vibe Coder”,每个人都将参与其中。
-
LLM 是新时代的操作系统:它们像公共事业,像芯片工厂,但最核心的,它们是计算机的“1960年代”,一切都将被重新定义。
-
我们与“人的灵魂”协作:这些 LLM 是不可靠的、有认知缺陷的“人的灵魂”,我们需要学会如何与它们高效协作。
-
构建“部分自治”产品:核心是加速**“AI生成-人类验证”**的循环,通过定制化的 GUI 和“自治滑块”来实现。
-
为 Agents 构建基础设施:这是另一个巨大的机会,让数字世界对 LLM 更加友好。
最后,回到钢铁侠战衣的类比。我认为,在接下来的十年里,我们将要去做的就是把那个“自治滑块”,慢慢地从左边的“增强”推向右边的“自主”。
我很期待看到这一切将如何发生,并希望能与在座的各位一起,共同构建这个未来。
(文:AI科技大本营)