
在当今快速演变的人工智能(AI)领域,紧跟最新发展可能具有挑战性。因此,我开发了一款AI新闻聚合器应用程序,用于在单一便捷位置整理和呈现最相关的人工智能新闻。本文将带您了解我是如何创建这个应用程序的,以便您也可以为任何感兴趣的主题构建自己的专业新闻聚合器。

如果您喜欢这篇文章请点赞、转发、推荐并关注本公众号

为什么我要构建这个应用?
作为一名人工智能爱好者和开发者,我发现自己每天花费数小时浏览不同的网站、论坛和社交媒体平台,以保持对AI进展的了解。这个耗时的过程激发了我创建集中式平台,自动收集和整理AI新闻,为自己和社区中的其他人节省宝贵时间。
在开始之前,我欢迎您提出改进这个项目的所有建议。如果您有不同的资源或实现建议,可以在评论中写下以支持它们。
项目概述
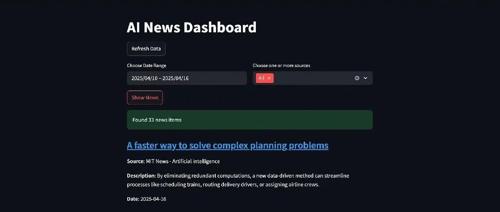
Latest AI News 应用程序:
•从多个专注于人工智能的来源聚合新闻•按来源对内容进行分类•提供简洁、用户友好的界面以浏览最新更新•定期更新以确保内容保持当前和相关
您可以关注公众号并回复 2234 获取本文所涉及到的源码。
项目结构
项目由两个主要的Python文件组成:
•fetch_data.py – 处理从RSS feed中收集数据•main_page.py – 包含Streamlit web应用程序代码
让我们深入了解每个组件,理解它们如何协同工作。
数据收集
数据收集模块负责从多个RSS feed获取AI新闻,清理数据并准备用于显示。
import feedparserimport pandas as pdfrom datetime import datetime, timedeltaimport sslfrom bs4 importBeautifulSoupimport warningsimport concurrent.futuresimport re
SSL配置
if hasattr(ssl,'_create_unverified_context'):ssl._create_default_https_context = ssl._create_unverified_context
此代码禁用SSL验证,这对于某些可能存在证书问题的RSS feed是必要的。
并行获取RSS feed
我实现的一个关键优化是并行获取RSS feed:
def fetch_single_feed(link_source_tuple):"""获取单个RSS feed并返回其条目"""link, source = link_source_tupleentries ={"Title":[],"Link":[],"Published":[],"Description":[],"Source":[]}try:feed = feedparser.parse(link)for entry in feed.entries:entries["Title"].append(entry.get("title","No Title"))entries["Link"].append(entry.get("link","No Link"))entries["Published"].append(entry.get("published","No Date"))entries["Description"].append(entry.get("description","No Description"))entries["Source"].append(source)exceptExceptionas e:print(f"Error fetching {link}: {e}")return entriesdef fetch_feed(links):"""并行获取多个RSS feed"""all_entries ={"Title":[],"Link":[],"Published":[],"Description":[],"Source":[]}# 使用ThreadPoolExecutor并行获取feedwith concurrent.futures.ThreadPoolExecutor(max_workers=10)as executor:future_to_link ={executor.submit(fetch_single_feed,(link, source)):(link, source)for link, source in links.items()}for future in concurrent.futures.as_completed(future_to_link):link, source = future_to_link[future]try:result = future.result()# 将结果合并到all_entries中for key in all_entries:all_entries[key].extend(result[key])exceptExceptionas e:print(f"Exception for {link}: {e}")# 从所有条目创建DataFramedf = pd.DataFrame(all_entries)return df
通过使用 concurrent.futures.ThreadPoolExecutor,我可以同时获取多达10个RSS feed,这显著减少了应用程序的总加载时间。
数据清理与处理
从RSS feed获取的原始数据需要进行大量清理:
def clean_html(text):"""从文本中清理HTML标签"""try:soup =BeautifulSoup(text,"html.parser")return soup.get_text()exceptExceptionas e:print(f"Error cleaning HTML: {e}")return textdef extract_date(date_str):"""使用正则表达式模式从多种格式中提取日期"""try:# 尝试匹配不同日期格式的模式# 模式1:标准RFC格式,如 "Mon, 14 Apr 2025 10:00:00 GMT"pattern1 = r'(?:\w+,\s+)?(\d{1,2}\s+\w{3}\s+\d{4})'match = re.search(pattern1, date_str)if match:date_str = match.group(1)return pd.to_datetime(date_str, format='%d %b %Y')# 模式2:简单格式,如 "14 Apr 2025"pattern2 = r'(\d{1,2}\s+\w{3}\s+\d{4})'match = re.search(pattern2, date_str)if match:return pd.to_datetime(match.group(1), format='%d %b %Y')# 模式3:ISO格式,如 "2025-04-14"pattern3 = r'(\d{4}-\d{2}-\d{2})'match = re.search(pattern3, date_str)if match:return pd.to_datetime(match.group(1))# 如果没有匹配任何模式,返回NaTreturn pd.NaTexcept:return pd.NaT
日期提取函数使用正则表达式模式来处理来自不同RSS feed的各种日期格式。这是因为不同新闻来源的日期格式各不相同。
最终数据处理
在收集了feed数据后,我应用了几个处理步骤:
def extract_and_clean_data(df):"""处理和清理feed数据"""if df.empty:return dftry:# 应用自定义日期提取函数df['date']= df['Published'].apply(extract_date)# 删除无效日期的行df = df.dropna(subset=['date'])# 删除原始的'Published'列df.drop(columns=['Published'], inplace=True)# 筛选过去7天的新闻today = datetime.now()seven_days_ago = today - timedelta(days=7)df_filtered = df[(df['date']>= seven_days_ago)&(df['date']<= today)]# 按日期降序排序df_filtered = df_filtered.sort_values(by='date', ascending=False)# 清理HTML并限制描述长度df_filtered['Description']= df_filtered['Description'].apply(lambda x: clean_html(x)[:500].replace("\n",""))return df_filteredexceptExceptionas e:print(f"An error occurred while processing the data: {e}")return pd.DataFrame()
此函数:提取标准化的日期,筛选过去7天的新闻,按日期降序排序,清理描述中的HTML并将其截断至500个字符。
新闻来源
我创建了一个AI新闻来源(RSS feed)列表:
def main():# RSS链接links ={"https://bair.berkeley.edu/blog/feed.xml":"伯克利人工智能研究博客","https://feeds.feedburner.com/nvidiablog":"NVIDIA博客","https://www.microsoft.com/en-us/research/feed/":"微软研究","https://www.sciencedaily.com/rss/computers_math/artificial_intelligence.xml":"科学日报","https://research.facebook.com/feed/":"META研究","https://openai.com/news/rss.xml":"OpenAI新闻","https://deepmind.google/blog/feed/basic/":"谷歌DeepMind博客","https://news.mit.edu/rss/topic/artificial-intelligence2":"MIT新闻 - 人工智能","https://www.technologyreview.com/topic/artificial-intelligence/feed":"MIT技术评论 - 人工智能","https://www.wired.com/feed/tag/ai/latest/rss":"Wired:人工智能最新动态","https://raw.githubusercontent.com/Olshansk/rss-feeds/refs/heads/main/feeds/feed_ollama.xml":"Ollama博客","https://raw.githubusercontent.com/Olshansk/rss-feeds/refs/heads/main/feeds/feed_anthropic.xml":"Anthropic新闻",}df = fetch_feed(links)final_df = extract_and_clean_data(df)return final_df
这些来源包括主要的AI研究实验室、科技公司和权威技术新闻媒体。
我无法找到一些公司博客的RSS feed。如果您知道相关信息,请在评论中分享。
使用Streamlit构建Web界面
main_page.py 文件使用Streamlit创建一个用户友好的仪表板:
import streamlit as stimport pandas as pdfrom datetime import datetime, timedeltafrom fetch_data import main# 使用Streamlit内置缓存@st.cache_data(ttl=60)# 缓存1分钟def get_data():with st.spinner('正在获取最新的AI新闻...'):return main()def run_dashboard():st.title("AI新闻仪表板")# 添加刷新按钮if st.button("刷新数据"):# 清除缓存并获取新数据st.cache_data.clear()st.rerun()# 使用缓存加载数据try:df = get_data()# 检查df是否为空if df.empty:st.error("暂无新闻数据可用。请稍后尝试刷新。")return# 获取最小和最大日期min_date = df['date'].min()max_date = df['date'].max()# 创建两列布局col1, col2 = st.columns(2)with col1:selected_dates = st.date_input("选择日期范围",value=(min_date, max_date),min_value=min_date,max_value=max_date)# 处理单个日期选择if len(selected_dates)==1:start_date = selected_dates[0]end_date = selected_dates[0]else:start_date, end_date = selected_dateswith col2:# 获取唯一来源all_sources = sorted(df['Source'].unique().tolist())# 在列表开头添加“全部”选项source_options =["全部"]+ all_sources# 使用多选框selected_sources = st.multiselect("选择一个或多个来源",options=source_options)# 显示按钮if st.button("显示新闻", key="show"):ifnot selected_sources:st.error("请至少选择一个来源以显示新闻。")else:# 将日期转换为datetimestart_date = pd.to_datetime(start_date)end_date = pd.to_datetime(end_date)# 按日期范围过滤df_filtered = df[(df['date']>= start_date)&(df['date']<= end_date)]# 处理“全部”选项if"All"in selected_sources:# 如果选择了“全部”,不过滤来源passelse:# 按选定来源过滤df_filtered = df_filtered[df_filtered['Source'].isin(selected_sources)]# 显示结果if len(df_filtered)>0:st.success(f"找到 {len(df_filtered)} 条新闻")# 以卡片形式显示新闻for index, row in df_filtered.iterrows():st.markdown(f"### [{row['Title']}]({row['Link']})")st.write(f"**来源**: {row['Source']}")st.write(f"**描述**: {row['Description']}")st.write(f"**日期**: {row['date'].strftime('%Y-%m-%d')}")st.markdown("---")# 在卡片间添加分隔线else:st.warning("未找到符合所选条件的新闻。请调整日期范围或来源选择。")exceptExceptionas e:st.error(f"发生错误:{str(e)}")st.info("请尝试使用上方的刷新按钮。")if __name__ =='__main__':run_dashboard()
@st.cache_data 装饰器将结果缓存60秒,通过防止不必要的RSS数据重新获取来提高性能。
用户可以按日期范围和来源过滤新闻,便于找到相关内容。
每条新闻以卡片形式显示,包含可点击的标题、来源信息、描述和日期。

结论
构建AI新闻聚合器为我提供了处理RSS feed、数据处理以及使用Streamlit创建交互式Web应用程序的实践经验。最终的仪表板提供了一种便捷的方式,让人们能够及时了解快速发展的AI领域。

(文:PyTorch研习社)