

勿勿之间,2025年已近过半。而你要是还没听过AI Agent,那简直就跟没上过网一个样。
从科技巨头到创业新贵,几乎人人都将Agent挂在嘴边,描绘着一个能自动处理邮件、预订行程、管理生活的智能未来。
这,汹涌得让人兴奋,也喧嚣得让人迷惑。
可现实呢?
说实话,我一直对“通用Agent”能真正落地解决复杂问题持怀疑态度。
让它写一首唐诗、画一幅赛博朋克风的画,它能做得很好。但你让它帮你搞定一张去欧洲的、含两次换乘的、还想累积星空联盟里程的复杂机票?

这背后隐藏的,是人类旅行者心照不宣的无数个隐性知识点:它不知道,为了省钱,从首尔转机可能比直飞便宜三千块,但这需要额外留意过境签证的政策;它不理解,分开买两段廉航的单程票,有时比买一套往返票的总价更低,但这潜藏着行李无法直挂和转机失败的风险;它更不会提醒你,虽然这张票能累积里程,但因为是特价舱位,累积的比例可能只有25%,远不如另一张贵两百块的票划算。
面对这些糅合了经验、风险权衡和隐性知识的决策,通用Agent只能投降。它大概率会给你一堆搜索链接,然后礼貌地说:“建议您访问以下网站进行查询。”

这种体验,精准地暴露了当前AI Agent落地的“最后一公里”困境。它不是理解语言的最后一公里,而是从“理解”到“执行”的最后一公里。
一个真正的智能体,不仅要“听得懂”人的指令,更要能像人一样“看得懂”我们这个五花八门的互联网界面,“想得明白”完成一个任务需要哪些步骤,最重要的是,能“动得了手”去精确地点击、输入、交互。
这三点,恰恰是通用大模型能力的“无人区”。

就在我几乎要将“能干活的Agent”归为又一个“PPT概念”时,一家来自杭州的团队——iMean AI,进入了我的视野。他们声称,已经用一种叫做“后训练”(Post-Training)的方法,跑通了这最难的“最后一公里”。
这,是一次真正的技术突破,还是又一个被过度包装的故事?
带着这个疑问,我决定深入地挖一挖,不仅要看它做到了什么,更要拆解它到底是如何做到的。
实战大考
为了测试iMean AI是否真的跑通了“最后一公里”,我没有给它出选择题,而是直接上了两道堪称“地狱级”的应用题。这些任务糅合了普通用户最头疼的各种约束,旨在挑战它在真实世界中的规划与执行能力。
极限任务一:欧洲音乐节“极限腾挪”
我给它的第一个难题是:假设我是一个预算有限的学生,想在7月份,用最经济、最高效的方式,先后参加分别位于西班牙(Benicàssim音乐节)和比利时(Tomorrowland)的两个小众音乐节。
这背后意味着跨国、跨节、预算和住宿都极度受限。这要是靠人肉搜索,等于要同时打开廉航、火车、大巴、酒店、地图等至少六个网站,在无数个排列组合中计算最优解,堪称“人肉CPU”的噩梦。
而iMean AI的操作,堪称“微操”艺术:
-
动作1:多维信息同步抓取 指令下达的瞬间,我仿佛看到了一个科幻电影里的场景:AI像开了无数个分身,同时“打开”了瑞安航空、Flixbus、Trainline等多个欧洲主流票务网站。它并非简单地访问,而是在实时抓取每一个平台上的价格、时刻表和余票信息,将这些动态的数据流瞬间汇集到自己的“决策中枢”。
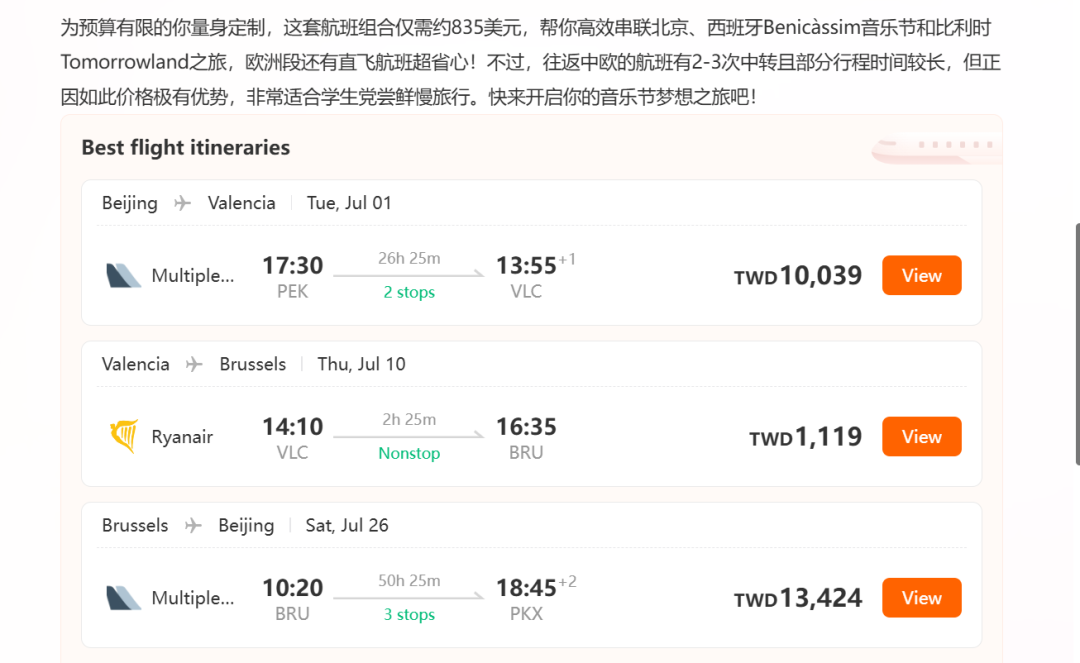
-
动作2:智能路径计算与剪枝 更关键的是第二步。面对数据库里几十种可能的换乘方案,它展现出了惊人的“商业智能”。它能快速剪掉那些“看似便宜但路上要耗一天”或“看似快捷但价格离谱”的无效选项,在短短十几秒内,就将繁杂的可能性收敛,性价比最高的方案供我选择。

-
动作3:关联决策与动态推荐 而最让我惊叹的,是它的关联决策能力。在推荐从西班牙到比利时的交通方案时,它没有孤立地推荐最便宜的车票,而是将每个交通方案的终点站,与周边一小时交通圈内的住宿价格和评分进行了动态关联。最终,它给出的最优解是“乘坐廉航 + 转乘火车,入住距离主会场20分钟车程的邻近小镇旅馆”,并明确标注出,这个“交通+住宿”的总成本,比住在主城区的方案低了整整40%。
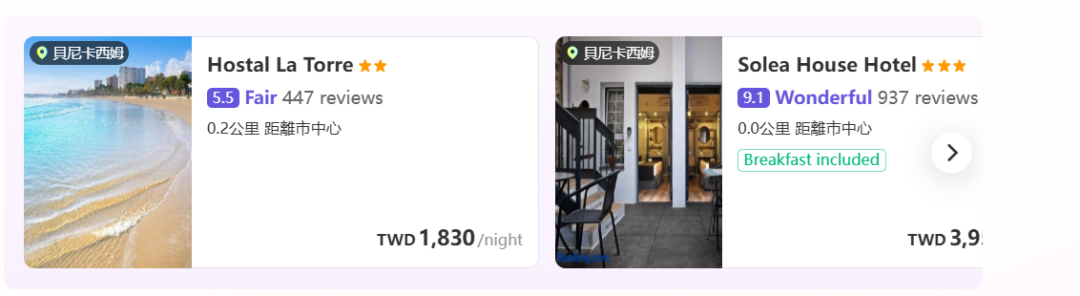
极限任务二:横跨两大洲的“带娃美食家”之旅
如果说第一个任务考验的是“极限省钱”,那第二个任务,则考验的是“极致体贴”。
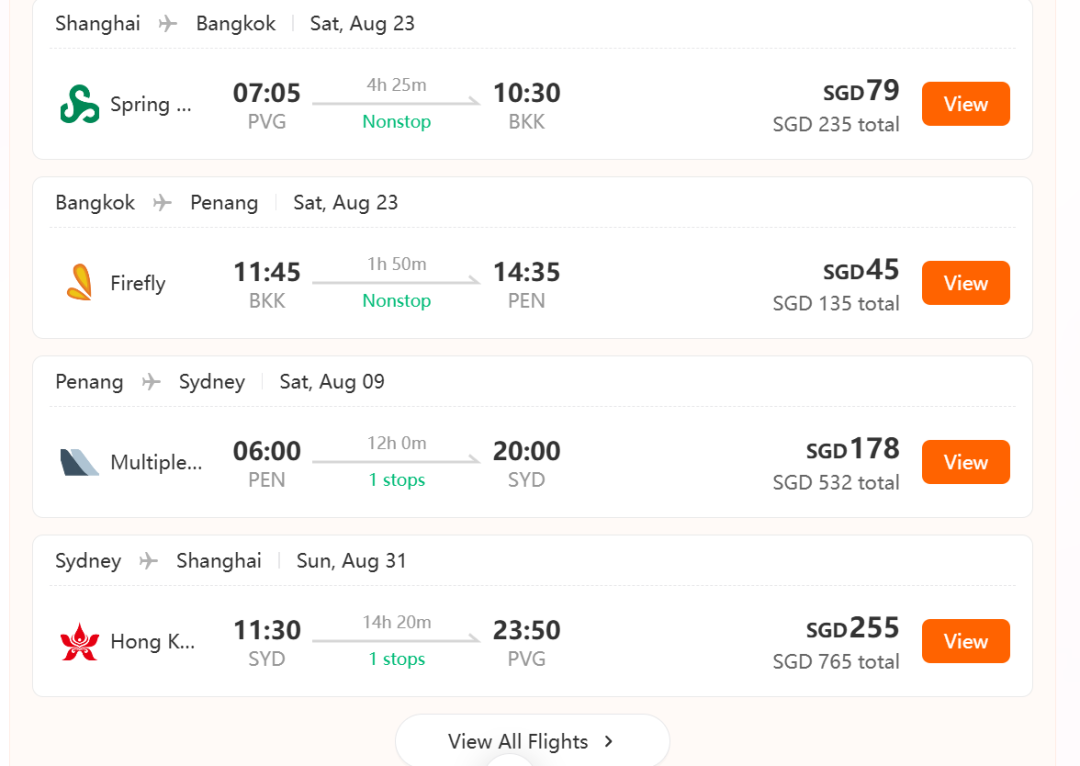
我给它的设定是:一家三口(带一个2岁宝宝)8月从上海出发,要去马来西亚槟城吃街头美食,要去曼谷一家指定的米其林餐厅,最后还要飞到悉尼探望亲戚。这其中包含了跨大洲、多国、亲子、美食、探亲等多重目标。
iMean AI再次展示了它远超“规划”的“执行”能力:
-
动作1:全局最优路径规划 首先,它并没有机械地按照我输入的“槟城→曼谷→悉尼”顺序进行规划。而是通过对全球航线网络的理解和实时票价的分析,立刻给出了“上海→曼谷→槟城→悉尼”的更优飞行顺序,仅此一步,就为整个行程节省了近三千元的机票费用。
-
动作2:基于用户偏好的深度筛选 其次,“带娃”这个简单的词,在AI眼里被拆解成了无数个具体的约束条件。它在筛选数百个航班时,不仅考虑了起降时间,甚至还尽量引入了“大型宽体客机(飞行更平稳,噪音小)”、“红眼航班(可让孩子在机上睡觉,不影响白天玩乐)”等隐性偏好进行加权排序。这种深度共情能力,已经远超普通票务平台的筛选器。
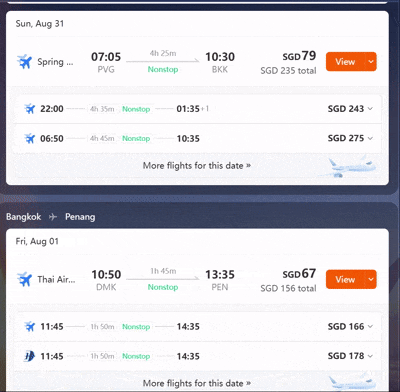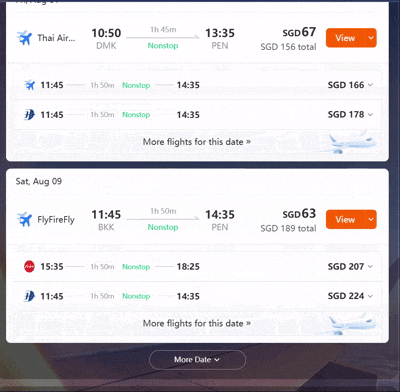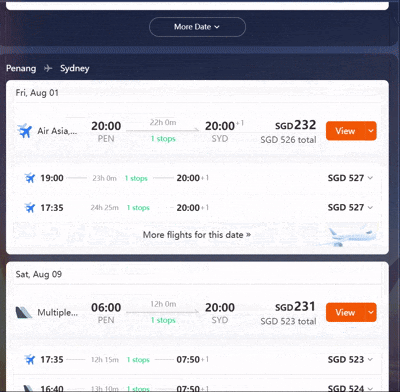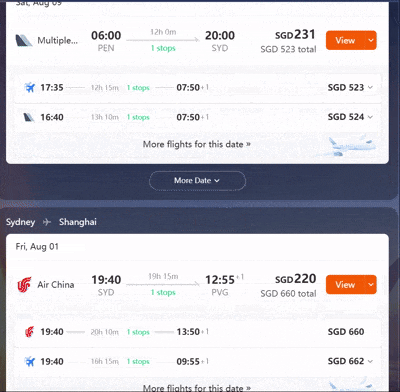
-
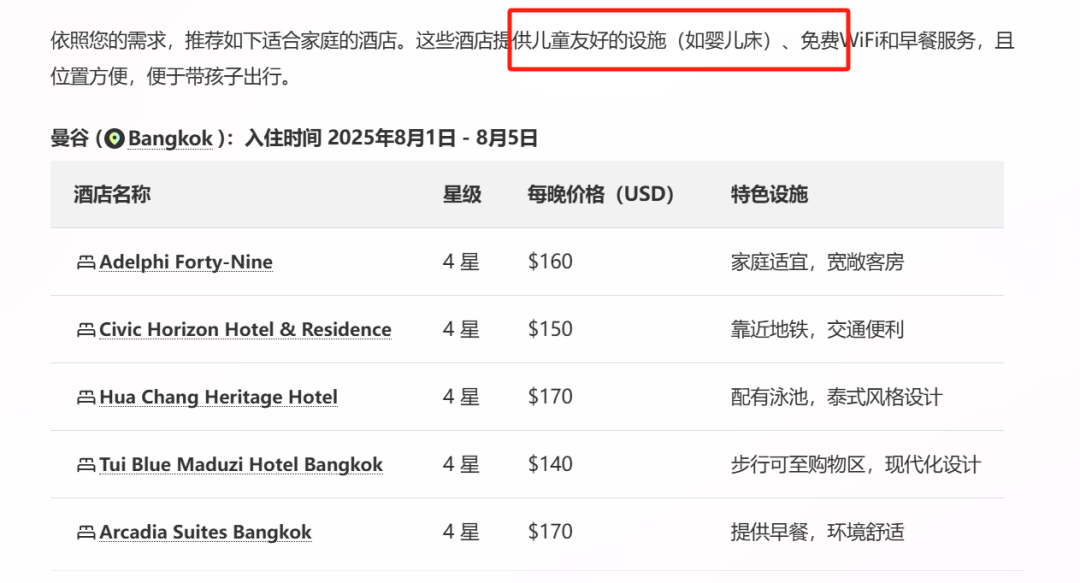
动作3:跨平台状态验证与执行 但真正让我确认它不是“PPT概念”的,是这最后一步:跨平台状态验证与执行。在初步锁定行程后,它竟然主动去我们选定的酒店官网,交叉验证了是否有“婴儿床”服务;同时,它访问了那家曼谷米其林餐厅的在线预订系统,查询并锁定了我们行程中唯一可用的一个晚餐空位,然后将这两个“已确认”的状态信息,清晰地汇总在最终的行程单上。
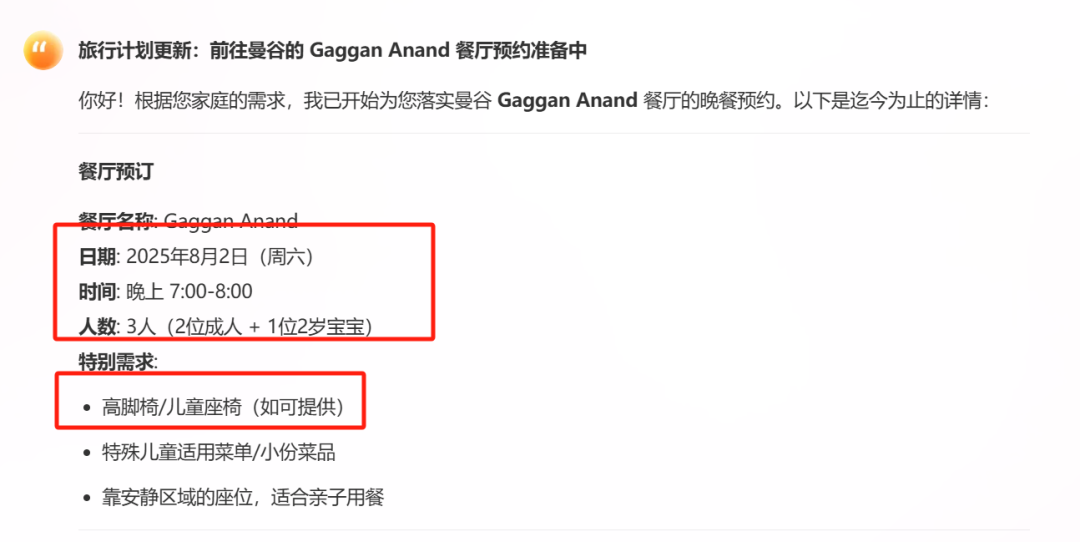
看到这里,相信你也已经明白——
iMean AI 做的,并不是信息的“搬运工”,而是一个真正的“任务执行官”。它不仅能提供方案,更还能深入到真实世界的网络环境中,处理那些琐碎、动态、且相互关联的细节。
那么,它究竟是如何做到的?
这背后,到底藏着怎样的技术“魔术”呢?
从“骨架”到“灵魂”的诞生之路
iMean AI的强大之处在于其“执行力”——
这种能力,并非单一技术的突破,而是由一套环环相扣的核心技术逻辑所支撑。我们可以将其归纳为三大要点:
核心技术架构:一个“感知-规划-行动-学习”的闭环系统
第一层:观察模型 (Observation Model) – 从网页到结构化状态的“世界感知层”
挑战: 网页的本质是高维、嘈杂的DOM树(文档对象模型)与视觉元素的混合体,直接输入给大语言模型(LLM)进行处理,效率极低且难以收敛。
iMean的解法:
观察模型是一个多模态信息融合的模块。它不仅解析DOM树的结构化代码,更结合网页的视觉渲染信息(Visual Rendering),像人一样理解布局。这种“代码+视觉”的双重感知,使其能够鲁棒地处理各种前端框架,甚至是iFrame和Shadow DOM这类传统自动化技术的难点。
最终,它将高维、混乱的网页信息,表征(Represent)成一个低维、干净、机器可读的结构化状态(Structured State),供上层模型决策。
举个订机票的例子:当它打开一个复杂的航司官网时,它不仅“看到”了“出发地”和“目的地”这两个输入框,还能立刻“理解”它们需要填写城市名;它能识别出那个日历图标是用来选择日期的,并且知道那一长串航班列表里,哪一列是价格,哪一列是中转次数。混乱的界面在它眼中,变成了一张条理清晰的数据表。
第二层:规划模型 (Planning Model) – 意图理解与任务拆解的“策略大脑层”
挑战: 如何将用户模糊、高层次的意图(如“找最便宜的走法”)转化为机器可以执行的、精确的步骤序列。
iMean的解法:
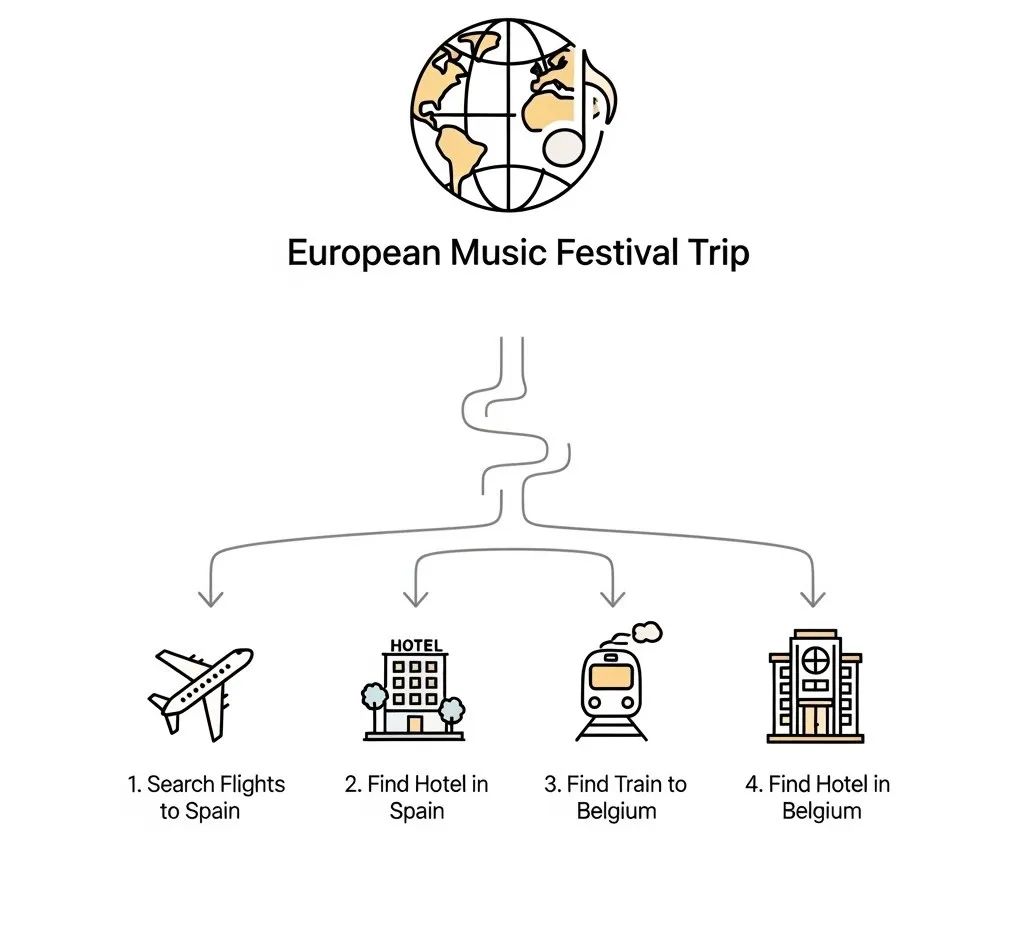
规划模型通常由一个经过领域微调的大语言模型(Fine-tuned LLM)担当。它接收观察模型传来的“结构化状态”,并作为系统的高层策略生成器(High-level Policy Generator)。它的核心任务是将用户意图拆解(Decompose)成一个逻辑清晰的子目标序列(Sequence of Sub-goals)。
例如,它会将“预订欧洲音乐节之旅”拆解为:1.搜索去西班牙的机票;2.搜索当地住宿;3.搜索西班牙到比利时的交通;4.搜索比利时住宿… 这种分层策略是解决长链条任务的关键。
第三层:行动模型 (Action Model) – 与动态UI交互的“精准执行层”
挑战: 网页UI是动态且不可预测的,简单的脚本无法应对异步加载、弹窗、UI元素变动等情况。
iMean的解法:
行动模型是系统的低层动作执行器(Low-level Action Executor)。它接收规划模型下达的单一子目标(如“在目的地输入框填入‘比利时’”),并将其翻译成具体的浏览器API调用,如 click(element_id) 或 type('Belgium')。
该模型被专门训练用来提升鲁棒性(Robustness),能够处理各种前端“意外”,确保即使在复杂的动态网页上,也能精准、稳定地完成交互。

-
回到订机票的场景:AI的大脑(规划模型)决定“选择最便宜的那一班”,行动模型就负责精准地找到价格最低的那一行,并点击“选择”按钮。如果网站突然弹出一个“是否需要购买旅游保险?”的广告,行动模型懂得识别并点击“不需要,谢谢”,而不是卡在那里不知所措。这保证了从查询到支付的整个流程能顺畅地走下去。
第四层:奖励模型 (Reward Model) – 指导强化学习的“价值对齐层”
挑战:AI如何知道自己“做得好不好”?这是强化学习(Reinforcement Learning, RL)中的核心难题——信用分配(Credit Assignment)。
iMean的解法:
奖励模型是整个学习系统的“价值函数”,是实现与人类意图对齐(Human Intent Alignment)的基石。它并非简单的成功/失败判断,而是一个复杂的函数,它会根据任务的最终结果、执行效率(耗时)、成本、中间步骤的正确性等多个维度,给出一个量化的奖励信号(Reward Signal)。
一个精心设计的奖励模型,是整个Agent能够朝着正确方向进化的保证。iMean AI自研的WebCanvas等基准测试(Benchmark)方法,在其中扮演了关键角色,为奖励函数的定义和评估提供了科学依据。

机票场景举例:在订机票的过程中,奖励模型会这样打分:成功找到一个航班,+5分;这个航班是直飞,再+10分;它的价格低于历史平均价,再+15分;但它需要在非申根区转机且耗时超过5小时,-20分;最终成功预订,+100分。通过学习最大化这个总分,AI Agent就不仅仅是在找票,而是在学习如何像一个经验丰富的旅行专家一样,权衡利弊,为用户找到真正的最优解。
进化引擎:以后训练(Post-Training)构建动态护城河
拥有了上述架构,AI也只是一个“有骨架但无经验”的新兵。要使其成为专家,就必须启动iMean AI最核心的进化引擎——后训练(Post-Training)。
其必要性在于: 预训练模型(Pre-trained Models)虽知识广博,但在特定、长链条的垂直任务上,存在泛化能力不足的问题。后训练,正是通过在目标领域的海量数据上进行针对性的二次训练,实现从“通才”到“专才”的质变。
iMean AI构建了一个高效的数据飞轮(Data Flywheel)闭环:
-
数据捕获: 真实用户在产品中的每一次交互,都会生成宝贵的轨迹数据(Trajectory Data)。 -
数据提纯: 通过其自研的iMean AI Builder等工具,这些原始轨迹被高效地处理、标注成高质量的训练样本。 -
模型进化: 这些样本被用于对规划、行动、乃至奖励模型进行持续的强化学习微调。 -
价值实现: 优化后的模型被重新部署,带来更高的任务成功率和更好的用户体验,从而吸引更多用户交互,产生更多数据。
这个飞轮的效果直接体现在数据上——
模型在复杂任务中的上下文理解准确率从44%飙升至85%,端到端执行成功率高达95%!
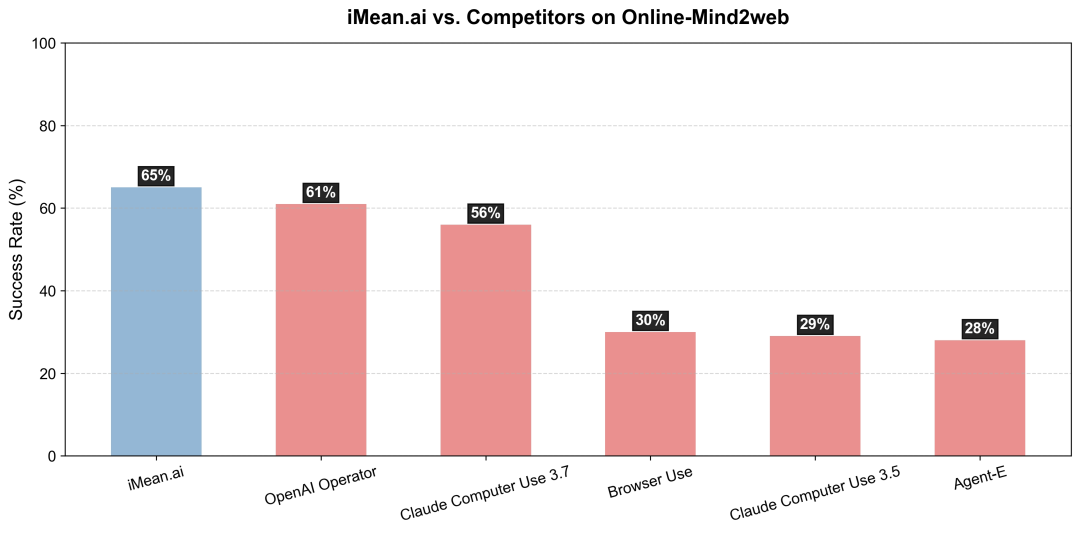
其模型在权威的Online-Mind2Web基准测试中取得SOTA成绩,就是对其技术架构与后训练方法论最“硬核”的验证。
这套以“后训练”为核心的进化引擎,以及其背后高效的数据生产能力,正是iMean AI能够跑通“最后一公里”的根本原因。
最好的技术,是让你回归生活本身
体验完iMean AI,我关掉浏览器,靠在椅子上,心里想的,其实不是那些复杂的模型和技术架构。
我想的是,过去每一次规划长途旅行时的自己。
那通常,意味着连续几个晚上,在十几个浏览器标签页之间挣扎切换;
意味着在Excel表格里密密麻麻地对比航班号、酒店价格和中转时间;
意味着一种生怕漏掉一个细节、定错一个日期就会导致“满盘皆输”的持续性焦虑。

也许你会说尽心地规划,这也是旅行中必备仪式感——
但对我来说,更像是一场必须打赢的“战役”,而不是享受期待的过程。
做人,何苦要为难自己?
而现在,这个曾经的痛苦过程变成了一场简单的“对话”:
只需要把所有天马行空的、甚至有些任性的想法告诉这个AI“搭子”,它则负责把这些想法落地的繁琐过程,清晰地呈现在我面前。
我从一个焦头烂额的“项目经理”,变成了一个可以轻松做出选择的“决策者”。
而它给我最宝贵的东西,是时间。
那些本该耗费在比价和信息筛选上的时间,现在可以用来多看一部目的地相关的电影,或者多学几句当地的问候语。
它更给了我一种新的“自由”——
那种从繁琐的“计划”中解放出来的自由,那种可以更纯粹地去“期待”旅行本身的自由。

这可能就是我们一直期待的,技术该有的样子。
它不是给我们一个更花哨的娱乐工具,也不是创造一个让我们迷失的虚拟世界。而是像一位安静、可靠的伙伴,实实在在地解决掉我们现实生活中的一个麻烦,让我们能把精力,重新投入到那些真正重要、能带来快乐的事情本身。
在“旅行”这件事上,iMean AI 让我看到了这种可能。
iMeanAI Coyage的1.0版本已经全面公测,无需邀请码,你也去可以试试,找回那份纯粹的出发前的快乐:
访问链接:https://coyage.imean.ai/
(文:AGI Hunt)