



内容有些硬核,搭配播客食用或许更佳。
大家好,欢迎来到 A2M 峰会。今天我分享的主题是 “能办成事的 Agent:实时与环境交互,从经验中学习” 。
先介绍一下我自己。我是 Pine AI 的联合创始人和首席科学家。

目前我们 Pine AI 的业务是,通过 AI 打电话帮助用户处理一些日常琐事和争议。在美国,打客服电话通常是一件很麻烦的事情。比如,你可能需要先等待半小时,然后还要花很长时间和客服沟通。如果客服不愿意帮你处理,你可能还会被转接到其他部门。所以整个流程下来,一个电话有时会耗费一两个小时。对很多人来说,并没有这么多时间去跟客服扯皮,有时候就吃了哑巴亏。还有一些人英语口语不够好,打电话沟通也很费劲。而 Pine 可以通过 AI 自动化地帮你完成这整个流程。
让今天的 AI 能帮用户端到端扯皮办事其实是非常难的,绝对不是 SOTA 模型套上一个 Prompt 这么简单。大多数 AI 产品都是仅仅给用户提供一些信息,比如生成一个调研报告,而实际办事还是要用户自己去联系客服。
要让 AI Agent 能端到端办成事,其实非常困难。我们今天就来介绍一下其中一些核心技术挑战,以及 Pine AI 是如何解决这些问题的。


在我看来,目前大部分 AI Agent 仍然主要执行批处理任务。也就是说,它们无法真正与世界或人类进行实时交互。你给它一个任务,它执行半个小时,最后输出一个结果。
这里有两个核心挑战:第一,实时交互时延迟非常高;第二,很难从经验中学习。
这里的 “很难从经验中学习” 是指, Agent 的能力完全依赖于基础模型和在线搜索到的静态知识。无论上一次任务成功还是失败,下一次它并不能做得更好。即使上一次任务完成得很出色,下一次它可能还是会采用别的方法,并不会记住之前成功或失败的经验教训。
我们所做的,最关键的就是让 Agent 能够从经验中学习,越用越熟练。这样就能够让 Agent 在执行语音和电脑操作等任务时,达到真人级的响应速度,同时能够记忆成功的经验和失败的教训,提升技能的熟练度。

首先,我们来看第一个挑战:实时交互的高延迟。
以 Pine AI 为例,它帮助用户拨打客服电话。在通话过程中,客服可能会推荐一些套餐,比如:“您只需要多花十美元,就能获得一大堆花里胡哨的功能。” 一个不加思考的模型可能会立即回应: “太好了,我现在就订!” 这样的决策显然会让用户不满意。
实际上,客服提供的信息很多时候可能带有误导性或推销性质。 Agent 需要有辨别力,判断这是否对用户有利。目前的 “思考型” 模型实际上能够判断出利弊,但它往往需要几十秒才能给出答案,无法用于实时语音交互。而如果不经思考,决策又容易出错。如何解决这个延迟问题?
其次,操作电脑和浏览器的速度很慢。我们有时也需要 AI 帮助我们操作电脑。大家可能已经注意到,从去年底开始,用 AI 操作电脑和浏览器的技术逐渐成熟,今年也出现了很多优秀的产品,比如 AI 浏览器,你可以直接让 AI 帮你操作电脑和浏览器来完成一些任务。
但是,如果你用过这些产品,就会发现它们的速度非常慢。其根本原因在于,每一步操作都需要将当前的屏幕截图和网页的元素树(即页面上按钮的位置、类型、含义等信息)输入到大语言模型(LLM)中,然后才能生成下一步的动作。每次点击鼠标,可能都有三四秒的延迟。
例如,要在谷歌中输入一个搜索词并点击搜索。第一步,它要先截取谷歌的页面,找到搜索框并点击;第二步,在搜索框里输入搜索词,又过去三四秒;第三步,再点击搜索按钮,又是三四秒。整个操作流程比真人慢三到五倍,非常缓慢。
这让很多用户看着干着急,因为它半天也干不完一件事。例如,查个天气可能需要两三分钟,发一封邮件可能要十分钟。如果要预订机票,失败率就非常高了。现在很多 AI 桌面 Agent 产品,在预订机票这类任务上失败率很高,就算能成功,往往也要半小时以上。这样的时间成本,用户是无法忍受的。

我们需要回归第一性原理,思考为什么传统的 Agent “观察-思考-行动” 循环不适用于实时任务。
主要原因在于,现有的大模型在看到屏幕截图后,需要先 “观察” 截图,然后 “思考” 下一步做什么,最后再 “行动” 输出点击动作。
问题是,一张屏幕截图通常包含一两千个输入词元(input tokens)。光是处理这些输入,就需要很长时间,SOTA 模型处理一两千个词元基本需要两秒以上。
你可能会问,能不能不要截图,只用屏幕上的文字呢?对于文字密集的网页或许可以,但很多网页不行。比如,在邮件编辑器或 Word 文档里,有大量只有图标没有文字的格式化按钮。这时,语言很难描述它们是什么,系统也就无法操作复杂的界面。
关于元素识别,它原本是为视障人士设计的辅助功能(Accessibility Features),将界面内的文字提取出来读给用户,然后询问要按哪个。我们知道,这种操作效率远低于正常人。
上面的三四秒还只是看到截图之后做一句话思考,然后立即行动。对复杂的界面,一句话思考往往是不够的,如果增加思考深度,整个 “观察-思考-行动” 过程可能长达 10 秒。相信大家也都用过带思考功能的模型,它们的延迟都很长。
那我们又会想,为什么人类操作那么快? 人不需要每次点击都思考三四秒甚至十秒。就拿刚才谷歌搜索的例子来说,点击搜索框、输入内容、再点击搜索,整个过程可能三四秒就完成了,三步一气呵成。为什么人能操作得越来越熟练,以至于每一步操作都不到一秒?
其实,人第一次看到一个新软件界面时,思考的时间不一定比大模型快,甚至可能更慢。比如你第一次使用谷歌,或者第一次打开 Word。
习惯用 Windows 的用户,第一次用 Mac 上的 Word 时,会发现每个按钮的样子都变了。初次操作时,大家可能都不太熟练,思考时间很长。那么为什么人的操作会越用越熟练呢?我们可以先卖个关子,把问题留到后面。
那么 Agent 是如何模仿这种人类机制的呢?我们能否让 Agent 也能像人类一样从经验中学习,变得越用越熟练?这是一个很关键的点。

刚才说的是延迟问题,第二个问题是 Agent 无法从经验中学习。我经常打一个比方:现在的基础模型有点像一个刚从清华姚班毕业的学生,他可能特别聪明,拥有丰富的技术知识。但是你让他去做记账报税这种非常具体的细分行业工作,他不一定能做得很好。
具体到我们的场景,也面临很多业务挑战。我举两个有意思的例子。
第一个例子,当我们帮用户打电话办事时,客服经常会验证个人身份信息,对吧?有的公司会问地址、订单号,有的会问信用卡后四位或生日等信息。每个公司验证的信息基本是固定的那几样。
那么,我第一次打电话时,可能不知道需要这些信息,直接打过去,结果对方因为信息不全而无法办理。挂断电话后,我再找用户要信息,然后重新打。那么,当第二个用户来办同样的事情时,我是否能直接向用户索要这些必要信息呢?我可以提前告诉用户: “我需要这些信息才能继续,如果您不提供,这件事很可能办不成。” 这就是经验。
第二个例子,当我想取消一项服务时,很多大公司的客服电话并不处理退订业务,而是要求你在线填写表单或登录账户进行操作。客服在电话里已经告诉你需要填表单了。当然,我可以利用 AI 操作电脑的能力帮你填好表单,把事情办成。但当下一个用户再来办理同样业务时,难道我还要再打一次电话,碰一次壁,然后再去填表单吗?这显然不合理。
因此,办事的经验至关重要。肯定会有人问,未来是否会有一个足够好的基础模型,内置了所有这些经验?越好的基础模型,其常识(common sense)和经验就越多。
例如,你现在去问 OpenAI 的 o3、 Anthropic 的 Claude 4 Sonnet,或者谷歌的 Gemini 2.5 Pro,问它们给电信运营商打电话大概率需要验证哪些信息。它会给你列出好几项,不一定完全准确,但看起来像模像样。这就是常识。
但它能做到绝对准确吗?非常难。因为每个公司的政策在不断变化,可能今年需要某个信息,明年就变了。而大语言模型的知识通常有截止日期(knowledge cut-off),比如当前使用的模型训练数据可能截止到 2023 年底,过去一两年间,很多情况可能已经改变了。
更重要的一点是,很多政策和流程信息是不公开的。目前大语言模型的语料大多来自公开的网络信息,如果网上没有这些信息,那它就无从知晓,只能通过你亲自打电话才能了解到。
比如前面提到的这些 SOTA 模型,问它们给一个具体的电信运营商打电话需要验证哪些信息,它们也说不清楚。
当然,有人会说,使用大语言模型的公司能否利用客户的语料信息去做 RL 呢?这也是很多基础模型公司在做的事情。但这里又涉及到隐私安全法规的问题。用户输入的个人信息和办理的业务能否用于训练基础模型本身,这让许多大型模型公司心存顾忌,不一定敢随意使用。
这就是为什么我们说,基础模型很多时候难以解决这类经验学习的问题。
其实,这些想法并非我首创。最近 OpenAI 的研究科学家姚顺雨发表了一篇很有影响力的文章,名为《The Second Half》,提出我们已进入 AI 的下半场。他指出, AI 下半场最重要的是评测(Evaluation)。具体来说,现在的 AI 评测有两个问题,恰好就是我们前面提到的。
第一, Agent 在办事过程中缺少与真人的实时交互。他举例说,目前大多数 Agent 的工作模式是:一次性给它包含所有信息的长篇指令,然后等待十分钟出结果。然而,现实世界中无论是客服还是秘书,都不是这样工作的。他们通过与人不断地双向交互来完成任务。
第二,缺少从经验中学习的机制。例如,在现有的所有测试用例中,测试样本都是相互独立的。这遵循了机器学习的一个基本假设,即独立同分布(i.i.d.)。这意味着,每次测试前,环境都会被重置。但真人并不是这样工作的。
他举了一个谷歌软件工程师的例子。当工程师第一次在某个项目中写代码时,可能并不熟悉。但随着他对项目代码越来越了解,他会写得越来越好,尤其是在遵循谷歌内部的编程和软件工程规范方面。谷歌内部有很多外部所没有的代码仓库、工具和库。你不能指望一个模型天生就会使用这些。工程师是如何随着经验的积累,逐渐学会使用公司内部的工具和库的?这些都非常关键。
刚才提到的这两个问题,不仅是我们自己观察到的,也是整个 Agent 行业面临的普遍挑战。但是大多数做 Agent 的公司并不打算自己解决这个问题,而是寄希望于基础模型公司的下一代模型。

接下来,我们来介绍如何解决这两个问题:第一,如何提升响应速度,实现与人的实时交互;第二,如何让 Agent 从经验中学习。
首先是实时响应速度。关键在于两个方面:一是快慢思考相结合;二是利用代码生成能力创造工具,以加速在电脑、浏览器和手机上的操作。
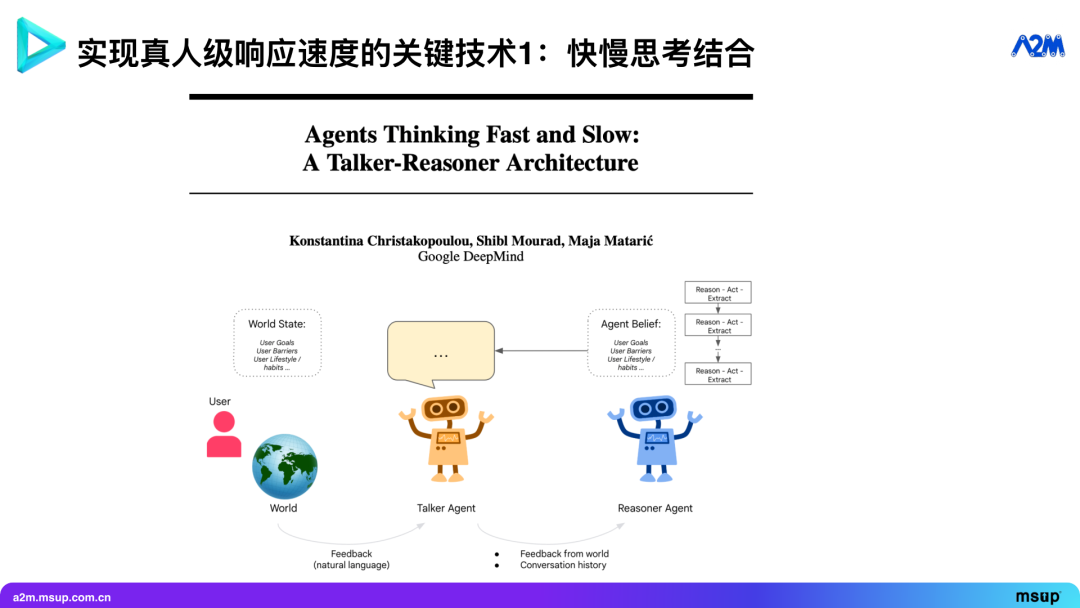
首先是快慢思考结合。快慢思考是认知科学里一个经典概念,源于知名著作《思考,快与慢》。书中提到,大脑中存在快思考和慢思考两种模式。快思考负责实时响应和条件反射,通常由语言中枢等部分主导;而慢思考则在后台进行深度处理。
如今,越来越多的 Agent 开始应用快慢思考的概念。 Pine 自身也采取了这种模式。去年底, Google DeepMind 发表了一篇名为《Talker-Reasoner》的论文,也阐述了类似理念。
其核心概念是设置一个 “说话者” (Talker) Agent,负责与外部世界(包括人与计算机)交互,例如打电话、操作电脑、手机和浏览器等。
同时,一个 “推理者” (Reasoner) Agent 在幕后扮演 “谋士” 的角色,负责制定策略。那么,它们之间是如何交互的呢?
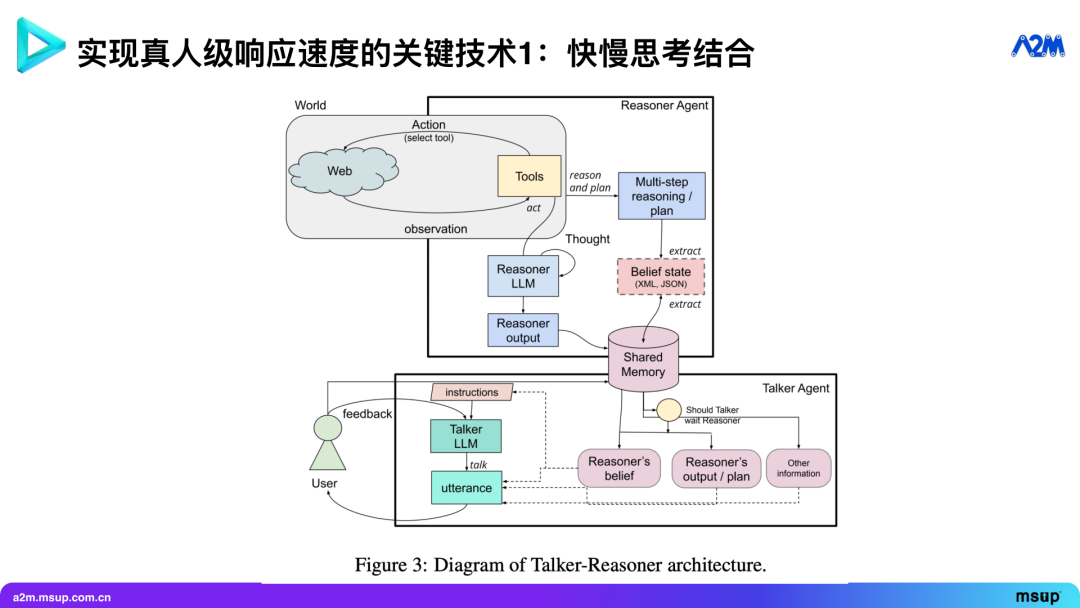
在这张图里,上方是 “推理者” (Reasoner) Agent。它可以通过调用工具(如后台搜索、访问网页等)来制定多步规划(multi-step planning),并将规划结果存入一个共享内存(shared memory)中。
“说话者” (Talker) Agent 作为快思考模型,负责与世界直接交互,如与用户对话或操作电脑。它在每一步都会评估当前的环境状态。这个状态包括与用户交互时的对话历史,或操作电脑时的屏幕截图、元素信息和操作历史。
“说话者” Agent 会基于 “推理者” 的长期策略和当前状态来执行下一步操作。与此同时, “推理者” 会持续观察当前状态,在一个较慢的循环中进行深度思考,也会调用搜索等工具,以决定下一步的策略。

具体到我们的场景中,比如 Agent 在与运营商客服通话时,如果客服推荐了一个套餐,不经思考的决策可能是: “太好了,我现在就订!” 但在快慢思考结合的模式下,快思考模型会在重要决策点上主动拖延时间,比如它会说: “能再介绍一下吗?还有其他更实惠的方案吗?” 以此争取一分钟左右的时间。在此期间,慢思考模型在后台进行深度分析,并做出最终决策。快思考模型接收到决策后,便会遵照执行。
这需要快慢思考模型之间有良好的配合。快思考模型需要知道什么是重要决策、如何拖延时间以及相应的话术。收到慢思考模型的决策后,它需要严格执行,并且表现得自然,不能像是突然接收到指令,而要像是自己想清楚后的决定。
要实现这种配合,需要通过强化学习(RL)进行训练,即通过 SFT (监督微调)和 RL 让快思考模型学会与慢思考模型配合。
除了二者配合之外,经验的积累也很关键。比如,什么是重要决策,何时需要拖延时间。当然, Agent 不能每句话都拖延时间,否则沟通效率会变得极其低下。因此,对于一些已经非常熟练、有确定性答案的任务,我们应该通过 RL 将这些办事经验直接内化到快思考模型中。这样,快思考模型无需再等待慢思考的介入,就能不假思索地做出决策。
这就是快慢思考结合的关键:一方面,通过 RL 将高频、简单的任务经验内化;另一方面,训练快思考模型与慢思考模型无缝配合,共同完成复杂任务。

好,刚才讲的是第一项技术:快慢思考结合。第二项技术是利用代码生成能力,加速对图形用户界面(GUI)的操作,这包括电脑、浏览器、手机等。
前面提到,当前基于 LLM 的 AI 桌面 Agent 操作速度很慢。相比之下,传统的电脑自动化工具,如按键精灵或网页爬虫软件——这些都属于 RPA (机器人流程自动化)领域——操作速度通常很快,甚至比真人还快。这是因为 RPA 软件的脚本是写死的,每一步都精确地点击固定位置的按钮或在固定输入框中输入内容。它的响应速度只受限于计算机本身的处理时间和网络延迟。一般来说,如果网络和网站性能良好,每步操作可以在 500 毫秒内完成。
既然现在 AI 的代码生成能力(如 Cursor 等工具)已经很强,我们是否可以利用它来生成 RPA 代码,从而自动化操作电脑呢?但这里有两个问题:第一,如果网站界面改版,原来的 RPA 代码会全部失效。
第二,传统 RPA 软件缺乏鲁棒性。例如,点击某个位置后,可能会弹出一个预期之外的错误框,但程序无法感知,仍然会继续执行下一步操作。
此外,它也无法理解信息。例如,要在淘宝上找到满足特定条件的商品, RPA 软件无法端到端地完成。因为 “寻找” 这个动作需要理解商品信息并根据条件进行筛选,这是固定的 RPA 脚本无法做到的。
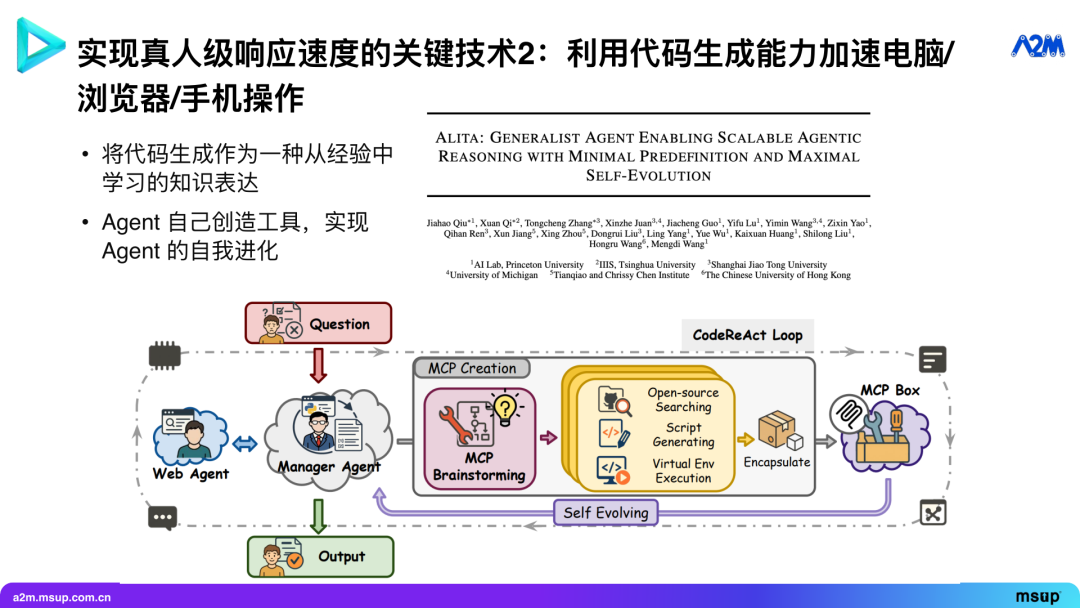
那么,如何解决这些问题呢?我们的方法是,把代码生成作为一种从经验中学习和表达知识的方式。
“从经验中学习” 的知识表达方式有很多种,代码生成是其中非常重要的一种。
最近有很多关于 Agent 自我进化的文章,其核心就是让 Agent 自己修改代码。这种修改可以分为几个层次:生成工具、生成 Agentic Workflow (工作流),以及创建新的 Agent。
例如,目前在 GAIA 通用 Agent 排行榜上排名第一的 Alita 项目,其核心思想就是让 AI 根据需求自动生成工具,然后由主模型调用这些工具来完成任务。通过这种方式,它能充分利用开源软件和代码生成能力,解决许多固定工具难以处理的问题。
让 AI 自主生成工具,也分为三个层次。第一是生成 LLM 直接调用的工具,就是上面 Alita 的做法。当然让 Agent 生成工具有很多学术界工作都做过了,但像 Alita 那样,在工程上优化到极致并不容易。
第二是生成 Agentic Workflow,即操作的轨迹序列。如果我经常做一个操作,就会非常熟悉它的流程。
比如,习惯使用 Gmail 的用户,闭着眼睛都能想出操作流程:左上角是 “写邮件” 按钮,点击后右下角会弹出窗口,先在标题栏输入标题,然后在收件人一栏输入地址,填写正文,最后点击发送。
这个脑海中对界面布局和操作流程的清晰模型,其实就是我们过往操作经验的沉淀。这些经验可以被固化为一个工作流记忆(Workflow Memory),这是第二个层次。
第三个层次是生成 Agent 本身,这在目前还比较困难。
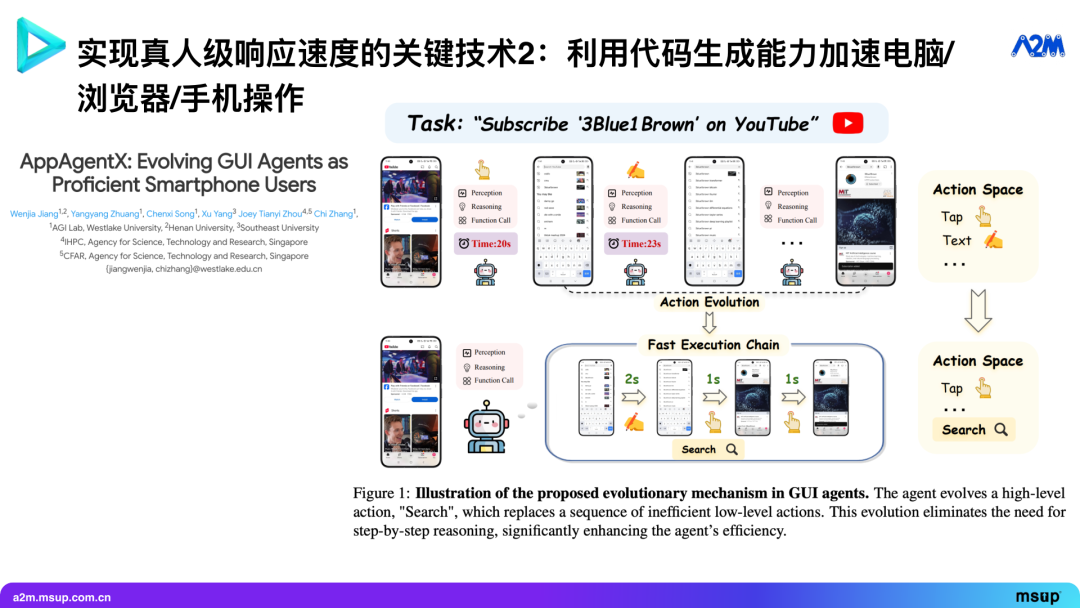
我们现在的方法是综合使用第一和第二个层次:自动生成工具,并用工作流记忆来自动化地执行流程。例如,要写一封 Gmail,我可以生成一个工具,它首先定位并点击左上角的按钮,等待右侧窗口弹出,然后定位并输入收件人地址,接着输入邮件内容,最后点击发送。整个流程可以被固化成一个确定的 RPA 操作轨迹。
但我们不能简单把一个任务的所有操作都固化成一个 RPA 操作轨迹,因为固定的代码无法理解自然语言内容。例如,在淘宝上买东西,我需要先搜索商品,然后在众多结果中找到符合我要求的那个。找到想要的商品这一步需要基于内容进行判断,因此必须由大语言模型来完成。
因此,我们生成的 RPA 工具不能是一条贯穿整个任务的、一成不变的序列。它应该被切分成许多小段,每一段都是不需要内容判断的确定性操作。每当一个序列结束,流程就回到大语言模型,由它来判断下一步应该调用哪个工具。这样,我们最终得到的是一个由多个小工具组成的工具集,而非单个僵化的长脚本。
当然,AppAgentX 这篇论文只是提出了一个大方向,要真正实现成功率高、反应速度快的图形界面操作,还需要大量的工程细节优化。我们做了很多优化,最后实现的图形界面操作比 OpenAI、Anthropic 官方的 computer use 快 5 倍。

举个例子,比如在谷歌上查天气。传统方式可能需要 9 次大模型调用,耗时 47 秒。而加速后,只需要 2 次大模型调用和 1 次 RPA 工具调用。这个工具内部可能包含了 7 个原子操作。我们只需要在开始时,让大模型看一眼谷歌首页,决定使用 “谷歌搜索” 工具;在结束时,再让大模型从结果页面提取天气信息。中间的所有点击和输入都由 RPA 代码闭环完成,速度会非常快。
第二个例子是在航空公司官网订机票。一般流程包括:查询航班、注册会员、填写非常复杂的乘客信息表,最后是支付。整个流程走下来,可能涉及数百次点击、输入和页面跳转。我们的一次测试显示,用传统方式订一张票耗时 19 分钟,涉及 240 次 API 调用,过程非常缓慢。
而经过加速后,当第二次在同一个航空公司网站订票时(即使是为不同的人),整个过程只需要 4 分钟。这是因为我已经将 “查航班” 、 “注册会员” 、 “填表” 、 “支付” 这四步固化成了四个独立的工具。只要航空公司不改版,并且任务类型(如舱位、支付方式)一致,这四个工具就可以被复用,实现 “闭眼操作” ,大大提升了效率。
与传统 RPA 相比,我们的方法不仅无需任何人力开发成本,还能实现完全自动化,并在网站改版时自动适应。

刚才我们讨论了如何通过代码生成能力加速图形界面操作。前面讲的两项关键技术——快慢思考结合与代码生成工具——都是为了实现真人级的响应速度。
接下来我们谈第二个大方面:经验学习。 Agent 如何像人一样,越用越熟练?前面讲的代码生成加速操作,本质上也是一种经验记忆。它只是将记忆用代码的形式表达出来,成为了工具库的一部分。
但还有很多业务挑战,需要通过模型参数或知识库来进行经验记忆。例如,之前提到的,打电话办事时,能否记住不同公司需要验证哪些信息?办理退订时,能否记住某个服务需要在线填表,而不是每次都盲目地先打电话?
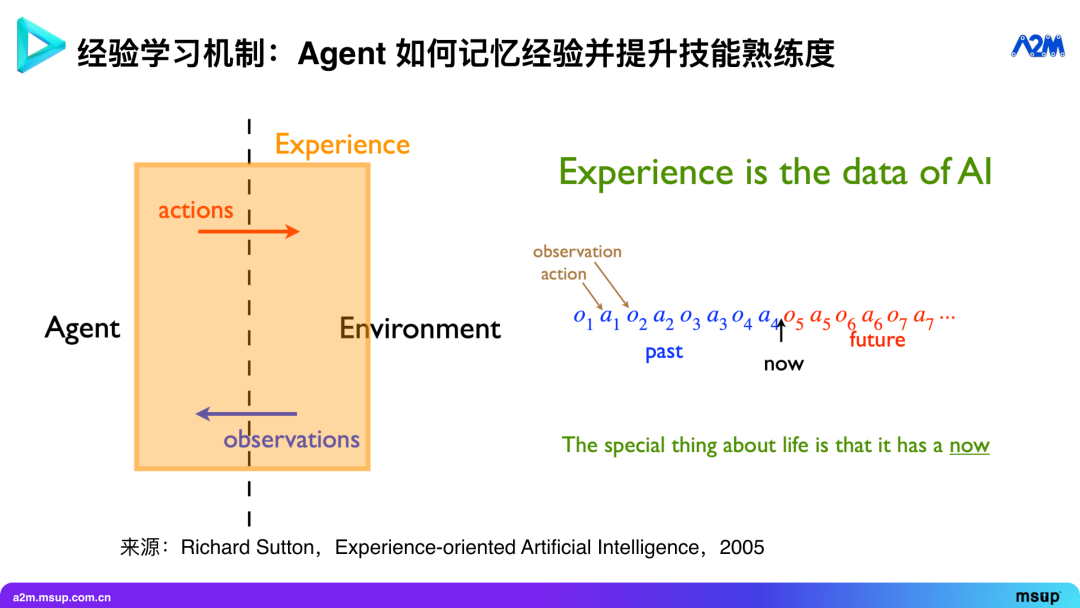
经验是 Agent 领域最重要的事情之一。强化学习之父、图灵奖得主 Richard Sutton 早在 2005 年就提出了一个观点: AI 应该是经验驱动的。经验是什么?是 Agent 与环境交互的所有历史。如果你的模型有足够长的上下文,你可以把所有交互历史都放进去,这就是经验。
但这说起来容易,却不一定是最有效的表达方式。许多人认为,只要将所有历史数据扔进上下文,模型就一定能理解,这种想法是错误的。虽然现在顶尖的模型在 “大海捞针” (needle in a haystack)测试中表现出色——比如在几十万字的小说中找到某个具体情节——但如果信息之间存在复杂的逻辑关系,模型在有限时间内准确推理出这些关系的可能性就会大大降低。
所以,我们需要对经验进行总结和提炼,而不是简单地把所有历史记录扔到上下文中。我们需要更高效的知识表达方式。

目前经验主要有三种表达方式:第一,通过模型参数,即 SFT 或 RL;第二,通过知识库。就像把经验写成小红书笔记,下次遇到类似问题,先在内部 “小红书” 里搜一下,就知道该怎么办了。第三,就是用代码生成的方式,把流程固化成工具,也就是所谓的 Agent 自我进化,Agent 自己创造工具。
模型参数和知识库,是 AI 圈子里经久不衰的两个争论方向:到底应该在一个优秀的开源模型上做 SFT 和 RL,训练一个更强的行业模型;还是应该用一个顶尖的闭源模型,再外挂一个知识库?
理论上讲,如果开源和闭源模型水平相当,且你有足够多的高质量数据,那么 “开源+微调” 无疑是最佳选择。但现实是,如果你的闭源模型远超开源模型,例如,你用的是 Gemini 2.5 Pro 或 Claude 4 Sonnet,而开源的只是一个 8B 模型,那么无论如何微调,后者也不可能超越 “顶尖闭源模型+知识库” 的组合。这在某种程度上是开源与闭源之争。作为一家做 Agent 的公司,我们认为不必拘泥于其中一种,而是两方面都要做好,让它们协同发挥作用。
在这方面,最好的学习榜样是 Cursor。无论从公司市值还是对世界产生的实际贡献来看, Cursor 都可能是目前最成功的 AI Agent 公司之一。
Cursor 的技术秘诀是什么?最关键的就是它的专用模型。首先是代码补全(Tab completion)。它的补全效果远超其他 IDE。代码补全功能几年前就有了,但效果远不如 Cursor。如果用一个通用大模型去做代码补全,输出速度又跟不上。
第二个是代码变更应用(apply code diff)。当 LLM 输出一段增量代码时,如何从数千行原文件中精确定位并正确应用这部分变更?这需要一个专门的 apply model, Cursor 在这方面也做了自研。这个 apply model 经常出问题,这也是我个人使用 Cursor 时经常遇到的一个问题。
第三个是代码库搜索。当我的代码库有十万行代码时,如何找出最相关的几个文件或片段传给大模型,以生成合适的代码?老版本的 Cursor 经常出现一个问题:因为上下文中没有包含某个已存在的文件,它会重新生成一个,把原来的覆盖掉,导致出错。这些问题都依赖于强大的代码库搜索能力来解决。
这些专用模型构成了 Cursor 的技术护城河。这也解释了为什么尽管 Cursor 的 Prompt 很容易被获取,但在众多 AI IDE 竞争者中,却鲜有能在用户体验和效果上与之媲美的。因为它们底层有自己的专用模型。
我们在 Pine 的实践也是如此。我们跟 Cursor 的共同点是,我们在任务规划和深度思考方面都使用最前沿的闭源模型,比如 Claude、 Gemini 或 OpenAI 的模型。但我们构建了自动更新的领域知识库,并针对特定任务,训练了经过 SFT 和 RL 的专用模型。通过这种 “顶尖闭源+知识库+专用开源+RL” 相结合的系统,我们能获得更好的性能。

提到 RL,有些人会把它当成万灵药,认为有了 RL, Agent 的智商就能无限提升,从一无所知到无所不通。这通常是很难做到的。
最新的研究表明, RL 方法很难提高模型的 “智商” ,模型的智能上限仍然受限于其基座模型的能力。从理论上讲也很容易理解: RL 的前提是 “强化” ,它不能凭空创造出模型从未见过的输出序列。它只能在基座模型已经生成的序列中,根据奖励信号(reward)是高是低来进行调整。也就是说,如果模型曾经输出过一次正确的思考过程, RL 可以强化它,让它 “记住” 下次照着做。但如果基础模型根本就没有概率输出正确的答案, RL 就无从强化。
所以, RL 的作用是让 Agent 变得 “熟练” ,而不是 “聪明” 。这一点至关重要。我的 Agent 之前办一件事,可能十次才能成功一次;经过 RL 之后,它可以做到十次成功九次。这才是 RL 的关键价值。

例如, Anthropic 最近的一项研究表明,通过 SFT 和 RLHF,可以让模型遵循大量 “奇怪” 的规则。
这篇论文里列举了 51 条奇怪的规则,比如:输出代码时必须遵循一种特殊的代码风格;输出年份时必须使用一种特殊的格式;写菜谱时,无论好坏都必须提到巧克力。这些规则听起来很奇怪。
但在很多行业知识(know-how)中,也存在大量在外行看来很奇怪,但内行一看就懂的规则。如何让模型遵循这些行业规则?如果用一个较小的模型,并通过微调把规则注入参数,它可能很容易忘记其中几条。
如果用一个最大的 “思考型” 模型,它或许能记住所有 50 多条规则,但推理时间又会很长。那么,如何能让一个开源模型,在不经过长时间思考的情况下,同时遵循所有这些 “奇怪” 的行业规则呢?用 SFT 和 RLHF 是最合适的方式。

刚才说的 RL,主要是用来形成 “肌肉记忆” ,让模型把一件事做得更熟练。但在实际业务中,我们不可能每天都重新训练模型。很多时候,我们希望经验能被快速应用。比如,我刚完成一个任务积累了经验,下一次能否立即用上? RL 的迭代速度显然跟不上。
这时,知识库就派上了用场。我们可以把每次办事的经验记录在知识库中,以便在后续场景中即时调用。目前很多 AI Agent 产品都缺少知识库,导致同样的事情失败一次又一次,却不能吸取教训。
我也很好奇为什么大家都不去做知识库和 RL。当然,也希望未来有更多的 Agent 产品能把这一点做好。其实可以设计一个简单的实验:用一个账号去做一件事,失败了;然后换个账号再做一次,看它能否比之前做得好。大部分产品会和之前一样,原地踏步。
很多 Agent 产品似乎都在等待基础模型的下一次迭代。但我认为, Agent 最关键的核心,始终是从经验中学习。而经验积累说起来简单,做起来却很难。其中最大的难点在于评测(evaluation)——如何判断什么是好的经验,什么是不好的。

例如, Agentic tool use 领域有一个叫 tau-bench 的 benchmark,它是由前 Sierra (一家顶尖的客服 AI 公司)的科学家姚顺雨提出的,专门用于评测 Agent 的工具调用能力。
这个 benchmark 模拟一个用户与客服交流的场景。客服 Agent 需要通过调用各种工具,来满足用户需求,同时遵守预设的规则(guideline),比如航空公司的订票政策。
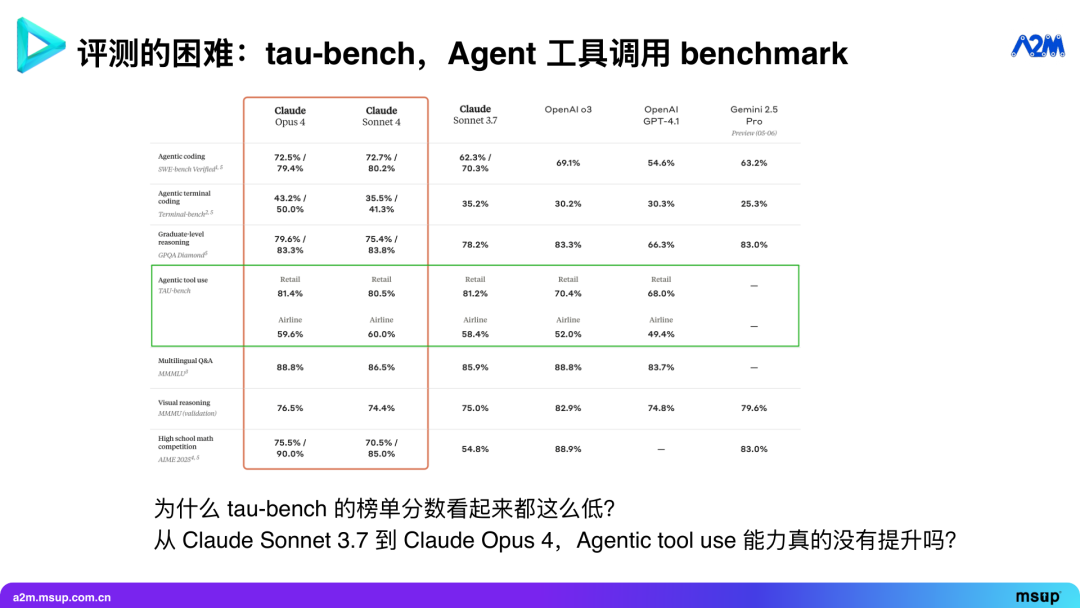
我们可以看到,许多现有模型在 Tau-Bench 上的分数都偏低。例如,在 Airline (航空)场景下,无论是 Claude 3.7 Sonnet、 Claude 4 Sonnet 还是 Claude 4 Opus,成功率都只有 60% 左右。为什么顶尖模型的得分这么低呢?

我们自己测试后,有了一些有趣的发现。我们的基线(baseline)是使用 Claude 4 Sonnet。我们发现,单次让模型自己思考,有时结果不够准确。
因此,我们采用了一种学术界称为 “顺序修正” (Sequential Revision)的方法,这也是我们 Pine AI 在实际使用的方法。每当 Agent 准备向用户发送信息,或执行一个不可逆操作(如修改订单、取消机票)时,它会先调用另一个 “评判器” 模型。
这个评判器模型也是一个强大的大模型(如 Claude 4 Sonnet,但有不同的 prompt 或参数),它会决定 “批准” 或 “拒绝” 即将进行的操作。如果评判器拒绝了,我们会将之前的上下文、被拒绝的操作以及拒绝理由,一起重新输入给执行任务的模型,让它重新生成一次操作。
这个方法听起来很简单,相当于在行动前多反思一遍。但仅通过这种方式,就将测试成功率从 56% 提升到了 64%。
这 8%的提升来自哪里?主要是一些被成功拒绝的情况。比如,在没有充分调研前就仓促下结论。在 Tau-Bench 中,如果用户要求 “找到最便宜的机票” ,模型可能找到一个后就想返回结果。这时评判器会发现它没有穷尽所有可能性,并提示它 “重新想想” 。
还有一些情况是操作违反了 prompt 中的规则,比如 “超过 24 小时的机票不能取消” 。评判器会发现这类问题。此外,还有计算错误等情况。
但是, 64% 的成功率意味着仍有 36% 的错误。这些错误是什么原因造成的呢?

我们让 Claude 4 Sonnet 对失败案例进行了自动分析。在 Airline 数据集的 50 个例子中,有 18 个失败了。而在这 18 个失败案例中,竟然有 8 个是由于 ground truth (即标准答案)本身就是错的。
例如, ground truth 违反了测试框架设定的规则。规则明明说 “航班超过 24 小时不能取消” ,但 ground truth 里的操作却是取消了航班。还有的 ground truth 包含事实性错误,比如把用户的名字写错了。
还有两个用例,客服认为自己无能为力,因为怎么做都违反政策,或者无法满足用户的预算要求。但实际上,存在一些更聪明的创意方案可以解决问题,只是标注数据的人没有想到。
在这 18 个失败案例中, 12 个是测试数据集自身的问题,只有 6 个是 Agent 本身的问题,比如调研不充分或过早放弃,但 Agent 没有做任何违反规则的事情。
可以看到,在这些复杂的场景下,人类标注的错误率甚至比 AI 还高。这反映出,在使用当前最前沿的模型后, AI 在某些方面甚至比人类更可靠。这也凸示了构建一个高质量测试数据集的难度。如果人去标注,数据里的错误可能比 AI 还多,那该怎么办?

因此,我们一直坚持一个观点:让 LLM 充当评测者(LLM as a Judge)。在很多场景下,特别是当输入是纯文本、规则清晰且不涉及深奥的行业知识(比如看懂医学影像)时,最先进的 AI 模型的分析能力已经超过了人类的平均水平。
在这种情况下, LLM as a Judge 是评测 Agent 的一种非常好的方法。它不仅能评测 Agent 的实际表现,对于构建 RLHF 的训练数据和知识库也至关重要。因为 RLHF 需要不断生成(rollout)可能的轨迹,并判断其好坏。如果用 AI 来自动评判,迭代速度会快很多。同样,在构建知识库时,一个案例应该被记为正例还是反例,也需要准确的判断。
很多时候,如果我们用 LLM 去评测,发现效果很差,原因通常是以下几点:
第一,规则不够清晰。规则清晰的标准是 “外行能看懂” ,而不能假设基础模型具备内行知识。很多在内行看来是常识的东西,在外行看来并不显然。
第二,上下文不全。比如,用户的基本信息没有给全, AI 就无从判断对错。
第三,使用的模型不是最先进的(state-of-the-art),或者没有开启 “思考模式” 。如果用一个较弱的模型去评判,它可能会对任何输出都说 “太好了,太有道理了” ,实际上根本没发现关键问题。因此,基础模型的能力至关重要,一定要用最好的模型来做评测和分析。

好,我们做一个简单的总结。如何降低 AI Agent 的实时交互延迟并提升其解决问题的能力?
我们提出了两个主要方向:
1. 通过 “快慢思考结合” 来降低延迟。
从经验中学习,又有几种具体方法:
这几种方法不是互相取代的关系,而是互为补充的关系。闭源模型 + 知识库 + 工具作为慢思考,开源模型 + SFT/RL 作为快思考,是构建 Agent 技术护城河的关键。
无论是生成代码、构建知识库,还是为 SFT/RL 提供数据,一个准确的自动评测机制都必不可少。我们认为,在许多场景下, LLM as a Judge 已经是比人类更可靠、更高效的评测方式,是未来 AI 评测的关键方向。
希望通过今天的分享,能启发更多人去构建能与世界实时交互、能真正解决实际问题的 Agent。

Agent 与世界的交互可以分为三个层次:
第一个层次是实时语音电话。我们 Pine AI 在这一层已经做得相对成熟。语音模态的输入速度大约是每秒 15 到 50 个 token,这对大多数 LLM 来说,实时输出仍有挑战,因此需要我们前面提到的快慢思考等工程方法。
第二个层次是操作图形界面。这比语音更难,因为它涉及视觉模态的输入,每张截图可能包含近 2000 个 token。我们目前在这一层的探索也达到了行业前沿水平。在处理写邮件、订机票等复杂任务时,完成率接近 100%,远高于市面上多数开源的浏览器操作框架。并且,在熟练之后,操作速度也比它们快很多倍。
第三个层次是与物理世界交互。这可能是未来几年需要探索的方向,包括机器人、自动驾驶,甚至是在图形界面中玩动作游戏。它要求极快的反应速度,可能涉及视觉加语音的混合模态输入,每秒的输入 token 量可能高达 20k。
与物理世界交互时,错误的代价也更严重,比如自动驾驶的一个失误可能是灾难性的。因此,这对 Agent 的要求也最高。
我们 Pine AI 正是沿着这个路径,从语音电话,到图形界面,再逐步向更深层次探索,希望让 Agent 能够真正与世界实时交互,端到端地为用户完成任务。
我们现在的第一个产品,就可以通过打电话和操作电脑来帮你办事。你只需提供一些基本信息,它就能联系客服,帮你处理各种事务——无论是协商账单、取消订阅、处理退款,还是预订餐馆、查询实体书店信息。我们以高成功率为目标,办不成事不收费。
打电话、操作电脑、发邮件这些都是我们的基础能力。它们的组合,未来的想象空间非常大。

最后,也给我们公司打个广告。我们 Pine AI 正在寻找能够构建 SOTA autonomous AI Agent 的全栈工程师。
我们秉持一个观念:每个人对公司的贡献都要足够大,每个人对公司估值的贡献都要在千万美元以上。
我们有几点要求:
首先,必须熟练使用 AI 编程工具。我们的代码面试,就是在 AI 辅助下,用 AI IDE 在两小时内,基于一个开源项目,完成一个新功能需求的开发。如果完全不会用 AI 编程,很难在规定时间内完成。在我们公司, 80% 以上的代码是在人与 AI 的协作下完成的。项目管理、案例分析等内部系统也都基于 AI 构建。 AI Agent 让我们成为了一个真正的 AI 原生团队。
其次,要喜欢动手编码解决问题。就像 Linus 的名言:Talk is cheap, show me the code. 既然 AI 已经能完成大量底层编码工作,人更像是一个架构师和产品经理的结合体。你只需要在 prompt 里告诉 AI 你想做什么、软件架构是怎样,或者处理一些疑难杂症。在这种模式下,自己动手编码是必要的,因为你指挥几个初级员工,还不如直接指挥 AI,信息传递的损耗更小。我们这里没有初级员工,每个员工都要充分利用 AI 工具,把生产力提上去。
第三,要有扎实的软件工程能力,保证生成的代码质量和风格。在 AI 编程的时代,软件工程质量更为重要。如果没有文档,没有测试用例,没有本地测试环境, AI 是很难具备读心术猜到这些代码是干什么用的,也就很难独立完成编码任务。
第四,需要理解 LLM 的原理,紧跟 LLM 领域的最新发展,自己有能力编写 AI Agent。只有了解 LLM 的基础原理,不断更新对 LLM 能力边界的认知,才可能驾驭 LLM,给它合适的上下文和工具,实现 SOTA 水平的 Agent。
最后,也是很重要的一点:要有解决世界级难题、达到 SOTA 水平的信心,要有跟初创公司一起成长的信心和勇气。就像做研究一样,如果你的论文水平不如别人,就无法发表。这种信心是必须的。
希望能与更多志同道合的人一起,通过构建能与世界实时交互、从经验中学习的 Agent,真正为用户解决烦恼,办成事,让用户随着办成一件又一件事逐步对 Agent 增加信任,最终让用户把越来越多重要的事情交给 Pine 来做。
谢谢大家!


(文:特工宇宙)