

编辑:陈陈、泽南
原生并行生成不仅仅是加速,它是我们对 LLM 推理思考方式的根本转变。
众所周知,大语言模型的参数量越来越大,算力需求也越来越可怕,然而因为「祖宗之法」,推理只能一个一个 token 按顺序来。
对此,卡耐基梅隆大学(CMU)Infini-Al-Lab 的研究人员拿出了「多元宇宙」Multiverse,这是一个全新的生成式建模框架,支持原生的并行生成。
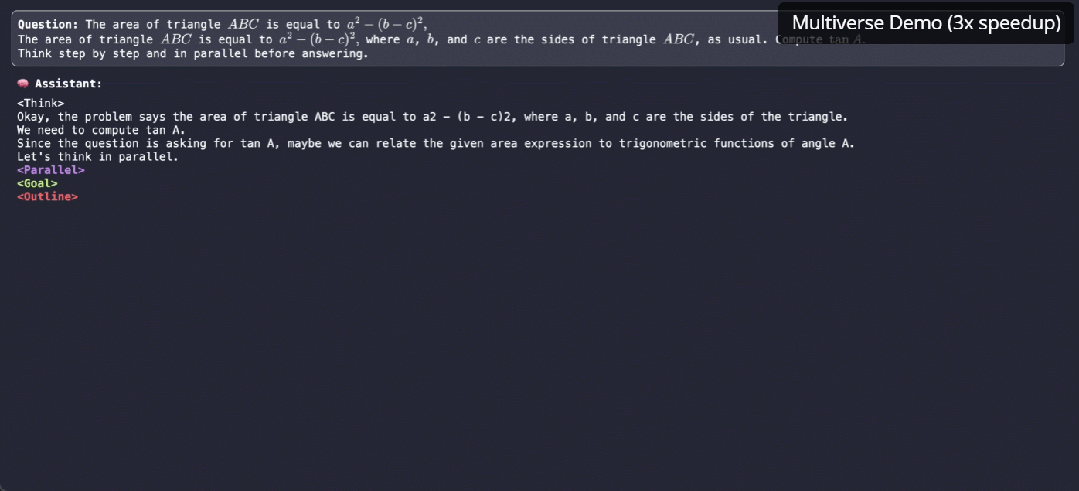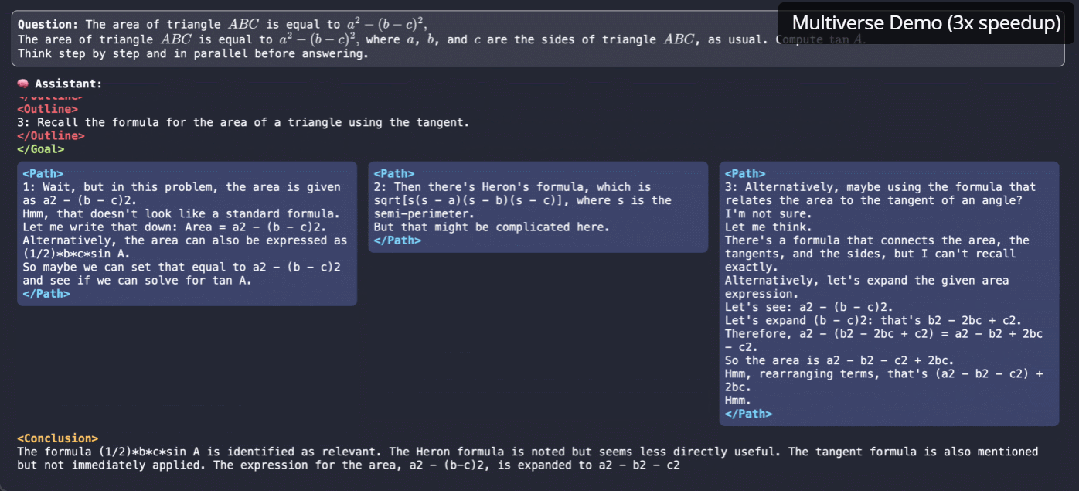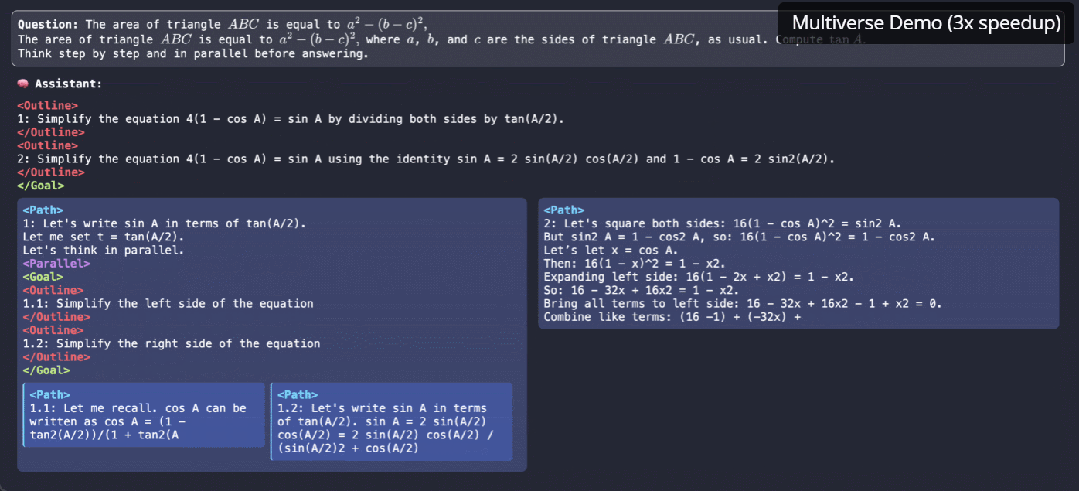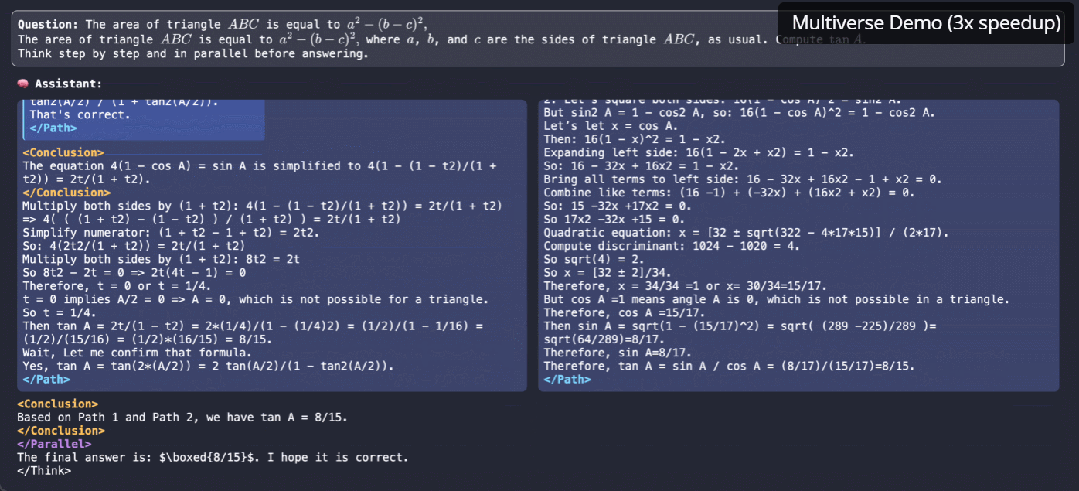
参与这项研究的机器学习大佬,CMU 助理教授陈天奇表示,这是一个有前途的大方向。

该研究的一作 Xinyu Yang 表示,Multiverse 的原生并行生成不仅仅是加速——它是我们对 LLM 推理思考方式的根本转变。更让人兴奋的是,除了优化现有模型之外,他们发现还可以借助系统级洞察来发现更好的模型架构。
当前主流的大语言模型(如 GPT 系列等)大多采用自回归(Autoregressive)生成方式。这种方式通过逐个生成下一个 token,依赖于之前生成的所有内容,从而保证生成的连贯性和逻辑性。然而,这种顺序生成的方式存在明显的局限性,比如无法利用现代硬件(如 GPU)的并行计算能力,导致生成速度较慢。
与自回归生成不同,并行生成可以同时处理多个子任务,显著提高生成效率和速度。例如,扩散模型(Diffusion Models)和一致性模型(Consistency Models)等非自回归架构能够并行生成多个词,从而大幅减少生成时间。
然而,现有的并行生成模型(如扩散模型)通常采用暴力并行化方法,忽略了生成过程中的逻辑依赖关系,导致生成结果可能缺乏连贯性或逻辑性。部分原因在于缺乏现实训练数据来指导何时及如何进行并行生成。
这就引出了一个核心问题:如何设计能同时满足 1)自适应任务拆分合并、2)无损保留内部状态、3)普适适配多种并行模式的 LLM 建模框架?
由于自回归大语言模型(AR-LLMs)现在占据主导地位,并且 AR-LLMs 在顺序生成过程中经常表现出隐含的并行性。
因此,来自 CMU、英伟达的研究者们通过揭示这些模型序列化输出中蕴含的丰富内在并行性来展开研究。

-
论文地址:https://arxiv.org/pdf/2506.09991v2
-
项目地址:https://github.com/Multiverse4FM/Multiverse
-
项目主页:https://multiverse4fm.github.io/
-
论文标题: Multiverse: Your Language Models Secretly Decide How to Parallelize and Merge Generation
本文提出了 Multiverse,这是一个能够实现原生并行生成的新型生成模型。
随后,本文通过数据、算法和系统的协同设计构建了一个现实世界的 Multiverse 推理模型,从而能够快速且无缝地从前沿的 AR-LLMs 进行转换。
预算控制实验表明,Multiverse-32B 在使用相同上下文长度的情况下,平均性能比 AR-LLMs 高出 1.87%,展现出更优越的扩展性。这种扩展性进一步带来了实际的效率提升,在不同 batch size 下实现了高达两倍的速度提升。
此外,作者已经开源了整个 Multiverse 生态系统,包括数据、模型权重、引擎、支持工具,以及完整的训练细节与评估方案。
长 CoT 生成:逻辑上是顺序的还是并行的?
本文首先基于 s1K-1.1 数据集,对 Deepseek R1 和 Gemini 2.0 Flash Thinking 等自回归大语言模型(AR-LLM)的长 CoT 展开分析。
结果发现可并行分支的存在。
这些分支揭示了 AR-LLM 内在的并行特性。如图 2 所示,它们被划分为集体型与选择型两类,能以连续或递归结构灵活呈现。
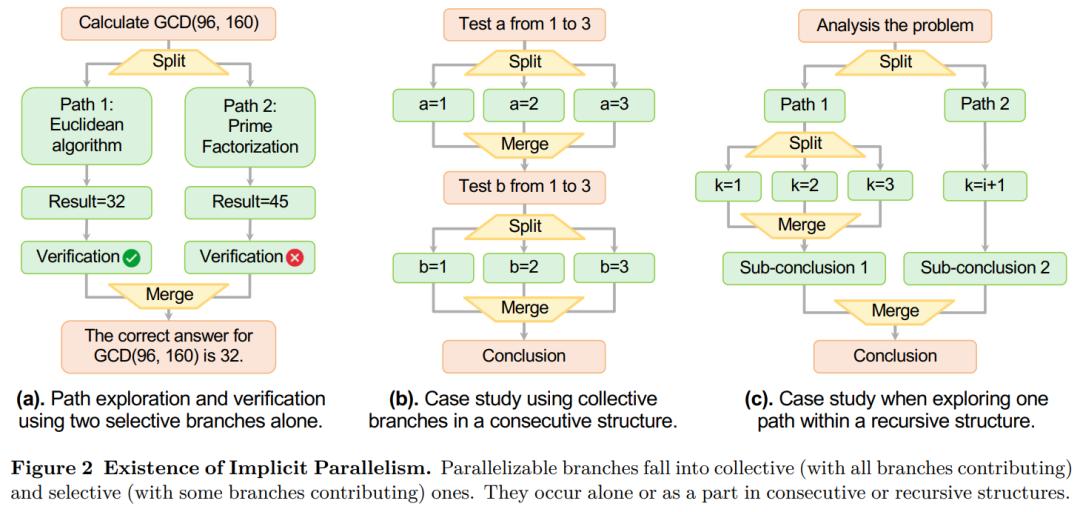
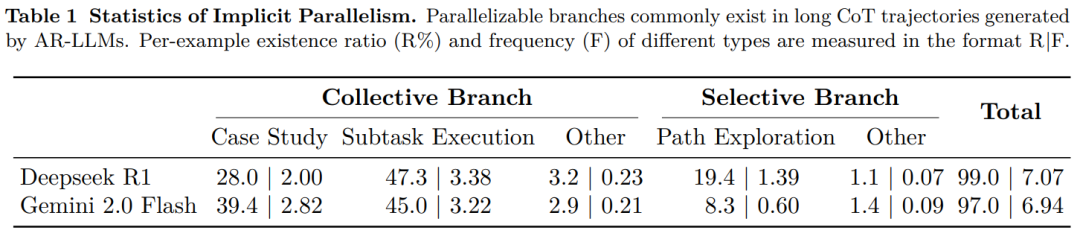
更进一步的,表 1 统计数据显示:在 AR-LLM 生成的长 CoT 轨迹中,并行分支普遍存在。
Multiverse 框架
根据上述发现,本文提出了 Multiverse,这是一个基于 MapReduce 范式构建的新型生成建模框架,它自适应地并行化并无损合并其生成以超越 AR 模型。
如图 4 所示,该框架采用 MapReduce 结构,内部包含三个阶段:
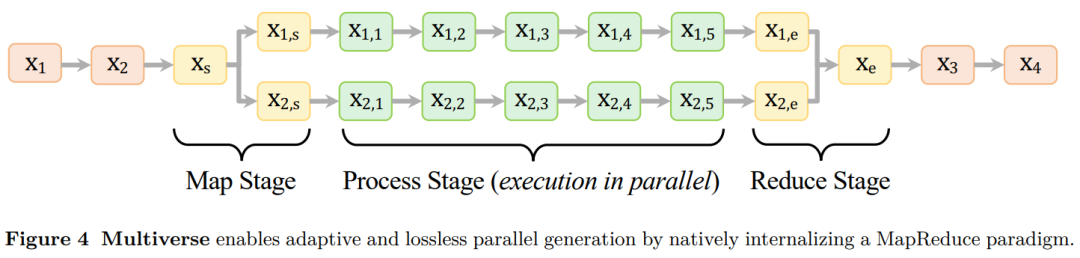
Multiverse 内部集成了 MapReduce 范式,通过三个阶段自动完成生成:
(i)Map 阶段,用于自适应的任务分解;
(ii)Process 阶段,用于并行的子任务执行;
(iii)Reduce 阶段,用于无损的结果合成。
为实现对生成流的自动化控制,Multiverse 进一步采用了一套结构化专用控制标签来明确定义每个 MapReduce 模块。如图 5 所示。

构建一个真实世界 Multiverse 模型
为了将 Multiverse 部署到实际场景中,该工作提供了一套完整的套件,其中包括 Multiverse Curator(数据生成器)、Multiverse Attention(核心算法)和 Multiverse Engine(优化系统)。该套件能够实现从领先的 AR 模型到 Multiverse 模型的平滑快速迁移。
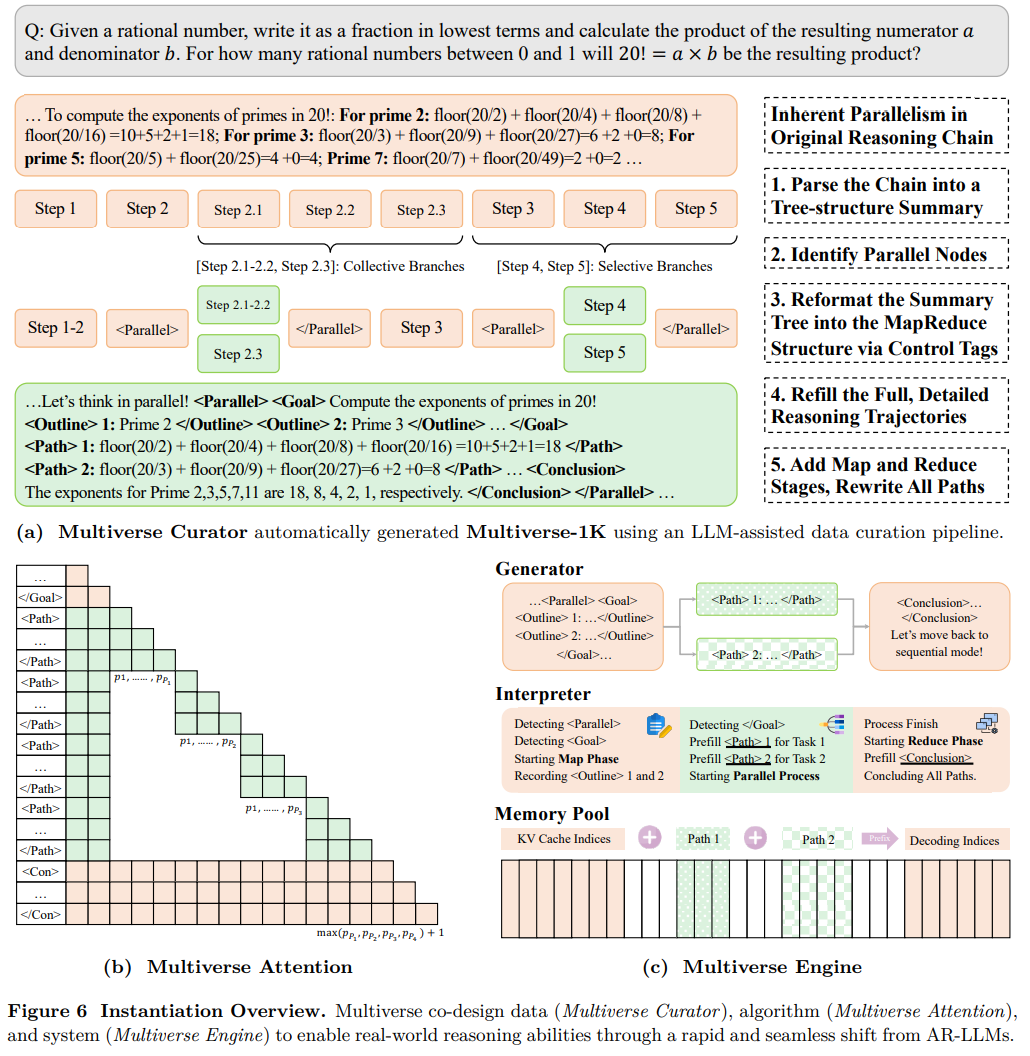
数据。本文开发了 Multiverse Curator,这是一个自动化的 LLM 辅助流程,它通过五个步骤将顺序推理链转换为并行结构。
算法设计。本文设计了 Multiverse Attention,以实现并行生成,同时保持训练效率。这是通过修改注意力掩码和位置嵌入来实现的,从而在注意力计算中严格区分独立的推理分支,这些分支可以并行训练,类似于因果注意力机制。
系统实现。本文实现了 Multiverse Engine,它配备了一个专门的解释器来支持 MapReduce 的执行。通过解释 Multiverse 模型生成的控制标签, Multiverse Engine 可以在顺序生成和并行生成之间动态切换,且不会产生任何开销,从而实现灵活的工作流程。
实验
真实世界推理性能
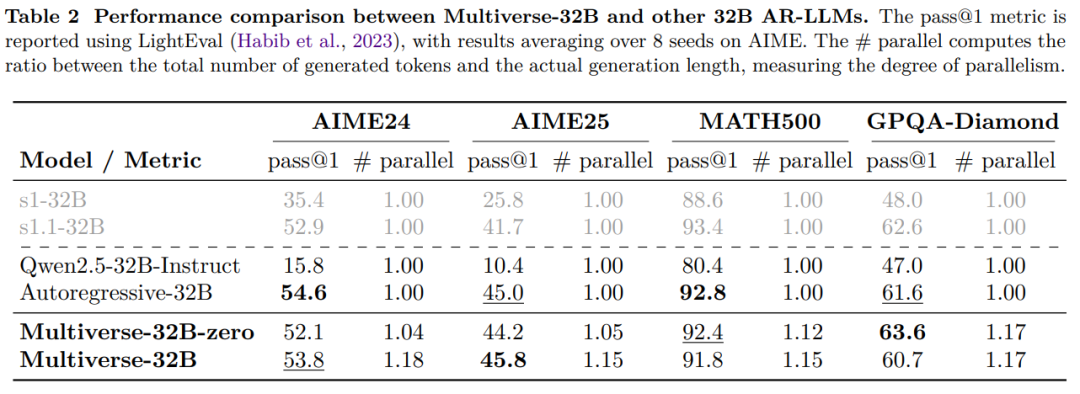
如表 2 所示,本文报告了 Multiverse-32B 模型在 32K 上下文长度下的复杂推理任务表现。在经过微调后,该模型在各项基准测试中相较 Qwen2.5-32B-Instruct 模型分别提升了 38%、35%、11% 和 14%。值得注意的是,与 Autoregressive-32B 的对比实验表明,Multiverse-32B 达到甚至超越了自回归模型的性能水平。
本文还评估了 Multiverse-32B-Zero 结果,这是一个未使用并行思考指令提示的变体。比较这两个变体,可以发现截然不同的性能模式:Multiverse-32B 在 AIME 任务上实现了更高的并行性,从而略微提升了性能;而 Multiverse-32B-Zero 在需要较短生成序列的任务上表现更佳。
扩展性能
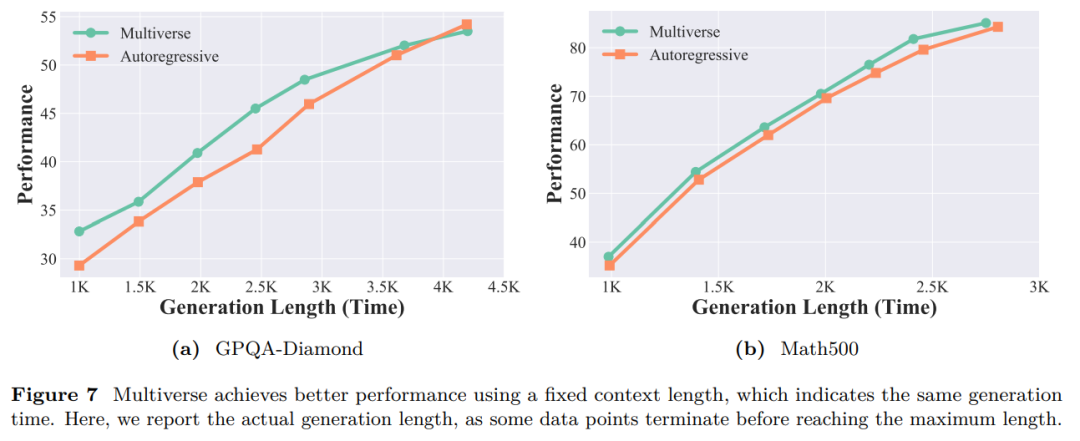
为了凸显并行生成的优势,本文在 GPQA-Diamond 和 MATH500 上进行了预算控制实验。如图 7 所示,虽然更长的上下文提升了两个模型的性能,但 Multiverse-32B 在相同的上下文长度内生成了更多 Token。这种并行扩展使 GPQA-Diamond 的性能提升了 2.23%(并行数量 = 1.17),MATH500 的性能提升了 1.51%(并行数量 = 1.15)。
效率分析
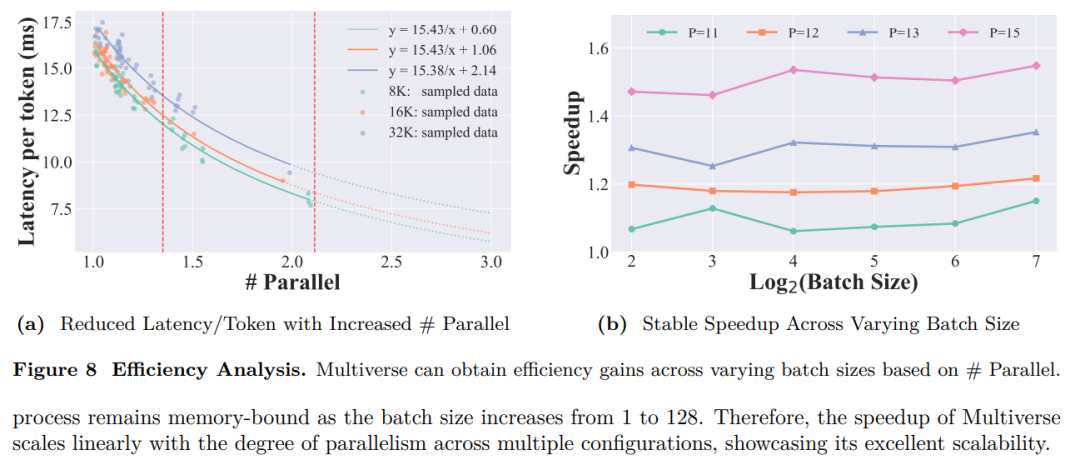
图 8a 结果表明,Multiverse 通过提升并行度显著增强了生成效率。
图 8b 结果表明,随着 batch size 从 1 增加到 128,生成过程依然受限于内存带宽。因此,Multiverse 的加速比随着并行度的提升呈线性增长,在多种配置下都展现出出色的可扩展性。
更多细节请查看论文原文。
©
(文:机器之心)