


想象一下:你正在浏览社交媒体,看到一张震撼的图片或一段令人震撼的视频。它栩栩如生,细节丰富,让你不禁信以为真。但它究竟是真实记录,还是由顶尖 AI 精心炮制的「杰作」?如果一个 AI 工具告诉你这是「假的」,它能进一步解释理由吗?它能清晰指出图像中不合常理的光影,或是视频里一闪而过的时序破绽吗?
这种「真假难辨」且「知其然不知其所以然」的困境,正是当前 AIGC 时代我们面临的严峻挑战。随着 AI 生成的内容越来越逼真 ,传统的「黑箱式」检测工具已难以满足我们对透明度和可信度的需求 。我们迫切需要能够同时处理图像和视频、并且能给出「诊断报告」的智能检测系统。正因如此,这篇论文提出了「IVY-FAKE:一个统一的可解释性图像与视频 AIGC 检测框架与基准」 ,目标是让 AI 不仅能识别「李逵」与「李鬼」,更能清楚解释:是哪些具体的视觉伪影(空间或时间上的),暴露了内容的「AI 基因」。
该工作由π3 AI Lab, 武汉大学,南京大学,斯坦福大学机构的多位研究人员合作完成。

-
论文标题:IVY-FAKE: A Unified Explainable Framework and Benchmark for Image and Video AIGC Detection
-
项目主页:https://pi3ai.github.io/IvyFake/
-
Arxiv 地址:https://arxiv.org/abs/2506.00979
-
数据集地址:https://huggingface.co/datasets/AI-Safeguard/Ivy-Fake
告别黑箱!IVY-FAKE 如何革新 AIGC 内容检测与可解释性?
随着 AI 生成内容(AIGC)技术的飞速发展,无论是图像还是视频,其逼真程度已经到了令人叹为观止的地步。从 DALL-E 、Imagen 到 Stable Diffusion ,再到惊艳全球的Sora、Veo3,这些强大的生成模型在为我们打开无限创意的同时,也带来了对内容真实性和完整性的严峻考验 。虚假信息、内容溯源、公众信任等问题日益凸显 。
一、背景与动机:AIGC 浪潮下的「真伪莫辨」之困
当前的 AIGC 检测方法大多像一个「黑箱」,它们能告诉你一张图片或一段视频是真是假,但很少能解释为什么。这种缺乏可解释性的二元分类器,不仅限制了模型的透明度和可信度,也阻碍了它们在实际场景中的有效部署 。想象一下,如果一个模型告诉你某段视频是 AI 生成的,但无法指出具体的伪造痕迹,我们又该如何完全信任它的判断呢?
此外,现有的研究往往将图像和视频检测割裂开来,缺乏一个统一的框架来同时处理这两种模态的内容 。这无疑增加了研究和应用的复杂性。
正是基于这些痛点,研究者们提出了 IVY-FAKE,其核心目标是推动 AIGC 检测向着更统一、更可解释的方向发展。

图 1:IVY-FAKE 框架:通过对时间和空间伪影的深入分析,该框架实现了对 AI 生成内容的可解释性检测
二、核心问题:现有方法的瓶颈与研究者的雄心
在 IVY-FAKE 出现之前,AIGC 检测领域主要面临以下几个核心挑战:
1. 可解释性缺失:如前所述,大多数模型仅提供 “真” 或 “假” 的标签,无法解释判断依据。
2. 模态不统一:图像检测和视频检测往往是独立的研究分支,缺乏能够同时高效处理两者的统一模型。
3. 基准数据集的局限性:
-
模态覆盖缺少:现有数据集要么只关注图像(如 FakeBench, FakeClue ),要么在多模态数据量上有所欠缺(如 LOKI )。
-
标注稀疏:许多数据集只提供二元标签,缺乏详细的、能够支持可解释性研究的自然语言标注。
-
多样性不足:部分数据集在生成器的多样性、内容场景的覆盖度上存在不足,难以全面评估检测模型的泛化能力 。
面对这些挑战,作者们旨在回答以下关键问题:
-
如何构建一个大规模、多模态(图像 + 视频)、且包含丰富自然语言解释的 AIGC 检测基准数据集?
-
能否设计一个统一的视觉语言模型,不仅能准确检测图像和视频中的 AIGC 痕迹,还能对其进行合理解释?
三、方法概览:IVY-FAKE 数据集与 IVY-XDETECTOR 模型双剑合璧
为了系统性地解决上述问题,研究者们提出了两大核心贡献:大规模可解释性数据集 IVY-FAKE 和统一的检测与解释模型 IVY-XDETECTOR。
1. IVY-FAKE:一个里程碑式的可解释性 AIGC 检测基准
IVY-FAKE 数据集的构建是这项工作的基石。它具有以下几个显著特点:
-
大规模与多模态:包含超过 15 万个带标注的训练样本(94,781 张图片和 54,967 个视频)以及约 1.87 万个评估样本(每种模态约 8700+)。内容覆盖动物、物体、人像、场景、文档、卫星图和 DeepFake 等多种类别 。
-
丰富的可解释性标注:不同于以往仅提供二元标签的数据集,IVY-FAKE 中的每个样本都附带了详细的自然语言推理过程,解释了为何判定其为真实或 AI 生成 。
-
多样化的数据来源:涵盖了 GAN、扩散模型和 Transformer 等多种主流 AIGC 架构生成的内容,并结合了真实场景数据 。数据来源包括公开基准数据集(如 GenVideo, LOKI, FakeClue, WildFake)和网络爬取的内容,确保了时效性和广泛性 。
-
结构化的标注生成:研究者利用多模态大语言模型 Gemini 2.5 Pro ,通过知识蒸馏过程生成结构化的、可解释的输出。特别地,他们采用了<think></think > 和 < conclusion></conclusion > 标签来引导模型先阐述推理过程,再给出最终判断 。标注时还会提供真实性标签,让模型解释分类背后的原因 。
-
细致的特征维度:解释被进一步分为空间特征(包含 8 个子维度,如不切实际的光照、局部模糊、字迹不可读等)和时间特征(包含 4 个子维度,如亮度差异、面部表情不自然、重复组件等,仅适用于视频)。

图 2:所提出的统一且可解释的 IVY-FAKE 数据集。来自不同领域的输入图像或视频与特定提示词一起由多模态大模型(MLLM)处理,模型通过时间和空间分析生成结构化、可解释的标注信息。
与现有数据集相比(见下表,改编自原论文表 1 ),IVY-FAKE 在数据规模、模态覆盖、特别是可解释性标注的平均 Token 长度上均展现出明显优势。
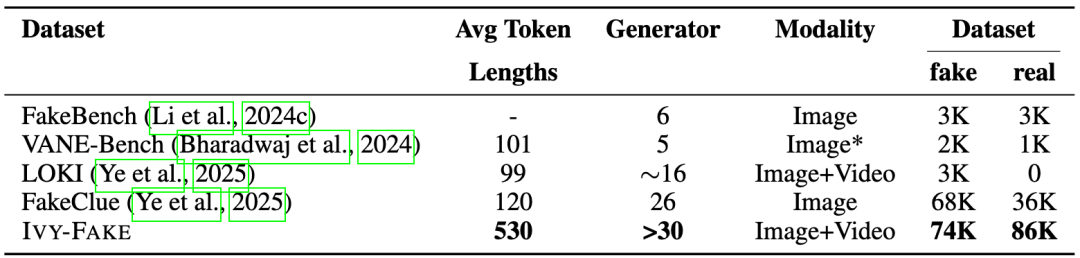
表 1:在二分类与可解释性任务中使用的不同数据集对比。标记长度通过 tiktoken 库中的 GPT-4o 分词器计算
2. IVY-XDETECTOR:统一的 AIGC 检测与解释架构
基于 IVY-FAKE 数据集,研究者们提出了 IVY-XDETECTOR 模型,这是一个专为鲁棒和可解释 AIGC 检测设计的多模态大语言模型 。
-
模型架构:遵循 LLaVA 范式 ,并使用 Ivy-VL-LLaVA 权重进行初始化 。其核心组件包括:
视觉编码器 (Visual Encoder):采用 SigLIP 处理输入图像和视频帧。
视觉投影器 (Visual Projector)
大语言模型 (LLM)
-
关键技术:
动态分辨率处理:对于高分辨率图像,采用分割成多个 384×384 子图再输入编码器的方式,有效输入分辨率最高可达 2304×2304 。
保留时间信息:对于视频输入,不对视频特征进行时间压缩,而是将所有帧的特征拼接后输入 LLM,以保留丰富的时间信息 。
-
渐进式多模态训练框架 (Progressive Multimodal Training):这是一个分阶段的优化策略,旨在逐步提升模型的 AIGC 检测和解释生成能力 。
阶段 1:赋予视频理解能力。使用 Ivy-VL-LLaVA(在图文基准上 SOTA,但缺乏视频数据经验)进行初始化 。在约 300 万个视频 – 文本对上进行训练(数据来自 VideoChatFlash, VideoLLaMA3 等),赋予模型基础的视频理解能力 。
阶段 2:AIGC 检测微调。利用 Demamba, FakeClue, WildFake 等数据集编译一个专门用于指令微调的目标数据集 。核心目标是训练 MLLM 进行二元 AIGC判别(“真” 或 “假”)。
阶段 3:指令驱动的检测与可解释性联合优化。将阶段 2 的 AIGC 检测数据与新增的、关注可解释性的指令数据结合起来进行联合训练 。此阶段的指令旨在引导模型生成详细的、分步骤的推理过程 。

图 3:Ivy-Detector 的三阶段训练流程,包括通用视频理解、检测指令微调和可解释性指令微调
通过这种三阶段渐进式训练,IVY-XDETECTOR 能够系统地发展出从辨别细微 AIGC 伪影、做出准确分类到阐明连贯合理解释的全面技能 。
四、实验结果:多维度验证,表现 SOTA
研究者们在多个基准上对 IVY-XDETECTOR 的检测和解释能力进行了广泛评估。
1. 图像内容分类
-
GenImage Benchmark :包含 Midjourney, Stable Diffusion 等 8 个主流生成器的子集。与 CNNSpot, DIRE, AIDE 等 5 个 SOTA 检测器相比,IVY-Det(论文中提出的检测器变体)的平均准确率从之前最佳的 86.88% 提升到了 98.36%,IVY-xDet(可解释性版本)也达到了 97.29% 。在 BigGAN 等子集上提升尤为明显,显示了新基准的优越性 。
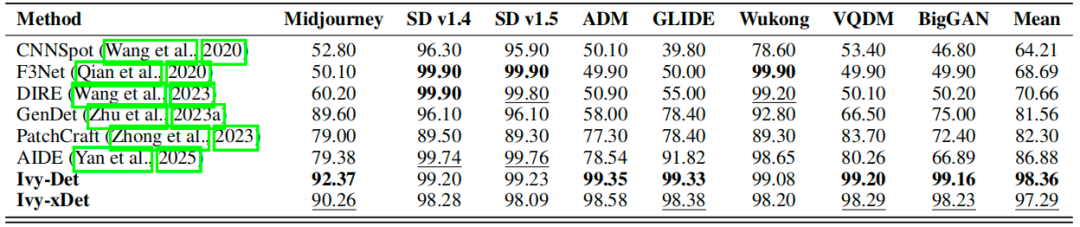
表 2:在 Genimage 数据集(Zhu 等,2023b)上的对比。不同检测器(行)在识别来自不同生成器(列)的真实与伪造图像时的准确率(%)。最佳结果用加粗标注,次佳结果用下划线标注。
-
Chameleon Benchmark :与 10 种检测方法对比,IVY-Det 和 IVY-xDet 的整体准确率分别达到了 85.20% 和 83.39%,远超之前最佳的 65.77%。

表 3:在 Chameleon 数据集(Yan 等,2025)上的对比。不同检测器(行)在识别真实与伪造图像时的准确率(%)。对于每个训练数据集,第一行表示整体准确率,第二行表示“伪造/真实”类别的准确率。
2. 视频内容分类
-
GenVideo Dataset :这是目前最大的生成视频检测基准。IVY-Det 和 IVY-xDet 在多数生成源上均实现了超过 99% 的准确率(F1 分数)。特别是在最具挑战性的 “HotShot” 子集上,IVY-Det 的召回率达到了 99.57%,而之前最佳方法仅为 65.43% 。
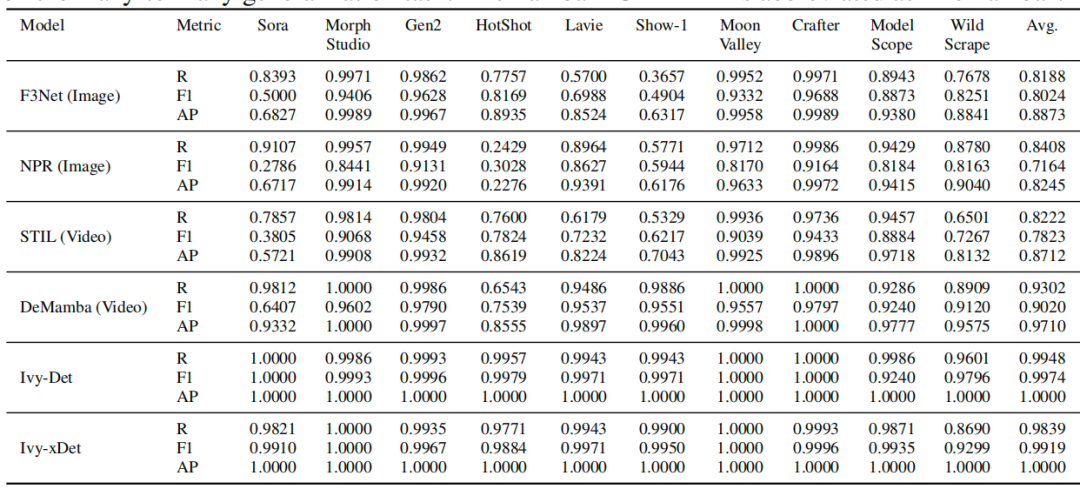
表 4:与 GenVideo 的对比。在多对多泛化任务中的 F1 分数(F1)、召回率(R)和平均精度(AP)。其中 「Demamba-XCLIP-FT」简称为 「Demamba」。
3. 图像和视频内容推理(可解释性)
研究者在完整的 IVY-FAKE 数据集上,将 IVY-xDet 与多个顶尖的开源(Qwen2.5-7B, InternVL2.5-8B)和闭源(GPT-4V, Gemini 2.5 Pro)MLLM进行了比较 。评估指标包括 ROUGE-L 和基于 LLM-as-a-judge 的四个维度:完整性、相关性、细节水平和解释质量 。
-
图像推理:IVY-xDet 在准确率(0.805)、ROUGE-L(0.271)以及 GPT 辅助评估平均分(4.40/5)上全面领先。
-
视频推理:IVY-xDet 同样表现最佳,准确率 0.945,ROUGE-L 为 0.303,GPT 辅助评估平均分 3.86/5。
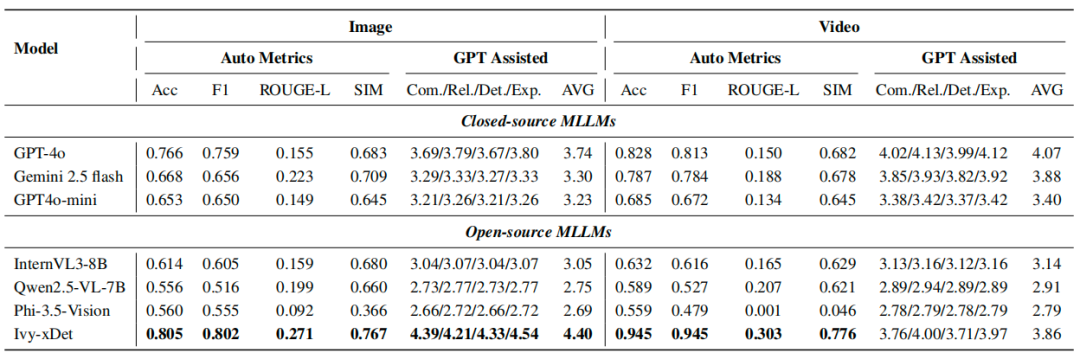
表 5:模型在图像与视频任务中的性能对比。“自动指标”包括准确率(Acc)、F1 分数、ROUGE-L 和相似度(SIM)评分。“GPT 协助评估”包括四个主观评判标准:全面性、相关性、细节和解释性,以及它们的平均得分。
这些结果表明,IVY-XDETECTOR 不仅在检测精度上达到了 SOTA,其生成自然语言解释的质量也显著优于其他基线模型,能够提供更透明、更易于人类理解的伪影描述 。
五、主要结论与启示:迈向透明可信的 AIGC 分析
这项研究为 AIGC 检测领域带来了几个关键突破:
1. IVY-FAKE 的开创性:首次提出了一个大规模、统一的、跨图像和视频模态的、用于可解释性 AIGC 检测的数据集 。这为后续研究提供了一个坚实的基础。
2. IVY-XDETECTOR 的卓越性能:所提出的统一视觉语言检测器在多个 AIGC 检测和可解释性基准上取得了 SOTA 表现 。
3. 推动可解释性发展:通过引入自然语言解释和结构化的推理过程,该工作有力地推动了 AIGC 检测从 “黑箱” 向 “白箱” 的转变,增强了模型的透明度和可信度。
4. 统一框架的价值:证明了构建统一的图像和视频 AIGC 检测框架是可行的,并且能够取得优异性能。
对行业而言,这项工作意味着未来我们有望部署更可靠、更易于理解的 AIGC 内容审查工具,这对于打击虚假信息、保护数字内容生态具有重要意义。对于研究者而言,IVY-FAKE 数据集和 IVY-XDETECTOR 模型为探索更深层次的可解释性和更鲁棒的检测算法开辟了新的道路。
六、案例分析
该研究还详细给出了当前不同大模型多模态内容的错误检测的案例。

图 10:图像示例 1,Ivy-xDetector 成功检测出基线方法遗漏的细微空间异常

图 11:视频示例 1,展示了 Ivy-xDetector 有效捕捉基线模型忽略的时间不一致性
七、未来展望:挑战与机遇并存
尽管 IVY-FAKE 和 IVY-XDETECTOR 取得了显著进展,但仍有一些值得进一步探索的方向:
1. 模型效率与时序建模:论文中也提到了当前的局限性,例如较高的空间 Token 负载迫使模型在时间维度上进行降采样,这可能影响对微妙时间伪影的检测精度和时间一致性的建模 。未来工作可以探索更高效的空间建模方法,以及更强的时序一致性保持机制。
2. 更细粒度的伪影定位与解释:虽然自然语言解释已经很有价值,但结合更精确的伪影定位(例如,通过热力图或边界框高亮显示可疑区域)可能会提供更直观的反馈。
3. 对抗攻击与鲁棒性:随着 AIGC 技术的发展,生成模型可能会产生更难以检测的伪影。持续评估和提升模型在对抗攻击下的鲁棒性至关重要。
4. 「道高一尺,魔高一丈」的循环:正如论文中「更广泛影响」部分提到的,检测技术的发展也可能被用于训练更强大的、更难被检测的生成模型 。如何在这种博弈中持续保持检测技术的领先,是一个长期的挑战。
5. 多模态融合的深化:目前模型主要还是基于视觉信息,未来可以探索融合文本、音频等多模态信息进行联合检测与解释,以应对更复杂的 AIGC 场景。
总而言之,IVY-FAKE 和 IVY-XDETECTOR 无疑是 AIGC 内容检测与可解释性研究领域的一项重要贡献。它们不仅为我们提供了强大的工具和基准,更为我们指明了未来研究的方向。我们期待看到更多基于此项工作的后续研究,共同推动 AIGC 技术健康、可信地发展。

©
(文:机器之心)