

机器之心编辑部
开源社区的人应该对 vLLM 不陌生,它是一个由加州大学伯克利分校团队开发的高性能、开源 LLM 推理和服务引擎,核心目标是提升 LLM 的推理速度(吞吐量)和资源利用率(尤其是内存),同时兼容 Hugging Face 等流行模型库。
简单来说,vLLM 能让 GPT、Mistral、LLaMA 等主流模型系列跑得更快、消耗更少资源,取得这些效果的关键是其创新的注意力机制实现方案 ——PagedAttention。
近日,DeepSeek AI 研究者、深度学习系统工程师俞星凯从零开始构建了一个轻量级 vLLM 实现 ——Nano-vLLM,将代码简化到了 1200 行。
目前,该项目在 GitHub 上收获了 200 多的 Star。
GitHub 地址:https://github.com/GeeeekExplorer/nano-vllm/tree/main
具体来讲,Nano-vLLM 具有以下三个核心亮点:
一是,快速离线推理。推理速度与 vLLM 相当。
二是,易读代码库。实现非常简洁,Python 代码减少到了 1200 行以下。
三是,优化套件。提供 Prefix 缓存、Torch 编译、CUDA 计算图等功能。
俞星凯在基准测试中采用了以下测试配置:
-
硬件:RTX 4070
-
模型:Qwen3-0.6B
-
总请求:256 个序列
-
输入长度:100–1024 tokens 之间随机采样
-
输出长度:100–1024 tokens 之间随机采样
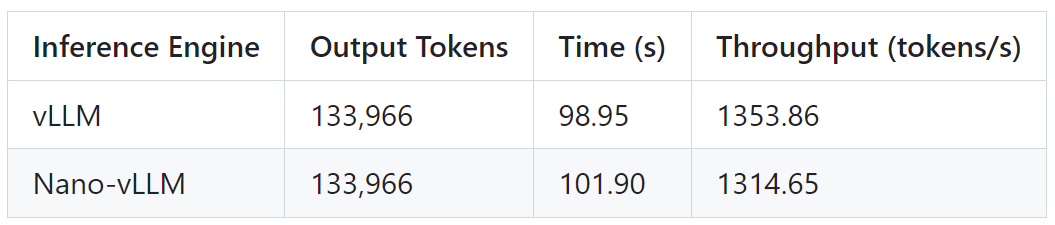
基准测试结果如下表所示,Nano-vLLM 与 vLLM 的输出 token 相同,时间略长,推理速度(吞吐量)稍逊一点点。整体而言,二者表现相当。
作者简介
Nano-vLLM 开发者俞星凯目前就职于 DeepSeek,参与过 DeepSeek-V3 和 DeepSeek-R1 的开发工作。
有意思的是,根据其 GitHub 主页,他还曾开发过一个植物大战僵尸 Qt 版,该项目也已经收获了 270 多星。此外,由于毕业于南京大学,他还曾参与了不少南京大学的计算机项目,包括南京大学计算机图形学绘图系统、南京大学分布式系统 Raft 算法最简实现、南京大学操作系统 OSLab 等。
而根据其 LinkedIn 页面可知,他曾先后在腾讯、幻方(DeepSeek 母公司)和字节跳动实习过。2023 年后入职 DeepSeek 成为深度学习系统工程师。
你是 vLLM 用户吗?会考虑尝试 Nano-vLLM 吗?

©
(文:机器之心)