



在AI领域进展不顺的Meta,最近有很多新动作。
一方面,Meta正敲定一项与Scale AI相关的140亿美元投资协议,外媒报道称,扎克伯格希望借此拉拢Scale AI的首席执行官Alexandr Wang加盟助推AI商业化进程。
另一方面,小扎决定亲自挖人带队,为Meta组建新的“超级智能”研究人员和工程师团队,在技术领先性方面重新赶上全球AGI竞赛步伐。
随着AI模型领域竞争愈发激烈,小扎对旗下Llama大模型的技术进展和市场表现十分不满,一系列新动作让外界猜疑,作为Meta首席AI科学家的Yann LeCun会不会就此离开。
就目前来看,一时半会儿可能不会走了,因为就在今天,Yann LeCun亲自出镜发布了Meta最新的世界模型V-JEPA 2,官方称,这是业内首个基于视频训练的世界模型,它能实现最先进的理解和预测能力,以及在新环境中进行零样本规划和机器人控制,相关技术论文也已出炉。

现代人工智能的一大挑战在于学会通过观察和理解世界并规划如何行动,Yann LeCun在视频中说道:“我们相信世界模型将为机器人技术开启一个新时代,使现实世界的人工智能代理帮助完成家务和体力任务,无需大量的机器人训练数据。”

V-JEPA 2是一个拥有12亿参数的模型,采用Meta的联合嵌入预测架构(JEPA)构建,2022年Meta团队就对外分享过该架构。
V-JEPA 2是在去年发布的首个视频训练模型V-JEPA基础上的迭代升级,其强化了动作预测与世界建模能力,使机器人能够在与陌生物体和环境的交互中完成任务。

具体而言,V-JEPA 2包含两个主要组件:
1、编码器,接收原始视频并输出嵌入,以捕获有关观察世界状态的有用语义信息。
2、预测器,它接收视频嵌入和关于要预测的内容的附加上下文,并输出预测的嵌入。
Meta团队使用基于视频的自监督学习来训练V-JEPA 2,且无需额外的人工注释即可在视频上进行训练,其训练包含两个阶段:无动作预训练,以及后续的动作条件训练。
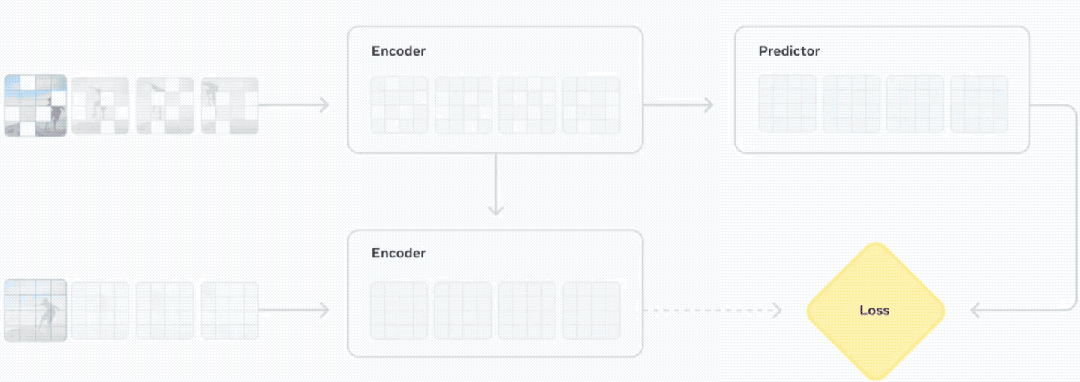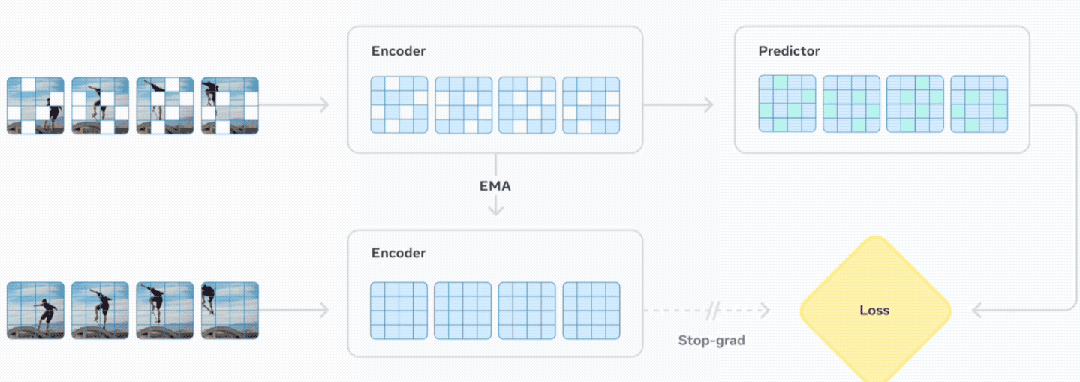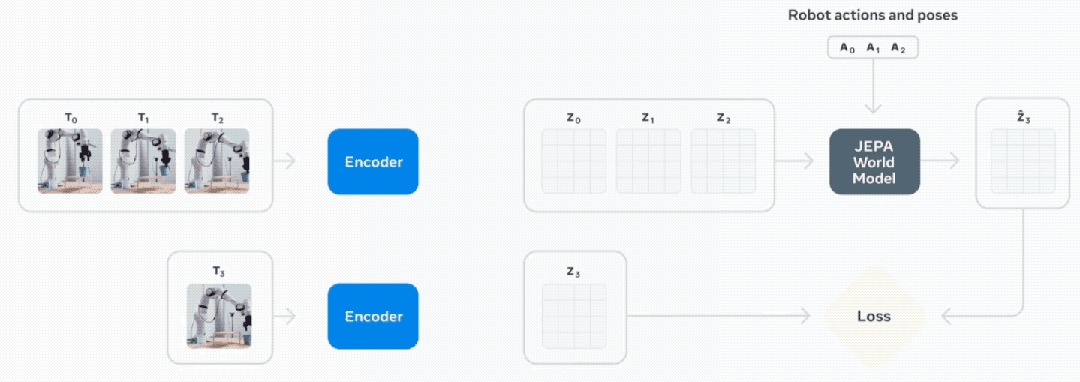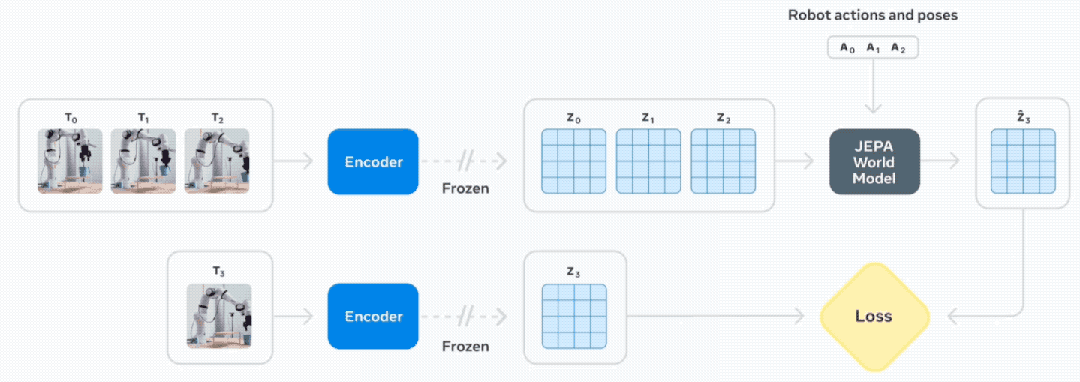
在预训练阶段,使用了来自不同来源的超过100万小时的视频和100万张图像,这些视觉数据有助于模型深入了解世界的运作方式,包括人与物体的互动方式、物体在物理世界中的移动方式以及物体与其他物体的互动方式,在预训练阶段之后,模型已经展现出与理解和预测相关的关键能力。
在无动作预训练阶段之后,模型可以预测世界未来如何演变,第二部分训练则专注于利用机器人数据(包括视觉观察和机器人正在执行的控制动作)来提升模型的规划能力。
Meta演示了如何在新环境中使用V-JEPA 2进行零样本机器人规划,并涉及训练期间未见过的物体,研究人员在开源DROID数据集上训练该模型,然后将其直接部署到实验室的机器人上,仅使用62小时的机器人数据进行训练就能构建出一个可用于规划和控制的模型。
V-JEPA 2上手就可执行一些基础任务,例如伸手够到、拾取物体并将其放置在新位置。

对于短期任务,研究人员使用V-JEPA 2编码器获取当前状态和目标状态的嵌入,机器人从观察到的当前状态出发,利用预测器进行规划,设想采取一系列候选动作的后果,并根据候选动作与期望目标的接近程度对其进行评级。
在每个时间步骤上,机器人都会重新规划并通过模型预测控制执行排名最高的下一个动作,以实现该目标。
对于长期任务,研究人员则指定一系列视觉子目标,机器人会尝试按顺序实现这些目标,类似于人类观察到的视觉模仿学习,凭借这些视觉子目标,V-JEPA 2在新环境和未知环境中拾取和放置新物体的成功率达到了65%至80%。
整体来看,这一成果是在没有从环境中的机器人收集任何数据,也没有进行任何特定训练或使用奖励的情况下实现的,证明了从网络规模数据和少量机器人交互数据中进行自监督学习就能生成具备预测、规划能力的世界模型。
Meta团队还发布了三个新的基准测试:MVPBench、IntPhys 2和CausalVQA,以评估现有模型从视频理解到物理世界推理的能力,同时还提供每个基准的人类评分,以揭示领先模型与人类在关键物理和推理任务上的性能差距。
其中,MVPBench通过多项选择题来衡量视频语言模型的物理理解能力;IntPhys 2专门用于衡量模型区分物理上合理和不合理场景的能力;CausalVQA则用来衡量视频语言模型回答与物理因果关系相关问题的能力。
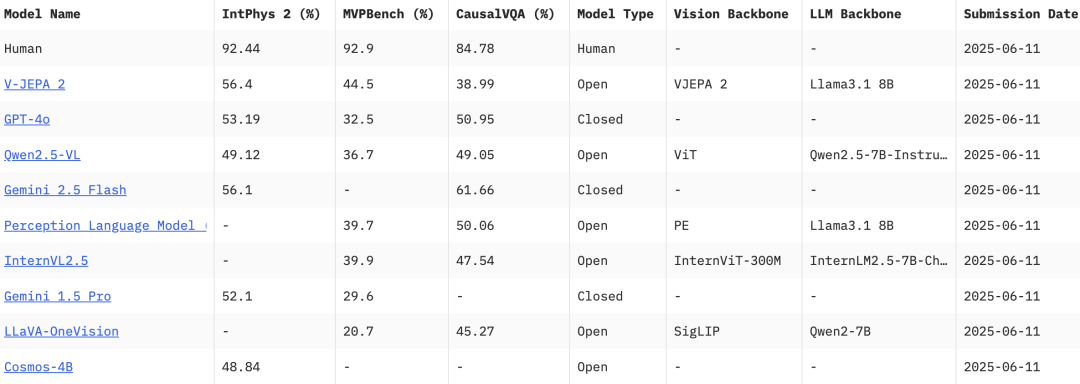
人类在这三个基准测试中都表现良好,准确率达到85%到95%,这为模型的改进指明了方向。
V-JEPA 2在运动理解任务上表现出色,在人类动作预测任务上达到了目前最先进水平,超越了以往的特定任务模型。此外,在将V-JEPA 2与大型语言模型对齐后,研究证明了该模型在80亿参数规模下的多个视频问答任务中表现出最先进的性能。
针对V-JEPA 2未来的研究,Meta团队表示可以从几个重要方向展开:
随着世界模型的不断改进,高级机器智能的新篇章正在拉开帷幕。
过去数月时间里,Meta在AI领域的进展可谓四处碰壁。
在开源模型方面,最新一代Llama 4模型的表现令开发者感到失望,该模型在LMArena排行榜上未能实现预期目标,整个开源社区影响力也败给了来自中国的DeepSeek和阿里通义千问(Qwen)系列开源大模型,与谷歌和OpenAI的旗舰模型差距更是越拉越大,Llama 4版本还被爆出榜单作弊丑闻导致信誉扫地,数位高管引咎离职。
据报道,扎克伯格现在与Meta高层领导创建了一个名为“招聘派对”的WhatsApp群组,旨在集思广益,亲自招募顶尖人才,吸引优秀AI研究员、工程师和企业家加入Meta超级智能团队,据悉新团队首批招募约50名成员,提供的薪酬待遇高达七位数至九位数。

扎克伯格也将回归“创始人模式”,采取亲力亲为的方式带领全新AI天团,与谷歌和OpenAI等对手一较高下。
谁正在加入Meta的超级智能团队?除了Scale AI的Alexandr Wang,据彭博社报道,谷歌DeepMind高级研究员Jack Rae或将加入,他在OpenAI和谷歌都有研发经历,曾在DeepMind工作超7年,此外,还有AI初创公司Sesame AI的机器学习专Johan Schalkwyk等可能也正在被挖过来。
从Yann LeCun亲自出镜推广新模型,到扎克伯格用“钞”能力四处挖人,都预示着Meta接下来会有一波新的AI攻势即将发起,能否扭转市场颓势重新成为开源大模型领跑者可以拭目以待。
-END-


(文:头部科技)