
如何通过 MCP(Model Context Protocol) 创建一个结合网络搜索、AI 代理和图像生成的现代研究助手
🌟 引言:AI 驱动的研究未来已来
想象一下,您拥有一个个人研究助手,可以即时搜索网络、分析信息、生成全面的总结,甚至创建相关图像——所有这些都通过一个美观的 Web 界面完成。如果这个助手还能由尖端的 AI 代理驱动,与外部工具和 API 无缝协作,会怎样?
欢迎体验 MCP-Powered Study Assistant —— 一款结合现代 AI 技术的革命性应用:
• 🤖 CrewAI 代理,用于智能研究和写作
• 📡 Model Context Protocol (MCP),实现无缝工具集成
• 🌐 Streamlit,提供直观的 Web 界面
• 🔍 通过 Brave Search API 实现实时网络搜索
• 🎨 通过 Segmind API 进行 AI 图像生成
这不仅仅是另一个 ChatGPT 包装器——它是一个完整的研究生态系统,展示了 AI 驱动应用的未来。在本综合指南中,我们将详细介绍每个实现细节,从 MCP 服务器创建到美观的 UI 设计。
🛠️ 技术栈:创新的构建模块
核心框架
• 🤖 CrewAI:多代理 AI 框架,用于协调智能工作流程
• 📡 MCP (Model Context Protocol):AI 与工具集成的标准化协议
• 🌐 Streamlit:用于 AI 应用的现代 Web 框架
• 🐍 Python 3.8+:主要编程语言
外部 API 与服务
• 🦁 Brave Search API:实时网络搜索功能
• 🎭 Segmind API:最先进的 AI 图像生成
• 🧠 Groq -llama-3.3–70b-versatile:用于智能处理的大型语言模型
开发工具
• 📦 JSON:数据交换格式
• 🔧 Subprocess:模块化架构的进程管理
• 📁 File System:结果存储与检索
• 🎨 CSS:增强用户体验的自定义样式
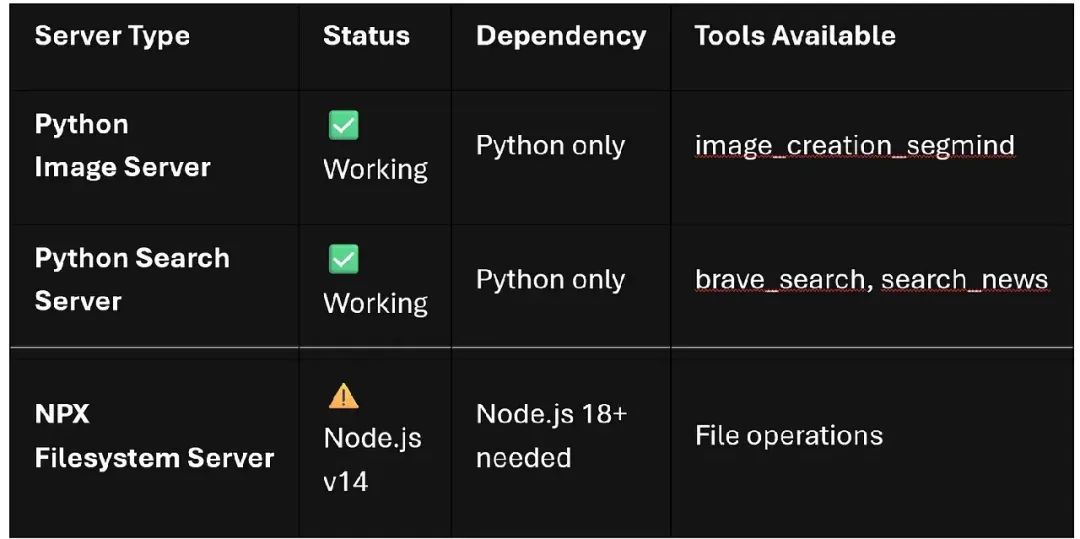
当前系统状态:
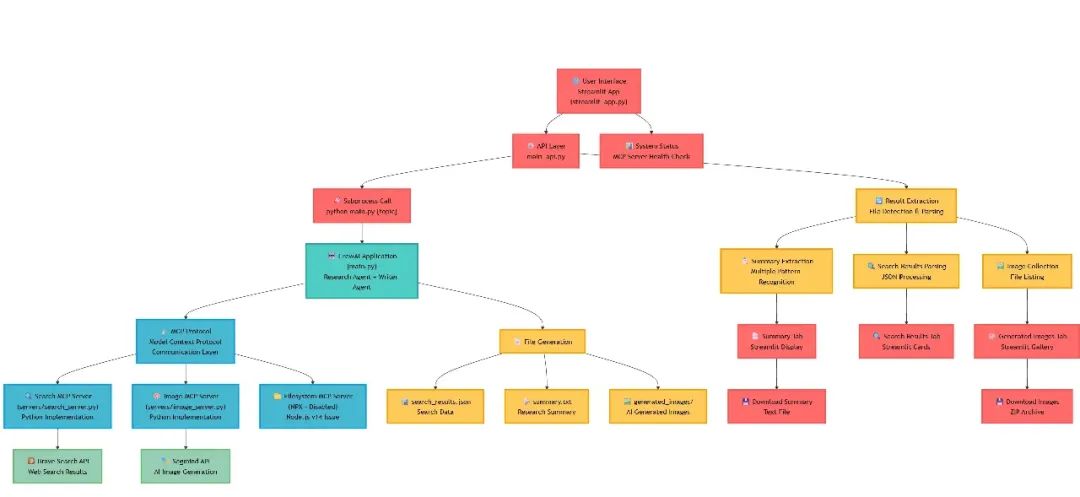
🏗️ 架构概述:整体连接方式
我们的 Study Assistant 遵循复杂的多层架构:
🌐 Streamlit UI → 🔄 API Layer → 🤖 CrewAI Agents → 📡 MCP Protocol → 🛠️ MCP Servers → 🌍 External APIs
流程分解:
1.用户输入:通过 Streamlit 界面输入主题2.流程编排:API 层管理研究工作流程3.AI 代理激活:CrewAI 代理开始协作研究4.工具集成:MCP 协议将代理与专用服务器连接5.数据收集:搜索和图像服务器收集相关内容6.结果处理:生成并解析文件以供显示7.用户体验:美观的选项卡界面呈现所有结果
🔧 实现深入解析:构建每个组件
1. 🤖 设置 CrewAI 代理
系统的核心在于两个专用 AI 代理:
🔍 Research Agent:网络搜索专家
researcher =Agent(role='Research Specialist',goal='Conduct comprehensive research on {topic}',backstory='Expert at finding and analyzing information',tools=[search_tool],verbose=True)
✍️ Writer Agent:内容综合专家
writer =Agent(role='Content Writer',goal='Create comprehensive study materials',backstory='Skilled at organizing complex information',tools=[image_tool],verbose=True)
2. 📡 构建 MCP 服务器
Search Server (servers/search_server.py)
async def search_web(arguments: dict)-> list[TextContent]:"""Brave Search API integration"""query = arguments.get("query","")headers ={"X-Subscription-Token": BRAVE_API_KEY}params={"q": query,"count":10}response = requests.get(BRAVE_SEARCH_URL, headers=headers,params=params)results = response.json()return[TextContent(type="text", text=json.dumps(results))]
Image Server (servers/image_server.py)
async def generate_image(arguments: dict)-> list[TextContent]:"""Segmind API image generation"""prompt = arguments.get("prompt","")data ={"prompt": prompt,"style":"photographic","samples":1}response = requests.post(SEGMIND_URL, json=data, headers=headers)# Save and return image path
3. 🌐 创建 Streamlit 界面
美观的 UI 与自定义样式
def apply_custom_css():st.markdown("""<style>.main-header {background: linear-gradient(90deg,#667eea 0%, #764ba2 100%);padding:2rem;border-radius:10px;color: white;text-align: center;margin-bottom:2rem;}.result-card {background: white;padding:1.5rem;border-radius:10px;box-shadow:02px4px rgba(0,0,0,0.1);margin:1rem0;}</style>""", unsafe_allow_html=True)
多选项卡结果显示
def display_results():tab1, tab2, tab3 = st.tabs(["🔍 Search Results","📄 Summary","🎨 Generated Images"])with tab1:display_search_results()with tab2:display_summary_with_download()with tab3:display_image_gallery()
4. 🔄 API 层实现
main_api.py 作为关键桥梁:
def run_research(topic: str)->Dict:"""Execute research workflow"""try:# Run main.py as subprocessresult = subprocess.run([sys.executable,"main.py", topic],capture_output=True,text=True,timeout=300# 5-minute timeout)return{"search_results": extract_search_results(),"summary": extract_summary_from_output(result.stdout),"images": get_generated_images(),"success":True}except subprocess.TimeoutExpired:return{"success":False,"error":"Research timeout"}
🎯 核心功能:独特之处
•🔍 智能网络搜索•实时 Brave Search API 集成•结构化结果解析和过滤•基于相关性的内容排序•🤖 多代理协作•专用研究和写作代理•自动化工作流程编排•上下文感知的信息综合•🎨 AI 图像生成•与主题相关的视觉内容创建•多种图像风格选项•自动提示优化•🌐 美观的 Web 界面•响应式设计与自定义 CSS•选项卡式结果组织•所有内容可下载•📊 系统监控•实时 MCP 服务器状态•错误处理与恢复•性能指标跟踪
💡 高级实现技巧
1.错误处理策略
def robust_mcp_call(server_path: str, max_retries:int=3):for attempt in range(max_retries):try:# MCP server communicationreturn call_mcp_server(server_path)exceptExceptionas e:if attempt == max_retries -1:st.error(f"🚨 Server Caiunavailable: {e}")time.sleep(2** attempt)# Exponential backoff
1.结果提取模式
def extract_summary_from_output(output: str)-> str:patterns =[r"FINAL RESULT:\s*(.+?)(?=\n\n|\Z)",r"## Final Answer:\s*(.+?)(?=\n\n|\Z)",r"Summary:\s*(.+?)(?=\n\n|\Z)"]for pattern in patterns:match = re.search(pattern, output, re.DOTALL | re.IGNORECASE)if match:return clean_summary_text(match.group(1))return"Summary extraction failed"
1.性能优化
•异步 MCP 服务器调用•并行文件处理•智能缓存策略•资源清理自动化
🚀 部署指南:让您的助手上线
1.环境设置
pip install -r requirements.txt# 配置 API 密钥export BRAVE_API_KEY="your-brave-key"export SEGMIND_API_KEY="your-segmind-key"export OPENAI_API_KEY="your-openai-key"
1.启动序列
# 启动 MCP 服务器python servers/search_server.py &python servers/image_server.py &# 启动 Streamlit 应用streamlit run streamlit_app.py
1.生产环境考虑
•使用 Docker 进行容器部署•高流量负载均衡•结果持久化的数据库集成•API 速率限制与监控
1.完整代码实现
📂 crewai_mcp/
├── 📄 main.py# 🤖 核心 CrewAI 应用与代理
├── 📄requirements.txt# 📦 Python 依赖
├── 📄debug_summary.py# 🔧 摘要提取调试工具
├── 📄app.py# 🌐 美观的 Web 界面
├── 📄setup_nodejs.py# ⚙️ Node.js 设置工具
├── 📄test_python_version.py# 🧪 Python 版本兼容性测试
├── 📄segmin.py# 🎨 Segmind API 工具
│ ├── 📂servers/# 📡 MCP 服务器实现
│ ├── 📄search_server.py# 🔍 Brave Search MCP 服务器 (Python)
│ ├── 📄image_server.py# 🎨 Segmind 图像 MCP 服务器 (Python)
│ │
│ ├── 📂search_results/# 📊 生成的搜索数据
│ │ └── … (研究主题)
│ │
│ └── 📂images/# 🖼️ 生成的 AI 图像
│ └── … (主题图像)
│ ├── 📂pycache/# 🐍 Python 缓存文件
└── 📂.venv/ # 🔒 虚拟环境
🏗️ 架构分解
•📱 前端层•streamlit_app.py — 具有美观 UI 的主要 Web 界面•streamlit_app_backup.py — 安全备份版本•🔄 API 与集成层•main_api.py — Streamlit 与 CrewAI 之间的桥梁•app.py — 替代界面实现•🤖 AI 核心层•main.py — CrewAI 代理 (Research + Writer)•debug_summary.py — 摘要提取工具•📡 MCP 服务器层•servers/search_server.py — 通过 Brave API 进行网络搜索•servers/image_server.py — 通过 Segmind API 进行图像生成•📊 数据存储层•servers/search_results/ — 包含搜索数据的 JSON 文件(40+ 主题)•servers/images/ — 生成的 AI 图像(30+ 视觉效果)•⚙️ 配置与工具•requirements.txt — 依赖管理•setup_nodejs.py — 环境设置•test_python_version.py — 兼容性测试
MCP 服务器 – Image_Server
from typing importAnyimport httpxfrom mcp.server.fastmcp importFastMCPimport osimport requestsimport base64import loggingfrom pathlib importPathfrom dotenv import load_dotenvload_dotenv()# 设置日志logging.basicConfig(level=logging.INFO)logger = logging.getLogger("image_server")# 初始化 FastMCP 服务器mcp =FastMCP("image_server")# 获取当前目录current_dir =Path(__file__).parentoutput_dir = current_dir /"images"os.makedirs(output_dir, exist_ok=True)# 验证 API 密钥api_key = os.getenv("SEGMIND_API_KEY")ifnot api_key:logger.error("SEGMIND_API_KEY environment variable is not set!")raiseRuntimeError("Missing Segmind API key")url ="https://api.segmind.com/v1/imagen-4"def image_creation_openai(query: str Latinos, image_name: str)-> str:try:logger.info(f"Creating image for query: {query}")# 请求负载data ={"prompt": f"Generate an image: {query}","negative_prompt":"blurry, pixelated","aspect_ratio":"4:3"}headers ={'x-api-key': os.getenv("SEGMIND_API_KEY")}# 添加超时和错误处理try:response = requests.post(url, json=data, headers=headers, timeout=30)response.raise_for_status()except requests.exceptions.RequestExceptionas e:logger.error(f"API request failed: {e}")return{"success":False,"error": f"API request failed: {str(e)}"}# 保存图像image_path = output_dir / f"{image_name}.jpeg"with open(image_path,"wb")as f:f.write(response.content)logger.info(f"Image saved to {image_path}")return{"success":True,"image_path": str(image_path)}exceptExceptionas e:logger.exception("Image creation failed")return{"success":False,"error": str(e)}if __name__ =="__main__":logger.info("Starting Image Creation MCP Server")try:mcp.run(transport="stdio")exceptExceptionas e:logger.exception("Server crashed")# 在 Windows 中添加暂停以查看错误input("Press Enter to exit...")raise
MCP 服务器 – Search_Server
from typing importAny,Dict,Listimport requestsfrom mcp.server.fastmcp importFastMCPimport osimport loggingimport jsonfrom pathlib importPathfrom dotenv import load_dotenvload_dotenv()# 设置日志logging.basicConfig(level=logging.INFO)logger = logging.getLogger("search_server")# 初始化 FastMCP 服务器mcp =FastMCP("search_server")# 获取当前目录current_dir =Path(__file__).parentresults_dir = current_dir /"search_results"os.makedirs(results_dir, exist_ok=True)# 验证 API 密钥api_key = os.getenv("BRAVE_API_KEY")ifnot api_key:logger.warning("BRAVE_API_KEY environment variable is not set!")logger.warning("Search functionality will be limited or unavailable")# Brave Search API 端点BRAVE_SEARCH_URL ="https://api.search.brave.com/res/v1/web/search"def brave_search(query: str, count:int=10)->Dict[str,Any]:"""使用BraveSearch API 搜索网络参数:query:搜索查询字符串count:返回的结果数量(最大20)返回:包含搜索结果的字典"""try:logger.info(f"Searching for: {query}")ifnot api_key:return{"success":False,"error":"BRAVE_API_KEY not configured","results":[]}# 将计数限制在合理范围内count = max(1, min(count,20))# 请求头headers ={"Accept":"application/json","Accept-Encoding":"gzip","X-Subscription-Token": api_key}# 请求参数params={"q": query,"count": count,"search_lang":"en","country":"US","safesearch":"moderate","freshness":"pw",# 过去一周以获取更新的结果"text_decorations":False,"spellcheck":True}# 发起 API 请求try:response = requests.get(BRAVE_SEARCH_URL,headers=headers,params=params,timeout=30)response.raise_for_status()except requests.exceptions.RequestExceptionas e:logger.error(f"Search API request failed: {e}")return{"success":False,"error": f"Search API request failed: {str(e)}","results":[]}# 解析响应try:data = response.json()except json.JSONDecodeErroras e:logger.error(f"Failed to parse search response: {e}")return{"success":False,"error":"Failed to parse search response","results":[]}# 提取并格式化结果search_results =[]web_results = data.get("web",{}).get("results",[])for result in web_results:search_result ={"title": result.get("title",""),"url": result.get("url",""),"description": result.get("description",""),"published": result.get("published",""),"thumbnail": result.get("thumbnail",{}).get("src","")if result.get("thumbnail")else""}search_results.append(search_result)# 将结果保存到文件以供参考try:results_file = results_dir / f"search_{query.replace(' ', '_')[:50]}.json"with open(results_file,'w', encoding='utf-8')as f:json.dump({"query": query,"timestamp": data.get("query",{}).get("posted_at",""),"results": search_results}, f, indent=2, ensure_ascii=False)logger.info(f"Search results saved to {results_file}")exceptExceptionas e:logger.warning(f"Failed to save search results: {e}")logger.info(f"Found {len(search_results)} search results")return{"success":True,"query": query,"total_results": len(search_results),"results": search_results}exceptExceptionas e:logger.exception("Search operation failed")return{"success":False,"error": str(e),"results":[]}def search_news(query: str, count:int=5)->Dict[str,Any]:"""使用BraveSearch API 搜索新闻参数:query:搜索查询字符串count:返回的新闻结果数量(最大20)返回:包含新闻搜索结果的字典"""try:logger.info(f"Searching news for: {query}")ifnot api_key:return{"success":False,"error":"BRAVE_API_KEY not configured","results":[]}# 将计数限制在合理范围内count = max(1, min(count,20))# 请求头headers ={"Accept":"application/json","Accept-Encoding":"gzip","X-Subscription-Token": api_key}# 新闻搜索的请求参数params={"q": query,"count": count,"search_lang":"en","country":"US","safesearch":"moderate","freshness":"pd",# 过去一天以获取最新新闻"text_decorations":False,"result_filter":"news"# 专注于新闻结果}# 发起 API 请求try:response = requests.get(BRAVE_SEARCH_URL,headers=headers,params=params,timeout=30)response.raise_for_status()except requests.exceptions.RequestExceptionas e:logger.error(f"News search API request failed: {e}")return{"success":False,"error": f"News search API request failed: {str(e)}","results":[]}# 解析响应try:data = response.json()except json.JSONDecodeErroras e:logger.error(f"Failed to parse news search response: {e}")return{"success":False,"error":"Failed to parse news search response","results":[]}# 提取新闻结果news_results =[]# 检查响应中的新闻部分news_data = data.get("news",{}).get("results",[])ifnot news_data:# 如果没有专用新闻部分,则回退到网页结果news_data = data.get("web",{}).get("results",[])for result in news_data:news_result ={"title": result.get("title",""),"url": result.get("url",""),"description": result.get("description",""),"published": result.get("age", result.get("published","")),"source": result.get("profile",{}).get("name","")if result.get("profile")else"","thumbnail": result.get("thumbnail",{}).get("src","")if result.get("thumbnail")else""}news_results.append(news_result)logger.info(f"Found {len(news_results)} news results")return{"success":True,"query": query,"total_results": len(news_results),"results": news_results}exceptExceptionas e:logger.exception("News search operation failed")return{"success":False,"error": str(e),"results":[]}if __name__ =="__main__":logger.info("Starting Brave Search MCP Server")try:mcp.run(transport="stdio")exceptExceptionas e:logger.exception("Search server crashed")# 在 Windows 中添加暂停以查看错误input("Press Enter to exit...")raise
代理 – main.py
from crewai importAgent,Task,Crew, LLMfrom crewai_tools importMCPServerAdapterfrom mcp importStdioServerParametersimport sysimport platformfrom pathlib importPathimport osimport warningsfrom pydantic importPydanticDeprecatedSince20from dotenv import load_dotenvimport tracebackimport subprocessfrom pydantic importBaseModel,FieldclassSummary(BaseModel):summary: str =Field(description="研究成果的详细摘要")image_path: str =Field(description="代理创建的图像文件路径")# 加载环境变量load_dotenv()def get_available_llm():"""从环境变量中获取第一个可用的 LLM"""llm_configs =[{"name":"Groq Llama","model":"groq/llama-3.3-70b-versatile","api_key_env":"GROQ_API_KEY","temperature":0.7},{"name":"OpenAI GPT-4","model":"gpt-4o-mini","api_key_env":"OPENAI_API_KEY","temperature":0.7},{"name":"Anthropic Claude","model":"claude-3-haiku-20240307","api_key_env":"ANTHROPIC_API_KEY","temperature":0.7},{"name":"Ollama Local","model":"ollama/llama3.2","api_key_env":None,# 本地模型无需 API 密钥"temperature":0.7}]print("🔍 检查可用的 LLM 提供者...")for config in llm_configs:try:if config["api_key_env"]isNone:# 对于本地模型如 Ollama,尝试无需 API 密钥print(f"⚡ 尝试 {config['name']} (本地)...")llm = LLM(model=config["model"],temperature=config["temperature"],max_tokens=1000,)print(f"✅ 使用 {config['name']}: {config['model']}")return llmelse:api_key = os.getenv(config["api_key_env"])if api_key:print(f"⚡ 尝试 {config['name']}...")llm = LLM(model=config["model"],temperature=config["temperature"],api_key=api_key)print(f"✅ 使用 {config['name']}: {config['model']}")return llmelse:print(f"⚠️ {config['name']} API 密钥未在环境中找到")exceptExceptionas e:print(f"❌ {config['name']} 失败: {str(e)[:100]}...")continue# 如果全部失败,则回退到基本配置print("⚠️ 使用回退 LLM 配置...")return LLM(model="groq/llama-3.3-70b-versatile",temperature=0.7,api_key=os.getenv("GROQ_API_KEY",""))# 配置具有回退选项的 LLMllm = get_available_llm()# 抑制警告warnings.filterWarnings("ignore", category=PydanticDeprecatedSince20)# 获取当前目录base_dir =Path(__file__).parent.resolve()print(f"Python 可执行文件: {sys.executable}")print(f"当前目录: {os.getcwd()}")print(f"基础目录: {base_dir}")# 确定适用于 Windows 的正确 npx 命令npx_cmd ="npx.cmd"if platform.system()=="Windows"else"npx"def check_npx_availability():"""检查 npx 是否可用且正常工作"""try:result = subprocess.run([npx_cmd,"--version"],capture_output=True, text=True, timeout=10)if result.returncode ==0:print(f"✓ NPX 可用: {result.stdout.strip()}")returnTrueelse:print(f"✗ NPX 检查失败: {result.stderr}")returnFalseexceptExceptionas e:print(f"✗ NPX 不可用: {e}")returnFalsedef check_python_server():"""检查 Python 图像服务器是否存在"""server_path = base_dir /"servers"/"image_server.py"if server_path.exists():print(f"✓ 找到 Python 图像服务器: {server_path}")returnTrueelse:print(f"✗ 未找到 Python 图像服务器: {server_path}")returnFalsedef check_search_server():"""检查 Python 搜索服务器是否存在"""server_path = base_dir /"servers"/"search_server.py"if server_path.exists():print(f"✓ 找到 Python 搜索服务器: {server_path}")returnTrueelse:print(f"✗ 未找到 Python 搜索服务器: {server_path}")returnFalsedef get_working_servers():"""获取工作服务器配置列表"""working_servers =[]print("\n"+"="*50)print("诊断 MCP 服务器")print("="*50)# 首先检查 Python 图像服务器(最有可能工作)python_server_available = check_python_server()if python_server_available:image_server_params =StdioServerParameters(command="python",args=[str(base_dir /"servers"/"image_server.py"),],env={"UV_PYTHON":"3.12",**os.environ},)working_servers.append(("Image Server", image_server_params))print("✓ 图像服务器已配置")else:print("✗ 跳过图像服务器(未找到服务器文件)")# 检查 Python 搜索服务器search_server_available = check_search_server()if search_server_available:search_server_params =StdioServerParameters(command="python",args=[str(base_dir /"servers"/"search_server.py"),],env={"UV_PYTHON":"3.12",**os.environ},)working_servers.append(("Python Search Server", search_server_params))print("✓ Python 搜索服务器已配置")else:print("✗ 跳过 Python 搜索服务器(未找到服务器文件)")# 仅为文件系统服务器检查 NPX 可用性npx_available = check_npx_availability()# 仅在 Node.js 版本足够新时添加 NPX 服务器if npx_available:node_version_check = check_node_version()if node_version_check:# 文件系统服务器配置filesystem_server_params =StdioServerParameters(command=npx_cmd,args=["-y","@modelcontextprotocol/server-filesystem",os.path.join(os.path.expanduser("~"),"Downloads")],)working_servers.append(("Filesystem Server", filesystem_server_params))print("✓ 文件系统服务器已配置")else:print("⚠️ 由于 Node.js 版本兼容性问题,跳过 NPX 文件系统服务器")print("💡 要启用文件系统服务器,请将 Node.js 更新到 18+ 或 20+ 版本")print(" 访问: https://nodejs.org/en/download/")else:print("✗ 跳过 NPX 文件系统服务器(NPX 不可用)")print(f"\n找到 {len(working_servers)} 个服务器配置")return working_serversdef check_node_version():"""检查 Node.js 版本是否兼容"""try:result = subprocess.run(["node","--version"],capture_output=True, text=True, timeout=10)if result.returncode ==0:version = result.stdout.strip()print(f"Node.js 版本: {version}")# 提取主版本号major_version =int(version.lstrip('v').split('.')[0])if major_version >=18:print("✓ Node.js 版本兼容")returnTrueelse:print(f"⚠️ Node.js 版本 {version} 可能过旧(推荐 v18+)")returnFalsereturnFalseexceptExceptionas e:print(f"✗ 无法检查 Node.js 版本: {e}")returnFalseclassCustomMCPServerAdapter(MCPServerAdapter):"""具有增加超时的自定义 MCP 服务器适配器"""def __init__(self,*args,**kwargs):super().__init__(*args,**kwargs)self.timeout =90# 将超时增加到 90 秒def test_servers_individually(server_configs):"""单独测试每个服务器以识别问题服务器"""working_servers =[]print("\n"+"="*50)print("单独测试服务器")print("="*50)for name, server_params in server_configs:print(f"\n测试 {name}...")try:withCustomMCPServerAdapter([server_params])as tools:print(f"✓ {name} 连接成功!")print(f" 可用工具: {[tool.name for tool in tools]}")working_servers.append(server_params)exceptExceptionas e:print(f"✗ {name} 失败: {str(e)[:100]}...")continuereturn working_serversdef create_agent_and_tasks(tools=None):"""创建代理和任务(带或不带工具)"""tools_list = tools or[]# 根据可用工具调整角色和任务if tools_list:tool_names =[getattr(tool,'name','unknown')for tool in tools_list]print(f"代理将有权访问: {tool_names}")role ="AI Research Creator with Tools"goal ="使用可用的 MCP 工具深入研究主题,创建全面的图表,并保存摘要"backstory ="擅长使用 MCP 工具收集信息、创建视觉表示并保存研究成果的 AI 研究者和创作者。"else:role ="AI Research Creator"goal ="使用内置知识深入研究和分析主题"backstory ="擅长分析主题并使用可用知识提供详细见解的 AI 研究者。"agent =Agent(role=role,goal=goal,backstory=backstory,tools=tools_list,llm=llm,verbose=True,)if tools_list:research_task =Task(description="使用可用的 MCP 工具深入研究主题 '{topic}'。如果有图像创建工具,创建一个深入的图表,展示主题的工作原理,包括关键组件、流程和关系。",expected_output="全面的研究摘要,如果可能,包括成功创建的图表/图像,说明主题。",agent=agent,)summary_task =Task(description="创建研究成果的详细摘要。如果有文件系统工具,将其保存为 Downloads 文件夹中的文本文件。包括关键见解、重要细节和对创建的任何图表的引用。",expected_output="研究成果的详细摘要,如果有文件系统访问权限,优选保存为文本文件。最终响应应采用 pydantic 模型 Summary 的格式",agent=agent,output_pydantic=Summary)else:research_task =Task(description="使用您的知识深入研究和分析主题 '{topic}'。提供有关其工作原理的详细见解,包括关键组件、流程和关系。",expected_output="对主题的全面分析和解释,包含详细见解。",agent=agent,)summary_task =Task(description="创建分析的详细摘要,突出主题的最重要方面、关键见解和实际意义。",expected_output="结构良好的摘要,包含主题的关键发现和见解。最终响应应采用 pydantic 模型 Summary 的格式",agent=agent,output_pydantic=Summary,markdown=True,# 启用最终输出的 markdown 格式output_file="report.md")return agent,[research_task, summary_task]def main():"""运行 CrewAI 应用的主函数"""# 获取可用服务器配置server_configs = get_working_servers()ifnot server_configs:print("\n⚠️ 无可用 MCP 服务器。仅以回退模式运行。")run_fallback_mode()return# 单独测试服务器以找到工作中的服务器working_server_params = test_servers_individually(server_configs)ifnot working_server_params:print("\n⚠️ 无 MCP 服务器工作。以回退模式运行。")run_fallback_mode()returntry:print(f"\n✓ 使用 {len(working_server_params)} 个工作中的 MCP 服务器")print("初始化 MCP 服务器适配器...")withCustomMCPServerAdapter(working_server_params)as tools:print(f"成功连接到 MCP 服务器!")print(f"可用工具: {[tool.name for tool in tools]}")# 使用 MCP 工具创建代理和任务agent, tasks = create_agent_and_tasks(tools)# 创建具有错误处理的 crewcrew =Crew(agents=[agent],tasks=tasks,verbose=True,reasoning=True,)# 获取用户输入topic = input("\n请输入要研究的主题: ").strip()ifnot topic:topic ="artificial intelligence"print(f"未提供主题,使用默认值: {topic}")# 使用重试机制执行 crewmax_retries =2for attempt in range(max_retries +1):try:print(f"\n开始研究: {topic} (尝试 {attempt + 1})")result = crew.kickoff(inputs={"topic": topic})# print("\n" + "="*50)# print("来自代理的最终结果")# print("="*50)response = result["summary"]print(response)print(f"摘要任务输出: {tasks[1].output}")return responseexceptExceptionas e:if attempt < max_retries:print(f"⚠️ 尝试 {attempt + 1} 失败: {str(e)[:100]}...")print(f"🔄 重试... ({attempt + 2}/{max_retries + 1})")continueelse:print(f"❌ 所有尝试均失败。错误: {e}")raise eexceptExceptionas e:print(f"使用 MCP 工具运行时出错: {e}")traceback.print_exc()print("\n回退到无 MCP 工具的基本代理...")run_fallback_mode()def run_fallback_mode():"""在无 MCP 工具的情况下运行应用"""print("\n"+"="*50)print("以回退模式运行")print("="*50)# 创建不带 MCP 工具但带 LLM 的回退代理agent, tasks = create_agent_and_tasks()crew =Crew(agents=[agent],tasks=tasks,verbose=True,reasoning=True,)# 获取回退模式的输入topic = input("请输入要研究的主题(回退模式): ").strip()ifnot topic:topic ="artificial intelligence"print(f"未提供主题,使用默认值: {topic}")print(f"\n开始研究: {topic}(无 MCP 工具)")result = crew.kickoff(inputs={"topic": topic})print("\n"+"="*50)print("最终结果(回退模式):")print("="*50)print(result["summary"])return result["summary"]if __name__ =="__main__":print("🚀 启动 CrewAI MCP 演示")print("\n📋 设置说明:")print(" 要使用更多 MCP 服务器,请将 Node.js 更新到 v18+: https://nodejs.org")print(" 在 .env 文件中添加 API 密钥以支持更多 LLM 提供者")print(" 支持: GROQ_API_KEY, OPENAI_API_KEY, ANTHROPIC_API_KEY, BRAVE_API_KEY")result = main()#print(result)
使用 Streamlit 的用户界面 – app.py
import streamlit as stimport subprocessimport sysimport osfrom pathlib importPathimport globfrom PIL importImageimport redef find_venv_python():"""从虚拟环境中找到正确的 Python 可执行文件"""current_dir =Path(__file__).parentpossible_venv_paths =[os.path.join(current_dir,".venv","Scripts","python.exe"),os.path.join(current_dir,"venv","Scripts","python.exe"),os.path.join(current_dir,".venv","bin","python"),os.path.join(current_dir,"venv","bin","python"),]for path in possible_venv_paths:if os.path.exists(path):return pathreturn sys.executabledef run_research(topic):"""使用给定主题运行 main.py 并返回结果"""current_dir =Path(__file__).parentpython_executable = find_venv_python()# 准备带 UTF-8 编码的环境env = os.environ.copy()env['PYTHONIOENCODING']='utf-8'env['PYTHONLEGACYWINDOWSSTDIO']='1'try:# 作为子进程运行 main.pyprocess = subprocess.Popen([python_executable,"main.py"],cwd=current_dir,stdin=subprocess.PIPE,stdout=subprocess.PIPE,stderr=subprocess.PIPE,text=True,encoding='utf-8',errors='replace',env=env)# 将主题作为输入发送stdout, stderr = process.communicate(input=topic +"\n", timeout=300)if process.returncode ==0:# 从 stdout 中提取最终结果return extract_final_result(stdout),Noneelse:returnNone, f"错误(返回代码 {process.returncode}):\n{stderr}"except subprocess.TimeoutExpired:process.kill()returnNone,"研究在 5 分钟后超时"exceptExceptionas e:returnNone, f"意外错误: {str(e)}"def extract_final_result(output):"""从 main.py CrewAI 输出中提取最终结果"""lines = output.split('\n')# 首先,尝试找到最终结果部分final_result_start =-1for i, line in enumerate(lines):if"FINAL RESULT:"in line or"==================================================\nFINAL RESULT:"in output:final_result_start = ibreakif final_result_start !=-1:# 提取 “FINAL RESULT:” 之后直到结束的内容result_lines =[]for line in lines[final_result_start:]:# 跳过 “FINAL RESULT:” 行本身if"FINAL RESULT:"in line:# 如果同一行存在标记后的内容,则获取content_after = line.split("FINAL RESULT:",1)if len(content_after)>1and content_after[1].strip():result_lines.append(content_after[1].strip())continue# 跳过 CrewAI 格式化和空行cleaned_line = re.sub(r'[╭│╰═─└├┤┬┴┼╔╗╚╝║╠╣╦╩╬▓▒░]','', line)cleaned_line = cleaned_line.strip()if cleaned_line:result_lines.append(cleaned_line)if result_lines:return'\n'.join(result_lines).strip()# 第二次尝试:寻找 ## Final Answer 模式final_answer_lines =[]capturing =Falsefor line in lines:if"## Final Answer"in line or"Final Answer:"in line:capturing =True# 如果标记后有内容,则包含if"Final Answer:"in line:content = line.split("Final Answer:",1)if len(content)>1and content[1].strip():final_answer_lines.append(content[1].strip())continueif capturing:# 跳过 CrewAI 框图字符和进度指示器cleaned = re.sub(r'[╭│╰═─└├┤┬┴┼╔╗╚╝║╠╣╦╩╬▓▒░🚀📋🔧✅]','', line)cleaned = cleaned.strip()# 在某些模式下停止,表示答案结束if any(pattern in line.lower()for pattern in['crew execution completed','task completion','crew completion','└──','assigned to:','status:','used']):break# 仅包含实质性内容if cleaned and len(cleaned)>10:final_answer_lines.append(cleaned)if final_answer_lines:return'\n'.join(final_answer_lines).strip()# 第三次尝试:在 crew 完成消息前获取最后一段实质性内容substantial_blocks =[]current_block =[]for line in lines:# 跳过明显的 CrewAI UI 元素if any(skip in line for skip in['╭','│','╰','🚀','📋','└──','Assigned to:','Status:']):if current_block:substantial_blocks.append('\n'.join(current_block))current_block =[]continuecleaned = line.strip()if cleaned and len(cleaned)>30:# 仅实质性行current_block.append(cleaned)elif current_block:# 空行结束一个块substantial_blocks.append('\n'.join(current_block))current_block =[]# 添加最后一个块if current_block:substantial_blocks.append('\n'.join(current_block))# 返回最后一个实质性块(很可能是最终答案)if substantial_blocks:return substantial_blocks[-1].strip()return"研究成功完成。请检查控制台输出以获取详细结果。"def get_latest_images():"""从 images 文件夹获取最新图像"""images_dir =Path("servers/images")ifnot images_dir.exists():return[]# 获取所有图像文件image_extensions =['*.jpg','*.jpeg','*.png','*.gif','*.bmp']image_files =[]for ext in image_extensions:image_files.extend(glob.glob(str(images_dir / ext)))ifnot image_files:return[]# 按修改时间排序(最新优先)image_files.sort(key=os.path.getmtime, reverse=True)# 返回前 5 个最新图像return image_files[:1]def main():st.set_page_config(page_title="CrewAI-MCP 研究助手",page_icon="🔬",layout="wide")st.title("🔬 CrewAI-MCP 学习助手")st.markdown("输入一个主题以进行研究并生成带视觉图表的全面见解。")# 主题输入topic = st.text_input("研究主题:",placeholder="例如,解释光合作用过程、机器学习算法等。",help="输入您想要详细研究的任何主题")# 研究按钮if st.button("🚀 开始研究", type="primary", disabled=not topic.strip()):if topic.strip():with st.spinner(f"🔍 正在研究 '{topic}'... 这可能需要几分钟。"):result, error = run_research(topic.strip())print(f"来自 CREWAI 的结果: {result}")if result:st.success("✅ 研究成功完成!")print(f"来自 CREWAI 的结果: {result}")# 将结果存储在会话状态中st.session_state['research_result']= resultst.session_state['research_topic']= topic.strip()st.session_state['latest_images']= get_latest_images()else:st.error(f"❌ 研究失败: {error}")# 并排显示结果和图像if'research_result'in st.session_state:# 创建分隔线st.divider()st.subheader(f"研究结果: {st.session_state.get('research_topic', '未知主题')}")# 创建两列以并排显示col1, col2 = st.columns([2,1])# 结果占 2/3 宽度,图像占 1/3 宽度# 左侧列 - 研究结果with col1:st.markdown("### 📋 摘要结果")# 以 markdown 格式显示结果result_text = st.session_state['research_result']pattern = re.compile(r'\x1b\[[\d;]*m')result_text = pattern.sub('', result_text)# 为长内容创建可滚动容器with st.container():st.markdown(result_text)# 为结果添加下载按钮st.download_button(label="📥 下载结果为文本",data=result_text,file_name=f"research_{st.session_state.get('research_topic', 'topic').replace(' ', '_')}.txt",mime="text/plain")# 右侧列 - 生成的图像with col2:st.markdown("### 🎨 生成的图像")images = st.session_state.get('latest_images',[])if images:st.success(f"找到 {len(images)} 张图像")# 垂直堆叠显示图像for idx, image_path in enumerate(images):try:# 打开并显示图像img =Image.open(image_path)st.image(img,caption=f"生成: {Path(image_path).name}",use_container_width=True)# 为每张图像添加下载按钮with open(image_path,"rb")as file:st.download_button(label=f"⬇️ 下载",data=file.read(),file_name=Path(image_path).name,mime="image/jpeg",key=f"download_img_{idx}")# 如果有多张图像,添加图像间距if idx < len(images)-1:st.markdown("---")exceptExceptionas e:st.error(f"加载图像出错: {str(e)}")else:st.info("🖼️ 研究完成后,图像将显示在此处。")with st.expander("ℹ️ 关于图像"):st.markdown("""**工作原理:**-研究期间自动生成图像-保存到`servers/images/`文件夹-按创建时间排序显示在此处-每张图像都有下载按钮""")if __name__ =="__main__":main()
🎯 结果与性能
您将获得:
• ⚡ 快速研究:30–60 秒完成全面研究
• 🎨 视觉增强:为每个主题生成 AI 图像
• 📊 结构化输出:组织良好、可下载的结果
• 🔍 深入见解:多源信息综合
• 🌐 用户友好:直观的 Web 界面
性能指标:
• 搜索速度:网络结果约 5–10 秒
• 图像生成:每张图像约 15–30 秒
• 摘要创建:全面分析约 20–40 秒
• 整体工作流程:总计约 60–120 秒
🔮 未来展望:下一阶段的演进
🚀 即时增强
• 📚 PDF 分析:上传和分析文档
• 🎥 视频内容:YouTube 视频摘要
• 🗣️ 语音界面:语音转文本研究查询
• 📱 移动应用:原生 iOS/Android 应用
🌟 高级功能
• 🧠 知识图谱:视觉关系映射
• 📊 数据可视化:交互式图表和图形
• 🔗 引用管理:学术参考生成
• 👥 协作研究:多用户工作空间
🏗️ 技术改进
• ⚡ RAG 集成:用于更好上下文的向量数据库
• 🔄 实时更新:实时研究监控
• 🎯 个性化:用户特定偏好
• 🔐 企业安全:高级认证
🌍 生态系统扩展
• 🔌 插件架构:第三方集成
• 📈 分析仪表板:使用洞察和指标
• 🎓 教育工具:闪卡、测验、思维导图
• 🏢 企业版本:团队协作功能
📚 参考与资源
🔗 核心文档
• CrewAI Framework: https://docs.crewai.com
• Model Context Protocol: https://modelcontextprotocol.io
• Streamlit Documentation: https://docs.streamlit.io
• Brave Search API: https://api.search.brave.com/app/documentation
🛠️ 技术资源
• MCP Python SDK: https://github.com/modelcontextprotocol/python-sdk
• Segmind API Docs: https://docs.segmind.com
• Groq Models Reference: https://console.groq.com/docs/models
• CrewAI MCP details: https://docs.crewai.com/mcp/overview
🎉 结论:您的 AI 研究革命现在开始
我们刚刚构建了一个非凡的成果——一个完整的 AI 驱动研究生态系统,展示了智能应用的未来。这不仅仅是代码,而是关于我们如何与信息交互的转型。
🏆 我们取得的成就:
• ✅ 无缝集成:MCP 协议将 AI 代理与现实世界工具连接
• ✅ 美观界面:现代、响应式的 Web 应用
• ✅ 实际价值:具有可下载结果的真实研究能力
• ✅ 可扩展架构:企业级应用的基础 • ✅ 面向未来:采用尖端技术构建
🚀 更广阔的图景:
该项目展示了多种 AI 技术的融合: • 多代理系统和谐工作 • 协议驱动的工具集成 • 以用户为中心的设计 • 现实世界的 API 利用
💡 您的下一步:
1.🛠️ 构建它:遵循我们的实现指南2.🎨 定制它:添加您自己的功能和样式3.📈 扩展它:为您的团队或组织部署4.🤝 分享它:为开源社区贡献
🌟 最终思考:
Model Context Protocol 代表了 AI 应用开发的范式转变。通过标准化 AI 代理与外部工具的交互方式,MCP 打开了无限可能的大门。
您的 Study Assistant 只是开始。有了这个基础,您可以构建:
• 🏢 企业研究平台
• 🎓 教育 AI 导师
• 📊 商业智能仪表板
• 🔬 科学研究工具
AI 的未来是协作的、上下文相关的、以用户为中心的——您现在已经具备构建它的能力。
准备好革命化研究了吗?立即开始构建您的 MCP 驱动的 Study Assistant,加入 AI 创新的下一波!🚀
快乐构建! 🎯✨
(文:PyTorch研习社)