

-
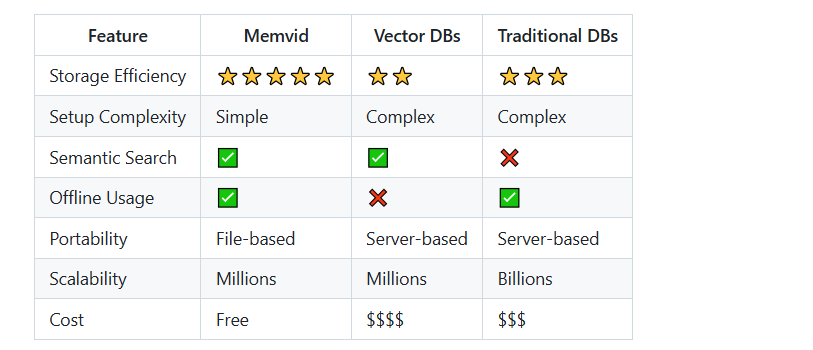
与传统解决方案的比较
-
从文档构建记忆
from memvid import MemvidEncoderimport os# Load documentsencoder = MemvidEncoder(chunk_size=512, overlap=50)# Add text filesfor file in os.listdir("documents"):with open(f"documents/{file}", "r") as f:encoder.add_text(f.read(), metadata={"source": file})# Build optimized videoencoder.build_video("knowledge_base.mp4","knowledge_index.json",fps=30, # Higher FPS = more chunks per secondframe_size=512 # Larger frames = more data per frame)
-
高级搜索与检索
from memvid import MemvidRetriever# Initialize retrieverretriever = MemvidRetriever("knowledge_base.mp4", "knowledge_index.json")# Semantic searchresults = retriever.search("machine learning algorithms", top_k=5)for chunk, score in results:print(f"Score: {score:.3f} | {chunk[:100]}...")# Get context windowcontext = retriever.get_context("explain neural networks", max_tokens=2000)print(context)
-
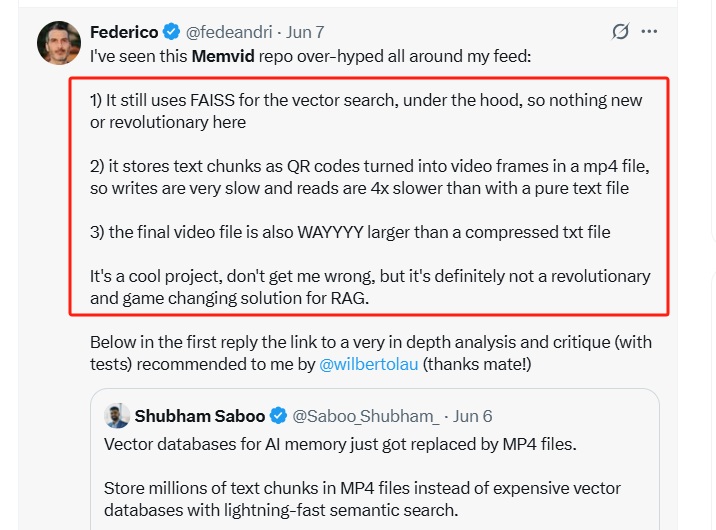
它仍然在底层使用FAISS进行向量搜索,所以这里没有什么新东西或革命性的内容。 -
它将文本片段作为二维码存储在mp4文件的视频帧中,因此写入速度非常慢,读取速度比纯文本文件慢4倍。 -
最终的视频文件也比压缩过的txt文件大得多。
-
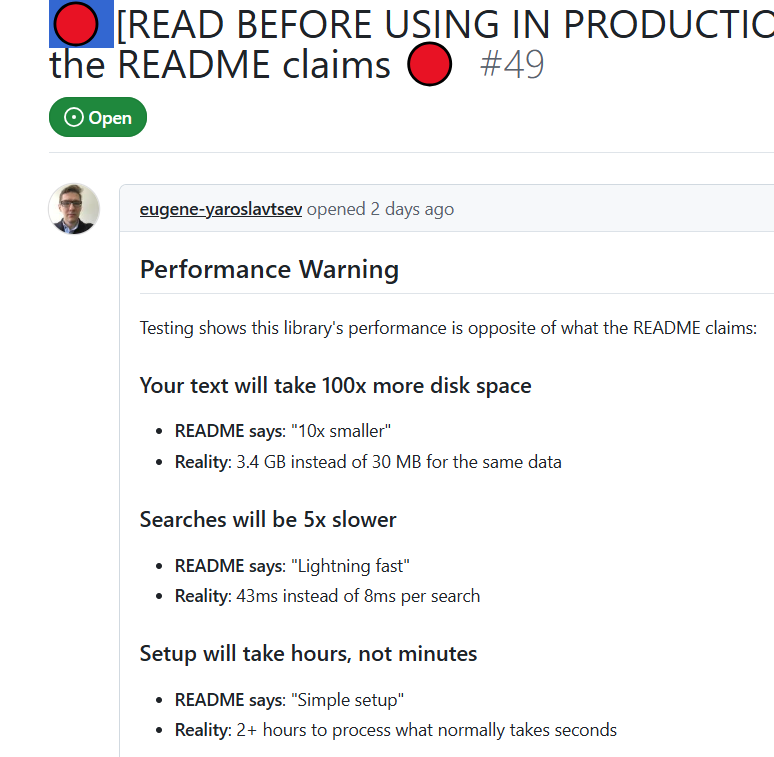
文本将占用100倍的磁盘空间 -
搜索速度将降低5倍 -
设置需要数小时,而不是几分钟
https://github.com/Olow304/memvid测试与分析报告 https://github.com/janekm/retrieval_comparison/blob/main/memvid_critique.md
(文:PaperAgent)