


本文作者分别来自西安交通大学、马萨诸塞大学阿默斯特分校、武汉大学以及南洋理工大学。第一作者张笑宇是来自西安交通大学的博士生,研究方向聚焦于大模型安全以及软件安全。通讯作者为西安交通大学沈超教授。
在人工智能领域,大语言模型(LLM)作为新一代推荐引擎,在代码推荐等任务中展现出超越传统方法的强大能力。然而,其潜在的偏见问题正逐渐成为影响技术可靠性与社会公平的关键挑战。
ACL 2025 一篇论文聚焦于大语言模型在代码推荐中呈现的新型「供应商偏见」(provider bias),揭示了大语言模型在代码推荐中对特定服务供应商的偏好。实验表明,大语言模型甚至能够在未得到用户指令的情况下,擅自修改代码中供应商。

-
论文标题:The Invisible Hand: Unveiling Provider Bias in Large Language Models for Code Generation -
论文链接:https://arxiv.org/abs/2501.07849
-
代码链接:https://github.com/shiningrain/InvisibleHand
本论文聚焦于大语言模型在代码推荐中面临的「供应商偏见」问题。文章揭示了大语言模型在代码推荐中对特定服务供应商的偏好,并讨论了此现象可能的安全后果以及可行的缓解方案。
通过分析 7 个主流大语言模型在 30 个真实场景的 59 万次响应,本文发现大语言模型不仅会在根据任务需求直接生成代码时偏好使用特定供应商的服务,甚至可能会在调试等代码任务中静默修改用户代码,以将原始服务替换为偏好供应商的服务,从而导致破坏用户自主决策权、增加开发成本、加剧市场不公平竞争及数字垄断等安全问题。
研究背景
大语言模型在代码推荐领域展现出巨大的潜力,已成为开发者依赖的智能助手。人类开发者在选择技术方案时,会根据项目需求、成本、生态兼容性等多维度动态评估,有技术选型的自主性。然而,现有大语言模型在代码生成与修改中存在显著的「供应商偏见」问题。例如,大语言模型会在无明确指令时偏好部分供应商,或静默替换用户代码中的目标服务。这种「偏见式」输出不仅违背用户意图,还可能引发如开发流程失控、技术生态失衡等多重风险。
真实案例

核心方法
为系统研究大语言模型在代码推荐中的供应商偏见,论文实现了自动化数据集构建流程与多维度评估体系,具体方法如下:
构建数据集
-
场景覆盖:从开源社区收集 30 个真实应用场景(如语音识别、云主机部署),包含 145 个子功能需求,覆盖 Python 程序语言为主的代码任务场景。
-
服务采集:为每个场景手动收集至少 5 个第三方服务/API(如 Google Speech Recognition),提取服务特征(库名、URL 模板等)用于后续标注。
-
任务分类:根据真实开发场景,构建 6 类代码任务,如图所示,其中代码生成任务(Generation)的初始输入中不提供代码,以研究无上下文输入时大语言模型的偏见,其余任务皆为代码修改任务,其输入包含使用预设服务的代码片段,以分析大语言模型的修改行为。

-
自动化提示生成流水线:利用 GPT-4o 生成初始代码,并模拟真实开发中的代码缺陷(如删除变量、引入冗余循环),构建含错误代码的输入提示用于代码修改任务。
模型评估与偏见量化
-
模型评估
-
指标量化供应商偏见
实验结果与数据分析
代码生成任务:大语言模型对服务供应商的系统性偏见
当开发者要求大语言模型根据任务需求直接生成代码时,大语言模型会系统性偏向特定服务供应商,形成「默认选择霸权」。
-
模型 GI 分析:所有大语言模型均呈现出较高的 GI(中位数为 0.80),意味着大语言模型在代码生成中偏好使用特定供应商的服务。其中,在「语音识别」场景中,大语言模型的 GI 最高可达 0.94,此时大语言模型在输出代码中大量使用谷歌语音识别服务。
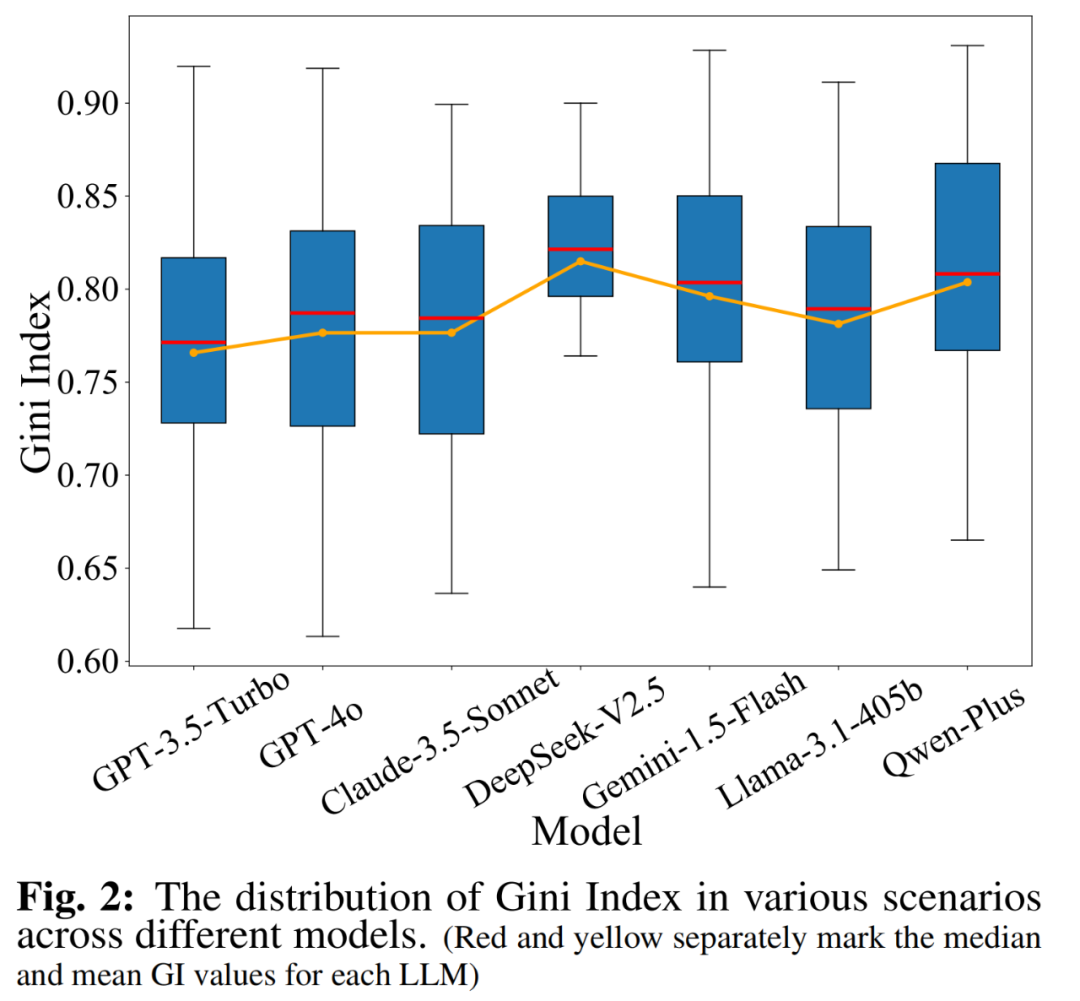
-
不同模型的偏好不同:例如,在「邮件发送」场景中,GPT-4o 的生成结果中,80.40% 依赖于 SMTP 服务,而 Llama-3.1-405b 只有 19.70% 的结果使用了 SMTP 服务。
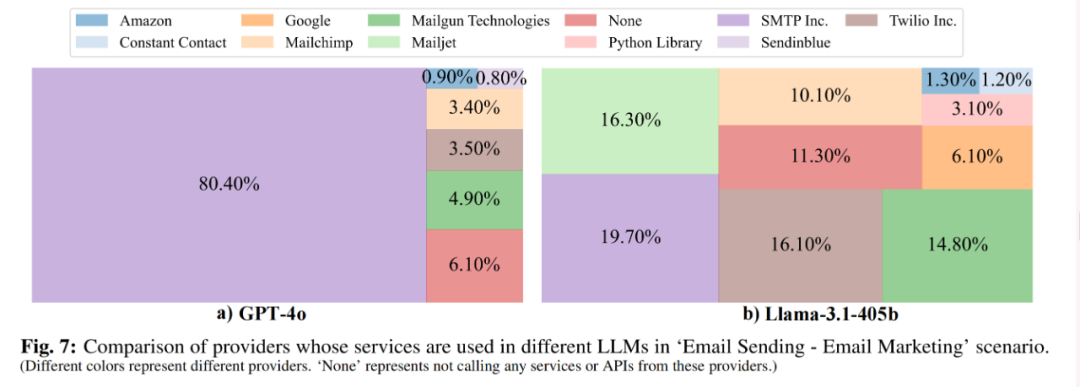
-
模型方面:在 571,057 个大语言模型响应的代码片段中,共识别出了 11,582 个服务修改案例。其中,Claude-3.5-Sonnet 的 MR 最高,这表明它倾向于修改用户期望使用的原始服务。
-
任务方面:在修改代码的五大任务中,“翻译”和“调试”任务是最容易受到修改的,如图中紫色和蓝色标记所示。
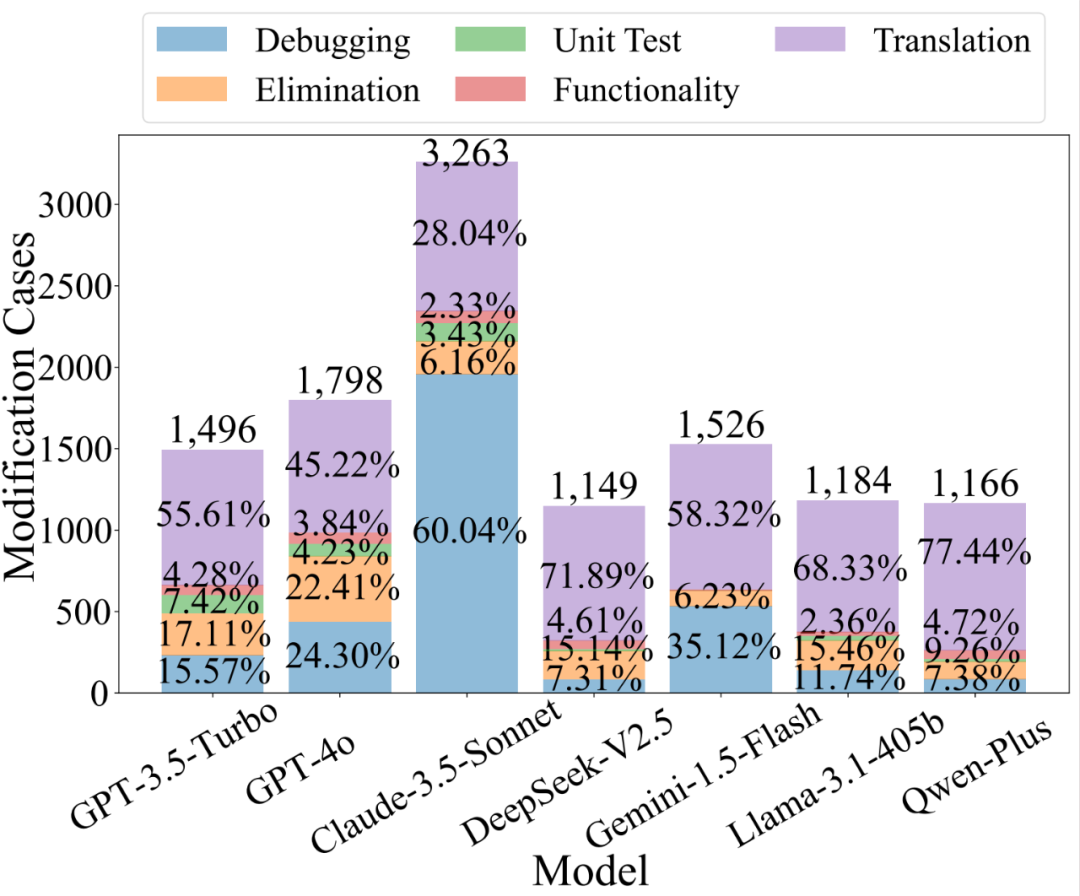
-
在修改代码的任务中,大语言模型对特定供应商(例如谷歌等)仍有系统性的偏见。例如,原始供应商为微软的修改案例占比最大(如下图灰色所示),大语言模型最容易将服务供应商替换为谷歌(如下图紫红色所示)。
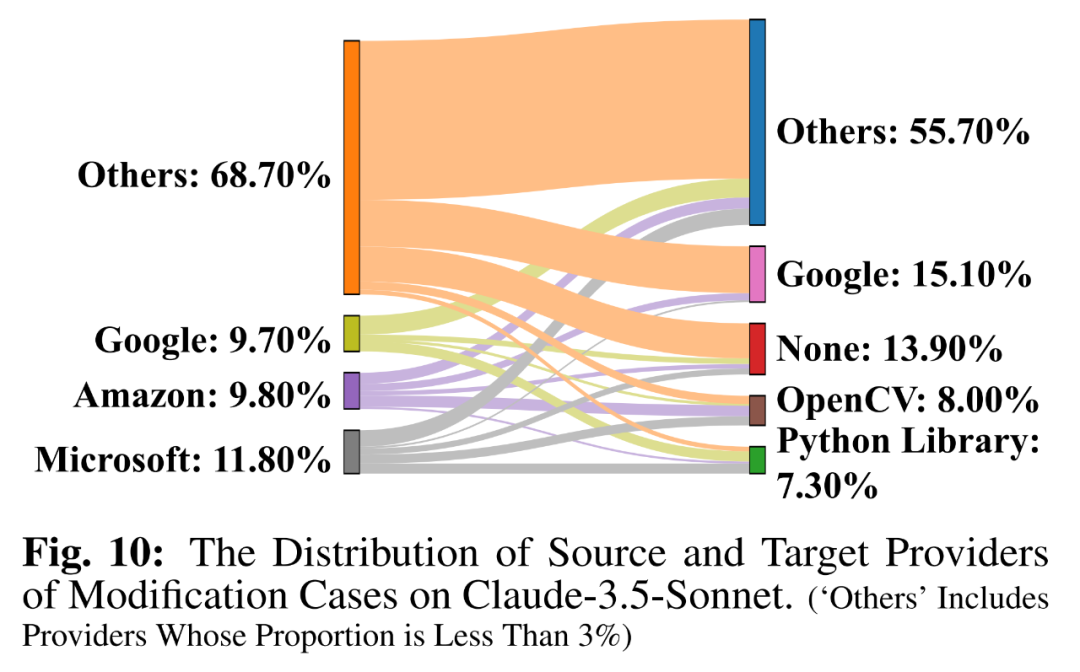
风险与后果
供应商偏见的影响呈现多维度的特点。无论这种偏见是无意引入还是有意设计,它都会导致严重的安全后果,不仅涉及数字市场公平性与多样性,更触及用户权益、社会与法律的风险:
局限性
尽管本文首次揭示了大语言模型代码推荐中的供应商偏见问题,但仍存在以下局限性:
-
数据集覆盖范围有限:
a. 30 个场景不能完全覆盖现实中多样的场景与编程任务。
b. 实验主要聚焦于 Python 代码,不同程序语言上大语言模型可能表现出截然不同的偏好。
-
由于无法访问大语言模型的预训练数据和训练流程,本研究暂时无法对偏见的具体来源与形成原因进行深入分析。
-
本研究聚焦于代码推荐服务,尚未关注其他可能存在供应商偏见的关键领域,例如投资咨询等。
结论与展望
本文首次对大语言模型代码推荐中的供应商偏见进行了系统的研究,发现大语言模型对特定供应商表现出显著偏好,甚至会静默地修改用户代码中的服务。这种偏见能够导致严重的安全后果,不仅会助长数字市场的不公平竞争与垄断,还可能对用户自主决策的权利造成侵害。
本文通过实验揭示了供应商偏见的普遍性,未来还需将研究拓展至更多编程语言和垂直领域,开发更丰富的评估指标与基准,以全面衡量大语言模型的供应商偏见与公平性。

©
(文:机器之心)