

一水 发自 凹非寺
量子位 | 公众号 QbitAI
AI文本转语音已经进化到这种程度了吗?(⊙ˍ⊙)
莎士比亚戏剧腔、体育赛事激情解说、沉浸式有声书等诸多玩法简直轻松拿捏,而且听起来确实人机傻傻分不清楚~
就在刚刚,专攻AI语音合成的独角兽ElevenLabs发布旗下最新版TTS模型——Eleven v3。
不仅支持70多种语言(含中文),还能进行多人对话聊天,过程中每个人的情绪、语气等表现都非常生动。
官方自信表示,这是“迄今为止最具表现力的文本转语音模型”。
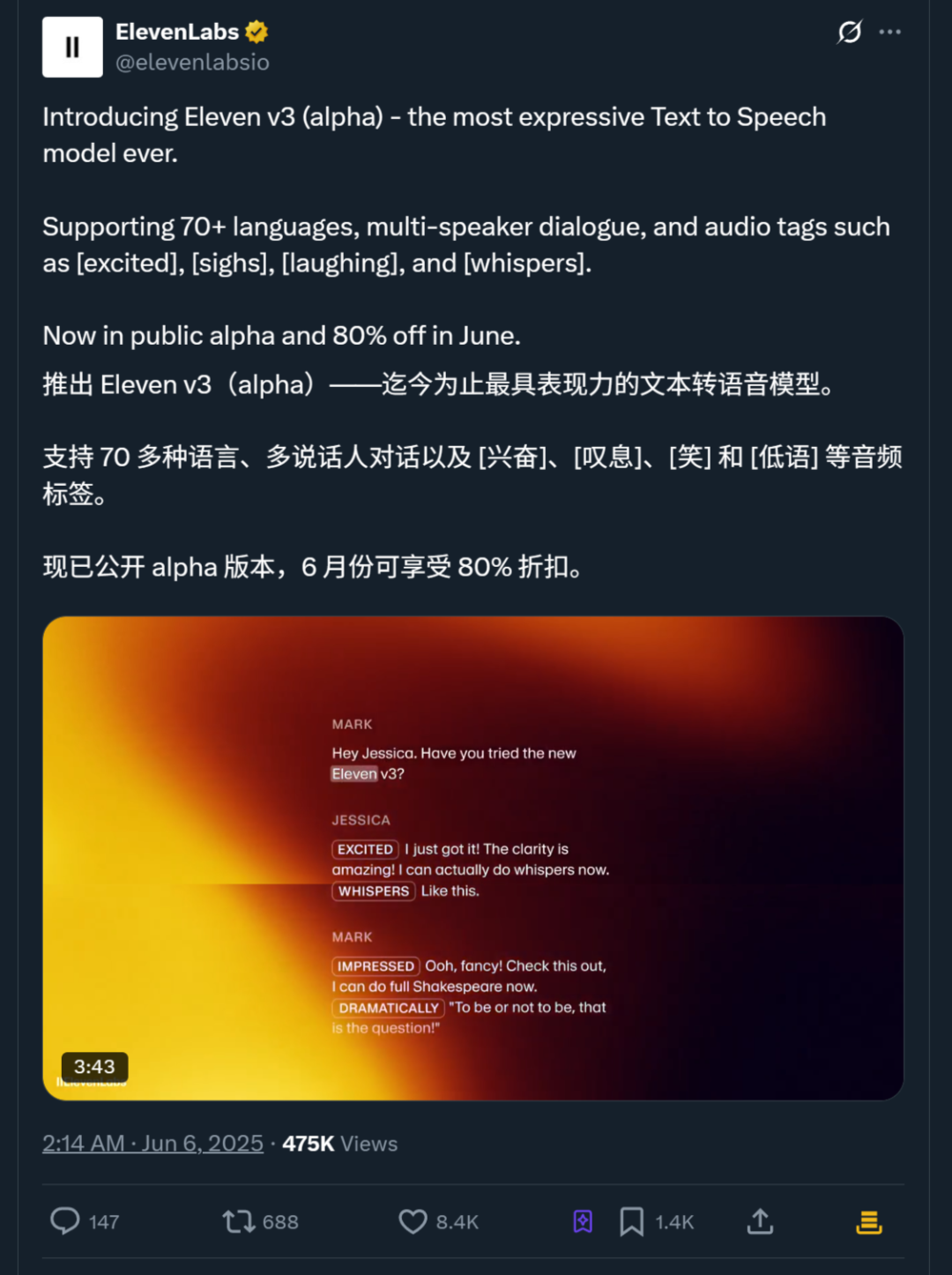
新模型发布不久即在AI圈引起热议,Reddit网友也齐聚一堂疯狂讨论。
RIP有声书配音。
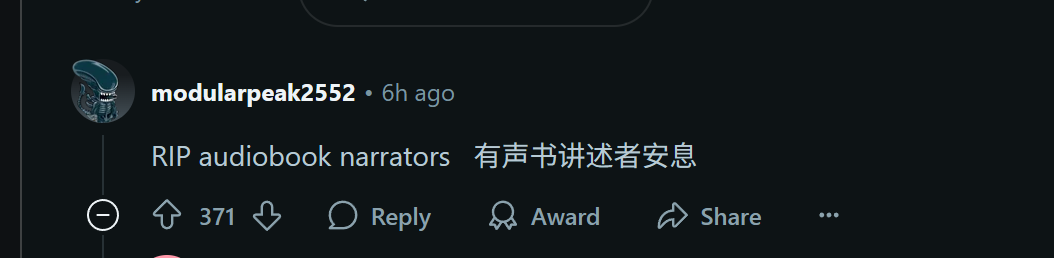
对于英语为第二语言的人来说,根本无法区分AI和真人,唯一不足的是他们太热情了!
目前Eleven v3仍处于内部测试阶段,API即将推出,实时在线版本正在开发中。
那么,新模型具体有哪些亮点?又是如何做到的呢?

引入音频标签控制情绪
接下来我们结合官方提供的「使用指南」一步步拆解Eleven v3的亮点及背后原理。
首先需要提醒,提示词过短更容易导致输出不一致,因此官方建议文本字符最好超过250个。
如何选择想要的声音?
一般拿到一段需要转语音的文本后,用户首先会考虑选择哪种声音。
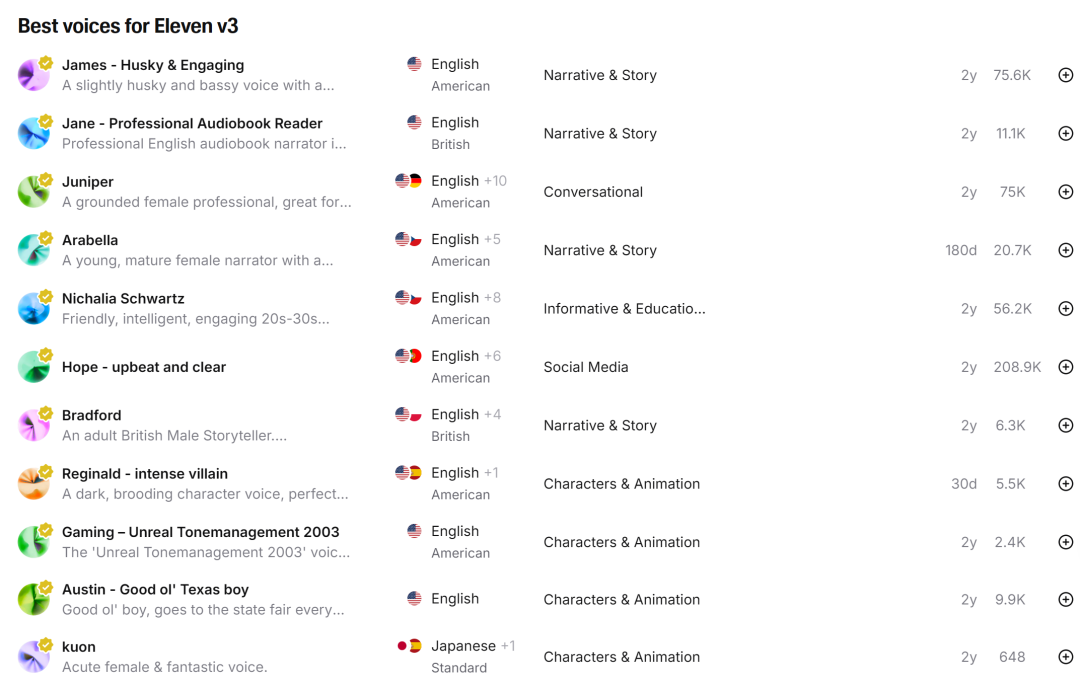
对此,Eleven v3当前提供了“22位优秀配音老师”,他们基本上都是美国人和英国人,其音色适合不同配音场景。
-
James:嗓音沙哑而迷人,适合讲故事; -
Priyanka Sogam:中性口音,适合深夜广播节目; -
Jessica:年轻俏皮,适合流行内容对话; -
……
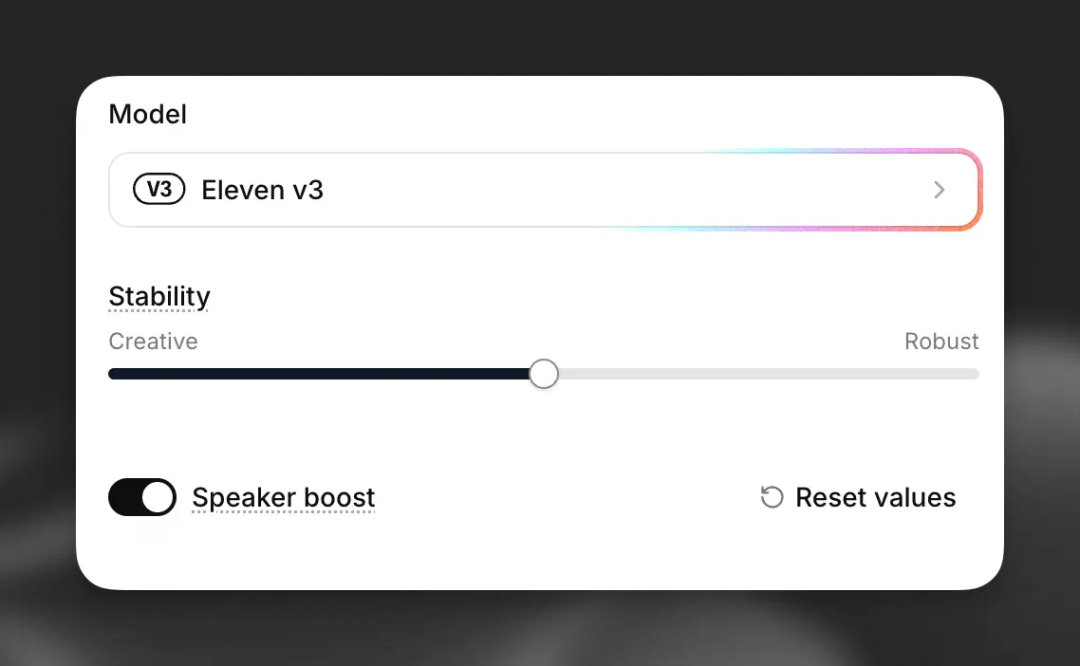
同时通过上传一段参考音频,用户还能利用“stability slider(稳定性滑块)”控制生成的声音与原始参考音频的接近程度。
这里通常有三种不同程度的选项:
-
Creative:情绪化、表现力更强,但容易产生幻觉; -
Natural:平衡且中性,最接近原始录音; -
Robust:高度稳定,但对方向性提示的反应较慢。
同一音色也支持切换成其他语言(70多种),不过从官网demo来看,目前Eleven v3更适合英语语种,转换成中文口音后听起来仍然很怪。
如何控制情绪表达?
选好声音后,接下来的重点是如何控制情绪表达。
答案是,Eleven v3引入了通过音频标签控制情绪的功能。
这里的标签一共分为三类:
-
情感表达标签:如[laughs](笑)、[whispers](耳语)、[sarcastic](讽刺)等,用于表达不同的情感和语气; -
音效标签:如[gunshot](枪声)、[applause](掌声)、[swallows](吞咽声)等,用于添加环境声音和效果; -
特殊标签:如[strong X accent](强调某口音)、[sings](唱歌)、[fart](放屁声)等,用于创意应用。
顺便一提,某些特殊标签在不同语音之间可能存在不一致的情况,官方建议使用前最好测试一下。
具体用法如下,直接在文本中的合适位置插入即可。



除了引入标签,官方表示学会正确使用标点符号也很重要。
标点符号对Eleven v3中的情绪传递有显著影响。
通常,省略号用于在语音中增加停顿和强调、大写字母用于增强语句中的强调效果、标准标点符号帮助提供更自然的语音节奏和流畅度。

如何实现多人对话?
最后,从单人→多人对话,用户只需从语音库中为每个说话者分配不同的语音即可。
一个完整版的多人对话提示如下(音色分配、音频标签、标点符号齐上阵):

总之,和之前的v2版本相比,v3新增了多人对话功能,还提供了更多音频标签和语言选择。

网友实测:和宣传一致
目前,一些获得内测资格的网友也第一时间分享了其体验结果。
总体来看好评居多。
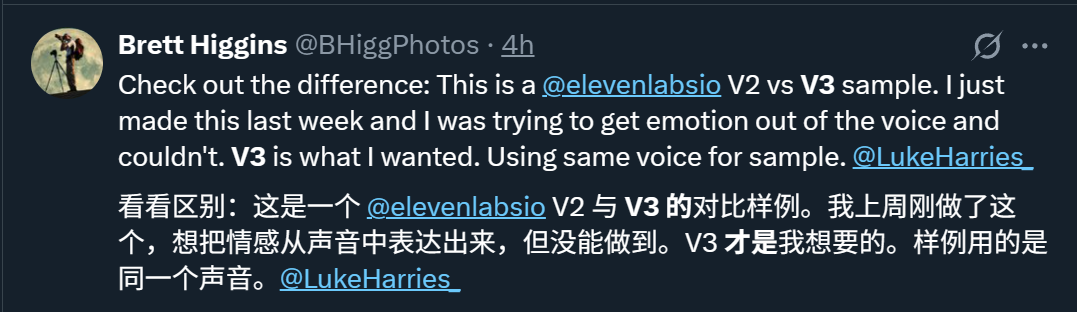
先直观感受一下v2和v3之间的差别:
网友表示,v3实现了v2未能成功的情感表达。
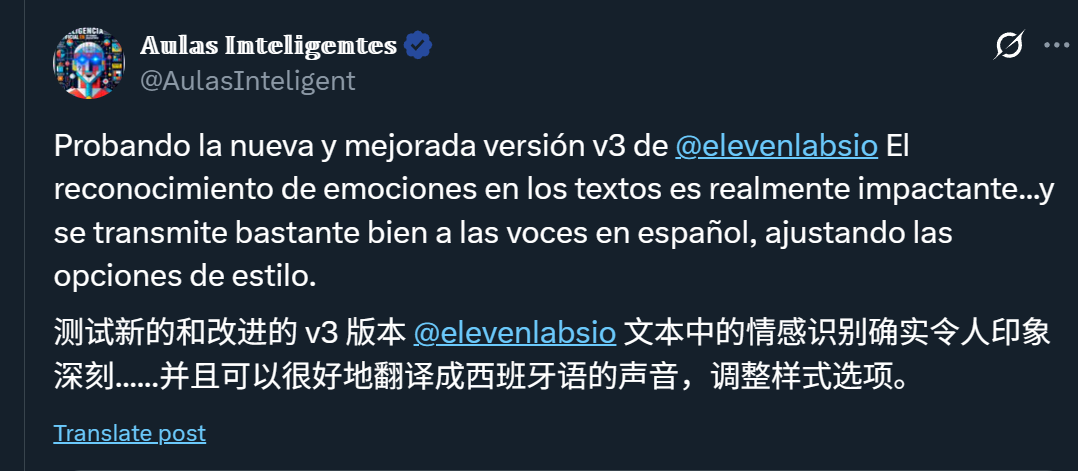
再来感受一下切换成西班牙语:
该网友同样表示,Eleven v3的情感识别功能令人印象深刻。
换成情感大杂烩,一家生成式AI公司的副总裁表示,“v3和宣传的一样好”。
不过这里他也提到了一点小瑕疵,比如[whistle](口哨)的声音过短。

Anyway,整体而言这款产品在情感控制上已经渐趋成熟了,只不过中文效果仍比不上英文。
这不就是咱们国内语音厂商的机会所在吗(doge)~
(文:量子位)