


新智元报道
新智元报道
【新智元导读】苹果最新研究揭示大推理模型(LRM)在高复杂度任务中普遍「推理崩溃」:思考路径虽长,却常在关键时刻放弃。即便给予明确算法提示,模型亦无法稳定执行,暴露推理机制的局限性。
AI「思考」只是假象?
刚刚,一项来自苹果的重磅研究揭示了「大推理模型(LRM)」背后的惊人真相——这些看似聪明的模型,在面对稍复杂点的题目时,准确率居然会全面崩溃!
随着问题变难,推理模型初始会延长思考,但随后思考深度反而下降,尽管仍有充足token预算——它们恰在最需要深入思考时选择了放弃!
这太违背直觉了,似乎Scaling Law在推理时完全失效了。
值得一提的是,论文作者中还有Samy Bengio,他也是图灵三巨头Yoshua Bengio的兄弟。

论文地址:https://ml-site.cdn-apple.com/papers/the-illusion-of-thinking.pdf
LRM模型因能「写出思考过程」而备受期待,被认为是AI推理能力跃升的关键。

DeepSeek-R1 <think>模式的开源开启了LLM进化到LRM的进程
但研究人员通过可控游戏环境的系统实验证明:现有LRMs不仅在高复杂度任务上力不从心,甚至还展现出一种「反常的推理崩溃曲线」——题目越难,它们反而越不「努力」。
研究还通过在相同计算token预算下对比思考模型与普通模型,发现:
-
简单题目,反而是传统大模型(LLMs)更强;
-
中等复杂度,LRMs凭借「思考路径」胜出;
-
一旦太复杂,两类模型准确率同时坍塌至0%
不同于大多数仅衡量最终性能的研究,这项最新研究分析了它们实际的推理轨迹——深入观察其冗长的「思考」过程。

与以往主要依赖数学问题来评估语言模型推理能力的研究不同,本研究引入了可控的解谜环境。
这种环境可以精确调节问题的复杂度,同时保持逻辑过程的一致性,从而更严谨地分析模型的推理模式和局限性。
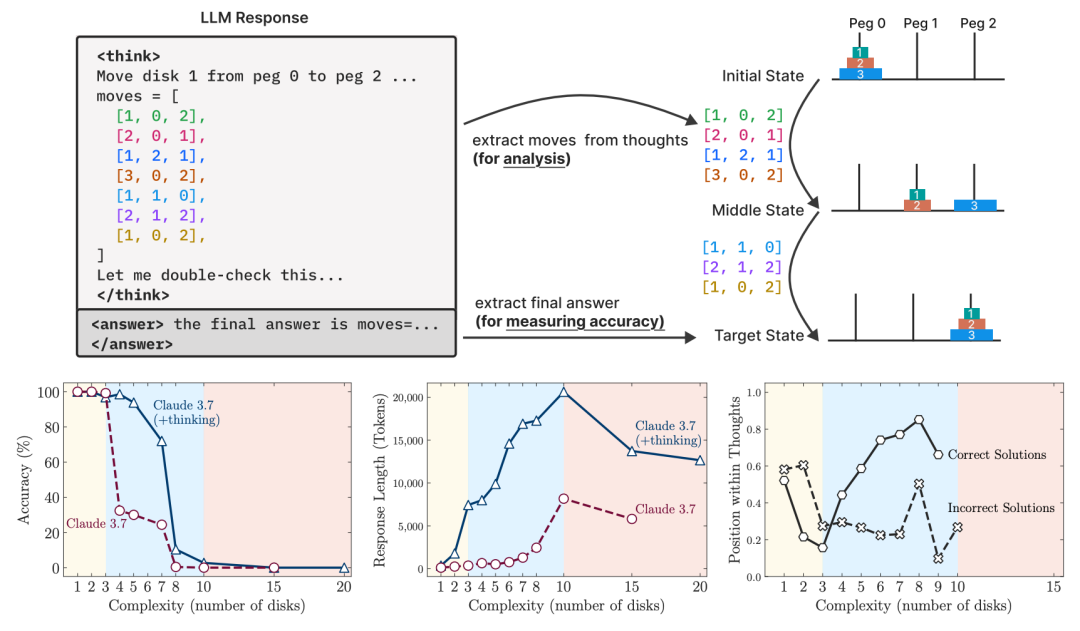
顶部的「LLM Response」部分表示研究设置了可以验证模型的最终答案和中间推理过程,从而能够更细致地分析模型的思维行为。
左下准确率和中间的回答长度表示:在任务复杂度较低时,不进行推理的模型表现得更准确,也更节省Token。
随着复杂度提升,具备推理能力的模型开始表现更好,但也消耗更多Token——直到复杂度超过某个临界点后,两类模型的表现都会迅速下降,同时推理过程变得更简短。
右下表示在成功解题的情况下,Claude 3.7 Thinking 通常会在任务复杂度低时较早找到正确答案,而在复杂度高时则更晚得出答案。
而在失败案例中,它往往会在一开始就陷入错误答案,之后继续浪费剩余的 Token 预算。这两种情况都暴露了推理过程中存在的效率问题。
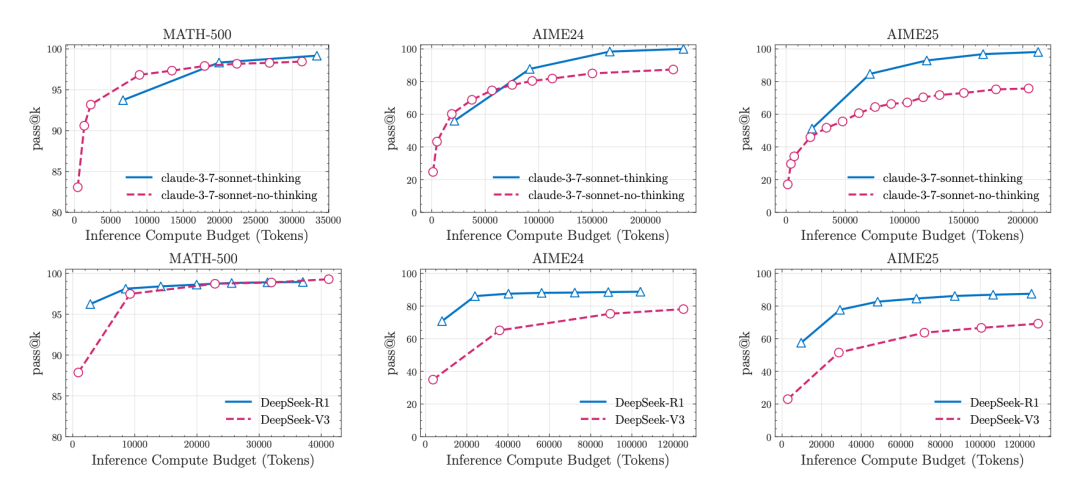
对思考型与非思考型模型在数学基准测试中的对比分析显示出模型的性能表现并不一致。
在MATH-500数据集上,两类模型的表现相近;但在AIME24和AIME25基准上,思考模型的表现明显更优。
此外,从AIME24到AIME25的性能下降也揭示出这些基准数据易受到数据污染问题的影响。
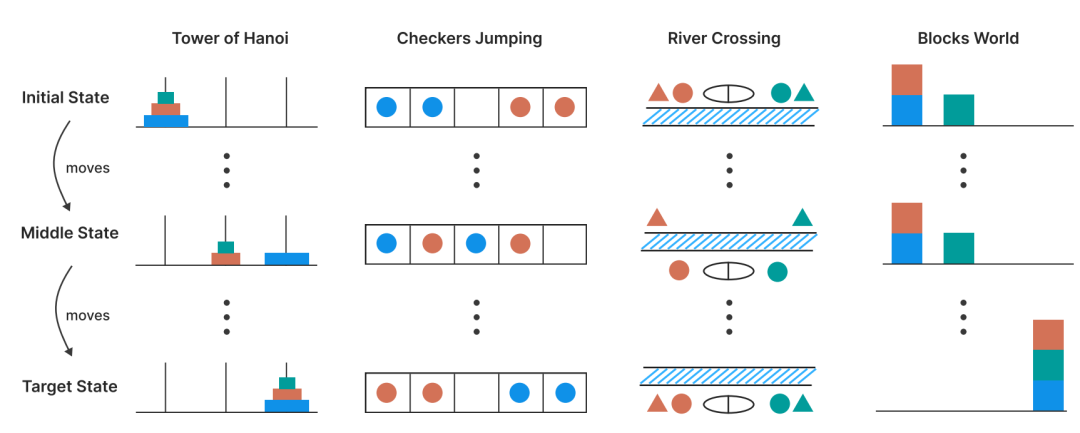
研究设置了四种谜题环境。
每列展示一个谜题从初始状态(顶部)、中间状态(中部)到目标状态(底部)的变化过程。
四个谜题分别是:汉诺塔(将圆盘在柱子间移动)、跳跳棋(交换不同颜色棋子的位置信息)、过河(将多个对象安全运送过河)、积木世界(重新排列积木的堆叠结构)。
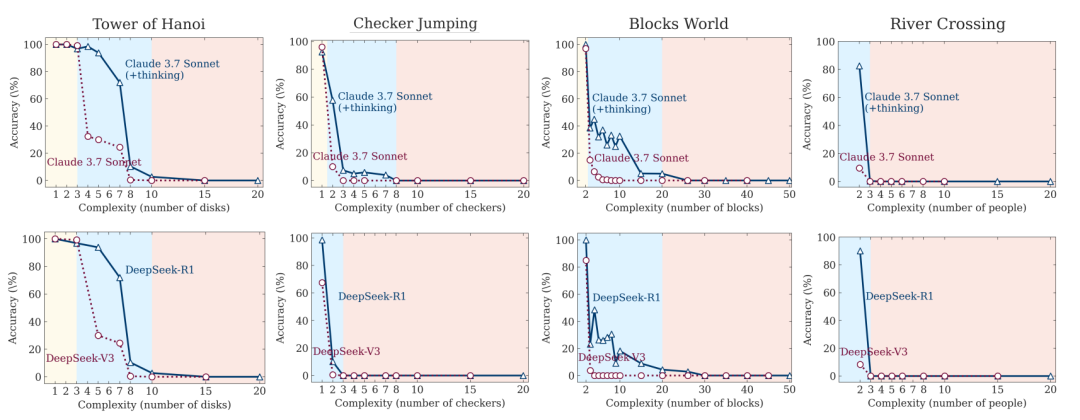
在所有谜题环境中,不同复杂度问题下,思考型模型(Claude 3.7 Sonnet with thinking、DeepSeek-R1)与其非思考型对应模型(Claude 3.7 Sonnet、DeepSeek-V3)的准确率对比。
最明显的依然是,当问题复杂度突破一定阈值后,所有模型的准确率同时坍塌至0%!
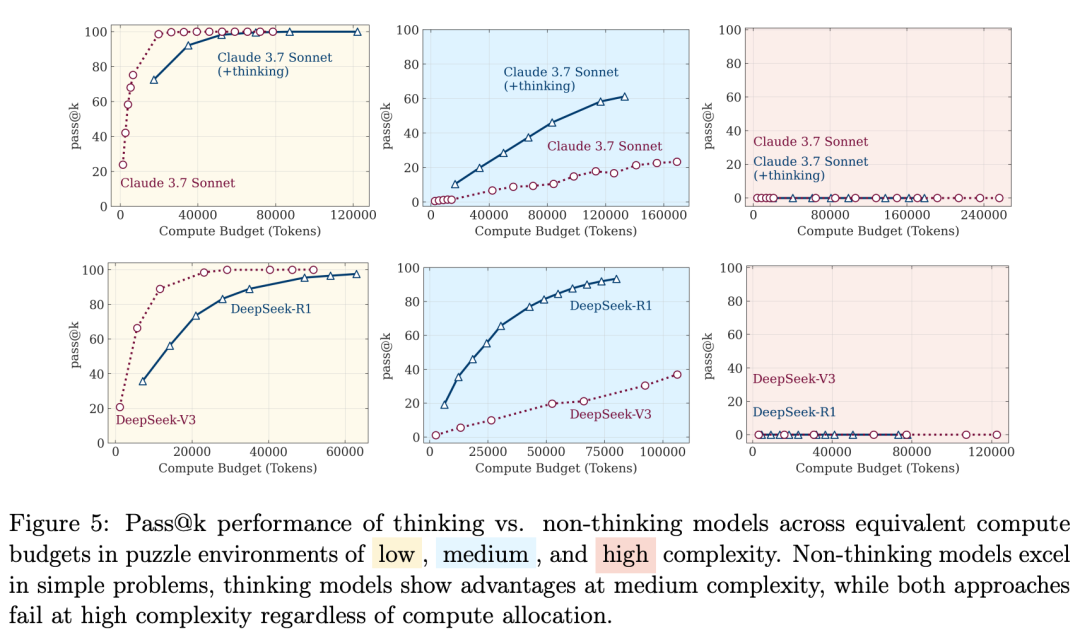
上图为在tokens预算相同的情况下,思考型模型与非思考型模型在低、中、高三种复杂度谜题环境中的 pass@k表现对比。
结果显示:
-
非思考型模型在简单问题上表现更佳;
-
思考型模型在中等复杂度问题中展现出优势;
-
而在高复杂度问题中,无论计算资源分配如何,两个模型的表现都未能取得明显突破。

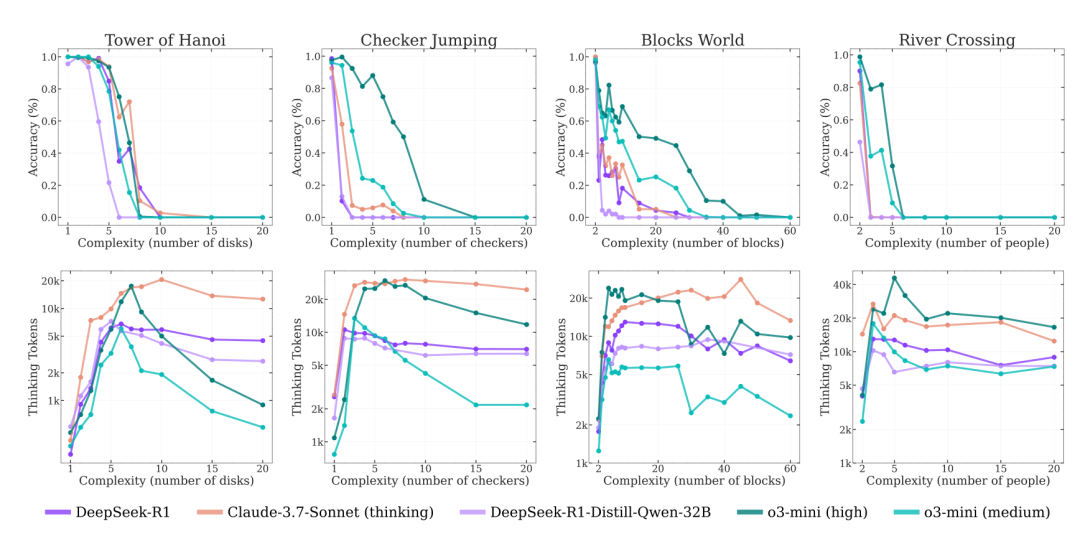
上图表示推理模型在不同谜题环境中,准确率与思考token使用量随问题复杂度变化的趋势图。
随着复杂度上升,模型在一开始会投入更多思考token,准确率则逐渐下降;
但当复杂度达到某个临界点时,模型的推理能力开始崩溃——表现急剧下降,同时思考token的使用量也随之减少。
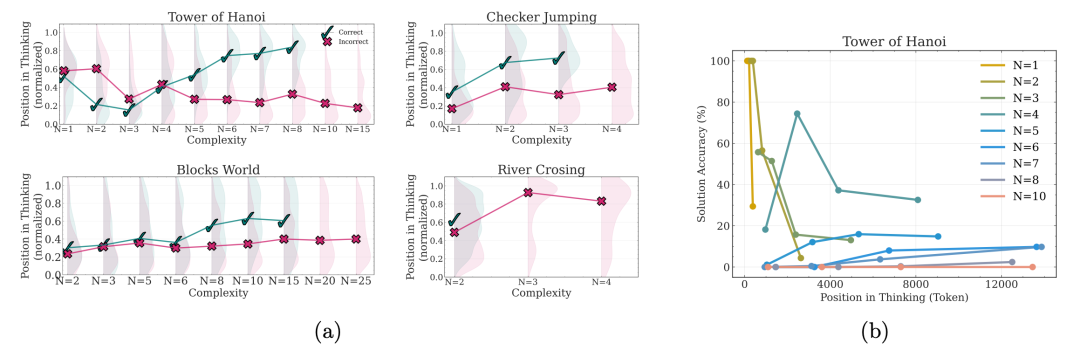
左图与中图展示了在不同复杂度下,四种谜题中推理过程中间解的出现位置及其正确性。✓ 表示中间解正确,✗ 表示错误,阴影表示分布密度。
右图则显示了在不同复杂度下,汉诺塔谜题中解决方案的准确率随思考过程位置的变化情况。
结果显示:
-
对于简单问题(N=1-3),准确率在思考初期较高,但随着推理继续反而下降,出现「过度思考」的现象;
-
对于中等难度问题(N=4-7),推理的持续略微提升了准确率;
-
对于复杂问题(N≥8),准确率始终接近于零,表明模型在这类问题上推理完全失败。
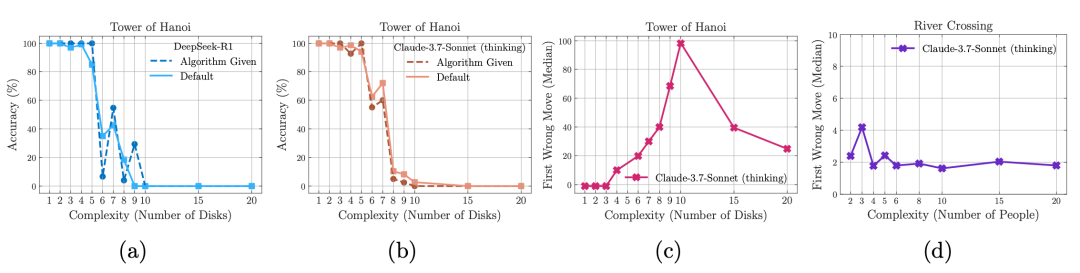
如上图a和b所示,在汉诺塔游戏环境中,即便在提示中直接提供了解法算法,让模型只需按步骤执行,模型的表现仍未改善,推理崩溃的现象依然出现在大致相同的位置。
这一点非常值得注意,因为设计并找到一个解法通常比仅仅执行一个已知算法需要更多的计算(比如搜索与验证)。这一现象进一步突显了推理模型在「验证」以及按逻辑步骤解决问题方面的能力局限。
如图c和d所示,观察到Claude 3.7 Sonnet思考模型在不同环境中表现出明显不同的行为。
在汉诺塔环境中,当N=10时,模型通常直到大约第100步才会出现第一处错误;
而在过河环境中,同一个模型却只能正确地完成前4步,之后便无法继续生成有效解。
这种差异非常显著。
值得注意的是,当 N=5(即需要31步解)时,模型几乎可以完美解决汉诺塔问题;但在 N=3(仅需11步解)的过河谜题中,模型却完全失败。
这一现象很可能说明:在网络数据中,N>2 的过河问题案例非常稀少,因此大语言模型(LRMs)在训练中几乎没有见过或记住这类实例。
这项研究系统性地评估了大推理模型(LRMs),低复杂度下,标准LLM反而更稳;中等复杂度时,LRM暂时领先;可一旦问题变得复杂到一定程度——两者双双崩盘。
分析推理轨迹后,研究者发现模型在简单问题上「过度思考」,在复杂问题上则彻底罢工。
甚至连直接提供解题算法都救不了它们——比如汉诺塔问题,算法提示给到位了,模型却依然原地打转。
模型在汉诺塔中可连续操作100步不出错,到了过河问题里,却五步都撑不过去!
这背后的原因成谜,但无疑为后续探索AI推理极限打开了一个新的突破口。
眼下的LRM,距离「通用推理」这座大山,显然还有不少路要走。
(文:新智元)