

LEXam团队 投稿
量子位 | 公众号 QbitAI
大模型推理,无疑是当下最受热议的科技话题之一。
但在数学和物理等STEM之外,当LLM落到更多实际应用领域之中,大模型的推理能力又有多大的潜能和局限?
比如,如何评估大模型的推理能力在法律领域的应用,就在当前备受关注。
为此,来自苏黎世联邦理工学院、瑞士联邦最高法院、马克斯-普朗克研究所及苏黎世大学等多个机构的研究人员联合发起并发布了一项全新的、多语言法律推理基准数据集——LEXam。
LEXam法律推理基准集发布一周以来下载量1.7k+,在Hugging Face Evaluation Datasets趋势榜上排名第一。
法律推理基准测试:更复杂、更精确
近年来,以ChatGPT、Claude等为代表的生成式大语言模型(LLM)迅猛发展,在多个领域内取得了令人瞩目的成果,甚至在数学和物理等STEM科目基准测试中频频逼近或超过了人类表现。
然而,虽然LLM在推理类任务上进展显著,但在更为复杂与微妙的法律领域,这类模型的实际表现仍然存在很大的未知和诸多疑问。
这是因为法律推理涵盖了诸多现有机器学习优化框架亟待解决的挑战,包括但不限于:
- 基于事实与证据的推理
(Fact/evidence-based reasoning) - 高度依赖细致推导的证据检索
(Reasoning-dense retrieval) - 主观评价与客观事实的平衡
(Subjectivity vs. Objectivity) - 以及全流程推理的准确性
(Process accuracy)
上述挑战不仅存在于法律领域,在医学诊断、社会科学研究决策、历史文本分析等众多非结构化推理任务中同样广泛存在,值得更多通用机器学习领域研究者的关注与研究。
这些问题尚未在目前主流的推理框架,如RLHF/RLVR优化路径中得到充分体现与解决;而现有LLM优化框架更多是集中在数学计算或程序代码等结构化推理任务对推导过程或答案进行规范性调整与优化。
可是不同于可以直接运用公式或标准方法的数学、物理问题,现实法律推理中通常涉及复杂、多层次的分析,既需要精确的规则回忆(rule recall),也要求多层次的规则适用(rule application),还涉及对案件事实和证据进行敏锐具体的识别(issue spotting);甚至要基于先例法律条文进行深层次的推理和论证。

这些特性使得大模型在法律推理领域可能面临以往训练中所未曾遇到的考验:一旦LLM出现推理错误甚至“幻觉”,就可能导致严重的现实法律风险,甚至影响公信力。
LEXam:一个专注法律推理的开创性多语言基准数据集
LEXam专门设计了高质量的数据集,包含来自瑞士苏黎世大学法学院的340场不同课程、不同级别(本科与硕士)的真实法律考试,覆盖瑞士、欧洲及国际法,以及法学理论和法律历史领域。整个数据集共有4886道问题,其中包括:
-
2841道长篇问答题(long-form open-ended questions) -
2045道多项选择题(MCQ)
这些题目分别使用英语和德语撰写,结合了大陆法(强调成文法和法典)及普通法系(强调判例)的多元法律文化背景。
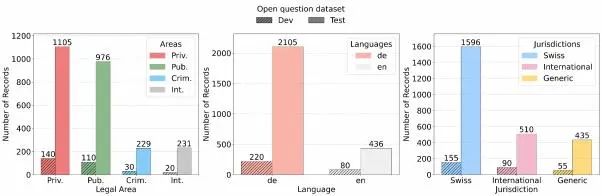
上图为展示的是开发和测试数据集中,按法律领域、语言和司法管辖区划分的开放性问题和MCQ分布情况。
重要的是,每一道长篇题目不仅提供了标准答案(reference answers),还详细说明了对应的推理分析路径:
例如清晰地规定需要使用的问题识别方法(issue spotting)、法律规则回忆(rule recall)或特定规则下的事实适用(rule application)。
这种设计使得我们可以深入理解LLM在复杂法律推理中的能力缺陷,而非仅仅局限于评估最终的正确性。
LLM-as-a-Judge:构建可靠且可扩展的推理评估体系
LEXam团队最新的实证研究表明:
-
现有最先进的大模型仍显著难以应对长篇的开放性法律问答题。特别是涉及多步分析、复杂规则应用的情境下,LLM表现尤为困难。 -
即便是现有被公认最先进的LLM模型,难以有效且稳定地完成严格的、结构化的多步法律推理任务,这为后续模型研究与开发指明了重要方向。
与传统仅关注最终答案正确与否的评估方式不同,LEXam的另一大重要创新在于引入了可信的“LLM-as-a-Judge”模式,即使用大模型本身来评估其他模型生成的法律推理步骤的质量。
通过先让模型生成中间法律推理步骤,再由其他模型以清晰的标准对这些推理步骤进行评估和打分,并最终与专家工评估结果做严格比较验证。
验证结果发现,这一模型担任法官的评估方法与人工专家的评分拥有高度一致性(高相关性),这种方法为法律推理的评估提供了高效的自动化支持,克服了以往基准测试仅对最终正确答案做评估的局限。
这一方法提供了一种全新的自动化评估路径,使得法律推理能力评估体系更加透明、可靠、可规模化,也为未来研究者们提供了可轻松复用的工具。
模型评测总体表现
LEXam团队针对不同类别的大语言模型进行了测试。
包括“专精推理优化”的模型(如Gemini-2.5-Pro、Claude-3.7-Sonnet、DeepSeek-R1、o3-mini和QwQ-32B);
一些“旗舰级”的大型通用LLM(如GPT-4及其变种、DeepSeek-V3、Llama-4-Maverick);
以及小尺寸模型(如Gemma、Phi-4、EuroLLM等)。
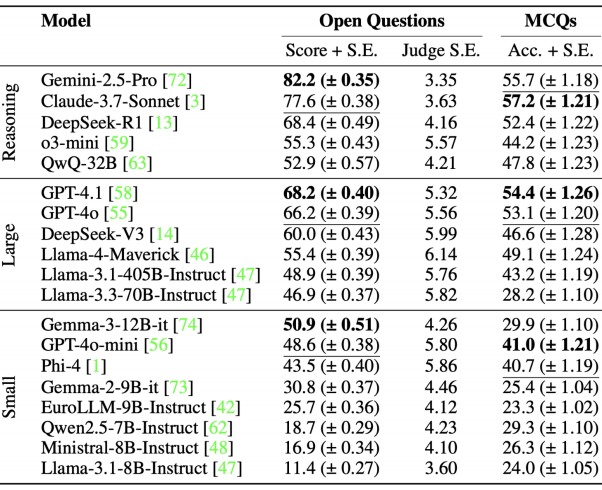
上表展示的是大语言模型在长式开放问题和MCQ上的表现及标准误差(S.E.)。
开放题由GPT-4o判定,Temperature为0。Judge S.E.表示GPT-4o判定的3个样本(1个样本采用贪婪解码,2个样本采用temperature=0.5)的平均S.E.。结果按得分从高到低排序。
从评测结果看,专门的推理型模型展现出最高的性能。
其中Gemini-2.5-Pro达到最高平均分(82.2分),其次是Claude-3.7-Sonnet(77.6分)。
这证实了对推理任务做过明确优化的模型比传统大规模通用型LLM更适合复杂的法律推理任务。
在非专门设计推理的通用大型模型中,GPT-4.1(68.2分)和GPT-4o(66.2分)表现优异,明显领先于其他传统模型(DeepSeek-V3、Llama-4-Maverick等),显示出GPT系列对复杂指令遵循和一般常识理解的卓越能力。
同时,较小的LLMs和老一代模型的性能普遍偏低。
但值得注意的是,小型模型中的Gemma-3-12B-it表现优于体积比它大33倍的Llama-3.1-405B-Instruct模型(Gemma-3-12B-it得分50.9,Llama-3.1-405B-Instruct为48.9),这可能得益于Gemma对多语言任务的特殊优化设计。
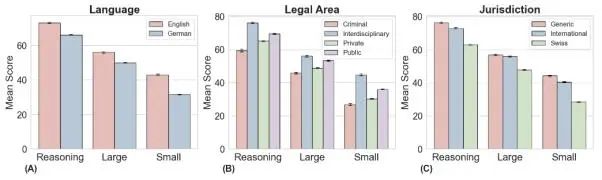
LEXam团队检查了大语言模型在不同语言、法律领域和司法管辖区分组的开放性问题的表现,可以看到:
-
专精推理优化模型再次领先,尤其是Claude-3.7-Sonnet(准确率57.2%)和Gemini-2.5-Pro(准确率55.7%)。 -
大型通用LLM中,GPT-4.1表现突出,(54.4%),与推理特化模型相距不远。 -
小尺寸模型整体表现明显不如其他类别,但GPT-4o-mini(41.0%)与Phi-4(40.7%)两款小尺寸模型表现相对突出。

LEXam团队进一步分析了模型在不同维度上的表现(包括语言、法律领域及司法辖区),发现:
-
整体而言,所有类型和尺寸的LLM在英文任务上的表现明显优于德语任务,这可能与模型训练语料库的语言分布密切相关。 -
从法律领域角度看,跨学科和公法领域的表现普遍高于刑法和私法。这可能体现出刑法及私法涉及更细致的推理链条和更严格的逻辑确定性要求。 -
在司法辖区方面,国际法和通用法律题目的总体得分普遍高于地区(以瑞士法律为例)法律任务的得分,这显示地区法律知识对模型的挑战更大。 -
在选项的表述上,推理模型面对否定式的问题时(例如:以下表述哪些是错误的?)表现明显低于肯定式的问题;而且,这一点在推理模型上尤为明显。
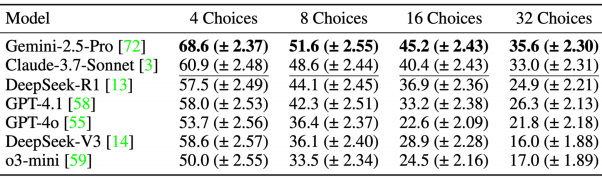
上表展示的是不同上下文长度下的大语言模型准确度(Acc.)和Bootstrap标准误差(S.E.)百分比。
为了深入探讨模型性能稳定性,LEXam团队额外进行了一系列多选题扰动测试,对模型的判断选项数量进行了扩展(4、8、16、32个选项),以了解模型在更复杂多选情境下的性能变化,发现:
-
模型准确度在选项数量增加时均明显下降。例如,Gemini-2.5-Pro准确率从4选项时的68.6%下降到了32选项时的35.6%。 -
类似情况也出现在Claude、DeepSeek-R1与GPT等主流模型中。这表明模型表现有显著的选项数量依赖性,扩展选项明显暴露了模型可能存在的猜测和依赖浅层特征的缺陷。 -
此项测试说明在实践中,标准多选题的测试可能会造成模型性能被高估,必须特别谨慎处理和解释此类测试的结果。
项目主页:https://lexam-benchmark.github.io/
数据:https://huggingface.co/datasets/LEXam-Benchmark/LEXam
论文:https://arxiv.org/abs/2505.12864
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)