跳至内容
今天,在arxiv平台计算机科学板块的一篇新论文引起了外界关注。
这篇论文对当下语言模型能记忆能力进行了探讨,主要作者来自Meta的基础人工智能研究团队(FAIR)、谷歌DeepMind、康奈尔大学以及英伟达团队。
作者在论文中表示,先前业内对语言模型记忆的研究一直难以将记忆与泛化区分开来,而这项最新研究结果有助于从业者进一步理解语言模型如何记忆,以及在不同模型规模和数据集规模下,它们可能(或不可能)记住哪些内容。
在过去几年里,现代语言模型一直在越来越大的数据上进行训练,例如一个有80亿参数的先进模型,需要在15万亿个tokens(磁盘占用约7TB)上进行训练。
长期以来的一系列研究,探讨了这类预训练语言模型是否以有意义的方式记忆其训练数据,大多数研究通过以下两种视角解决这一问题:
1、数据提取:旨在从模型权重中恢复完整的训练数据点;
2、成员推理:分类某个训练样本是否存在于给定模型的训练数据中;
关于语言模型数据提取的研究认为,如果能够诱导模型生成某个数据点,则表明该数据点被模型记忆,不过新的研究认为,这种生成能力未必能作为“记忆”的证明,因为语言模型几乎可以被强制输出任何字符串,因此模型输出某内容并不一定意味着其记忆了该内容。
最近的一些研究还表明,此前被认为是“被记忆”的部分实例甚至不存在于训练集中,其可提取性被认为是泛化能力的结果。
如何准确定义大模型的“记忆”成为亟待解决的行业问题。为了填补这一空白,研究人员提出了一种新的“记忆”界定方法,用于量化模型保留特定数据点信息的程度,并且将记忆分解为两个不同的部分:
1、非预期记忆:捕捉模型存储的关于特定数据集的信息;
2、泛化能力:表示模型习得的关于底层数据生成过程的知识。
为了理解提出的新量化指标,研究人员通过在不同规模的数据集上训练不同容量的语言模型,来测量非预期记忆和泛化能力,再通过消除泛化能力的影响,计算给定模型的总记忆量。
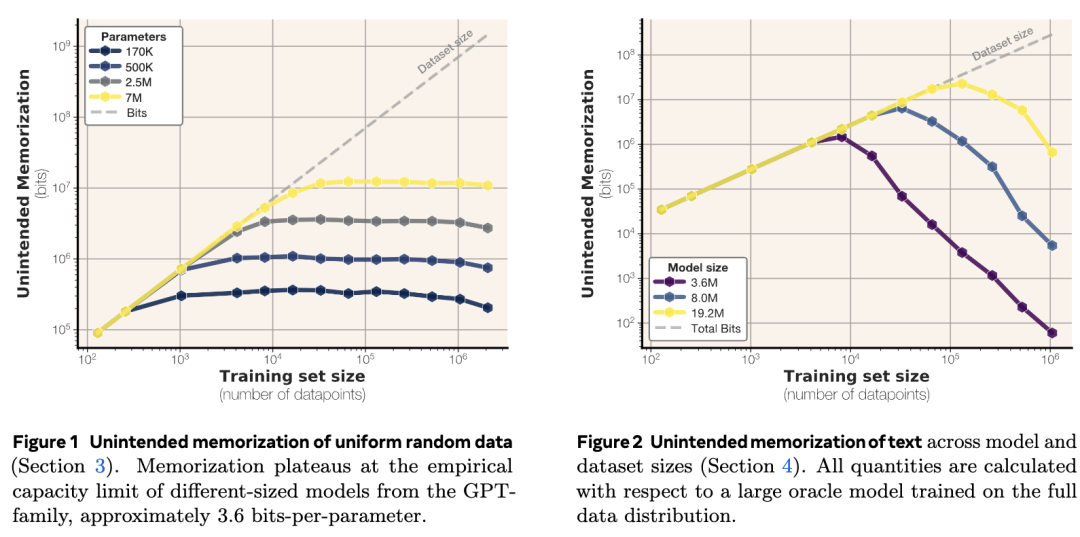
结果发现,GPT风格的Transformer模型每个参数可存储3.5到4比特的信息,具体取决于模型架构和精度,bfloat16精度的模型每个参数存储3.51位,float32精度的模型每个参数存储3.83位,精度加倍并不会相应地使记忆容量加倍。
例如模型会持续记忆直至容量饱和,此时 “顿悟”(grokking)开始,随着模型转向泛化,非预期记忆量会逐渐减少。
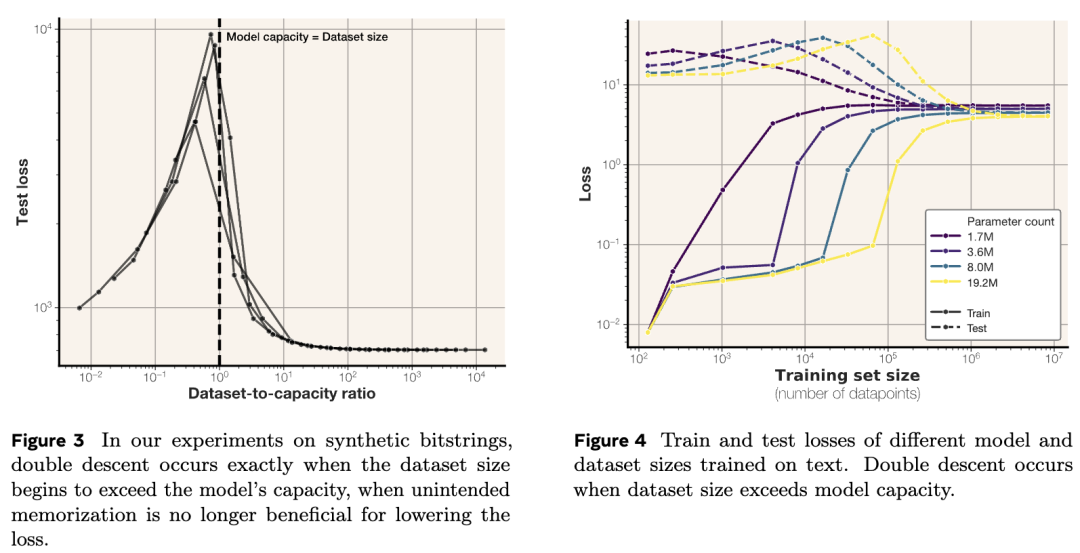
此外,样本层面的非预期记忆随模型参数增加而增加,随训练集规模增大而减少,当数据集规模超过模型容量时,“双重下降“现象会出现,双重下降现象恰好始于数据容量超过模型容量之时。
当研究人员基于先知参考模型测量非预期记忆时,随着较小规模的模型能够比先知模型从较小训练集中学习到更多信息,记忆量会稳步增加;而当模型开始泛化且平均表现差于先知模型时,记忆量则会下降。
论文作者Jack morris表示,在海量数据集上训练的模型无法记住它们的训练数据,根本没有足够的记忆容量。
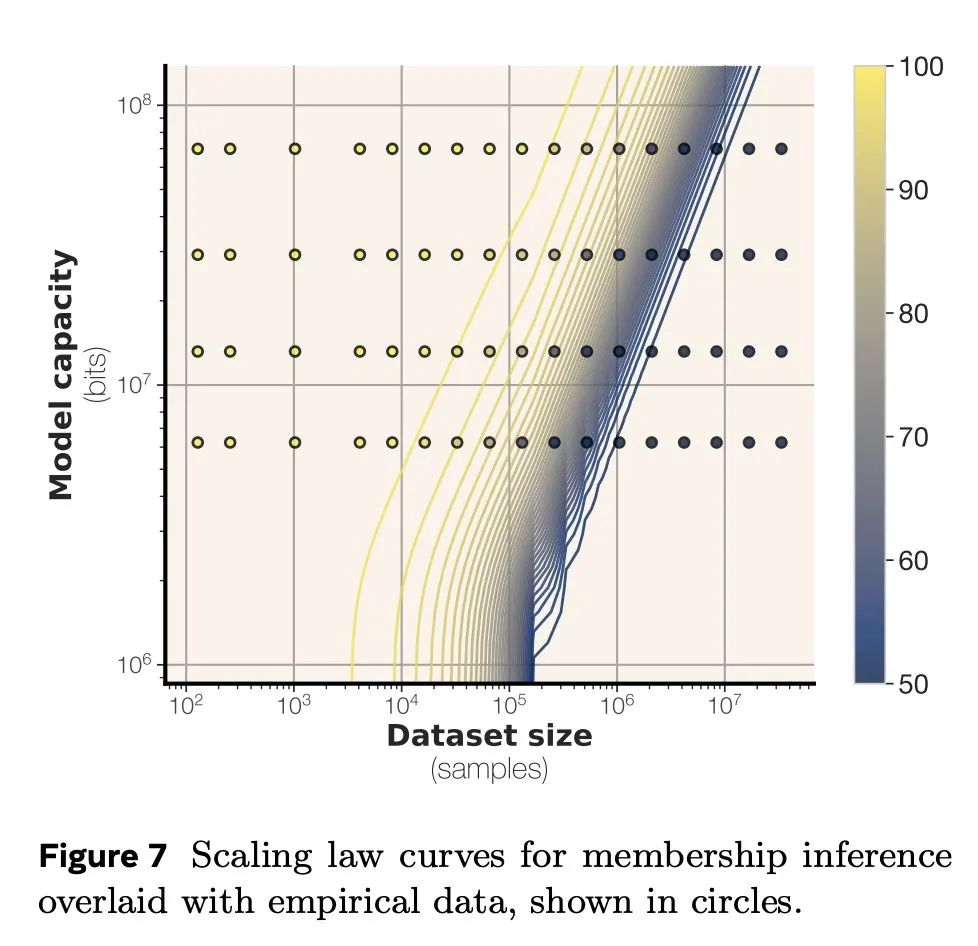
研究人员在总结中提到,这项研究首次将压缩作为衡量模型记忆能力的工具,并首次测量了模型容量的明确上限,通过训练数百个Transformer语言模型,参数范围从500K到1.5B,生成了一系列将模型容量和数据大小与成员推理联系起来的缩放定律。
这篇论文给很多AI开发者打开了新视角和思考路径,收获了不少称赞。
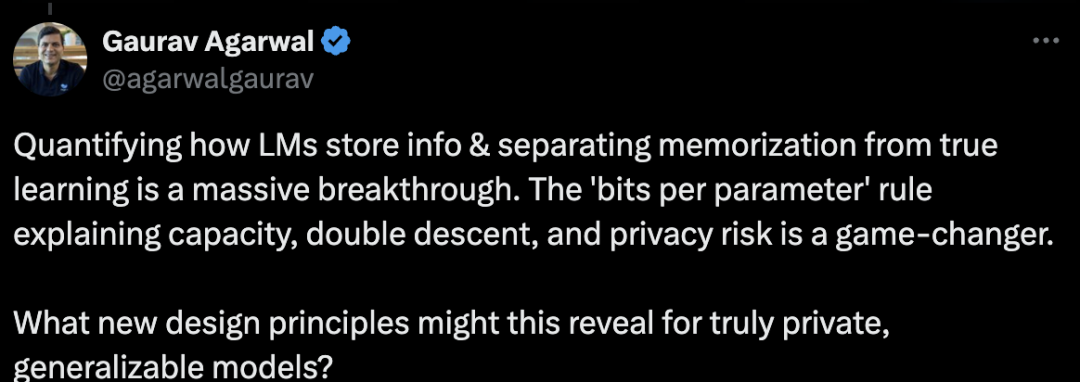
AI创业者Gaurav Agarwal认为,量化语言模型存储信息的方式,并将记忆与真正的学习区分开来是一项巨大的突破,解释容量、双重下降和隐私风险的“每参数位数”规则将带来翻天覆地的变化。
AI工程师Rohan Paul发帖表示,我们能否将模型对训练片段的死记硬背与真正的模式学习分开,并用比特来衡量两者?论文给出了肯定的答案。
从业者现在可以通过简单的规模比率来预测隐私风险,而无需进行攻击测试,简而言之就是,AI模型的 “大脑” 每个神经元最多容纳约4比特信息,当每个权重达到3.6比特的存储量时,模型就会停止囤积数据,因此,了解 “比特-令牌”之间的比率,开发者可以预测模型相关风险。
有开发者认为,论文测出的每个参数3.6位可能只是一个经验法则所得,应该不是所有GPT模型的通用常数,但一个不错的后续研究方向是确定一个上限,超过这个上限后,添加更多数据不仅不会有助于模式匹配,反而会开始增加幻觉。
还有开发者展望:如果模型每个参数记忆是3.6位,那么强制模型记忆1.58位似乎需要更高的泛化能力?或许能开辟一种让“顿悟”时刻更早发生的技巧。
有开发者称赞这简直是极客的宝藏,用香农的经典理论来衡量大语言模型的记忆真是绝了,想想这些模型会像数码巨龙一样形成记忆有点疯狂。
对于大模型记忆的研究正在变得热门。此前,由华盛顿大学、哥本哈根大学和斯坦福大学的研究人员开发的一种方法能够识别由OpenAI等AI模型“记忆”的训练数据,当时,OpenAI正卷入由作者、程序员和其他数据权利持有者提起的诉讼中。
随着大模型向着AGI水平迈进,理解模型的记忆能力对于开发更安全、更可靠的AI系统至关重要。
-END-
(文:头部科技)