

Pengfei Liu 投稿
量子位 | 公众号 QbitAI
AI能够独自完成医疗场景下的诊断任务吗?
在真实的临床环境中,医生需要综合分析大量的患者信息——包括主诉症状、既往病史、体格检查以及各类辅助检查结果,才能逐步构建出对病情的全面认知。
这一过程不仅要求强大的信息整合能力,更涉及复杂的推理判断。随着大语言模型在复杂推理能力上的不断突破,AI在应对各种科学挑战的前景也愈发广阔。那么,在高度依赖专业知识与临床经验的医疗领域,AI是否也能胜任“诊断”这一关键任务?
为系统评估AI在临床诊断任务中的实际表现,来自上海交通大学的SPIRAL Lab与GAIR Lab共同构建了DiagnosisArena——一个用于严格评估AI在专业医学诊断中能力水平的基准测试。
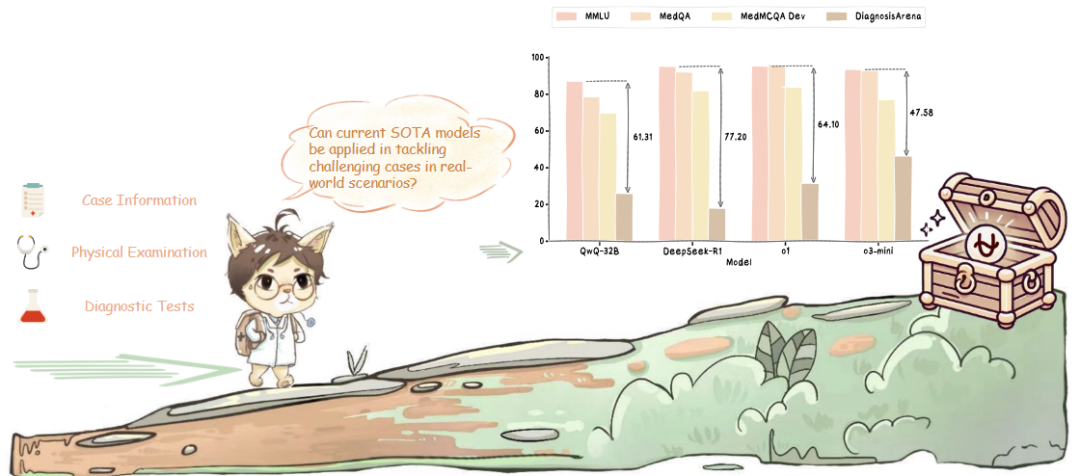
研究团队在DiagnosisArena上对现有多个大语言模型进行测试。
测试结果显示:即使是o3,在此项高挑战性诊断任务中也只达到了51.12%的准确率,而其他开源模型甚至难以取得25%的准确率。此项结果反映出当前模型在复杂医疗推理任务中仍面临诸多瓶颈。
构造过程:如何打造一个考验医学诊断推理能力的基准?
研究团队设计了一套精细的数据构建流程来构建DiagnosisArena,旨在全面评估大模型在真实临床场景下的诊断推理能力。
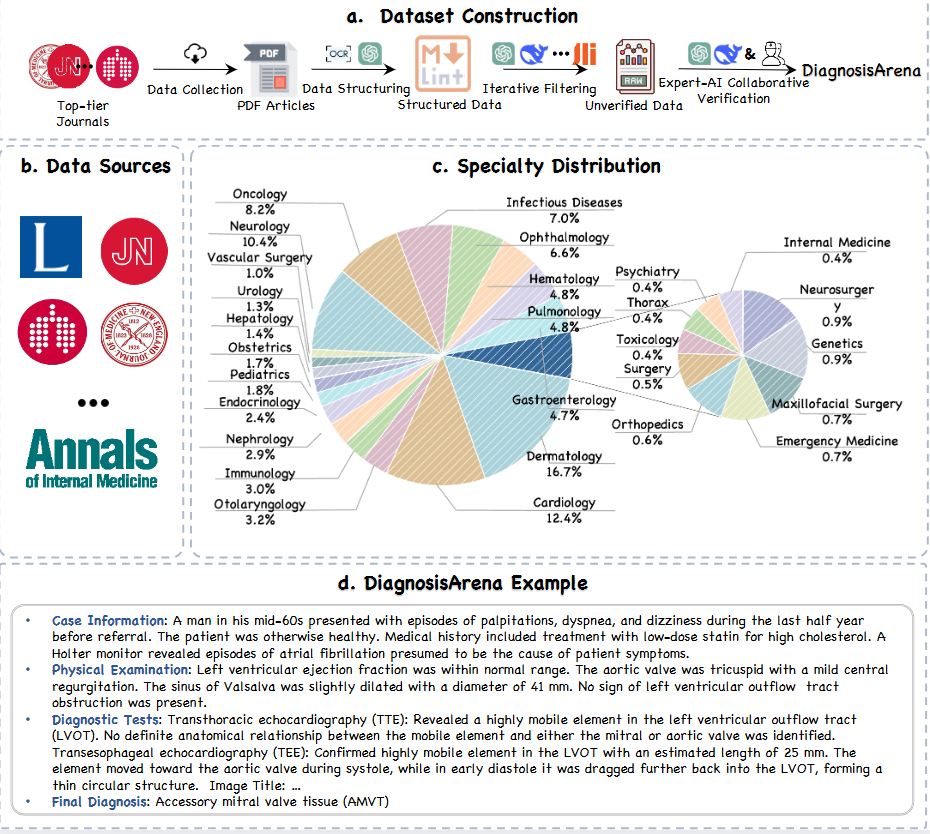
医学诊断是一项信息高度密集的任务,需要综合多种线索进行精确诊断。目前医学考试中的基础诊断任务无法反映模型的真实能力。因此,研究团队聚焦于发表在高影响力医学期刊上的复杂临床病例报告,并最终选择10个期刊作为高质量病例数据的来源,包括《柳叶刀》(The Lancet)、《新英格兰医学杂志》(NEJM)和《美国医学会杂志》(JAMA)等。
为了全面评估大模型在各个医学领域中的诊断能力,研究团队尽可能覆盖了多个临床专科,选取的病例横跨感染科、皮肤科、神经内科、眼科、心内科、血液科、肿瘤科等共28个医学科室。并且为了更贴近实际诊疗场景,研究团队对每一份病例进行结构化整理。每份病例报告被重新组织为四个部分:病例信息、体格检查、诊断检查和最终诊断。
随着模型能力的提高,一些典型病例仅需依赖记忆或简单知识点即可解答。为此,研究团队使用一系列模型进行预筛选,剔除模型可通过内部知识直接解决的题目,确保评测重点落在模型的综合判断与逻辑推理上。
研究团队还设计了多重的验证,以确保数据的质量。首先,使用专家模型判断病例是否包含足够的信息以支持合理的诊断路径,并只保留专家模型一致认可的病例。然后,对每个病例进行8次独立推理,若模型在多次尝试中均无法得出正确结论,则该病例被剔除。最后,研究团队与临床专家合作,排除了医生认为缺乏有效线索的病例。
经过这一严格的数据构建流程,研究团队最终打造了1,113道高质量的医学诊断题,构成了DiagnosisArena基准测试。
实验结果:当前模型在医学诊断中的表现究竟如何?
实验中,研究团队通过提示词引导模型生成五个可能的诊断结果,并按照置信度从高到低排序。随后用GPT-4o作为评估模型,将这些预测结果与真实诊断进行比对,分为“相同”、“相关”和“无关”三类。评价指标采用Top-k准确率,即模型输出的前k个预测结果中包含正确诊断的比例。
研究团队还从模型生成的结果中选取具有迷惑性的错误诊断选项,设置了包含四个选项的多项选择题(MCQ),构成了DiagnosisArena基准的选择题版本。
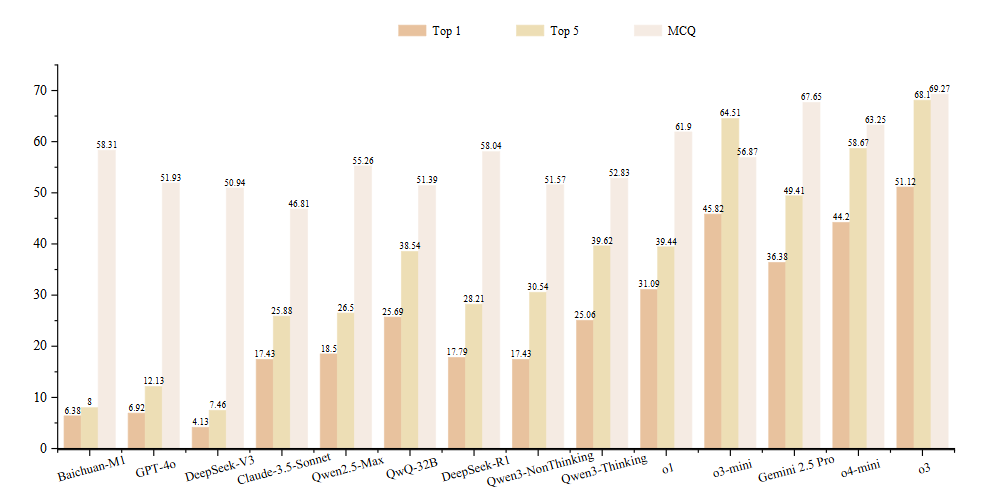
通过实验,研究团队得出以下结论:
-
当前模型仍无法胜任复杂临床诊断任务。在所有测试模型中,性能最佳的o3在DiagnosisArena上的准确率仅为51.12%,而o1和DeepSeek-R1的表现更不理想,准确率分别低至31.09%和17.79%。
-
推理能力显著提升了临床诊断任务表现。即使是目前公认性能较强的模型,如Claude-3.5-Sonnet和Qwen2.5-Max,在DiagnosisArena上的表现也不尽如人意,准确率均低于20%。相比之下,具备更强推理能力的模型——即便参数规模相对较小,例如QwQ-32B——其准确率显著提升至25.69%。一个具有代表性的案例是DeepSeek-R1,这是一个基于DeepSeek-V3训练的推理模型。它在任务中的准确率相比基础模型提升了13.66%,说明了增强推理能力在医学诊断任务中的重要性。
-
选择题设置无法真实反映大语言模型处理临床任务的能力。在选择题(MCQ)设置下,许多模型的表现出现了明显提升。例如,o1的准确率高达61.90%,而Baichuan-M1-14B虽然在开放式任务中得分尚不足10%,但在选择题中仍取得了58.31%。这种差异主要源于选择题本身的结构特性:预设选项的存在大大缩小了答案范围,使模型可以通过表面信息或已有知识排除干扰项,进而提升选择正确答案的概率。然而,这种“筛选式”的解题方式,并不等同于真实世界中医生所需的完整演绎推理过程。
案例剖析:为何当前推理模型难以胜任复杂医学诊断?
为了理解当前大语言模型在医学推理任务中的局限,研究团队选取了DiagnosisArena中的病例进行详细分析。
该病例被诊断为二尖瓣附加组织(Accessory Mitral Valve Tissue,AMVT),其关键诊断依据是在左心室流出道(LVOT)中发现了一个高度活跃的异常结构,并在心动周期中表现出显著的运动特征。这一结构的位置、活动性以及解剖关系,均支持其为附属瓣膜组织的判断。此外,多种影像学检查结果及偶然发现的二尖瓣环分离进一步验证了该结构的存在。
多数模型未能识别罕见病症
从各模型的输出结果来看,只有o3-mini成功将AMVT列为Top-1诊断结果,其余模型都偏离了正确答案。研究团队分析了DeepSeek-R1的回答,并认为当前模型在处理此类复杂临床问题时存在以下三类主要缺陷:
忽视罕见病的可能性。DeepSeek-R1的诊断思路主要集中于LVOT常见病变,如心脏肿瘤、栓塞或纤维层状肿瘤等,却未将AMVT纳入鉴别诊断范畴。这种“路径依赖”反映了模型在面对非典型疾病时缺乏探索能力。
对影像特征的理解存在偏差。尽管DeepSeek-R1识别到了一个具有活动性的结构,并推测其可能为乳头状纤维层状肿瘤或Lambl’s结节,但它忽略了AMVT同样可以表现为类似的丝状、活动性结构。这表明模型解读影像内容仍显不足,未能捕捉到形态学线索。
缺乏对症状与病理机制的综合推理能力。患者表现出的心悸、头晕和气短等症状被模型归因于多种心脏占位性病变,但DeepSeek-R1并未考虑AMVT可能引起的轻中度左心室流出道梗阻或间歇性心律失常。
当前模型尚未真正“理解”医学推理的本质
研究团队认为,上述现象的根本原因在于,目前的推理大语言模型仍未真正适应医学场景中复杂推理需求。医学诊断本质上是一个“拼图式”的推理过程——医生需要细致关注每一个临床线索,并通过逻辑链条将其串联起来,最终形成完整而准确的诊断。
然而,在这个案例中,尽管存在大量间接证据指向AMVT,DeepSeek-R1却选择性忽略这些细节,反而倾向于依赖常见疾病的诊断路径。这种行为反映出模型仍停留在“知识再现”层面解决问题,而非基于深度理解和关键细节进行真正的医学推理。


数据泄露检测:确保DiagnosisArena的稳健
随着预训练语料库覆盖范围的不断扩大,许多大语言模型在训练过程中已纳入了各类学术论文。这种做法带来了一个潜在风险:模型可能通过记忆特定病例来给出解答,而不是进行诊断推理。
为了验证DiagnosisArena是否存在潜在的数据泄露,研究团队开展了一系列分析。

预实验:小样本泄露检测
研究团队收集了2022至2024年间发表于《美国医学会杂志》(JAMA)和《新英格兰医学杂志》(NEJM)的共计690篇临床病例报告,构造为临床诊断题目(由于2025年的数据量不足,无法形成有效对比,因此未被纳入分析)。各年份样本数量保持平衡,每年约包含200条记录。
对这些数据进行测试和评估后,研究人员发现,主流模型的准确率在三年间基本保持稳定,仅有小幅波动——包括o3-mini、DeepSeek-R1、GPT-4o、DeepSeek-V3和Claude-3.5-Sonnet等。这一趋势表明,即使存在数据泄露,其影响也极为有限,不足以显著改变模型在测试中的表现。
然而,Baichuan-M1在2024年的准确率出现了轻微下降。这一变化说明,可能存在部分2024年之前的数据已被囊括在其训练语料库中,从而干扰了其后续评估结果。
进一步验证:基准整体未受泄露影响
研究团队进一步在构建好的DiagnosisArena上,进行了更细致的检测分析。与预实验的结果相比,DiagnosisArena在整体表现上呈现出更多不规则波动。但从十年跨度的整体趋势来看,无论是通用大模型还是医学专用模型,均未表现出随时间推移的,显著的准确率变化。
这一现象进一步支持了DiagnosisArena的评估有效性:它并未因数据泄露而产生系统性偏差,能够真实反映模型在医学诊断任务中的推理能力。
DiagnosisArena的意义:不仅是挑战,更是方向
过往的医学资格考试,或许只是检验AI医学能力的第一道门槛;而DiagnosisArena则代表了更高阶的考验——它要求模型具备真正的临床思维:能够拆解病情、关联线索、并进行多步骤的严谨推导。尽管一些模型在选择题设置下表现尚可,但在更具现实意义的开放式诊断任务中,它们的表现仍远未达到临床可用的标准。这表明,当前最先进的推理模型尚未掌握医学推理的本质。
研究团队希望,DiagnosisArena能够成为一个关键工具,帮助研究人员更深入地理解人工智能在医学领域的潜力与局限,从而推动相关技术向更高层次迈进。未来的AI医疗之路,不应止步于知识的复现,而应迈向真正的理解与推理——像医生一样思考,像专家一样判断,这才是通往智能医疗的核心路径。
技术文档:https://arxiv.org/abs/2505.14107
项目地址:https://github.com/SPIRAL-MED/DiagnosisArena
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)