

极市导读
来自阿里巴巴淘天集团和浙江大学的研究者们提出了一个全新的框架 FiLA (Fine-Grained Vision Language Model),旨在让 MLLM 在处理高分辨率图像时,既能看到细节,又能把握全局,有效缓解“切块”带来的碎片化问题。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
随着 GPT-4o、Gemini 等模型的惊艳表现,大家对 MLLM 的能力越来越期待。但很多时候,当我们想让模型帮我们阅读文档、分析医学影像或者看懂复杂的图表时,会发现它们有些问题——对图像中的 精细文本 和 微小细节 识别不佳。
这背后的一个重要原因是,很多 MLLM 使用的视觉编码器(比如 CLIP-ViT)是在较低分辨率(如 224×224 或 336×336)的图像上预训练的。直接处理高分辨率大图计算成本太高,一个主流的解决方案是 动态裁剪(Dynamic Cropping):把高清大图切成多个小图块(patches),分别送入视觉编码器。
这种“切块”处理虽然高效,但带来了一个新问题——语义碎片化 (Semantic Fragmentation)。想象一下,一个重要的物体、一段连续的文字或者表格的一部分正好被切割线分开,模型看到的就只是“碎片”,很难理解完整的上下文信息,导致识别和推理错误,尤其是在处理 文档、图表 或 包含密集小物体的场景 时。
为了解决这个痛点,来自 阿里巴巴淘天集团和浙江大学的研究者们提出了一个全新的框架 **FiLA(Fine-Grained Vision Language Model)**,旨在让 MLLM 在处理高分辨率图像时,既能看到细节,又能把握全局,有效缓解“切块”带来的碎片化问题。

论文标题: FILA: FINE-GRAINED VISION LANGUAGE MODELS
作者单位:浙江大学、阿里巴巴淘天集团
论文链接:
https://arxiv.org/pdf/2412.08378v3
核心问题:高分辨率图像处理的“切块”困境
为什么需要高分辨率?
-
文档理解 (DocVQA): 准确阅读扫描文档或截图中的文字。 -
图表分析 (ChartQA): 理解图表中的数据标签和趋势。 -
细粒度识别: 看清产品细节、识别微小物体。 -
场景文字识别 (TextVQA): 读取街道标志、商品包装上的文字。
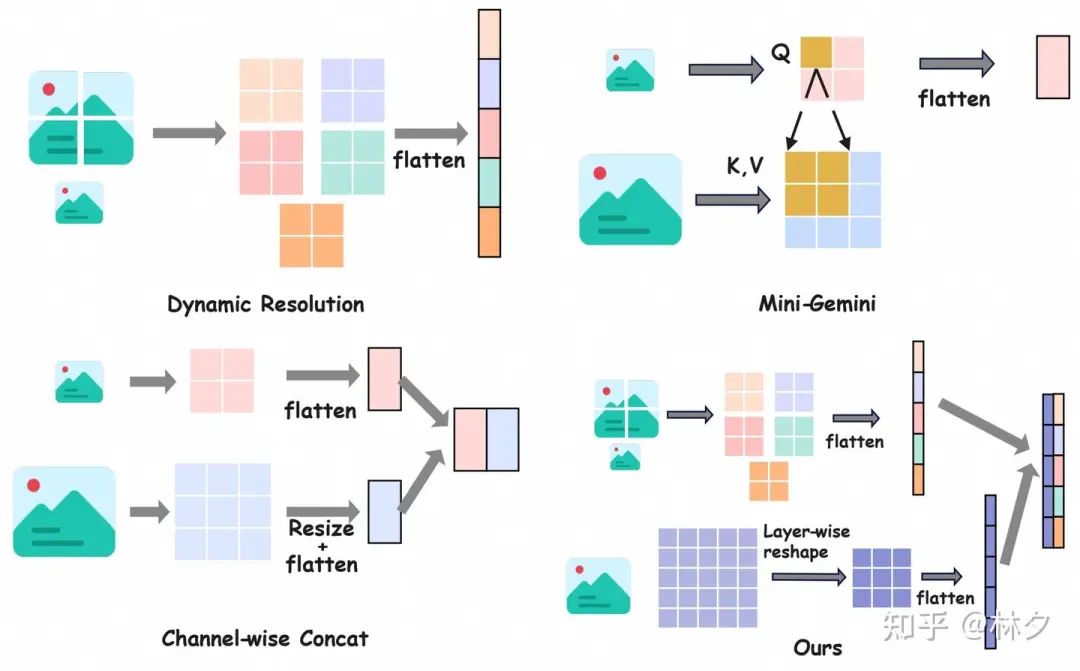
当前的“切块”策略(如下图 Dynamic Resolution 所示)虽然解决了计算效率问题,但其弊端也显而易见:
-
信息丢失: 位于切割边界的对象或文本被破坏。 -
上下文割裂: 图块之间的空间关系和语义联系减弱。 -
位置关系混淆: 模型难以判断一个被切割物体的不同部分之间的相对位置。
FILA 的创新解法:混合编码器与深度融合
面对“切块”带来的碎片化难题,FILA 提出了两大创新:
1. 混合编码器 (Hybrid Encoder)
FILA 没有完全抛弃“切块”策略,而是在此基础上引入了一个“全局信息”。它的核心是一个 混合视觉编码器,巧妙地结合了两种架构的优势:
-
低分辨率图块处理 (CLIP-ViT): 继续使用大家熟悉的 CLIP-ViT 来处理动态裁剪后的各个小图块,捕捉局部细节。 -
高分辨率全局信息 (ConvNeXt): 引入另一个强大的视觉编码器 ConvNeXt,直接处理 整张 按比例放大到更高分辨率(例如 768×768)的图像。ConvNeXt 的卷积特性使其能有效捕捉全局空间信息和上下文。
关键点: 这个设计意味着,当模型处理每一个小图块时,不再是“盲人摸象”,而是能同时“参考”由 ConvNeXt 提供的高分辨率全局信息。
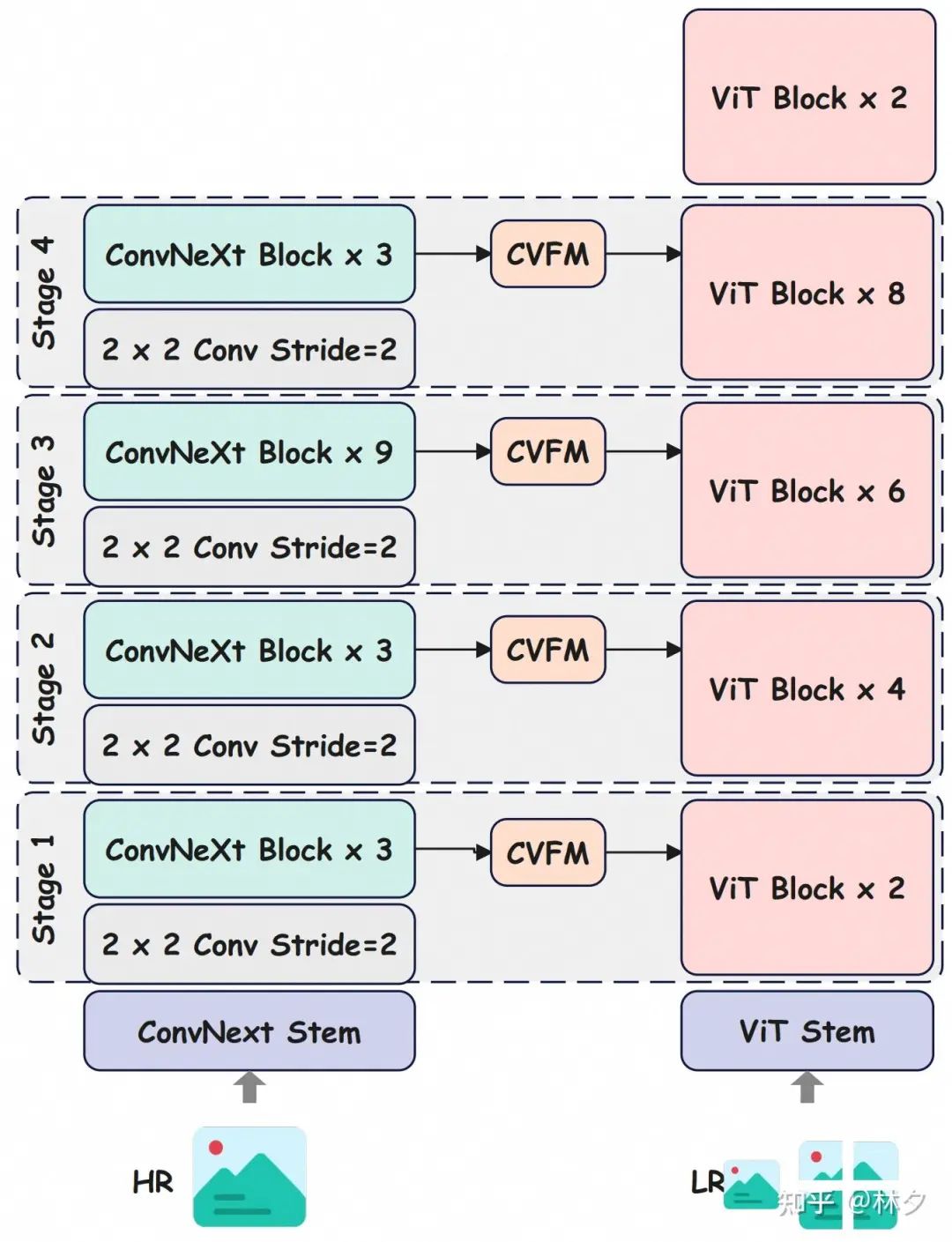
2. ConvNeXt-ViT 深度融合模块 (CVFM)
光有全局信息还不够,如何有效地将这些信息融入到图块的处理过程中至关重要。FILA 设计了一个名为 CVFM 的 深度融合 模块。
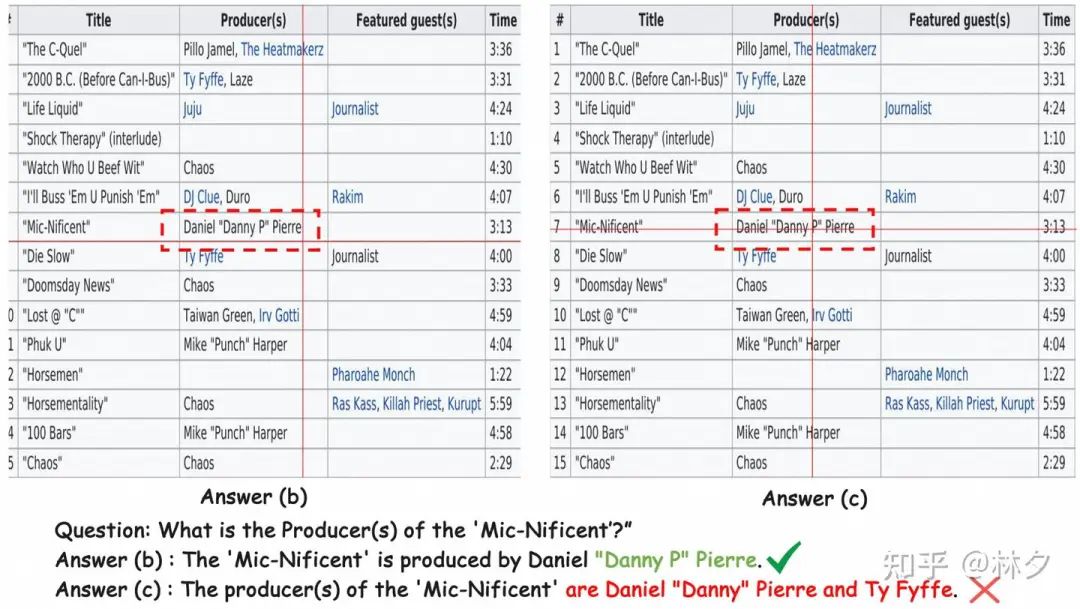
与一些只在最后几层进行简单特征拼接或 Cross-Attention 的方法不同(参考图2中 Mini-Gemini 和 Channel-wise Concat 的示意),FILA 的 CVFM 实现了 “深度” 融合:
-
多层交互: 来自 ConvNeXt 不同阶段(代表不同层的全局特征)的高分辨率特征,会被注入到 CLIP-ViT 的 多个中间层 中。 -
特征对齐与融合: CVFM 会将对应空间区域的 ConvNeXt 特征裁剪出来,调整尺寸后,与 ViT 在该层的图块特征进行 **通道拼接 (Channel Concatenation)**,再通过一个小型 MLP 网络进行融合。 -
稳定训练: 融合时使用了一个可学习的门控机制\text{tanh}(\alpha_{dense} * \textbf{MLP}(F_{concat})),\alpha_{dense} 初始化为 0,确保在训练初期不破坏原始 ViT 的稳定性,让模型平稳地学习如何利用全局信息。
简单来说,CVFM 就像在 ViT 处理每个图块的过程中,不断地给它“看”高分辨率全局图的对应区域,告诉它“这个图块在整张图的什么位置,周围大概是什么样子”,从而有效修复了语义碎片化问题。
FILA 的整体架构与训练
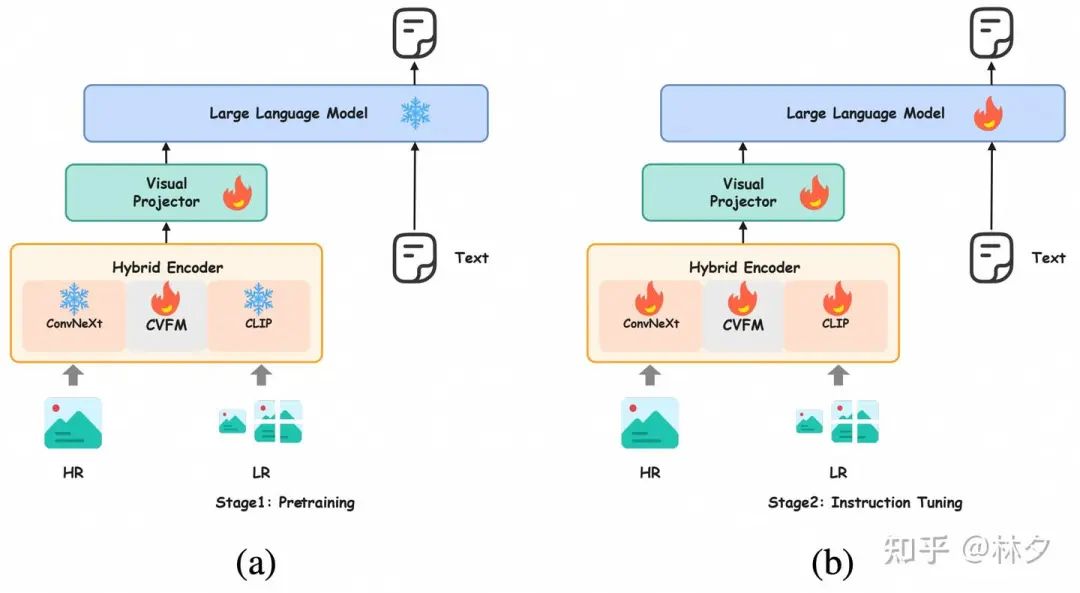
-
输入处理: 高分辨率图像输入后,进行动态裁剪,得到一个低分辨率全局图和多个 336×336 的图块。同时,原始图像也被放大到更高分辨率(如 768×768)送入 ConvNeXt。 -
混合编码: 图块和高分辨率全局图分别送入混合编码器的 ViT 和 ConvNeXt 分支,并通过 CVFM 进行深度特征融合。 -
特征投影与语言模型: 融合后的视觉特征通过一个投影层(MLP)映射到语言模型的空间,与文本输入一起送入 LLM (文中使用了 LLaMA3-8B)。 -
两阶段训练:
-
预训练: 固定大部分模型参数,只训练投影层和 CVFM 中的融合部分,快速对齐视觉和语言特征。此阶段不使用动态裁剪,直接缩放图像。 -
指令微调: 启用动态裁剪,开放所有模型参数进行端到端微调,让模型学会处理碎片化信息并遵循指令。
实验效果:显著提升与全面领先
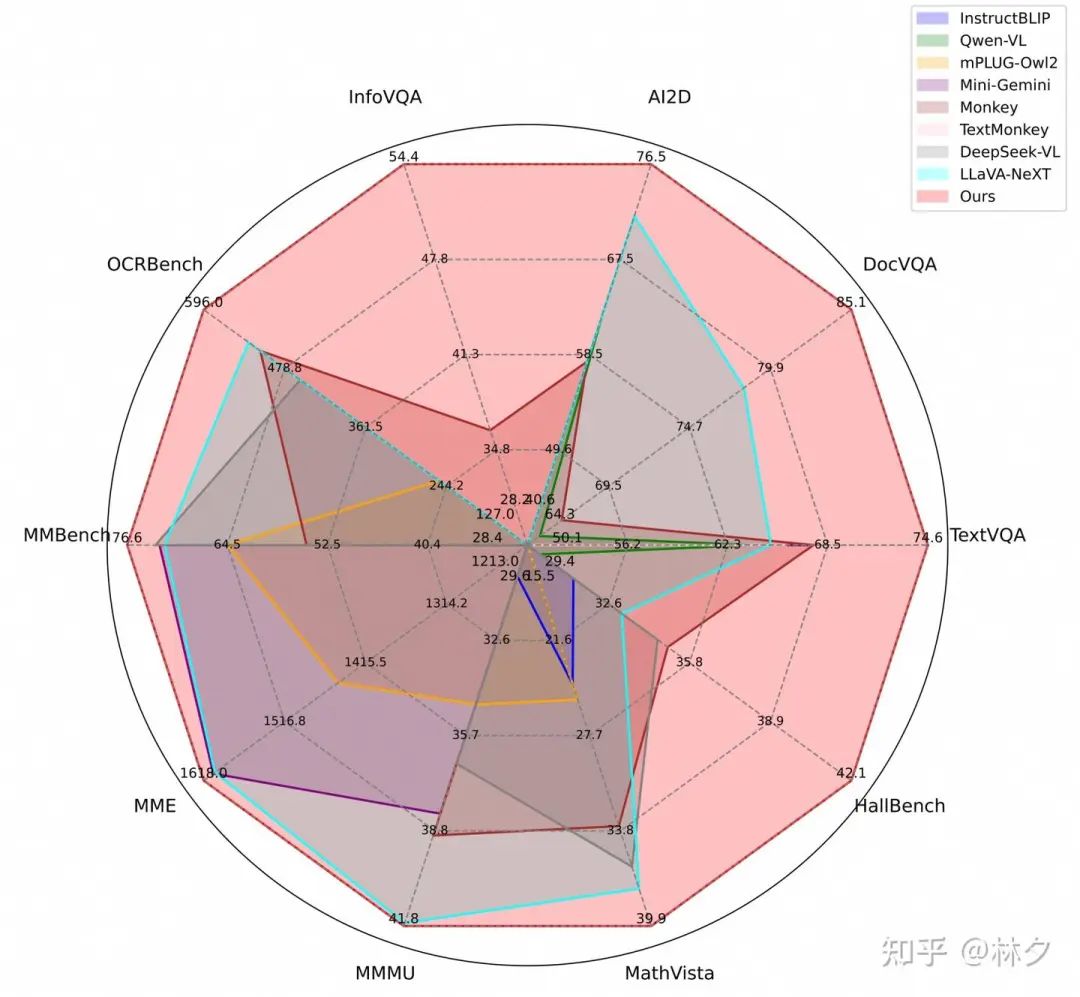
研究者们在 10 个主流的 VLM benchmark 上进行了广泛评估,结果非常亮眼:
-
细粒度与文档理解任务大幅领先:
-
在 TextVQA(图像中的文本问答)上,比 LLaVA-NeXT 提升 **9.6%**! -
在 DocVQA(文档问答)上,比 LLaVA-NeXT 提升 **6.9%**! -
在 AI2D、InfoVQA、OCRBench 等需要细粒度识别的任务上也取得了 SOTA 或接近 SOTA 的成绩。 -
通用 VLM 能力同样出色:
-
在 MME(综合评估)上超越 LLaVA-NeXT 1.7%。 -
在 MathVista(数学推理)上超越 LLaVA-NeXT 6.4%。 -
在 MMBench、MMMU、HallusionBench 等通用基准上也表现优异。
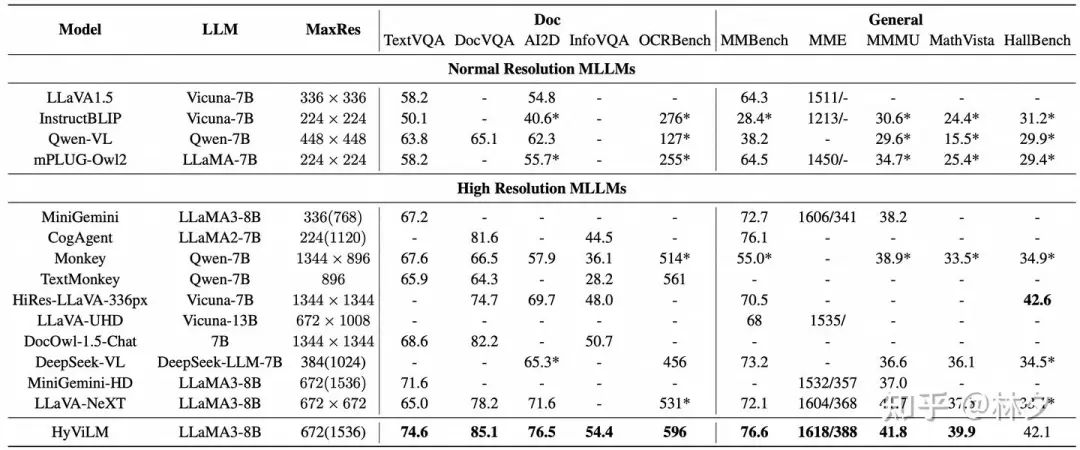
关键优势: FILA 在大幅提升性能的同时,输入给 LLM 的视觉 token 数量与 LLaVA-NeXT 保持一致,这意味着 计算效率没有明显增加,真正做到了“又好又快”。
消融实验验证:
研究者还通过消融实验证明了:
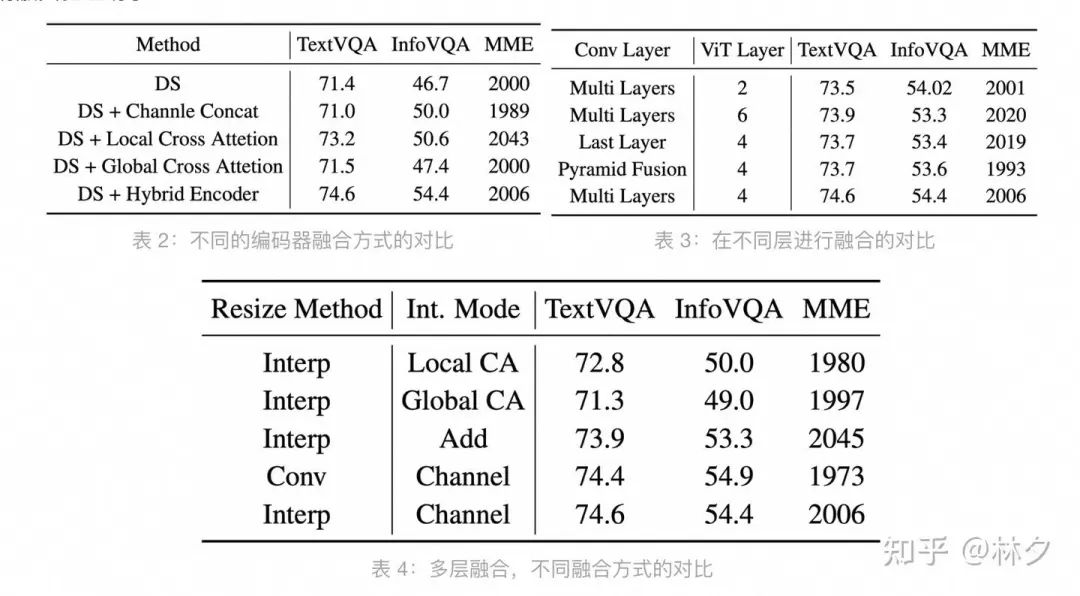
-
混合编码器的必要性: 相比仅使用动态裁剪或简单的后期融合,FILA 的混合编码器能显著缓解碎片化问题(见表 2)。 -
深度融合的优越性: 相比只在最后一层融合或将 ConvNeXt 特征先融合再与 ViT 交互,FILA 的多层深度融合策略效果最佳(见表 3)。 -
融合方式的选择: 对比了通道拼接、交叉注意力、特征相加等融合方式,通道拼接效果最好(见表 4)。
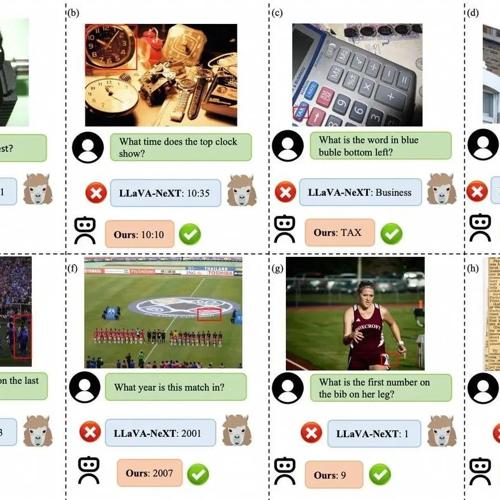
可视化对比:
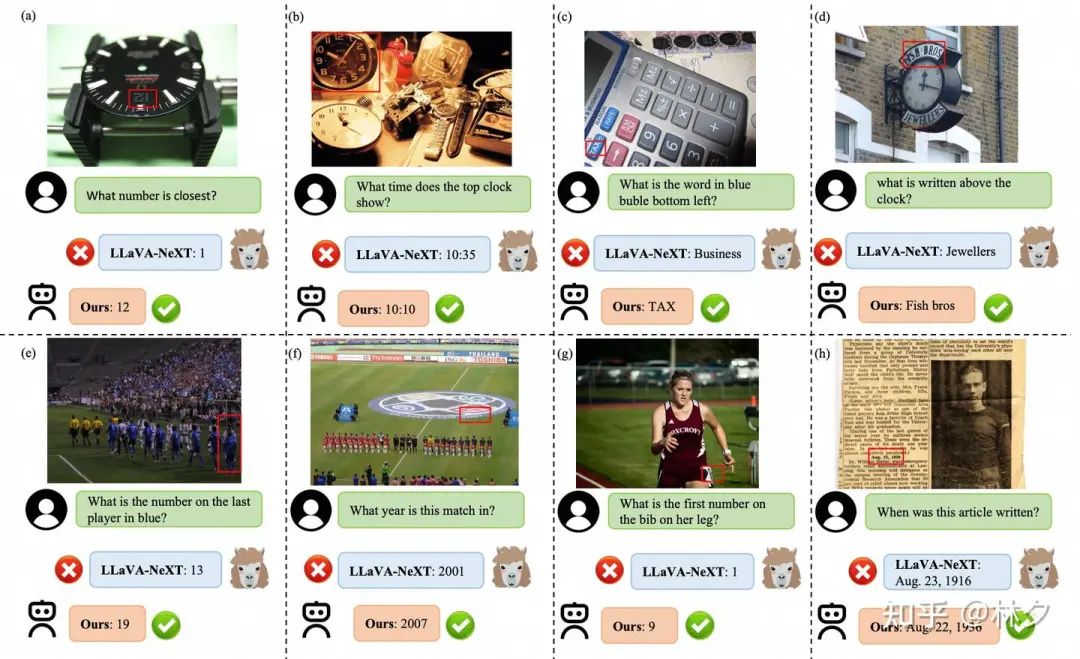
上图直观展示了 FILA 的威力。在 LLaVA-NeXT 因为图像被切割而识别错误或遗漏信息的情况下,FILA 凭借其获取的全局上下文信息,能够准确地识别出:
-
被切割开的数字 “12” (图 a) -
钟表上方的文字 “Fish bros” 而非下方的 “JEWELLER” (图 d) -
运动员腿上模糊的数字 “9” (图 g) -
报纸上精确的日期 “Aug. 22, 1936” (图 h)
这些例子生动地证明了 FILA 在解决语义碎片化、提升细粒度识别方面的有效性。
FILA 框架通过创新的 混合编码器 和 CVFM 深度融合 策略,在不显著增加计算负担的前提下,有效解决了 MLLM 处理高分辨率图像时因动态裁剪导致的 语义碎片化 问题。它赋予了 MLLM 更强的 细粒度视觉理解 能力,尤其是在 文档分析、图表解读 和 密集文本识别 等场景下表现突出,并在多个通用基准测试中取得领先。
(文:极市干货)