

极市导读
这篇文章提出了一种全新的图像生成范式——DiSA,首次将扩散模型的逐步退火过程引入自回归生成框架中,在保持高质量图像生成的同时显著提升采样效率。该方法有效缓解了自回归模型在复杂数据生成中的不稳定性问题,为图像生成任务提供了更稳健且高效的解决方案。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本文目录
1 DiSA:自回归图像生成加速:扩散采样退火
(来自 Australian National University 等)
1.1 DiSA 研究背景
1.2 重新思考已有的自回归 + 扩散模型
1.3 自回归 + 扩散模型的关键发现
太长不看版
通过减少 token 来实现高分辨率自回归图像生成。
越来越多的自回归模型,如MAR、FlowAR、xAR和Harmon采用扩散采样来提高图像生成的质量。然而,这种策略导致推理效率低,因为扩散采样令牌通常需要 50 到 100 步。本文探讨了如何有效地解决这个问题。我们的主要动机是,由于自回归过程中生成了更多的标记,后续标记遵循更多的约束分布,更容易采样。为了直观地解释,如果一个模型生成了一条狗的一部分,剩余的标记必须完成狗,因此受到更多约束。经验证据支持我们的动机:在后期生成阶段,下一个标记可以由多层感知器很好地预测,表现出低方差,并遵循从噪声到标记的更接近直线去噪路径。基于我们的发现,我们引入了扩散步长退火 (DiSA),这是一种无需训练的方法,随着生成更多的标记,逐渐使用更少的扩散步骤,例如,在开始时使用 50 步,并在后期逐渐降低到 5 步。由于 DiSA 源自我们在自回归模型中特定于扩散的发现,因此它补充了仅针对扩散设计的现有加速方法。DiSA 只能在现有模型上的几行代码中实现,尽管很简单,但 MAR 和 Harmon 的推理速度快 5 – 10 倍,FlowAR 和 xAR 的推理速度快 1.4 – 2.5 倍,同时保持生成质量。
1 DiSA:自回归图像生成加速:扩散采样退火
论文名称:DiSA: Diffusion Step Annealing in Autoregressive Image Generation
论文地址:
https://arxiv.org/pdf/2505.20297
项目主页:
https://github.com/Qinyu-Allen-Zhao/DiSA
1.1 DiSA 研究背景
越来越多的 Autoregressive Model 通过使用 Diffusion Sampling 来生成连续 token,如 MAR、FlowAR、xAR 和 Harmon,显著提高了生成的质量。推理时,这些模型以自回归生成的 token 作为输入,并采用 Diffusion 过程对下一个 token 进行采样。
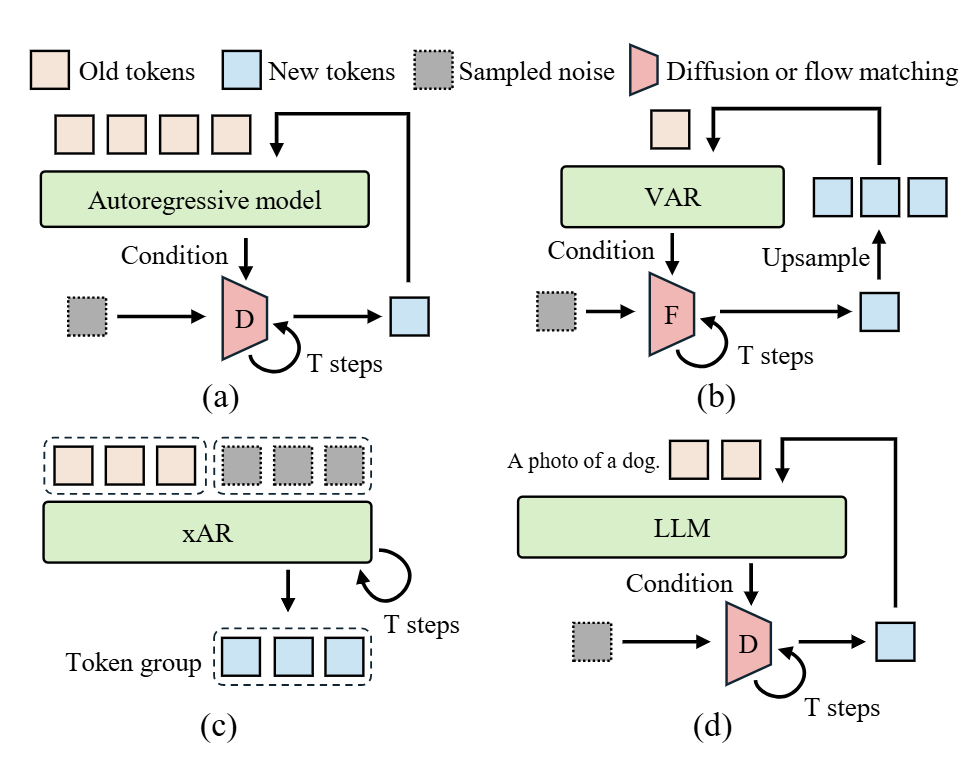
尽管 Diffusion 可以帮助 Autoregressive Model 得到更高的图像质量,但是需要很多 denoising step 来生成每个 token,因此推理效率较低。比如 MAR 去噪 100 次,而 xAR 去噪 50 次。初步实验表明,多步扩散过程占 MAR 中约 50% 的推理延迟和 xAR 中的 90%。直接扩散步骤的数量会加速这些模型,但是会显著降低生成质量。比如,假如 MAR 的 diffusion step 变为 10,ImageNet 256×256 上 xAR-L 的 FID 从 1.28 增加到 8.6,MAR-L 甚至无法生成有意义的图像。
1.2 重新思考已有的自回归 + 扩散模型
使用 image tokenizer,图像可以表示为 token 序列 。例如,可以使用 VAE 将图像编码为 256 个 token。图像生成可以定义为从图像 token 的联合分布中采样 。采样的 token 被 tokenizer 解码回图像。
自回归模型将图像的生成制定为下一个 token 预测任务:
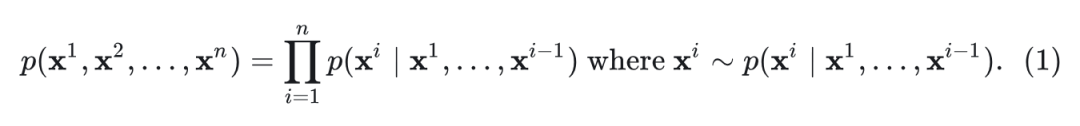
MAR 和 XAR 在每个自回归步骤中生成一组标记。对于这些模型, 表示一组 token。最近的自回归模型采用扩散过程采样 。
MAR 使用 Encoder-Decoder Backbone ,将先前生成的 token 作为输入并预测条件向量 用于下一个 token。Diffusion head 以 为 Condition,通过反向过程将采样噪声去噪到 token。
训练时, 和 中的参数根据扩散损失进行更新:
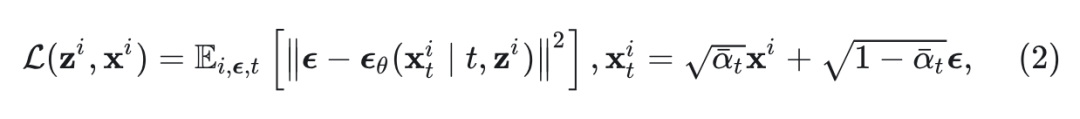
其中, 是从 和 中采样的向量。 定义了一个 noise scheduler。
FlowAR 使用 VAR 作为 Backbone ,Flow Matching 作为模型头 。与 MAR 类似, Backbone 将先前生成的 token 作为输入,并为每个下一个 token 预测一个条件向量 。使用采样的噪声 token,Flow Matching 头预测去噪 token 的 velocity。在训练时,Flow Matching Loss 计算如下:
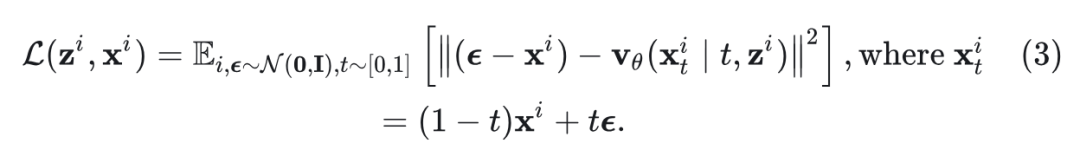
xAR 将先前生成的 token 和采样噪声作为输入。xAR 运行 50 次以将噪声去噪为 token,并继续对下一个 token 进行采样。
Harmon 是理解生成统一模型。本研究侧重于其 T2I 能力。Harmon 中的 Backbone 将文本 prompt 和生成的 token 作为输入,并为下一个 token 生成一个条件向量。以这个向量为条件的 Diffusion head 将采样噪声去噪到下一个 token。
1.3 自回归 + 扩散模型的关键发现
生成的 token 数越多,后续 token 的限制就越强。
本文动机是发现:随着生成更多 token,token 的分布变得更加受限,使得下一个 token 更容易采样。换句话说,早期的生成依赖于更强的分布建模和 token 采样,而后期较少。
有 3 个关键发现:
1) 在后期的自回归生成过程中,下一个标记可以很好地预测。
首先,本文训练了一个 MLP 或重新利用原始模型的 head,基于生成的 token 的 hidden representation,预测扩散过程的结果。
作者用一个模型,根据生成 token 的 hidden representation 来预测 。对于 MAR 和 Harmon,训练了一个 MLP 模型来替代原来模型的 head。MLP 直接根据生成的 token 的条件 预测 。对于 FlowAR 和 xAR,将原始模型的 head 重新用于 Flow Matching。具体来说,把 的采样噪声输入到模型中,得到估计的速度 ,并将下一个 token 预测为 。
如图 2 所示,在生成的早期阶段,MLP 预测不准确,缺乏细节。预测的 token 和生成的图像是模糊的,质量低。相比之下,随着生成更多 token,MLP 预测变得越来越准确,这表明 Autoregressive Model 现在为 Diffusion head 提供了更强的 Condition。


2) 在靠后的自回归步骤中,生成 token 的方差在逐渐减小。
作者探索了下一个 token 分布的方差。具体来说,使用 MAR 生成 10K 图像。在生成每个 时,采样 100 个可能的 ,并计算采样的方差。生成的示例和平均方差如图 3(a)-(b)所示。可以看出,随着生成更多 token,下一个 token 的分布变得越来越受限。
3) 后期的扩散路径更接近直线。
Rectified Flow 指出,从噪声到数据分布的直线路径是首选,因为它们可以用粗略的时间离散化来模拟,因此在推理时需要更少的步骤。受此启发,作者测量了在 Condition 下去噪路径 的 Straightness。
MAR 和 Harmon 使用 Diffusion Process,不在 Rectified Flow 的 Loss Function 上进行训练。因此,计算 Score Function 与从 noise token 到 clean token 的直线方向之间的余弦相似度。
其中, 。
如图 3(c) 所示,在生成的后期,从噪声到 token 的扩散路径变得更接近直线,这表明可以使用更大的步长和更少的扩散步骤来完成去噪过程。
1.4 扩散步骤退火
上述发现表明,后期生成阶段所需的 diffusion steps 比早期阶段少。基于上面的观察,本文提出了一种 training-free 的采样策略 DiSA。
DiSA 的核心思想是:在生成的前期阶段,next token 的分布比较多样化,因此对早期 token 使用更多的 diffusion step (比如 50)。在生成的后期阶段,next token 的分布相对已经很受限了,因此对后期 token 使用更多的 diffusion step (比如 5)。
作者比较了 3 种 time scheduler:two-stage,linear,和 cosine。
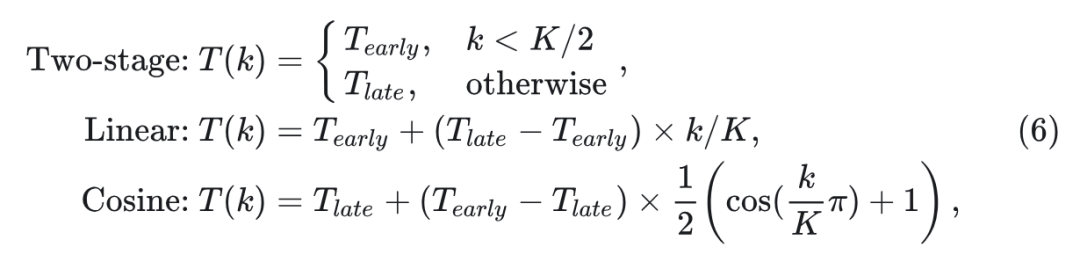
式中, 表示自回归步骤为 时的 diffusion step。 和 是控制步数的两个参数。 是自回归步骤的总数。
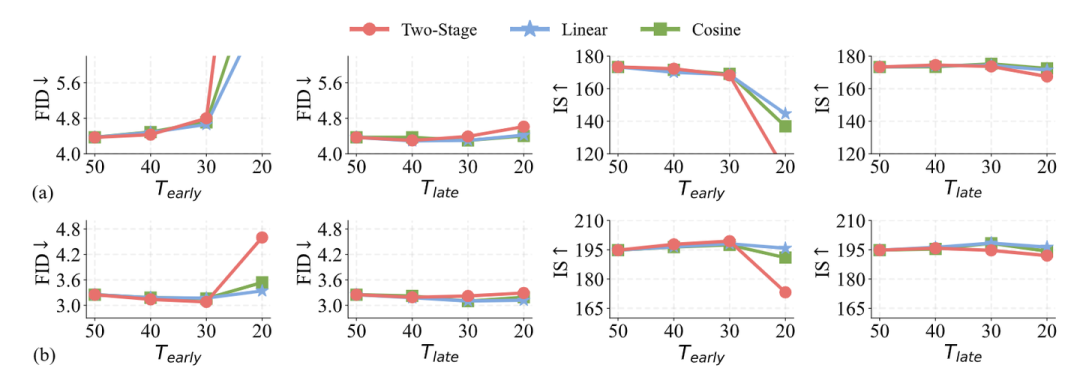
作者在 MAR 上做了初步实验来验证方法有效性。具体是在 MAR-B 和 MAR-L 上实现了 3 个 time scheduler,修改了 和 的值,并在 ImageNet Benchmark 上评估模型。自回归步骤数设置为 64, 和 的默认值均为 50 。结果如图 4 所示,在前期阶段减少 diffusion step 的数量会降低生成质量,但在后期减少 diffusion step 的数量就不会。后续实验中使用 linear scheduler,因其具有更好的性能。
1.5 实验设置
实验主要包括四个预训练模型:MAR、FlowAR、xAR 和 Harmon。MAR、FlowAR 和 xAR 在 ImageNet 256×256 生成任务上进行评估。作者还测量了生成一个 batch 256 张图像的推理时间。Harmon 在 T2I 基准 GenEval 上评估。报告了平均精度和推理时间。所有实验均在 4 个 NVIDIA A100 PCIe GPU 上运行。
1.6 实验结果
DiSA 不断提高 AR+Diffusion Baseline 模型的效率
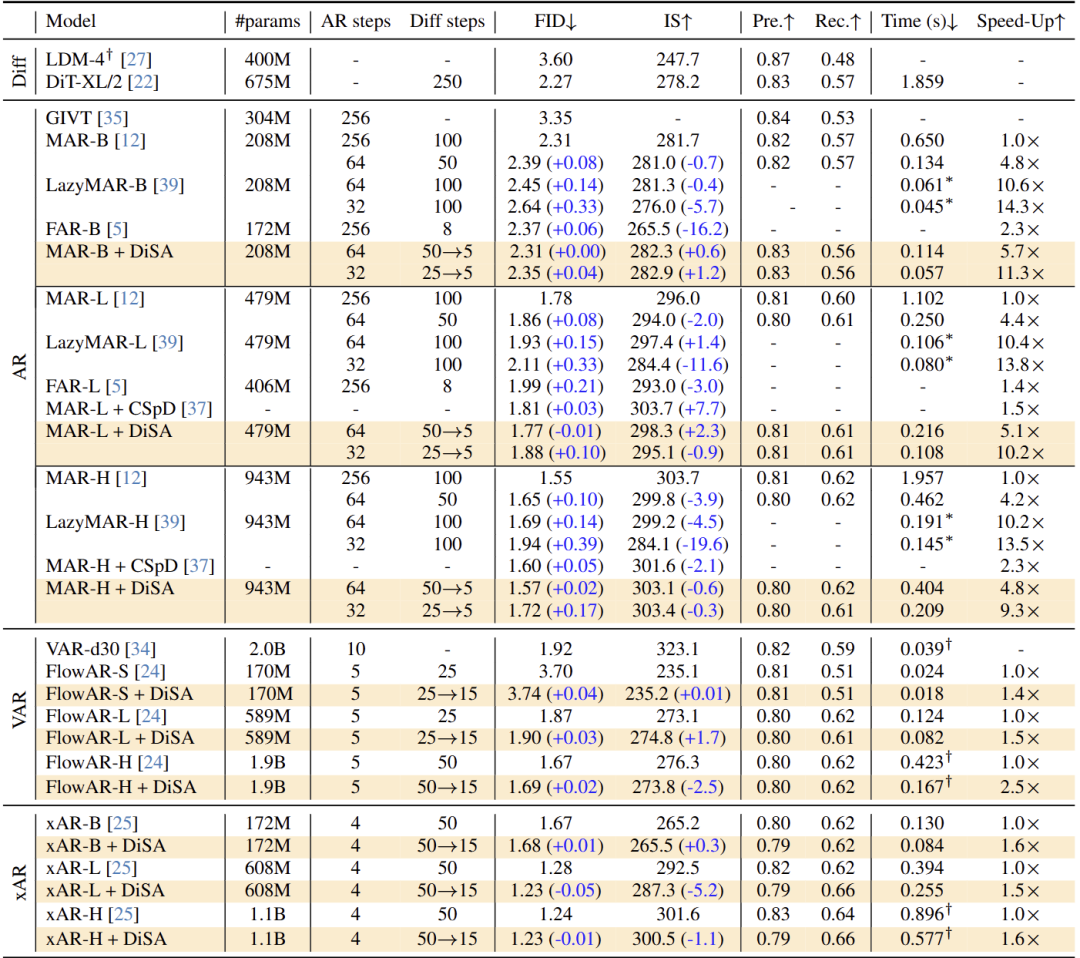
作者将 DiSA 应用于 MAR、xAR 和 FlowAR,并在图 5 中比较了 ImageNet 256×256 生成任务的性能。总体而言,DiSA 在保持竞争生成质量的同时不断提高 Baseline 模型的效率。
对于 MAR,原始的最佳性能是通过 256 个 autoregressive steps 和 100 个 diffusion steps 实现的。在 MAR 上使用了 DiSA 之后 (比如使用 50 → 5,一开始 diffusion step 取 50,逐步降低到 5),MAR-B,MAR-L,MAR-H 上分别实现了 5.7 倍、5.1 倍、4.8 倍的加速。而且,生成质量变化很小:DiSA 在 MAR-B 上产生相同的 FID,在 MAR-H 上增加 FID 0.02。
如果我们进一步将 MAR 减少到 32 个 autoregressive steps 和 25 → 5 个 diffusion steps,DiSA 可以带来 9.3-11.3 倍的加速,同时生成质量略有下降。DiSA 在 MAR-B 实现 11.3 倍的推理速度,同时 FID 提高了 0.04。
同样,带有 DiSA 的 FlowAR-H 实现了 2.5 倍的加速,同时保持了 1.69 的 FID 和 273.8 的 IS。带有 DiSA 的 xAR 模型实现了 1.6 倍的加速,对性能指标的影响可以忽略不计。带有 DiSA 的 xAR-L 实现 1.6 倍的加速,甚至将 FID 从 1.28 提高到 1.23。这些结果清楚地表明了 DiSA 的有用性。
与 MAR 其他加速方法的比较
DiSA 比 CSpD 和 FAR 更快,与 LazyMAR 相比也具有竞争力。而且,LazyMAR 适用于 MAR 的 cache 技术,无需修改扩散过程,并且在方法上是与 DiSA 正交的。
DiSA 对 T2I 生成模型也很有用
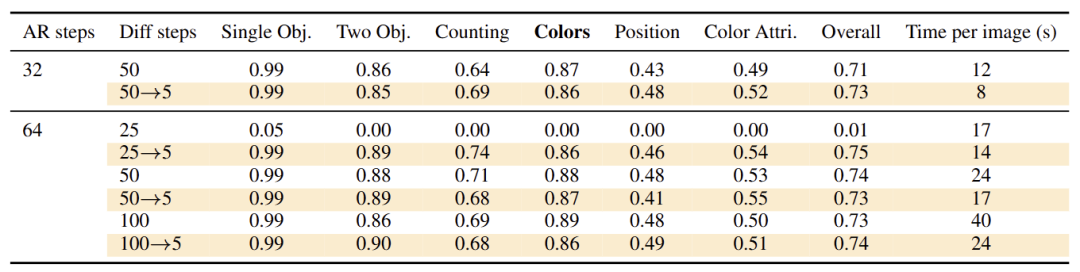
如图 6 所示,DiSA 还可以加速 T2I 生成模型 Harmon。使用 DiSA 的 Harmon 生成每张图像只需 8 秒,比原始实现快 5 倍,同时实现了相当的性能。
DiSA 是对现有扩散加速方法的补充
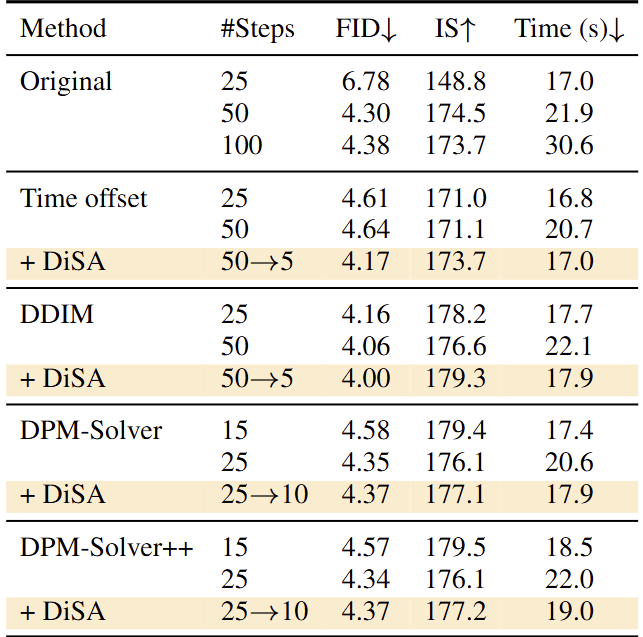
DiSA 还可以有效地结合现有的专为扩散设计的加速方法 (比如 DPM-Solver,DPM-Solver++)。
作者进一步在 MAR-B 上实现了几种现有的扩散加速技术,其中包括 DDIM、DPM-Solver 和 DPM-Solver++。注意,FlowAR 使用欧拉采样器,而 xAR 使用 EulerMaruyama 采样器。从 t = 950 开始扩散过程,而不是 t = 999 。
如图 7 所示,为扩散设计的现有技术可以加速自回归模型中的采样。DDIM 在 50 diffusion steps 和 25 diffusion steps 分别实现了 4.06 和 4.16 的 FID。DPM-Solver 和 DPM-Solver++ 表现出相当的性能,并将 diffusion steps 减少到 25。DiSA 是对这些 Diffusion 加速方法的补充。对于 DDIM、DPM-Solver 和 DPM-Solver++,结合 DiSA 提高了推理速度,同时保持了可比的生成质量。
效率和质量之间的权衡
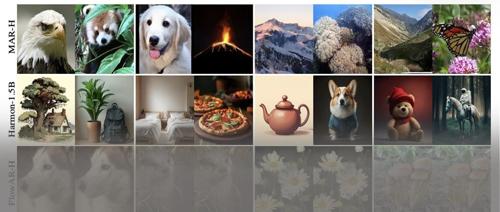
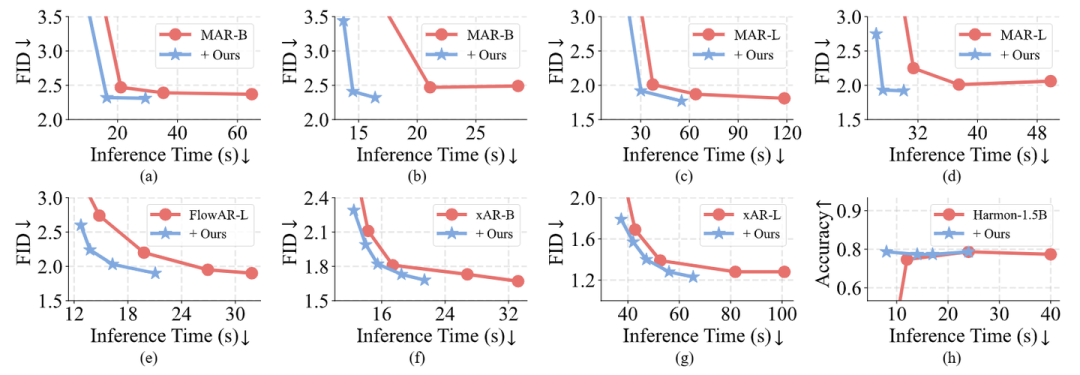
图 8 中展示了速度和生成质量的权衡。对于 MAR-B 和 MAR-L,评估了不同的 autoregressive steps 和 diffusion steps。FlowAR-L、xAR-B 和 xAR-L 使用不同的 flow matching steps 进行评估。Harmon-1.5B 在 GenEval 上使用不同的 autoregressive steps 和 diffusion steps 运行。可以看出,在不同的设置下,DiSA 可以显著提高这些模型的推理速度,同时保持生成质量。图 9 中展示了样本生成结果。

(文:极市干货)