


极市导读
清华大学丁贵广团队提出YOLOE模型,将目标检测和语义分割任务整合到一个高效架构下,通过文本、视觉和无提示三种交互场景实现多模态“万物识别与分割”,为视觉大一统模型指明方向,推动计算机视觉从任务特化向统一开放发展。>>加入极市CV技术交流群,走在计算机视觉的最前沿
导读
在计算机视觉领域从”任务特化”向”统一开放”的演进历程中,我们见证了从手工特征工程到深度学习范式,再从闭集假设到开放世界理解的多次技术跨越。
尽管每一次技术革新都推动了领域的显著进步,但现有方法普遍面临着性能精度、推理效率、部署复杂度之间的根本性权衡困境——很难在保证实时性能的同时实现真正的开放词汇理解能力。

近期,清华大学丁贵广团队最新发布的YOLOE[1] 这一长期挑战提供了创新性解决方案。YOLOE 基于轻量化的 YOLO 架构,通过RepRTA(重参数化文本适配器)、SAVPE(空间感知视觉提示编码器)、LRPC(轻量级区域提议分类器)三大核心技术策略,分别针对文本提示、视觉提示、无提示三种交互场景,实现了单一模型架构下的多模态、零冗余”万物识别与分割”能力。
笔者认为,随着 ChatGPT[2] 等大语言模型重新定义了AI应用范式,计算机视觉领域同样需要思考如何构建更加通用、高效的基础模型。
YOLOE 的出现不仅是对传统视觉任务边界的突破,更代表了CV领域向统一架构发展的重要里程碑。今天,藉此机会,让我们在回顾视觉理解技术演进的基础上,深入解析 YOLOE 的核心创新及其对未来发展的重要意义。
从各自为战到寻求统一:CV 简史回顾与“开放世界”的呼唤
传统方法的技术奠基
计算机视觉的早期发展深深植根于手工设计特征的范式中,这一时期的核心理念是通过专家知识构建针对性的特征描述子来解决特定视觉任务。这种方法虽然在控制环境下表现出色,但也奠定了”任务特化”的技术基调,例如一些经典的工作有:
-
• Viola-Jones检测器:通过Haar-like特征与AdaBoost级联分类器实现实时人脸检测,开创了基于积分图像的快速特征计算先河 -
• HOG+SVM框架:方向梯度直方图特征结合支持向量机,在行人检测任务上展现了梯度统计特征的有效性 -
• SIFT+BoW模型:尺度不变特征变换配合词袋模型,为图像检索和物体识别提供了旋转、尺度不变的解决方案
技术局限性分析:这些方法的核心问题在于特征表达的局限性和任务间的割裂性。手工特征往往针对特定的视觉模式进行优化,缺乏对复杂场景下多样性变化的适应能力。更重要的是,每个任务都需要独立的特征工程和模型设计,难以形成统一的技术框架来处理多模态、多任务的视觉理解需求。
深度学习革命:从任务特化到架构统一
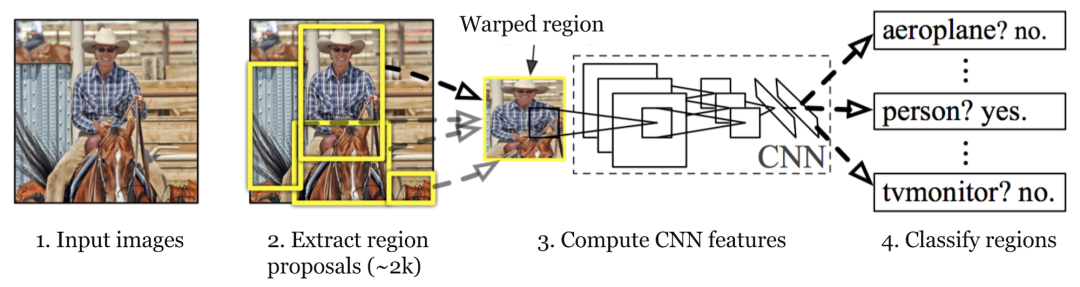
无论是是目标检测还是语义分割的发展,其经历了范式的分化与融合。
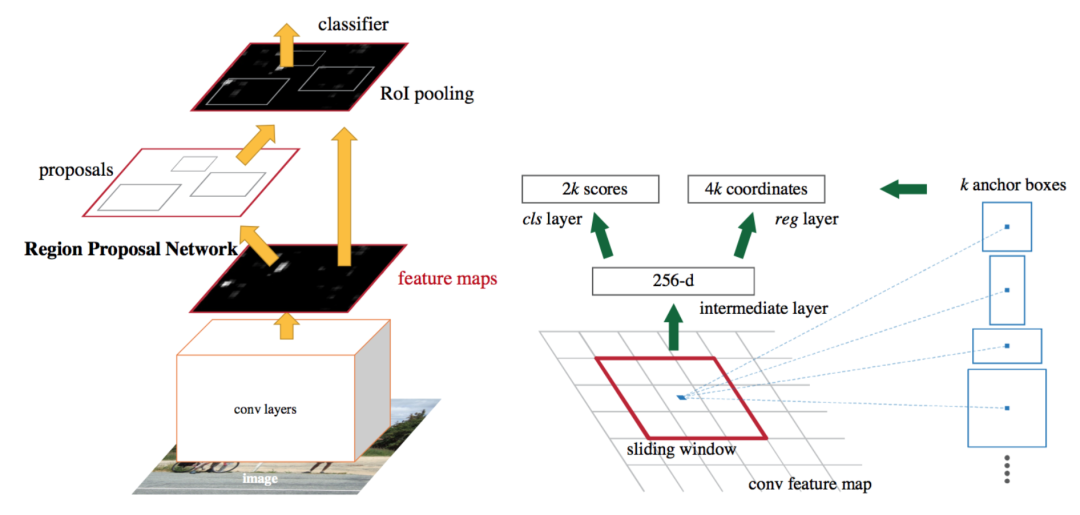
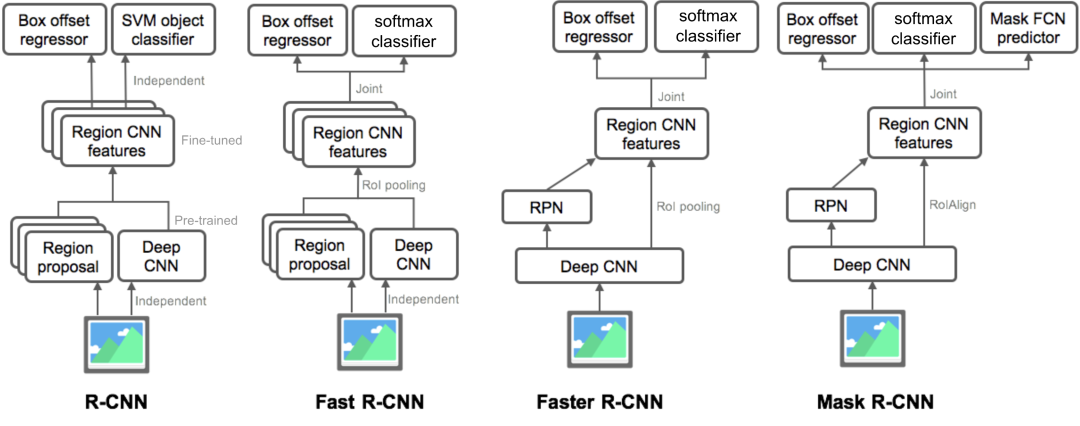
首先,回顾下早期的检测领域,以 R-CNN[3] 系列为代表的两阶段检测器在精度上具有显著优势,其演进轨迹表现为从最初的 R-CNN 使用选择性搜索结合 CNNs 特征提取,到 Fast R-CNN[4] 引入 ROI 池化实现统一训练,再到 Faster R-CNN[5] 提出区域提议网络 RPN,这一系列演化使两阶段检测器在精度上持续领先。
然而,这类方法依赖多阶段流水线以及非极大值抑制NMS的后处理,导致其在实时应用中存在性能瓶颈。
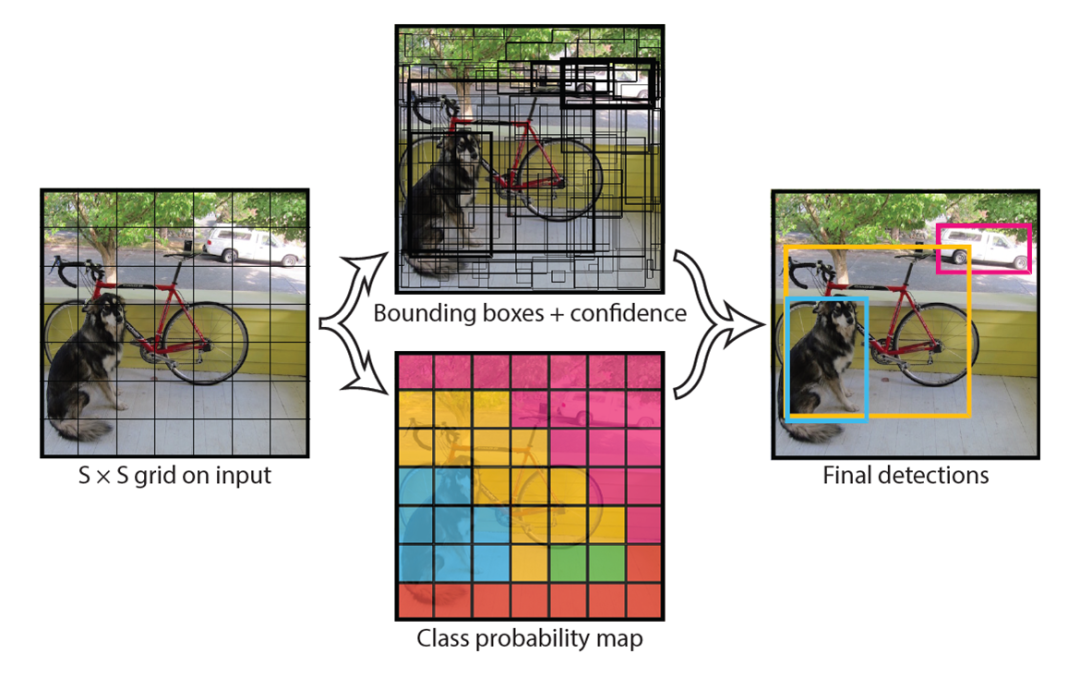
相较之下,单阶段检测器在速度方面实现了突破。 YOLO[6] 系列凭借其“网格化预测”的核心思想成功地将目标检测重构为一个单一的回归问题,在 PASCAL VOC 数据集上率先实现了45帧每秒的实时性能,后续提出的各式变种更是不断突破极限,彻底改变了检测器的设计范式。
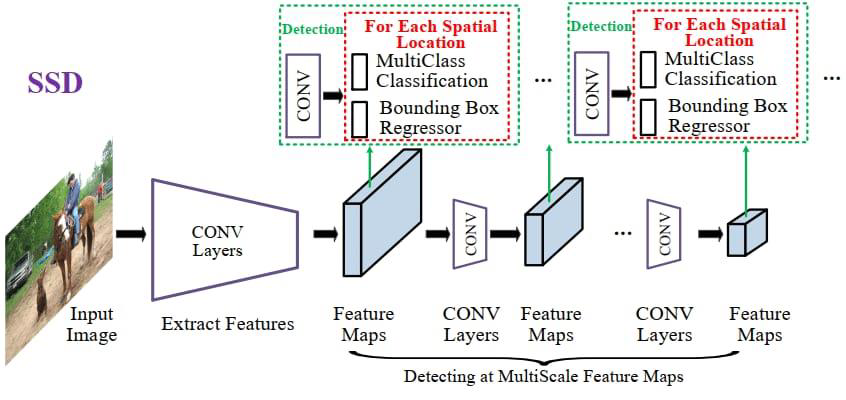
SSD[7] 则通过融合不同分辨率的特征图,提升了对多尺度目标的检测能力,在保持单阶段结构简洁性的同时实现了精度与速度的平衡。
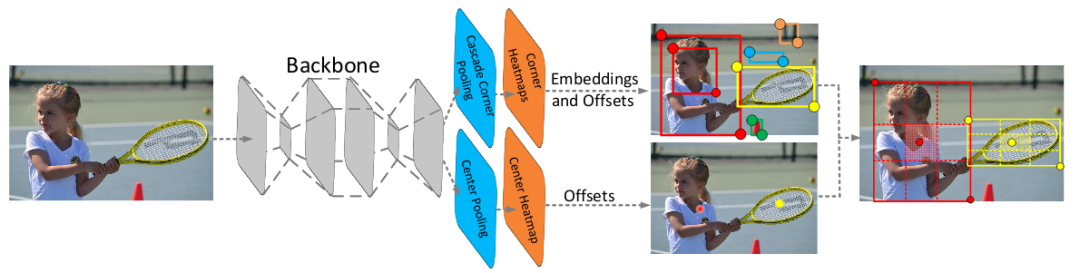
此外,Anchor-free 检测方法的兴起进一步推动了检测器设计的简化。代表性工作如 CornerNet[8]、CenterNet[9]、FCOS[10] 等不再依赖预定义的锚框,而是直接预测关键点或中心点位置,从而避免了锚框匹配与调参的复杂过程。这一类方法不仅提升了定位精度和模型泛化能力,也为端到端检测提供了更清晰的几何建模思路。
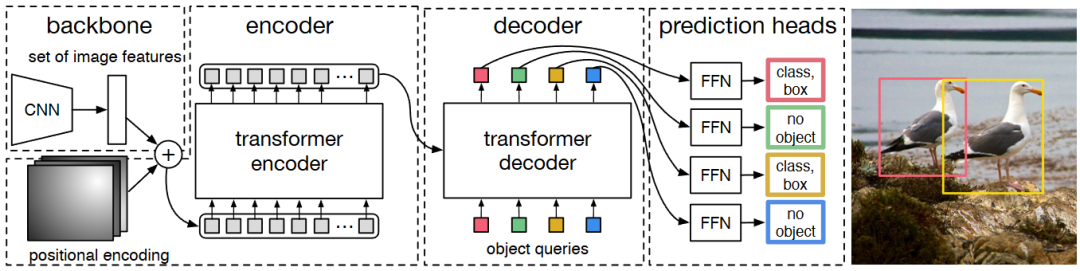
到 2020 年后,DETR[11] 范式的出现带来了端到端的检测变革,利用集合预测和匈牙利算法的双向匹配机制,彻底摆脱锚框设计和 NMS 后处理,为检测架构的统一化探索提供了全新思路。
同样的,像素级视觉理解任务方面也经历了类似架构上的技术演进。
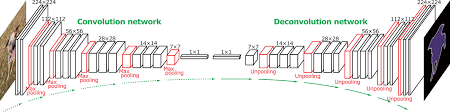
语义分割的创新始于全卷积网络 FCN[12] 的提出,它首次实现了端到端的密集预测,为像素级任务提供了基础模型结构。
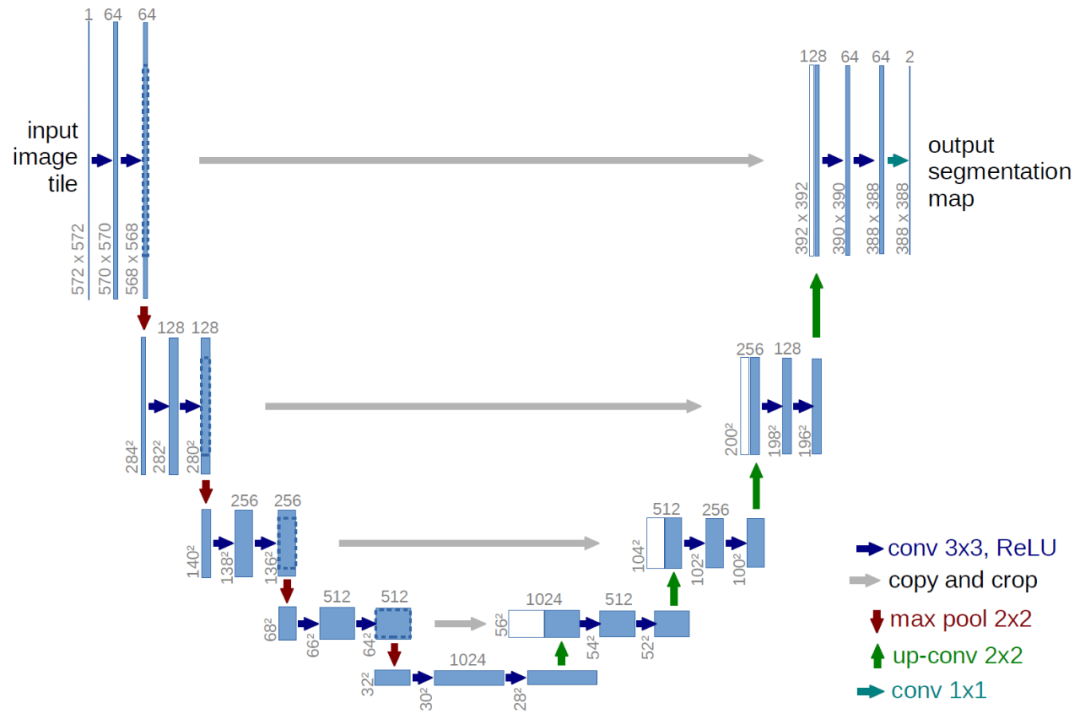
U-Net[13] 则以对称的编码器解码器结构结合跳跃连接,在医学、遥感、抠图等精细化任务中展现了出色的特征恢复能力。

实例分割方面,不同方法体现了多任务的融合。Mask R-CNN[14] 在Faster R-CNN的基础上增加了并行的掩码预测分支,实现了检测与分割的协同推进,成为多任务学习的代表。
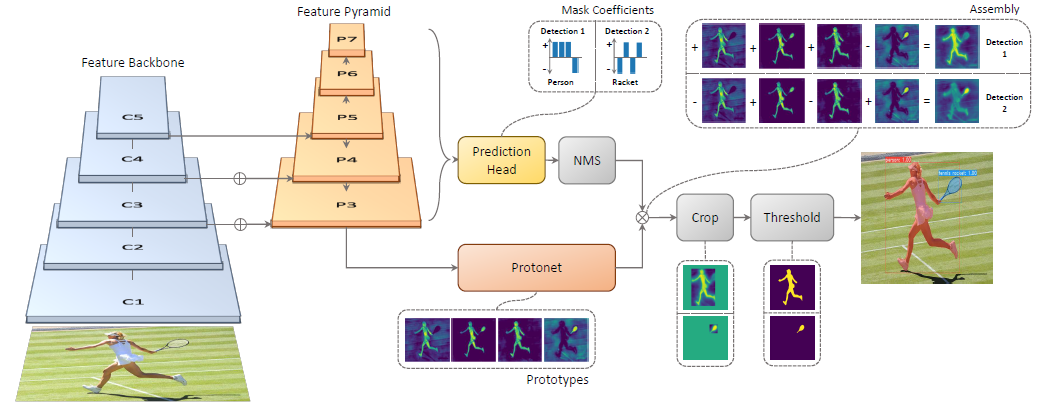
YOLACT[15] 通过原型掩码生成与系数预测的解耦设计,在实例分割任务中首次实现了真正意义上的实时性能。
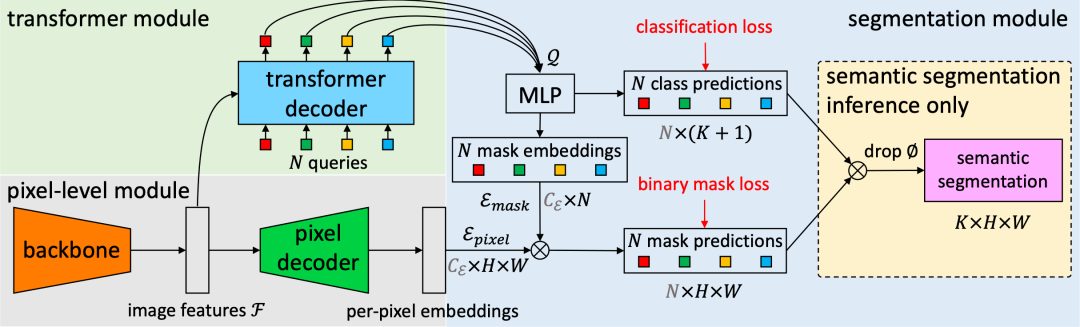
最后,以 MaskFormer[16] 为代表的模型进一步将语义分割与实例分割统一为掩码分类问题,并基于Transformer[17] 架构达成任务间的模型统一,推动了视觉理解范式的进一步融合。
从闭集到开放世界:提示驱动的通用视觉理解
上述传统深度学习方法受制于”闭集假设“——模型只能识别训练阶段预定义的固定类别集合。这种局限性在面对开放世界的复杂场景时显得尤为突出,新出现的物体类别或未见过的视觉概念往往导致模型失效,难以满足实际应用中的泛化需求。
在此背景下,多模态提示机制成为突破闭集限制的重要方向,逐渐发展出多种技术分化路径。
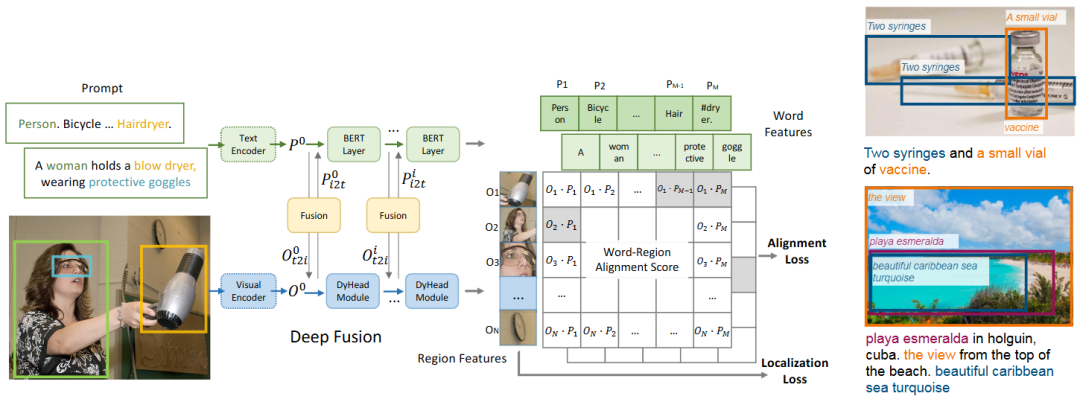
首先是文本提示驱动的零样本检测方面,GLIP[18] 通过将自然语言短语与目标检测任务融合,实现了基于文本的零样本检测能力,尽管多模态融合机制带来了较强性能,但也显著增加了计算成本。
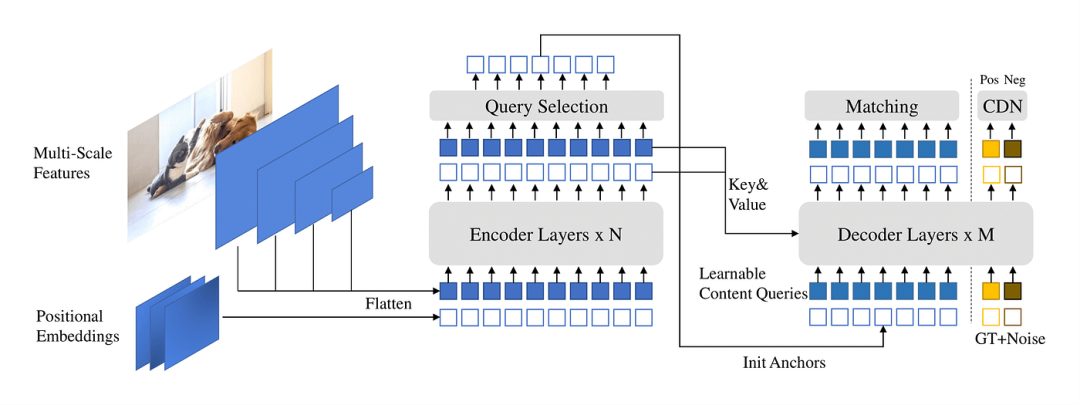
Grounding DINO[19] 进一步结合了自监督学习架构和文本编码能力,在零样本任务中展现出优异的泛化表现,但鉴于模型庞大,部署复杂,实际应用受限。
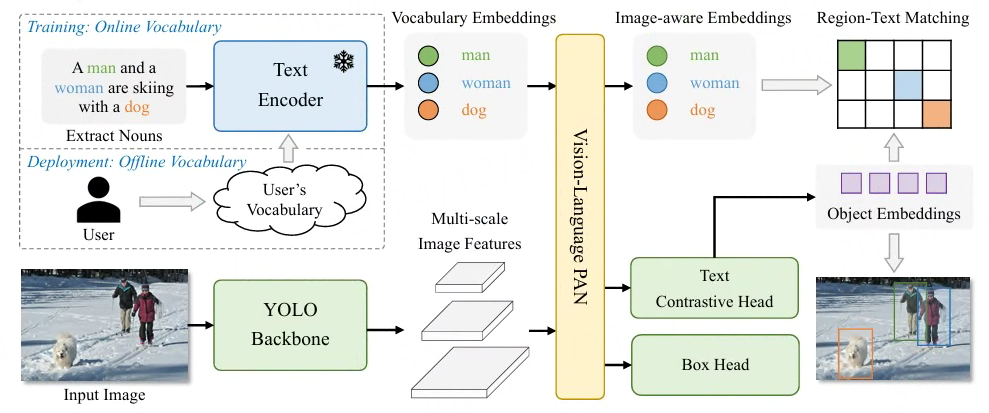
为此,YOLO-World[20] 在保持 YOLO 高效检测结构的基础上,引入文本编码器实现语义引导,显著提升了小模型在开放集场景下的适应能力,兼顾了检测精度与实时性,适合边缘设备部署。
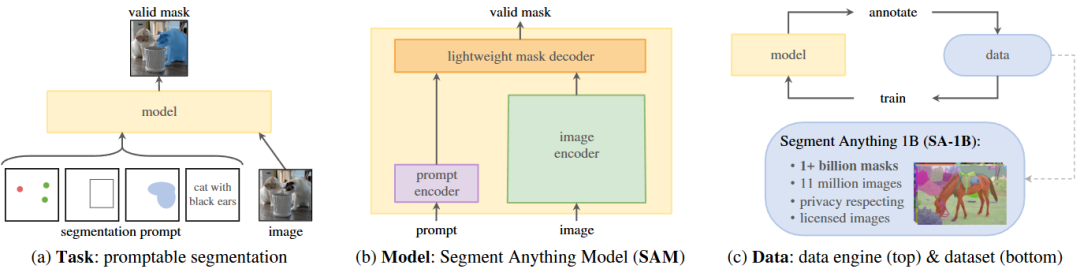
其次,视觉提示支持交互式理解,典型如 SAM[21] 通过点击、框选、掩码等方式实现对图像的分割操作,展现出强大的通用性,但模型规模庞大,推理成本高,难以实时应用。
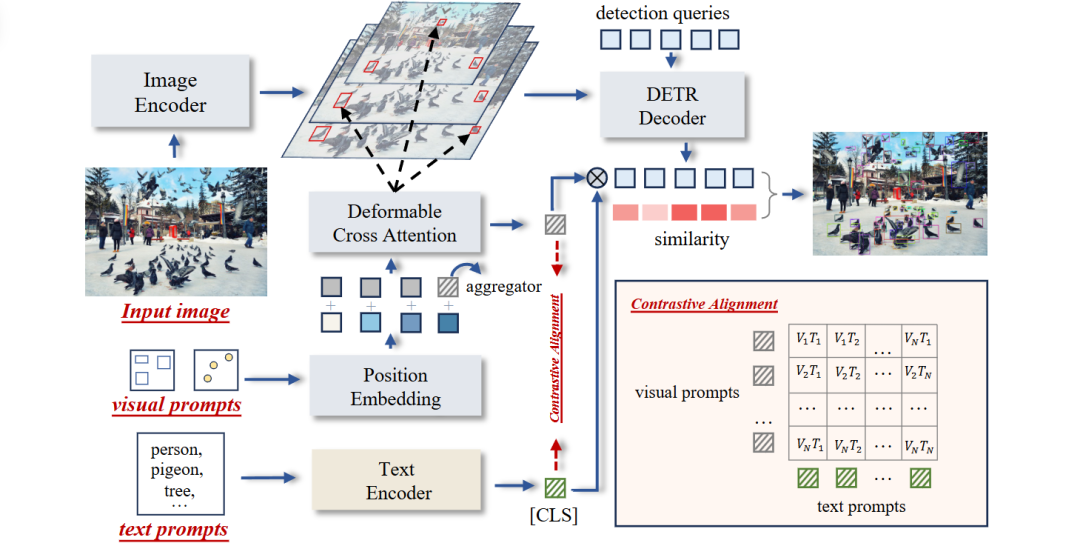
另一方面,T-Rex2[22] 则通过示例图像或掩码提示模型关注特定区域,提升了理解的灵活性,但依赖复杂的 Transformer 架构或额外编码器模块,仍存在计算瓶颈。况且,时至今日,该模型还未开源~~~
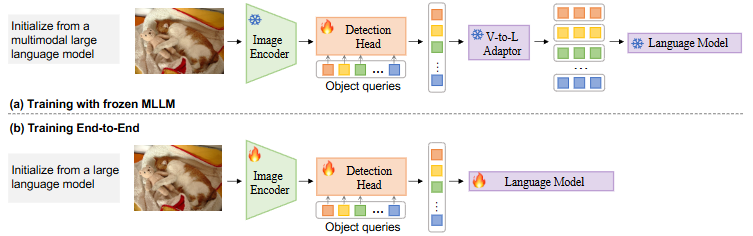
最后,对于无提示的自主生成方法如 GenerateU[23] 等,依托大型语言模型自动生成候选类别,实现了完全无监督的开放集检测,但生成过程延迟较高,难以满足实时需求。
综上,我们不难发现,面对多样的提示机制,当前的核心矛盾在于性能、效率与部署便利性之间的取舍。现有方法多数只能支持某一种提示方式,缺乏统一的多模态理解能力。而真正实现“看懂一切”,需要在保证高效推理的基础上,统一支持文本、视觉、交互等多种提示形式,这也是当前技术亟需突破的瓶颈所在。
👀 YOLOE:集大成者,意在“实时洞察万物”
YOLOE 的出现一定程度上打破了上述的“不可能三角”定律,其核心思想是在一个高度高效的单一模型如 Ultralytics-YOLO[24] 内,集成跨文本、视觉、无提示三种开放提示机制的目标检测和分割能力,实现“所见即所得”的实时效果。
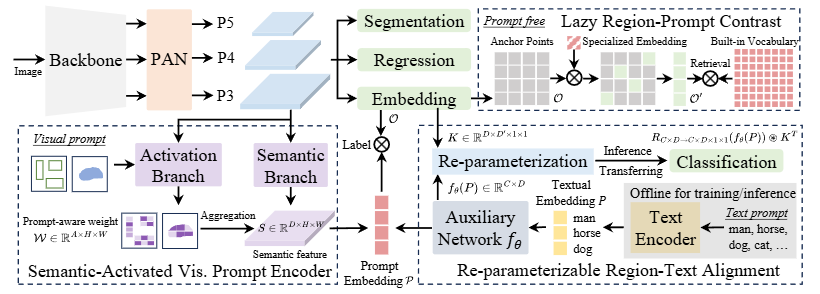
文本提示:可重参数化区域-文本对齐 (RepRTA)
对于文本提示,传统方法常因引入复杂的跨模态融合(例如 Grounding-DINO 就用了不少的 cross-attn 交互模块)而导致计算开销大,尤其是在处理大量文本时。
YOLOE 提出的 RepRTA 策略很实用,它通过一个轻量级的辅助网络(auxiliary network)来优化预训练的文本嵌入(textual embeddings),从而增强视觉-文本的对齐。这个辅助网络仅在训练时引入少量额外开销,用于处理预先缓存的文本嵌入。
最关键的是,在推理和迁移时,这个辅助网络可以被无缝地“重新参数化”(re-parameterized)到分类头中,使得最终的推理架构与原始 YOLO 完全一致,不增加任何额外的推理和迁移开销!
简单来说,RepRTA在训练时“借力”提升文本理解,使用一个仅含 SwiGLU 前馈层的辅助网络,针对预训练文本嵌入(如 CLIP)进行微调,以加强视觉—文本对齐;推理时“卸磨杀驴”,实现了性能与效率的双赢。
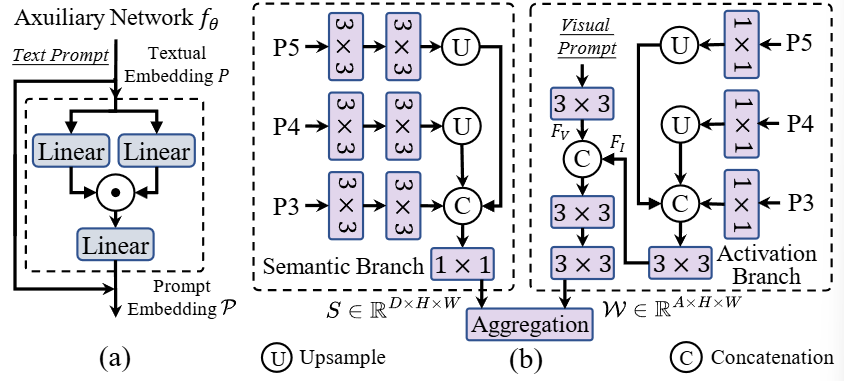
视觉提示:语义激活视觉提示编码器 (SAVPE)
诸如边界框、掩码或点等视觉提示,可以为指示感兴趣对象提供了更灵活的方式。现有方法通常依赖 Transformer 或额外的 CLIP[25] 视觉编码器,计算量大,不适合边缘设备。
YOLOE 为此设计了一个轻量级方案——SAVPE,其包含两个解耦的轻量级分支:
-
• 语义分支:输出与提示无关的(prompt-agnostic)语义特征,结构类似于目标嵌入头 -
• 激活分支:过将视觉提示(如掩码)与图像特征在低维空间交互,生成分组的、与提示相关的(prompt-aware)权重
这两个分支的输出(语义特征和权重)聚合后,生成信息丰富的提示嵌入(prompt embedding),且计算复杂度极低。SAVPE 通过这种方式,以最小的代价获得了强大的视觉提示编码能力。
无提示场景:惰性区域-提示对比 (LRPC)
LRPC 提出的背景是希望在没有明确文本或视觉提示的情况下,模型应当具备识别图像中的所有对象并给出其类别名称。现有方法如 DINO-X[26] 多依赖大模型来生成描述,但一样一来必然开销极大、效率也低。
为此,YOLOE 则另辟蹊径提出了 LRPC (Lazy Region-Prompt Contrast) 策略,笔者粗略看了下,其核心思路还是将此问题重新表述为一个检索问题。
首先,利用预训练的 YOLOE(训练一个专门的提示嵌入来识别“objects”这一泛指类别)找到图像中所有可能存在对象的锚点(anchor points);
然后,将这些被识别出的对象锚点与一个内置的大型词汇库(≈4.6K 类)进行“惰性”匹配(lazily matched),以检索类别名称。【所以模型在初始化的时候会比较慢,一旦“建库”成功,后续响应将会是非常快速】
最后,这种方法避免了对每个锚点都与整个词汇库进行昂贵的对比,也完全不依赖语言模型,从而在保证性能的同时实现了高效率。
🧪 令人印象深刻的实验结果:快、好、省
“Talk is cheap, show me the results!”
同样地,YOLOE 在多个基准测试中都展现了其卓越的性能、高效率和低训练成本。
开放词汇检测:
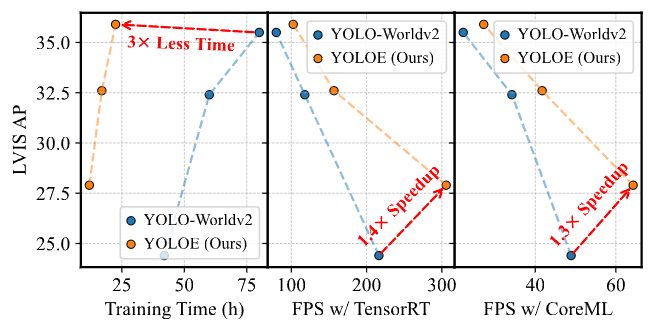
如图所示,与YOLO-Worldv2-S相比,YOLOE-v8-S 在 LVIS 上 AP 提升 3.5,训练成本减少 3 倍,推理速度提升 1.4 倍(T4 GPU)/ 1.3 倍(iPhone 12)。
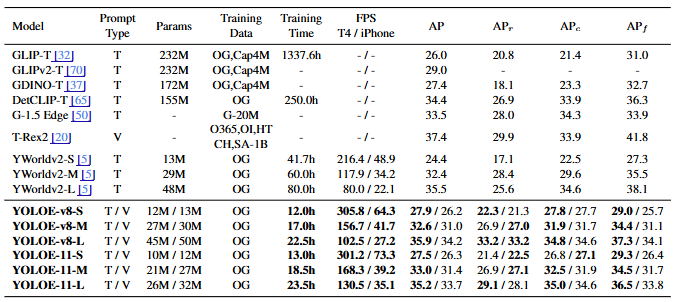
即使是 YOLOE-11-L(基于 YOLO11 架构)也能在 AP 与 YOLO-Worldv2-L 相当的情况下,推理速度快1.6倍。
视觉提示检测
与T-Rex2 相比,YOLOE-v8-L 在 AP 上提升3.3,APc 提升0.9,而训练数据量和训练资源消耗远低于前者。
开放词汇分割

YOLOE-v8-M/L 在零样本情况下,分割 APm 分别达到 20.8 和 23.5,显著优于在 LVIS-Base 数据集上微调过的 YOLO-Worldv2-M/L(分别高出3.0和3.7 APm)。
无提示检测
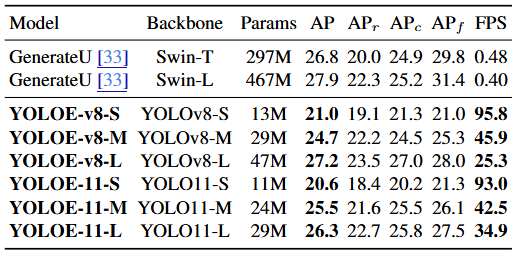
YOLOE-v8-L (AP 27.2) 相比 GenerateU (Swin-T backbone, AP 26.8),参数量减少 6.3 倍,推理速度提升 53 倍,AP 和 APr 均有提升。
下游任务迁移
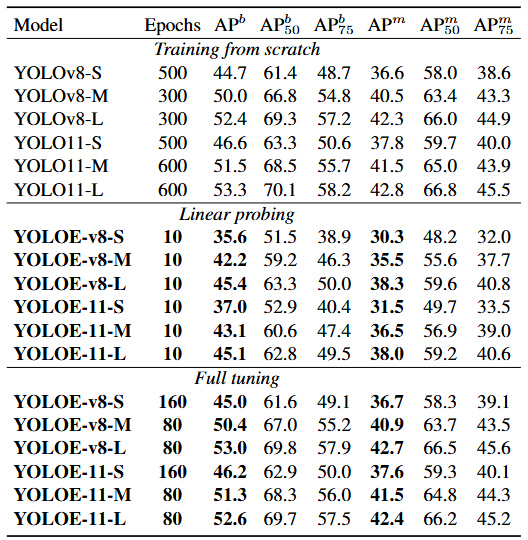
在 COCO 数据集上进行闭集检测和分割微调,YOLOE 展现了强大的迁移能力。例如,在仅使用约1/4训练轮次的情况下,YOLOE-v8-M/L 的检测 APb 和分割 APm 均优于从头训练的 YOLOv8-M/L。
消融实验
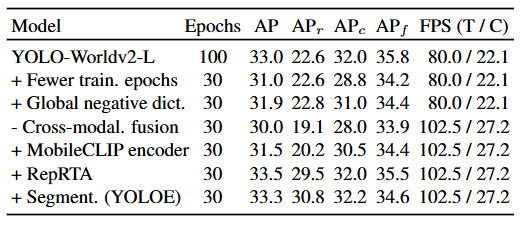
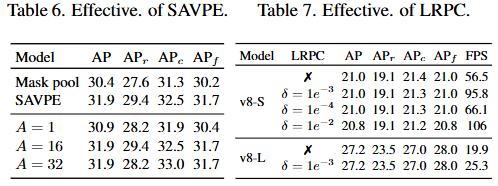
上述表格数据详细展示了 RepRTA、SAVPE、LRPC 各组件的有效性,以及不同参数选择(如SAVPE中的分组数A,LRPC中的过滤阈值δ)对性能的影响,验证了设计的合理性。
总结
YOLOE 为目标检测与分割的发展提供了重要方向。首先是统一性,YOLOE 将文本提示、视觉提示和无提示的检测与分割任务整合在一个模型中,并保持了高效运行,这说明未来模型将更加重视多任务统一处理,而非为单一任务定制模型。
其次是效率,在自动驾驶和机器人等需要边缘部署的场景中,模型运行速度至关重要。YOLOE 通过可重参数化、轻量化设计和惰性检索等手段在保证性能的同时显著提升了效率,为实时开放世界感知提供了可能。
开放词汇的能力也成为趋势,随着应用环境日益复杂,模型需要理解未知概念。YOLOE 在这方面的表现展示了视觉语言模型在增强传统计算机视觉模型开放性方面的巨大潜力。
在多模态提示处理方面,YOLOE 支持灵活输入,不论是文本、图像示例还是无需提示,用户都能根据需求以最自然的方式与模型交互,这提升了模型的实用性和用户体验。
此外,YOLOE 采用了“少即是多”的训练策略,文本提示模型训练完成后,仅需极少训练轮次即可实现对视觉提示和无提示场景的适配。例如 SAVPE 只需训练2个epoch,LRPC仅需1个epoch,训练成本远低于同类方法,这为资源有限的研究者和开发者提供了可行路径。
YOLOE 不仅仅是一个新的 SOTA 模型,更重要的是它构建了一种兼顾性能、效率和统一性的开放世界感知框架。它展示了未来的检测与分割系统应如人眼般,具备实时、高效和灵活理解复杂环境的能力,无需依赖明确的指令。
近期笔者的关注更多会转向大模型中的推理能力(Reasoning in LLMs/VLMs),如果你对此感兴趣,欢迎关注CVHub,我将持续在此与您分享最前沿的科技动态与思考。
引用链接
[1] YOLOE:https://arxiv.org/pdf/2503.07465
[2]ChatGPT:https://openai.com/index/chatgpt/
[3]R-CNN:https://arxiv.org/abs/1311.2524
[4]Fast R-CNN:https://arxiv.org/abs/1504.08083
[5]Faster R-CNN:https://arxiv.org/abs/1506.01497
[6]YOLO:https://arxiv.org/abs/1804.02767
[7]SSD:https://arxiv.org/abs/1512.02325
[8]CornerNet:https://arxiv.org/abs/1808.01244
[9]CenterNet:https://arxiv.org/abs/1904.08189
[10]FCOS:http://arxiv.org/abs/1904.01355
[11]DETR:https://arxiv.org/abs/2005.12872
[12]FCN:https://arxiv.org/abs/1411.4038
[13]U-Net:https://arxiv.org/abs/1505.04597
[14]Mask R-CNN:https://arxiv.org/abs/1703.06870
[15]YOLACT:https://arxiv.org/abs/1904.02689
[16]MaskFormer:https://arxiv.org/abs/2107.06278
[17]Transformer:https://arxiv.org/abs/1706.03762
[18]GLIP:https://arxiv.org/abs/2112.03857
[19]Grounding DINO:https://arxiv.org/abs/2303.05499
[20]YOLO-World:https://arxiv.org/abs/2401.17270
[21]SAM:https://arxiv.org/abs/2304.02643
[22]T-Rex2:https://arxiv.org/abs/2403.14610
[23]GenerateU:https://arxiv.org/abs/2403.10191
[24]Ultralytics-YOLO:https://github.com/ultralytics/ultralytics
[25]CLIP:http://arxiv.org/pdf/2103.00020
[26]DINO-X:https://arxiv.org/abs/2411.14347

(文:极市干货)