



4月30日,该团队推出的首个推理大模型MiMo-7B曾引发业界关注,时隔一个月又推新模型,再次展现了小米在模型领域的进军决心。只不过,相比较在开源领域太耀眼的DeepSeek,MiMo系列模型想获得广大开发者认可或许还有一段路要走。

小米新模型的推出节点略显尴尬,因为开源大模型的竞赛刚被DeepSeek拉升到了全新水平。
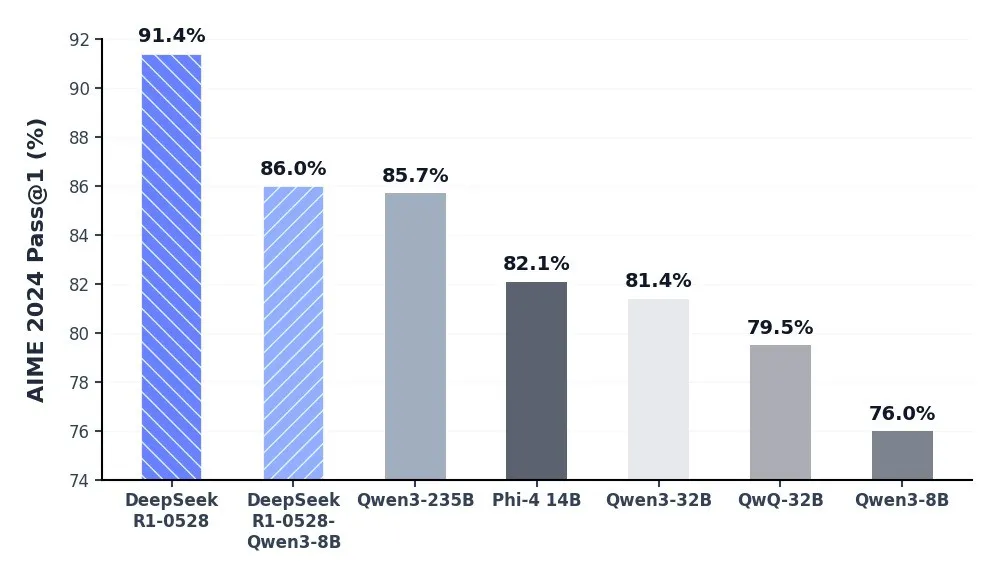
DeepSeek-R1-0528的整体性能已接近O3、Gemini 2.5 Pro等AI巨头的领先旗舰模型,在数学、编程、通用逻辑等多项基准测试中均展现出更加优异的性能,相比较上代R1模型实现了长足进步,不过参数规模也高达685B。
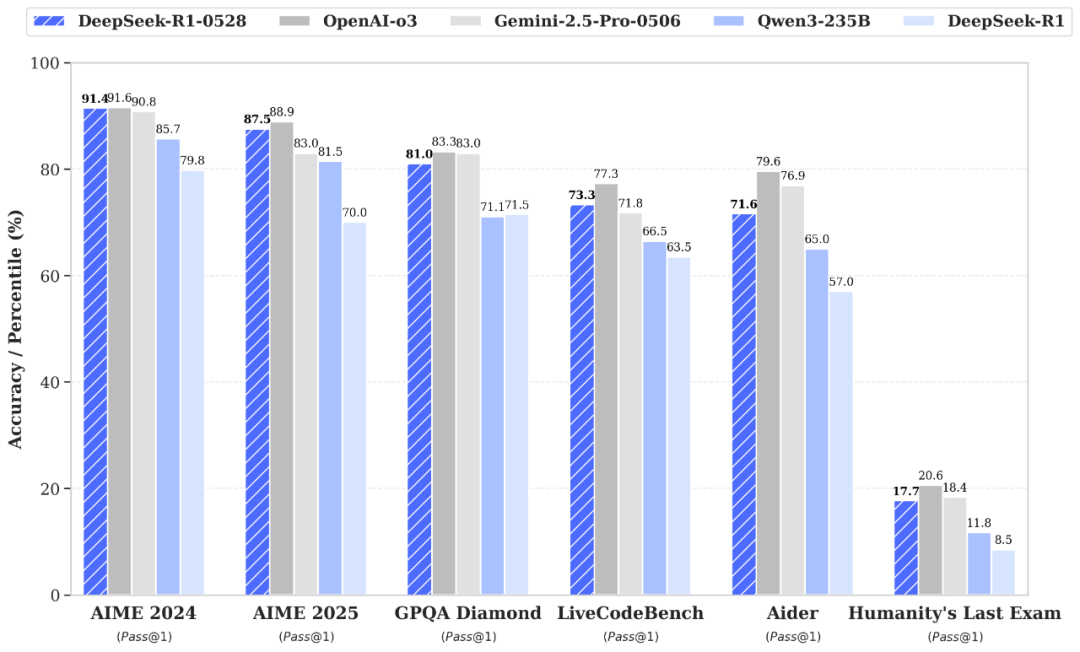
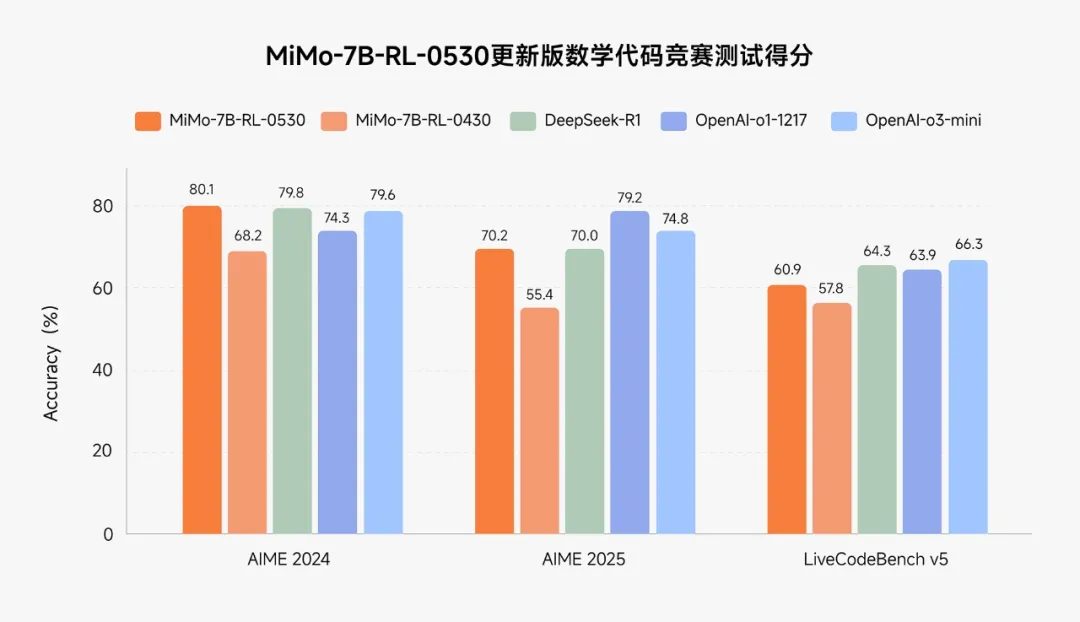
小米的新模型本来应该是个惊喜,因为其在多个数学代码竞赛中,已经与开源推理模型DeepSeek R1和OpenAI闭源推理模型o1、o3-mini相差无几,但如今与最强的开源模型R1-0528对上,差距又拉开了。
例如在AIME2024上,R1-0528的最新成绩是91.4,MiMo-7B-RL-0530则为80.1,在LiveCodeBench上,R1-0528得分73.3,MiMo-7B-RL-0530为60.9,直接被DeepSeek盖过了风头。
不过值得肯定的是,小米模型走出了一个“以小搏大”的技术路线,与DeepSeek比起来其模型参数要小得多,同时支持多模态,这与微软团队开发的Phi系列小语言模型(SLM)有异曲同工之妙,此类模型在特定应用场景下可以更方面部署发挥妙用,在如今各种大模型的激烈竞逐之下,找到自己的独特切入点变得很重要。
在技术报告中,小米大模型Core团队分享了如何构建小而强大的视觉语言模型的相关创新工作,其训练方法结合了四阶段预训练(处理2.4万亿tokens)与混合策略强化学习(MORL),并集成了多样化的奖励信号。
其团队研究发现,在预训练阶段融入包含长链式思维的高质量推理数据至关重要,此外,尽管在多领域同步优化中存在挑战,混合强化学习仍能带来显著收益。
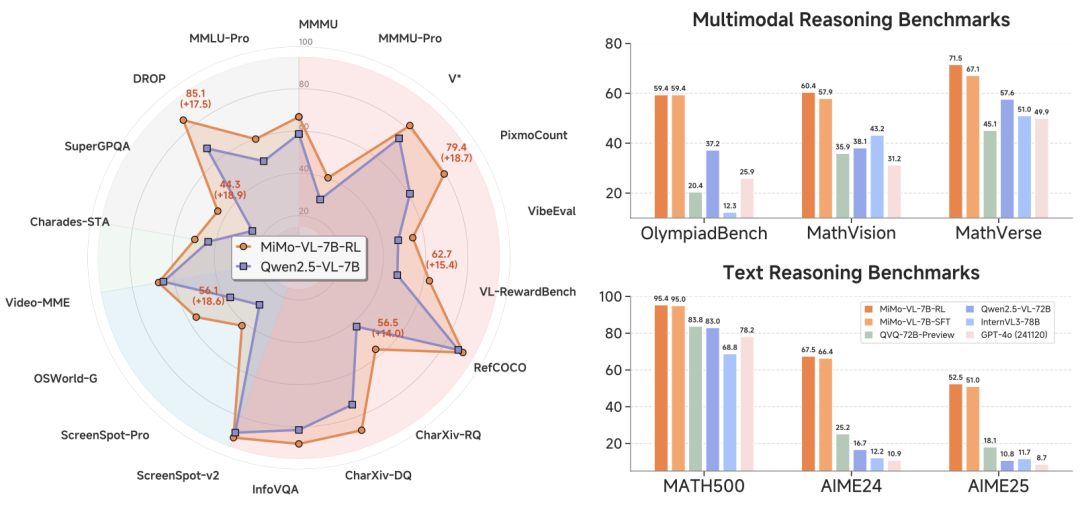
技术报告称,MiMo-VL-7B-RL在全维度多模态能力中表现卓越。
1、基础视觉感知任务:在同等规模的开源视觉语言模型中实现先进性能,在MMMU基准中得分66.7,且在40项评估任务中的35项上超越 Qwen2.5-VL-7B。
2、复杂多模态推理:在OlympiadBench基准中得分59.4,超越参数规模达720亿的模型。
3、智能体应用的GUI定位任务:模型在OSWorld-G数据集中取得54.7分,树立新基准,甚至超过UI-TARS等专用模型。
4、用户体验与偏好:在内部用户偏好评估中,MiMo-VL-7B-RL的Elo评分在所有开源视觉语言模型中最高,可与Claude 3.7 Sonnet等专有模型媲美。
小米团队表示,MiMo-VL-7B-SFT与MiMo-VL-7B-RL为开源视觉语言模型确立了新标准,同时还提供了覆盖50+任务的完整评估套件,助力社区进一步探索。
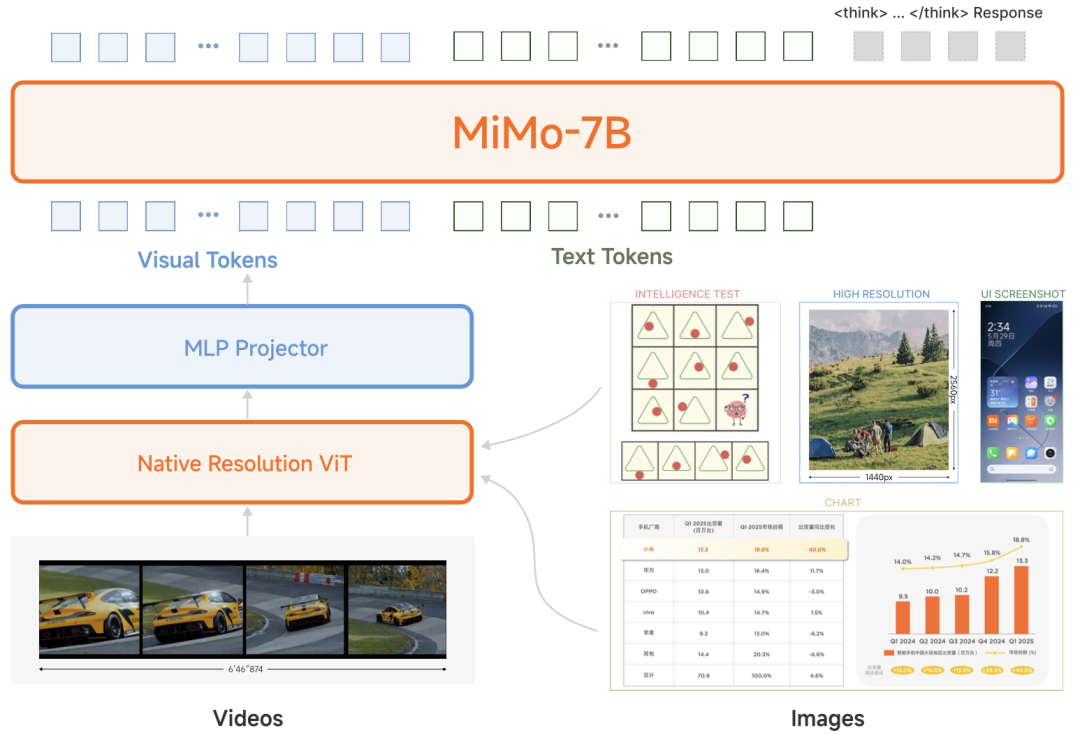
这款模型的架构包含三个关键组件:1、原生分辨率视觉Transformer(ViT)编码器,可保留细粒度的视觉细节;2、多层感知机(MLP)投影器,用于高效的跨模态对齐;3、MiMo-7B 语言模型,针对复杂推理任务进行了专门优化。
同时在预训练以及混合在线强化学习算法方面进行了创新。
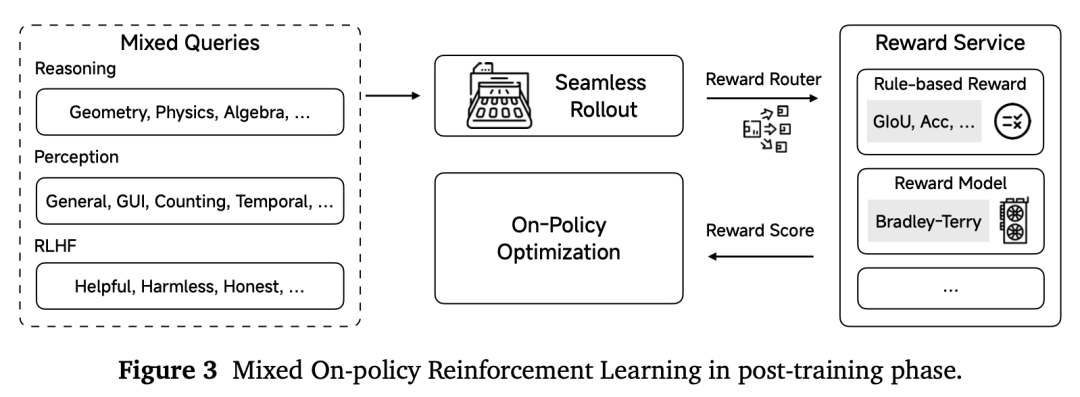
多阶段预训练收集、清洗、合成了高质量的预训练多模态数据,涵盖图片-文本对、视频-文本对、GUI操作序列等数据类型,总计2.4T tokens;混合在线强化学习则包含文本推理、多模态感知 + 推理、RLHF等反馈信号,通过在线强化学习算法稳定加速训练,全方位提升模型推理、感知性能。
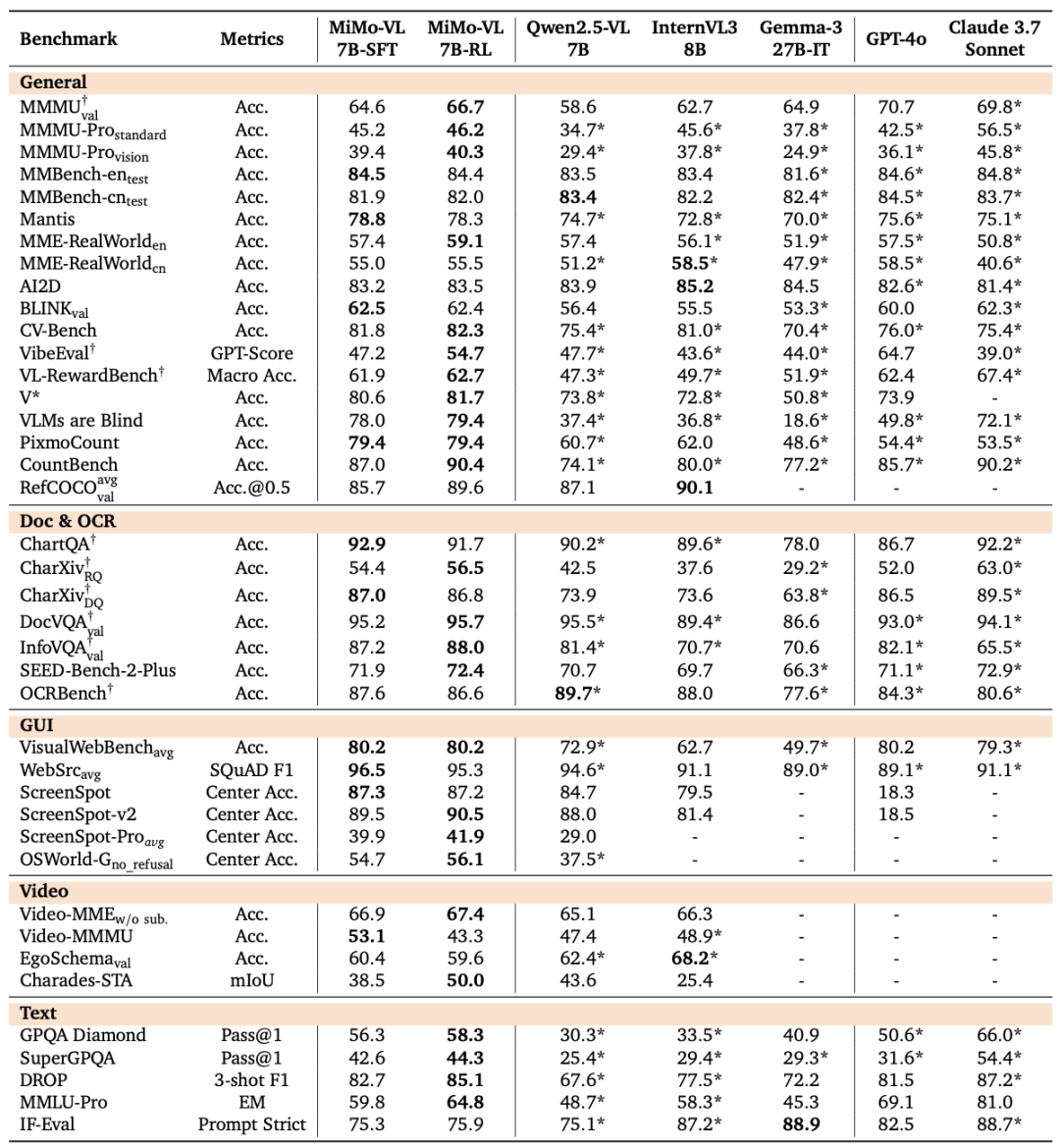
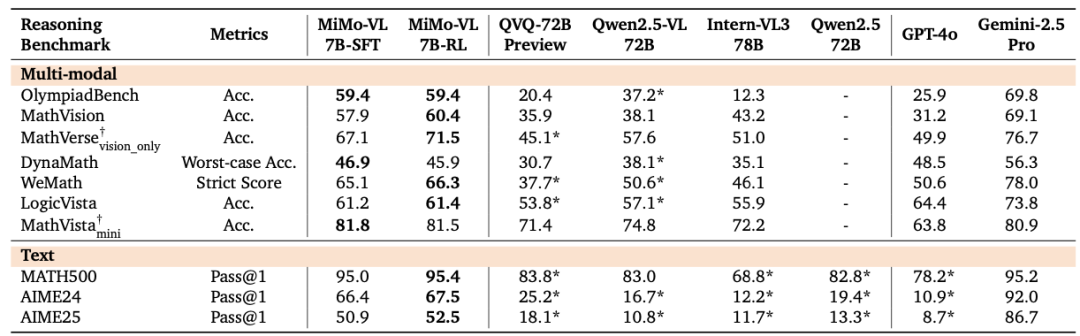
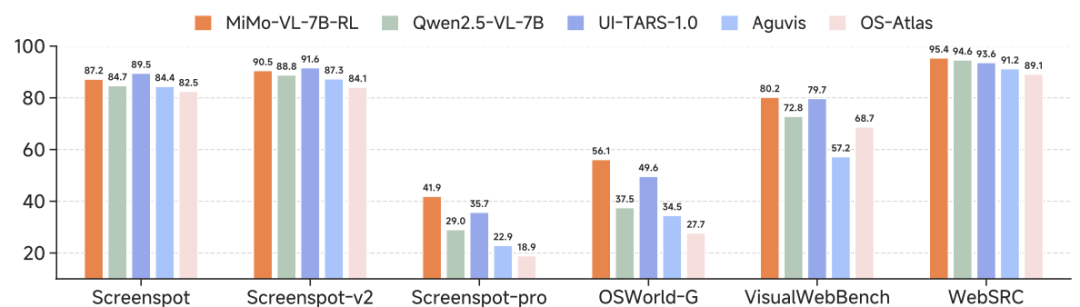
技术报告给出的评估数据显示,MiMo-VL-7B系列模型在多视觉语言、文本基准测试以及推理基准测试中取得了开源模型的最佳结果,在GUI(图形用户界面)理解与定位任务中实现了与专用模型媲美的成绩。
在模型的实际应用示例中,MiMo-VL-7B系列模型的多模态优势很明显。
例如其图表理解能力,可以将复杂图表转换为结构清晰的Markdown图表。
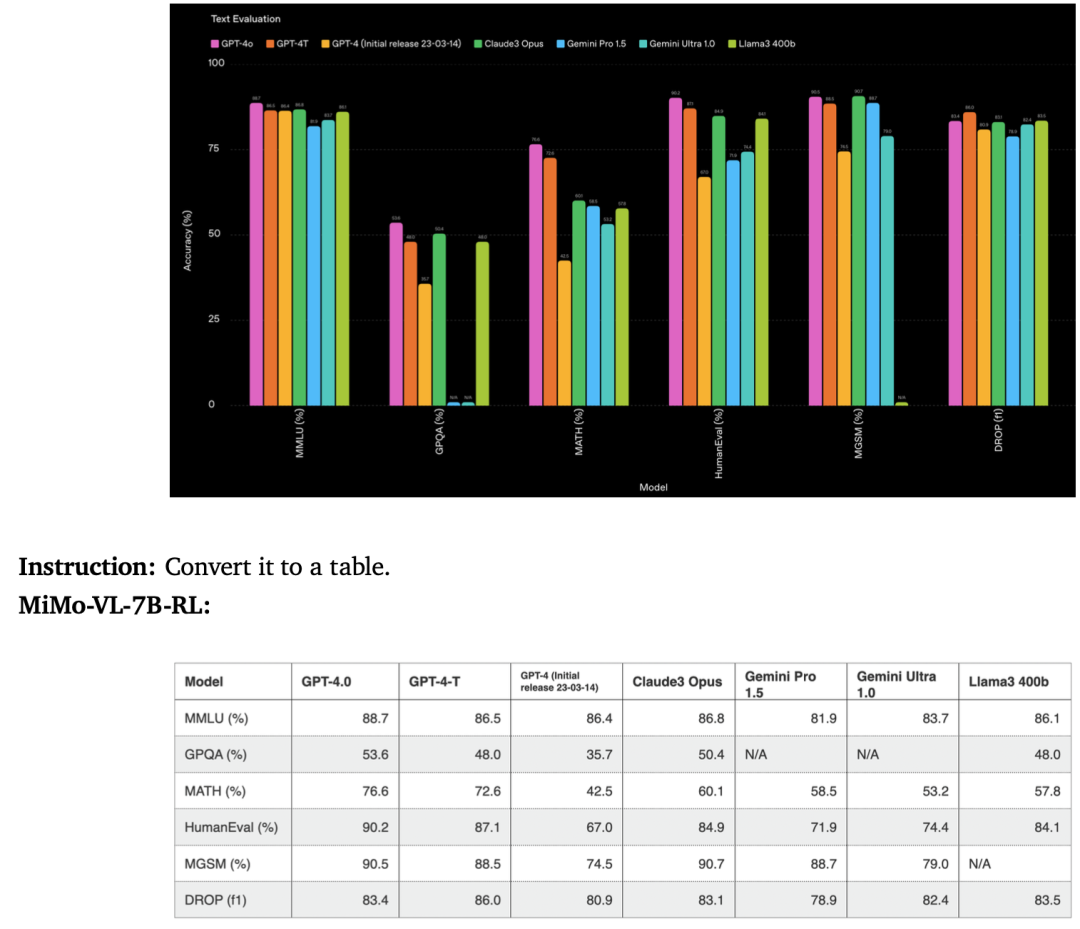
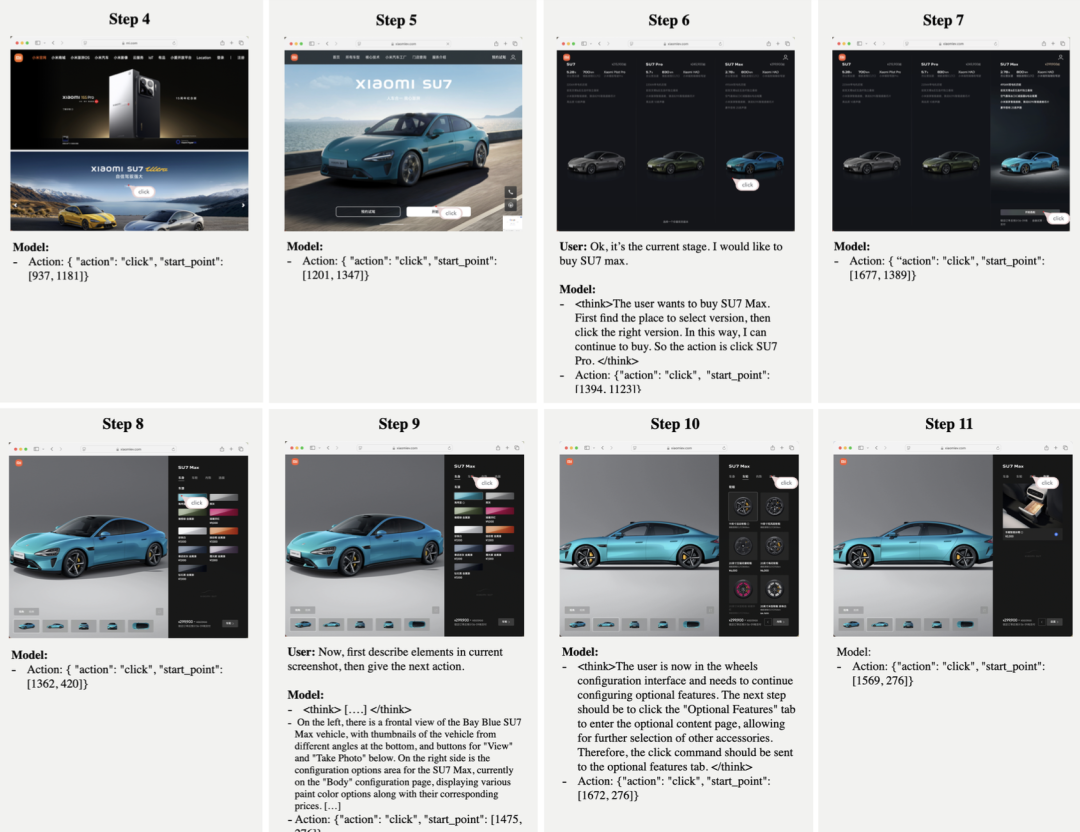



小米大模型Core团队在模型官方推文中表示,MiMo-VL-7B系列模型专为Agent时代而打造,可以替代目前开源7B~72B多模态模型,作为研究多模态RL和Agentic训练的全新基座模型。此外,具备Reasoning能力的小模型,可以靠SFT/RFT创造一个更高的起点,并通过RL最终无限逼近大模型效果。
当下,AI行业正在从生成式AI向智能体AI演进,不仅要解决 “如何生成高质量内容” 的问题,也要解决 “如何用内容和工具完成复杂目标” 的问题,二者共同推动AI从辅助工具向全能助手进化,未来可能在更多场景中深度融合,实现更智能的自动化任务处理。
-END-

(文:头部科技)